
РОДОСЛОВНАЯ — это… Что такое РОДОСЛОВНАЯ?
родословная — происхождение, источник; поколение, колено; родословное дерево, генеалогия, шажере, родословие, генеалогическое дерево, родословное древо, генеалогическое древо Словарь русских синонимов. родословная родословие, генеалогия, генеалогическое (или… … Словарь синонимов
Родословная — Родословная свод данных, описывающих происхождение тех или иных сущностей (существ) от других сущностей. Наиболее часто это понятие используется для обозначение родословной человека. Родословные также используются в сельскохозяйственном и… … Википедия
РОДОСЛОВНАЯ — (родословие), перечень поколений одного рода, устанавливающий происхождение и степени родства. Смотри также Генеалогия … Современная энциклопедия
родословная — РОДОСЛОВНЫЙ, ая, ое. Толковый словарь Ожегова. С.И. Ожегов, Н.Ю. Шведова. 1949 1992 … Толковый словарь Ожегова
родословная
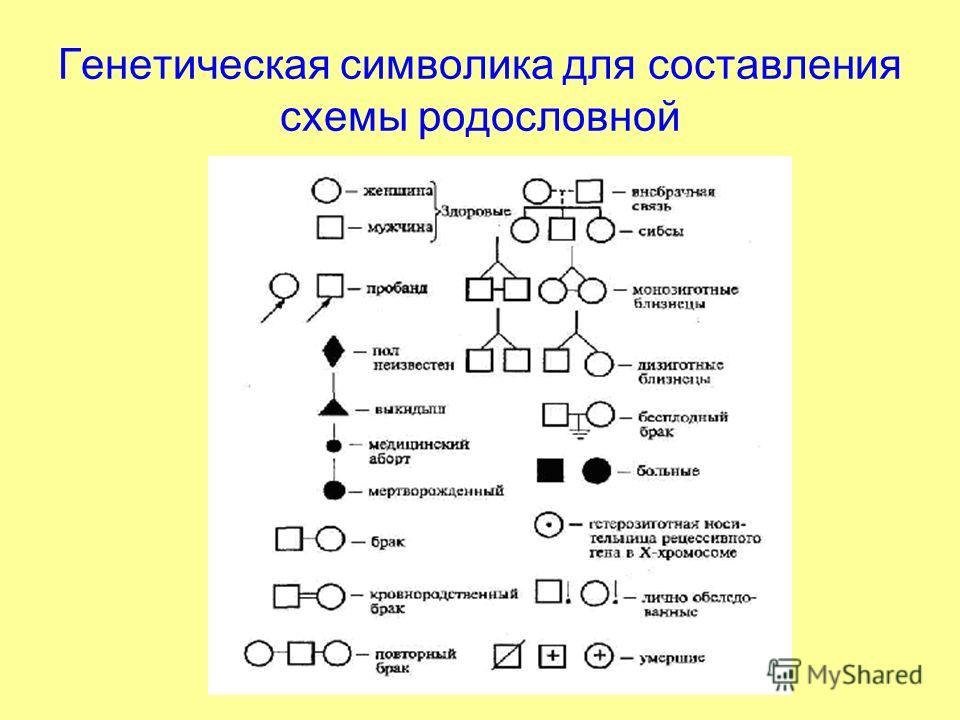 См. генеалогическая схема. (Источник: «Англо русский толковый словарь генетических терминов». Арефьев В.А., Лисовенко Л.А., Москва: Изд во ВНИРО, 1995 г.) … Молекулярная биология и генетика. Толковый словарь.
См. генеалогическая схема. (Источник: «Англо русский толковый словарь генетических терминов». Арефьев В.А., Лисовенко Л.А., Москва: Изд во ВНИРО, 1995 г.) … Молекулярная биология и генетика. Толковый словарь.родословная — генеалогическая схема Диаграмма, изображающая характеристики родственных особей в ряду последовательный поколений. [Арефьев В.А., Лисовенко Л.А. Англо русский толковый словарь генетических терминов 1995 407с.] Тематики генетика Синонимы… … Справочник технического переводчика
Родословная — (родословие), перечень поколений одного рода, устанавливающий происхождение и степени родства. Смотри также Генеалогия. … Иллюстрированный энциклопедический словарь
родословная — ой; ж. Перечень поколений одного рода, содержащий указания на происхождение и степени родства. Собака с родословной. Иметь родословную (документ об истории рода; предков). Составить родословную (восстановить историю своего рода, своих предков).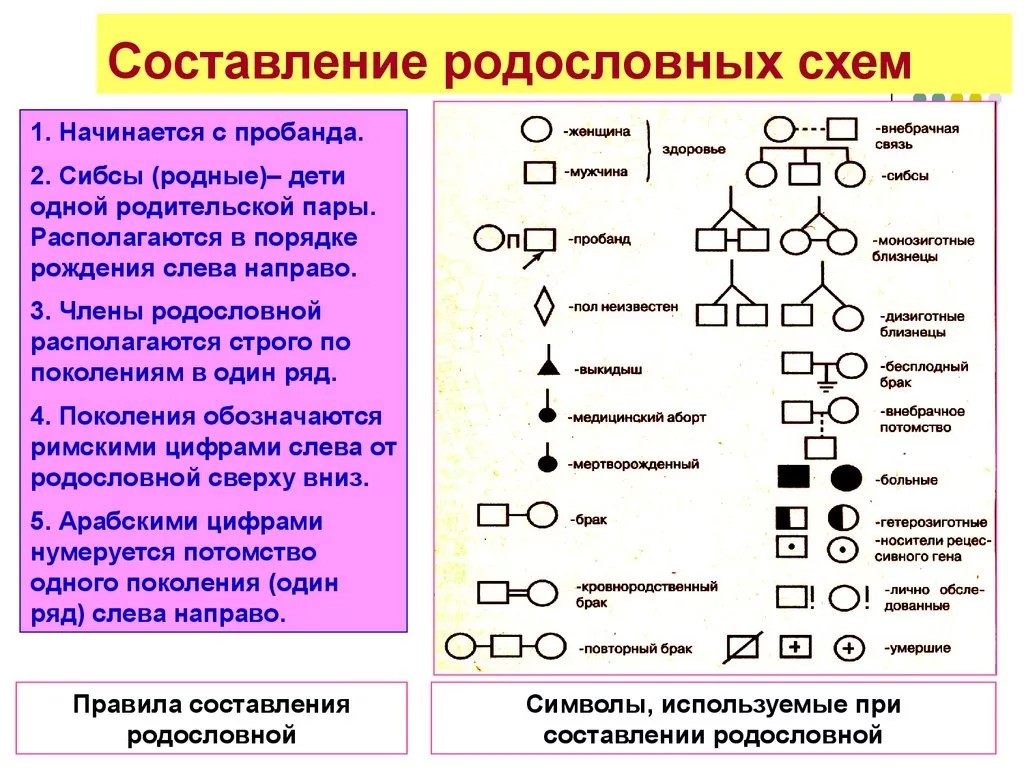
РОДОСЛОВНАЯ — Запись о происхождении племенного животного, в которой приводятся сведения о родителях и предках нескольких поколений. Родословная заносится в индивидуальные карточки племенных животных, способствует решению вопросов отбора и подбора, разведения… … Термины и определения, используемые в селекции, генетике и воспроизводстве сельскохозяйственных животных
Родословная — – подробное генеалогическое «древо» со сложной системой обозначений различных аспектов генетических связей. Традиции прослеживать родословие свойственны, в основном, племенным культурам, в которых положение индивида в обществе существенно зависит … Энциклопедический словарь по психологии и педагогике
Как правильно составить генеалогическое древо своей семьи — сделать родословное дерево — как нарисовать, правила составления родословной
Каждый человек интересуется историей своей семьи и своих корней.
Мы привыкли принимать такие сведения из уст старших поколений и накапливать их. Такая информация помогает узнать историю рода, организовать внутрисемейные связи и узнать предрасположенность к тем или иным болезням.
Процесс сбора данных и оформления подобной схемы непрост, он требует специальных навыков и следования инструкциям.
Сегодня мы поговорим о том, как правильно составить и нарисовать генеалогическое древо семьи, представим шаблон и схему, а также дадим полезные советы и напутствия.
Определение
Перед нами реляционная структура, которая описывает семейные связи в рамках одного рода. Такое название она получила из-за того, что связь между членами семьи изображена в виде веток дерева. В основании находится основоположник рода или же предок, а на исходящих из основания линиях располагаются разные семьи, образовавшиеся из его детей и внуков.
Потребность к изучению своей фамилии пришла к нам из древности. Еще в эпоху неолита люди следили за связями внутри общины, так как знали, что смешение одной крови может привести к появлению на свет детей с серьезными отклонениями. Именно поэтому мужья искали жен в соседних племенах. Когда требовалось сохранить определенные черты, такие как цвет волос или глаз, невесту выбирали из определенного круга. Знание своих корней было необходимо для сохранения родственных уз.
Еще в эпоху неолита люди следили за связями внутри общины, так как знали, что смешение одной крови может привести к появлению на свет детей с серьезными отклонениями. Именно поэтому мужья искали жен в соседних племенах. Когда требовалось сохранить определенные черты, такие как цвет волос или глаз, невесту выбирали из определенного круга. Знание своих корней было необходимо для сохранения родственных уз.
Почему же так важно знать, как сделать генеалогическое или родословное древо семьи? Ответ прост: издавна тесные кровные связи означали не только принадлежность к одной династии, но и служили символом крепких отношений, а также неделимых черт, присущих каждому члену общины, представителю фамилии.
Многие черты характера и поведения формируются с детства и зависят от окружения – заветов наших бабушек, дедушек, мам и пап. К таким можно отнести:
- Привычки.
- Структуру мышления.
- Модель поведения.
- Особенности речи.
В каждом нашем предке – зачастую нереализованные возможности. Они могут проявиться и в нас – в большей или меньшей мере. Поэтому важно знать историю своей фамилии, бережно хранить память о своих корнях. В некоторых случаях составление родословного генеалогического древа своей семьи помогает выявить скрытые характеристики, требующие развития на протяжении всей жизни человека.
Они могут проявиться и в нас – в большей или меньшей мере. Поэтому важно знать историю своей фамилии, бережно хранить память о своих корнях. В некоторых случаях составление родословного генеалогического древа своей семьи помогает выявить скрытые характеристики, требующие развития на протяжении всей жизни человека.
Наследование таких черт не может и не должно быть прямым. Порой оно проявляется через одно колено, а иногда и еще реже. Знание родословной поможет Вам узнать больше не только о своем окружении, но и о самом себе. А процесс сбора материала не только сплотит семью, но и даст шанс наладить контакт с близкими людьми.
Какие существуют виды изобразительных схем
Всего принято выделять два способа отображения кровных уз. Рассмотрим каждую из них.
С восходящей структурой
К этому варианту относят оформление по заведенному порядку: от младших поколений к старшим. В роли отправного пункта принято обозначать составителя проекта, то есть Вас. Эта методика составления древа родословной – наиболее простая. Она подойдет тем, кто только начал искать информацию о своих корнях. Для начала Вам понадобится информация об отце и матери, бабушках, дедушках и так далее. Удобство заключается в том, что Вы в любой момент можете добавить недостающий компонент, отобразив новое ответвление. Рекомендуем использовать этот способ на начальных стадиях изучения своей семьи.
Она подойдет тем, кто только начал искать информацию о своих корнях. Для начала Вам понадобится информация об отце и матери, бабушках, дедушках и так далее. Удобство заключается в том, что Вы в любой момент можете добавить недостающий компонент, отобразив новое ответвление. Рекомендуем использовать этот способ на начальных стадиях изучения своей семьи.
С нисходящей структурой
Эта разновидность характеризуется обратным порядком ведения записей. Точкой отсчета является самый дальний предок – родоначальник. От него проводят лучи, расходящиеся в стороны. Это его дети, от них идут внуки, правнуки и т.д. Для организации подобной структуры понадобятся обширные знания о своей фамилии. Этот метод можно применить на финальных стадиях изучения своей семьи.
Оптимальным вариантом для новичков станет использование первой схемы. Постепенно собирая и накапливая необходимые сведения, Вы сможете организовать большую структуру. После накопленные данные можно перенести в нисходящую схему.
Следующее, на что стоит обратить внимание при составлении семейного древа – линии наследования. Они могут быть представлены двумя видами таблиц:
- Прямая – включает Вас, Ваших маму и папу, прародителей и так далее.
- Обратная – для создания подобного проекта Вам понадобятся сведения о братьях и сестрах, племянниках, в том числе двоюродных, троюродных и т.д.
Структуры такого типа можно составлять как в общем виде, то есть для представителей мужского и женского пола, так и для отслеживания кровных уз только по отцовской или материнской линии. В этом случае формирующиеся отношения принято называть однолинейными.
Генеалогическое древо как подарок
Помимо саморазвития, получения недостающей информации о собственных корнях и сплочения семьи, такой проект может стать прекрасным сюрпризом для любого человека, который интересуется историей своей фамилии, хочет узнать больше о своих предках.
Если Вы хотите сделать необычный подарок, Вам понадобится схема, дополненная соответствующим рисунком. Для этого подойдет структура любой сложности. Начинающим стоит воспользоваться самым простым способом. Оформить проект можно как своими руками, нарисовав изображение на плотном листе бумаге, так и используя специальное программное обеспечение. Первый вариант будет гораздо дороже – в нем особенно заметно Ваше старание, участие, его гораздо приятнее получать. Но это не отменяет ценности напечатанной версии, созданной на компьютере. И в том, и в другом случае Вам придется проделать большую работу, разыскивая сведения о представителях рода.
Для этого подойдет структура любой сложности. Начинающим стоит воспользоваться самым простым способом. Оформить проект можно как своими руками, нарисовав изображение на плотном листе бумаге, так и используя специальное программное обеспечение. Первый вариант будет гораздо дороже – в нем особенно заметно Ваше старание, участие, его гораздо приятнее получать. Но это не отменяет ценности напечатанной версии, созданной на компьютере. И в том, и в другом случае Вам придется проделать большую работу, разыскивая сведения о представителях рода.
Как правильно составить семейное древо со схемой в качестве подарка? Для этого можно приобрести специальную книгу в изящном переплете.
Этот проект будет особенно полезен для:
- Ваших детей – он расскажет подрастающему поколению о предках.
- Дальних родственников – для них можно подготовить обратную нисходящую таблицу, на которой будут изображены братья, сестры, кузены и тд.
- Прародителей – возможен нестандартный вариант оформления в виде песочных часов.
 Для составления подобного варианта можно совместить две методики и провести схему от получателя презента к Вам, используя бабушку или дедушку в качестве ключевой фигуры.
Для составления подобного варианта можно совместить две методики и провести схему от получателя презента к Вам, используя бабушку или дедушку в качестве ключевой фигуры.
Также можно взять такой распространенный шаблон, как «бабочка». В нем основой является супружеская пара от которой ведутся восходящие и нисходящие ветви к предкам и потомкам.
Менее популярный, но при этом более подробный способ описания кровных уз – круговая диаграмма. Данная схема пользуется спросом за рубежом. При этом ее не так часто встретишь на территории РФ. Суть заключается в совмещении восходящей и нисходящей составляющей. Рассмотрим основные этапы оформления, чтобы узнать, как правильно составить родословное древо семьи и сделать его оригинальным.
- В качестве базы используйте веер – одну четвертую круга.
- Также можно нарисовать несколько централизованных окружностей, которые будут включать и предков, и потомков.
- Другой способ – разделить круг и составить уникальный проект родословной, соединив оба способа описания фамилии.

Любой из предложенных вариантов можно украсить снимками, заметками. Вы можете вписать в проект занимательные факты из общей истории, связав их с деталями декора.
Что необходимо для самостоятельного создания схемы
Для начала Вам потребуется изучить семейный архив. Постарайтесь найти все сохранившиеся фотографии и бумаги, свидетельствующие о кровных узах. Наиболее важными будут:
- Трудовые книжки.
- Удостоверения.
- Документы.
- Свидетельства о браке.
- Аттестаты.
Подобные документы послужат отправной точкой для дальнейших поисков, сбора информации для фамильного древа. Все найденные бумаги и снимки следует отсканировать и хранить не только на компьютере, но и на внешнем носителе, например, флешке. Это поможет защитить материалы от случайного удаления, даже если Ваш ПК выйдет из строя и все сведения на нем пропадут.
Следующий этап – наиболее важная часть процесса. Это обращение к Вашим родным и близким. Каких-то определенных правил составления генеалогического древа не существует, но эта стадия остается одной из важнейших, поскольку позволяет узнать информацию из первых уст. Перед визитом советуем определиться с перечнем вопросов и записать их, чтобы ничего не упустить. Для создания проекта фамильной схемы Вам могут быть полезны следующие данные:
Каких-то определенных правил составления генеалогического древа не существует, но эта стадия остается одной из важнейших, поскольку позволяет узнать информацию из первых уст. Перед визитом советуем определиться с перечнем вопросов и записать их, чтобы ничего не упустить. Для создания проекта фамильной схемы Вам могут быть полезны следующие данные:
Дата рождения того или иного предка.
- Место и время их работы.
- Учились ли они. Если да, то где и в какое время.
- На ком они были женаты или за кого вышли замуж.
- Количество детей, их ФИО и даты рождения, хотя бы приблизительные.
- Если потомка больше нет в живых, необходимо узнать, в каком году он ушел из жизни, где он/она похоронены.
Из этого следует, что самая полезная информация – дата и место того или иного происшествия. Именно эти данные помогут Вам в дальнейшем обратиться в архив за подробностями.
Помимо этого следует уделить должное внимание рассказам самих родственников. Это позволит Вам узнать полезную информацию о своих предках, их достижениях, преданиях, передающихся из поколения в поколение.
Это позволит Вам узнать полезную информацию о своих предках, их достижениях, преданиях, передающихся из поколения в поколение.
Для сохранения всех деталей при составлении родословного древа семьи советуем воспользоваться устройством записи при разговоре. Для этого можно использовать как диктофон, так и смартфон, оснащенный подобной функцией.
После беседы следует несколько раз переслушать запись, чтобы не упустить из виду какие-либо важные моменты и вехи развития вашего рода. Далее полученные сведения необходимо структурировать и записать в специально отведенную тетрадь или на электронный носитель. Во втором случае советуем завести отдельную папку, в которую Вы будете переносить все данные и фотографии. Также стоит продублировать ее на внешний накопитель или облачный сервис, такой как Яндекс.Диск или Google.Docs. Это позволит Вам иметь доступ к информации в любой точке света.
Для углубленного и детального поиска сведений, которые помогут Вам воссоздать полную картину, могут понадобиться месяцы, а порой и несколько лет кропотливой работы. Как составить схему фамильного древа семьи, если времени мало и Вам нужна помощь? Для ускорения процесса Вы можете подключить остальную родню: братьев, сестер или родителей.
Как составить схему фамильного древа семьи, если времени мало и Вам нужна помощь? Для ускорения процесса Вы можете подключить остальную родню: братьев, сестер или родителей.
В этом случае каждый участник должен выбрать определенную ветвь и работать именно по ней. После того, как каждый из Вас закончит сбор информации, полученный материал следует собрать воедино и организовать полную систему. Такой подход позволит не только ускорить процесс, но и получить более глубокие познания. Помимо этого у Вас будет шанс наладить отношения с родственниками, которые участвуют в поисках.
Древо жизни: как составить родословную с помощью компьютерных программ
Сбор данных о предках – дело требующее большого труда и времени. Если Вы будете использовать восходящий тип проекта, то уже к седьмому колену насчитаете более ста представителей одной фамилии.
Использование блокнотов или тетрадей для хранения информации непрактично. В любой момент Вы можете потерять носитель, а с ним и информацию, собранную за время усердного труда. Для упрощения работы можно использовать машинные базы данных, такие как Microsoft Office Excel или Access. Также можно начать разрабатывать проект в специализированном софте, которые предназначен для создания фамильных деревьев. Так Вы сможете без труда составить красивую и корректно структурированную диаграмму.
Для упрощения работы можно использовать машинные базы данных, такие как Microsoft Office Excel или Access. Также можно начать разрабатывать проект в специализированном софте, которые предназначен для создания фамильных деревьев. Так Вы сможете без труда составить красивую и корректно структурированную диаграмму.
Такие сервисы делятся на онлайн и оффлайн утилиты. Первые позволяют хранить все сведения в интернете и получать к ним доступ с любого устройства. Из недостатков можно выделить короткий срок хранения. Обычно такие сайты позволяют накапливать информацию не более пяти лет, затем все материалы будут удалены. Софт второго типа хранит все данные на компьютере, на котором установлено приложение.
Также программы можно разделить на платные и бесплатные. Первые имеют более богатый функционал, вторые выгоднее использовать, если Вы не готовы потратиться на оформление схемы.
Сегодня мы рассказали, как составить родовое дерево для приятного семейного подарка, что для этого понадобится, а также дали полезные советы и напутствия. Не затягивайте и начинайте сбор информации прямо сейчас. Так у Вас будет возможность получить больше сведений и лучше узнать своих предков.
Не затягивайте и начинайте сбор информации прямо сейчас. Так у Вас будет возможность получить больше сведений и лучше узнать своих предков.
Методы исследования генетики — урок. Биология, Общие биологические закономерности (9–11 класс).
Гибридологический метод — система скрещиваний, позволяющая проследить закономерности наследования признаков в ряду поколений.
Отличительные особенности метода:
- целенаправленный подбор родителей, различающихся по одной, двум, трём и т. д. парам альтернативных признаков;
- строгий количественный учёт наследования признаков у гибридов;
- индивидуальная оценка потомства от каждого родителя в ряду поколений.
Генеалогический метод — составление родословной и её анализ.
Анализ родословных применяется для организмов, у которых невозможно скрещивание (человек) или размножение происходит медленно.
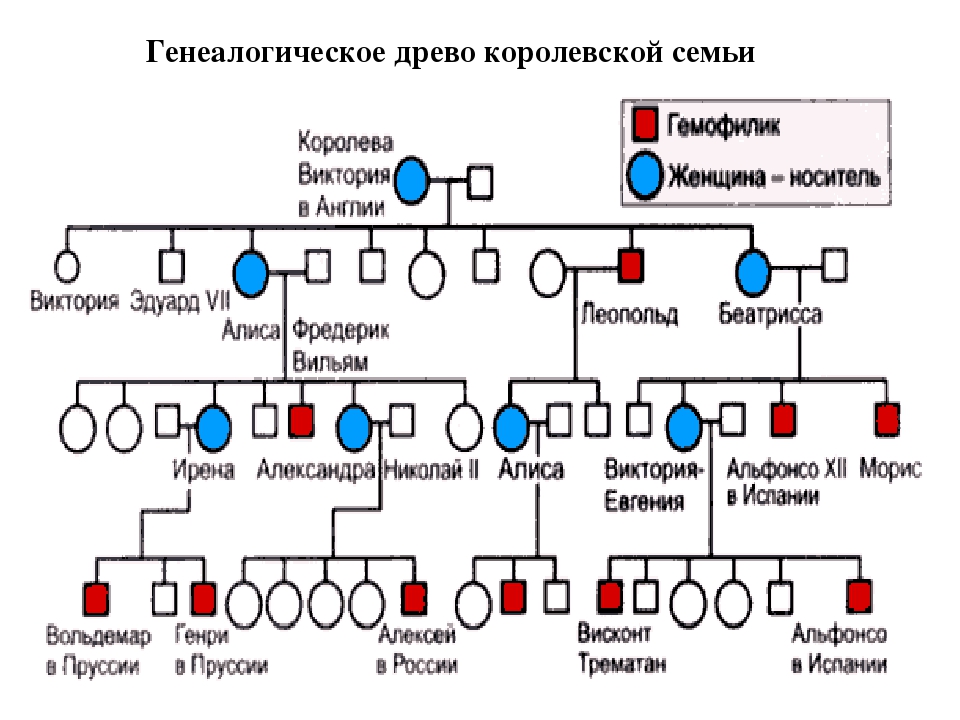
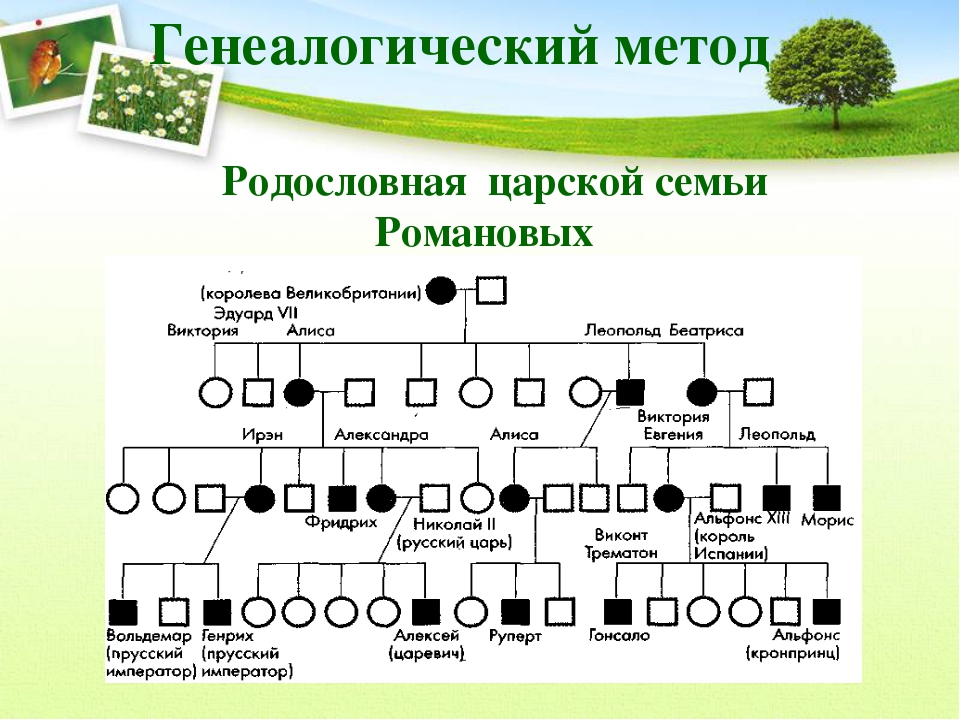
Рис.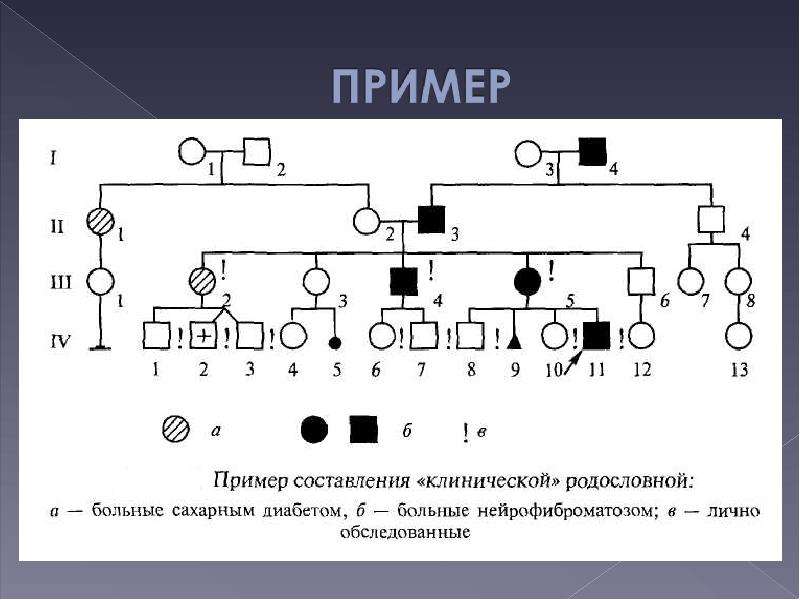 \(1\). Родословная королевы Виктории (наследование гемофилии)
\(1\). Родословная королевы Виктории (наследование гемофилии)
С помощью этого метода можно установить особенности наследования признаков. Если признак проявляется в каждом поколении, то он доминантный; если признак проявляется через поколение, то он рецессивный. Если признак чаще проявляется у одного пола, то это признак, сцепленный с полом.
Близнецовый метод — изучение проявления признаков у однояйцевых и разнояйцевых близнецов.
Близнецовый метод позволяет изучать роль генотипа и среды в формировании конкретных признаков организма. Однояйцевые близнецы имеют одинаковый генотип, поэтому они всегда одного пола и похожи друг на друга. Различия, которые возникают у таких близнецов в течение жизни, связаны с воздействием условий окружающей среды.
Популяционно-статистический метод — анализ частоты встречаемости генов и генотипов в популяции.
Этот метод даёт информацию об эволюции вида, позволяет прогнозировать количество особей с мутациями.
Цитогенетический метод — микроскопическое изучение числа, формы и размеров хромосом в делящихся клетках организма.
Исследование кариотипа организма с помощью микроскопа используется для установления геномных и хромосомных мутаций.
Рис. \(2\). Хромосомы человека
Биохимический метод — анализ состава веществ, содержащихся в организме, и биохимических реакций, протекающих в его клетках.
Этим методом можно устанавливать функцию гена, изучать нарушения обмена веществ.
Молекулярно-генетический метод — расшифровка геномов организма.
Устанавливается последовательность нуклеотидов в ДНК организма.
В генетике находят применение и другие методы исследования.
Источники:
Рис. 1. Родословная. королевы Виктории. © ЯКласс
Рис. 2. Хромосомы человека. © ЯКласс
Информио
×Неверный логин или пароль
×Все поля являются обязательными для заполнения
×Сервис «Комментарии» — это возможность для всех наших читателей дополнить опубликованный на сайте материал фактами или выразить свое мнение по затрагиваемой материалом теме.
Редакция Информио.ру оставляет за собой право удалить комментарий пользователя без предупреждения и объяснения причин. Однако этого, скорее всего, не произойдет, если Вы будете придерживаться следующих правил:
- Не стоит размещать бессодержательные сообщения, не несущие смысловой нагрузки.
- Не разрешается публикация комментариев, написанных полностью или частично в режиме Caps Lock (Заглавными буквами). Запрещается использование нецензурных выражений и ругательств, способных оскорбить честь и достоинство, а также национальные и религиозные чувства людей (на любом языке, в любой кодировке, в любой части сообщения — заголовке, тексте, подписи и пр.)
- Запрещается пропаганда употребления наркотиков и спиртных напитков. Например, обсуждать преимущества употребления того или иного вида наркотиков; утверждать, что они якобы безвредны для здоровья.
- Запрещается обсуждать способы изготовления, а также места и способы распространения наркотиков, оружия и взрывчатых веществ.

- Запрещается размещение сообщений, направленных на разжигание социальной, национальной, половой и религиозной ненависти и нетерпимости в любых формах.
- Запрещается размещение сообщений, прямо либо косвенно призывающих к нарушению законодательства РФ. Например: не платить налоги, не служить в армии, саботировать работу городских служб и т.д.
- Запрещается использование в качестве аватара фотографии эротического характера, изображения с зарегистрированным товарным знаком и фотоснимки с узнаваемым изображением известных людей. Редакция оставляет за собой право удалять аватары без предупреждения и объяснения причин.
- Запрещается публикация комментариев, содержащих личные оскорбления собеседника по форуму, комментатора, чье мнение приводится в статье, а также журналиста.
Претензии к качеству материалов, заголовкам, работе журналистов и СМИ в целом присылайте на адрес
×Информация доступна только для зарегистрированных пользователей.
Уважаемые коллеги. Убедительная просьба быть внимательнее при оформлении заявки. На основании заполненной формы оформляется электронное свидетельство. В случае неверно указанных данных организация ответственности не несёт.
Как правильно составить генеалогическое древо рода и семьи самостоятельно — шаблон, образец и схема с примерами
Прослеживая их, можно многое узнать о себе и скорректировать собственную судьбу. Даже тем, кто еще мало задумывается о собственном происхождении, эта информация будет полезна хотя бы на уровне определения генетических предрасположенностей к заболеваниям.
Но собрать и правильно оформить сведения о своих родных очень нелегко. В этой статье мы расскажем о том, как правильно составить генеалогическое (родословное) дерево семьи со схемами, примерами и шаблонами.
Что такое генеалогическое дерево
Родословное древо – условная схема, описывающая родственные связи в пределах одной семьи. Оно достаточно часто изображается в виде реального дерева.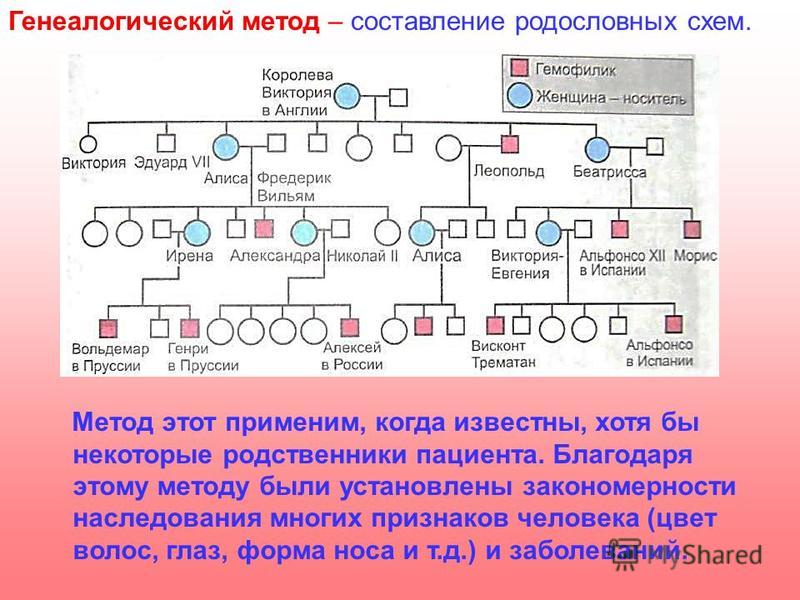 Рядом с корнями обычно располагается родоначальник или же последний потомок, для которого составляется схема, а на ветвях различные линии рода.
Рядом с корнями обычно располагается родоначальник или же последний потомок, для которого составляется схема, а на ветвях различные линии рода.
В древности сохранение знаний о своем происхождении было прямой необходимостью каждого. Уже во времена неолита люди знали, что близкородственные браки ведут к появлению нежизнеспособных детей. Поэтому мужчины брали себе жен в соседних селениях, родах и племенах. Впрочем, иногда требовалось сохранить внутри линии какие-то качества, и тогда люди выбирали невест и женихов среди ограниченного круга. Но и в первом, и во втором случае знание своих предков было обязательным.
Кровь (кровное родство) в прошлом означала не только наличие родственных связей, но и некую психо-эмоциональную общность, и в отношении представителей одной семьи спектр ожиданий от людей был довольно близким.
Такое поведение имеет под собой почву. Замечали ли вы, что есть семьи, представители разный линий и поколений которых сами по себе выбирают близкие направления развития. Есть семьи, в которой все связаны с искусством, а есть те, где на протяжении поколений каждый второй имеет склонность к инженерным наукам. И дело тут не только в воспитании, но и в особенностях функционирования организма. Генетическая предрасположенность проявляет себя не только в болезнях, но и в талантах представителей родственной линии.
Есть семьи, в которой все связаны с искусством, а есть те, где на протяжении поколений каждый второй имеет склонность к инженерным наукам. И дело тут не только в воспитании, но и в особенностях функционирования организма. Генетическая предрасположенность проявляет себя не только в болезнях, но и в талантах представителей родственной линии.
Система родов поддерживалась и социальным устройством. Большинство обществ проходят этапы сначала кастовой, потом сословной, потом классовой системы. И браки в них обычно устраиваются в пределах своего социального круга.
История рода может пролить свет на многие личные ценности. Очень многое закладывается в человека в самом раннем возрасте на примере отношений его родителей и их родственников: модели поведения, структура мышления, привычки и слова. Но наследование не всегда прямое. Изучение истории рода и воссоздание родового древа способствует самоидентификации личности, позволяет осознать свои личностные основы. Это полезно как самому человеку, так и семье в целом. Сам процесс сбора сведений и их оформления будет полезен для налаживания контакта между родственниками.
Сам процесс сбора сведений и их оформления будет полезен для налаживания контакта между родственниками.
Виды генеалогического древа
Есть несколько методов составления родословного древа:
- Восходящее. Здесь цепочка строится по направлению от потомка к предкам. В качестве начального элемента выступает составитель схемы. Способ удобен тем, кто только начал изучение своей семьи. Составитель располагает информацией в основном о своих ближайших родственниках: родителях, дедушках, бабушках и т. д. – и постепенно углубляется в прошлое.
- Нисходящее. В этом случае цепочка имеет противоположное направление. В качестве начала выступает один предок (или супруги). Для такого построения нужно обладать достаточно обширными сведениями о своих родственниках.
Составляя родословное дерево нужно учитывать линии наследования. Они бывают двух видов:
- Прямая ветвь. Цепочка включает, Вас, Ваших родителей, их родителей и т. д.
- Боковая ветвь.
 Она учитывает Ваших братьев и племянников, братьев и сестер дедушек и бабушек, прадедушек и прабабушек и т. д.
Она учитывает Ваших братьев и племянников, братьев и сестер дедушек и бабушек, прадедушек и прабабушек и т. д.
Эти схемы – восходящую и нисходящую с прямыми и боковыми ветвями – можно составлять, как смешанную: одновременно для мужчин и женщин своего рода, – так и для отслеживания наследования только по роду отца или матери.
Родовое древо можно оформлять следующим образом:
Привычное нам ветвящееся взаиморасположение, которое часто дополняют рисунком дерева. Подходит для оформления генеалогических схем любой степени сложности.
- Вы нарисуйте в этом стиле восходящее родовое дерево вашего ребенка.
- Сделайте прекрасный подарок для дальнего родственника, изобразив на схеме в качестве начальной фигуры общего предка и от него построив нисходящую систему связей всех двоюродных и троюродных братьев и сестер.
- Оформите чертеж в виде песочных часов. Такой вариант подойдет для старших родственников: дедов или прадедов.
 Возьмите их в качестве ключевых фигур и составьте генеалогическое родословное древо этих членов своей семьи, совместив на рисунке нисходящие и восходящие схемы – родителей и потомков.
Возьмите их в качестве ключевых фигур и составьте генеалогическое родословное древо этих членов своей семьи, совместив на рисунке нисходящие и восходящие схемы – родителей и потомков.
Схема «бабочка» по своей сути довольно близка к варианту «часы». У неё исходной точкой являются супруги, по обеим сторонам от них располагаются восходящие родовые древа их родителей, а внизу нисходящее.
Существует еще один вариант построения структуры. Он не распространен на территории России, но позволяет создать достаточно полное описание семейных связей. Это так называемая круговая таблица. Она также способна вмещать восходящее и нисходящее направления описание рода.
- Для простых схем можно взять в качестве основы четверть круга – схема «веер».
- Есть вариант оформления восходящей или нисходящей структуры в виде концентрированных окружностей, в которых вписывают предков или потомков.
- Или же круг можно разделить и составить генеалогическое древо рода, совместив оба направления семьи аналогично шаблону «часы».
Любой из описанных вариантов можно дополнить фотографиями и заметками.
Как самостоятельно можно составить генеалогическое древо семьи
Исследование лучше начинать с семейного архива. Посмотрите, остались ли у вас старые фотографии и официальные документы Ваших старших родственников. Особенно полезные будут документы: свидетельства о браке или рождении, дипломы, аттестаты, трудовые книжки, – поскольку именно с их помощью проще всего начинать поиски в архиве. Все бумаги и фотографии стоит отсканировать, сохранить где-нибудь в цифровом формате и в дальнейшем использовать именно их. А оригиналы вернуть на место, чтобы не потерять эти важные свидетельства.
Следующим важным этапом является опрос родственников. И поскольку родные невечны, затягивать с ним не стоит. Чтобы не переутомить пожилых людей и не запутаться самому, важно заранее очертить круг вопросов. К примеру, когда мы составляем генеалогическое древо семьи, стоит интересоваться информацией:
- Когда и где родились те или иные родственники.
- Где и когда работали.
- Время и место учебы.
- На ком и когда женились.
- Сколько у них было детей, их имена и даты рождения.
- Если родственники умерли, стоит знать, когда и где это произошло.
Как Вы видите, с точки зрения дальнейших поисков, из перечня самая важная информация – это место и время тех или иных событий. Зная их, можно обращаться в архивы за документами.
Но с точки зрения семьи намного важнее услышать рассказы о жизни своих родных. Каждая семья хранит свои предания, в каждой происходило что-то, достойное памяти поколений. Поэтому не пренебрегайте долгими разговорами о прошлом.
При сборе устных сведений стоит пользоваться диктофоном, чтобы не упустить ни одной мелочи.
Всю полученную информацию важно грамотно и быстро структурировать, иначе Вы просто запутаетесь в хитросплетениях Ваших семейных связей. Сведения Вы можете хранить на бумажных носителях в папках, относящихся к каждой линии семьи. Или же создать отдельную папку на компьютере, куда будете помещать файлы о каждом из родственников.
Или же создать отдельную папку на компьютере, куда будете помещать файлы о каждом из родственников.
Некоторые люди исследуют свою родословную годами, постепенно углубляя знания о своих родных по прямой и непрямой линии.
Но можно начальные этапы процесса сделать более быстрым, предложите своим родным поучаствовать с вами в этом важном деле. Если несколько человек каждый по своей линии составит список ближайших родственников с именами, фотографиями и датами, а потом все эти сведения объединят в единую схему, Вы сможете получить родословное древо на несколько поколений глубь всего за несколько месяцев. К тому же, такое решение поможет наладить общение между отдельными ветвями семьи.
Сервисы и программы, помогающие составить родословное древо семьи
Сбор информации о родственниках достаточно трудное дело. Просто потому что с каждым поколением количество людей, о которых нужно собрать сведения, будет увеличиваться в геометрической прогрессии. Даже при использовании восходящей схемы с учетом только прямых ветвей к седьмому поколению Вы будете насчитывать 126 человек предков.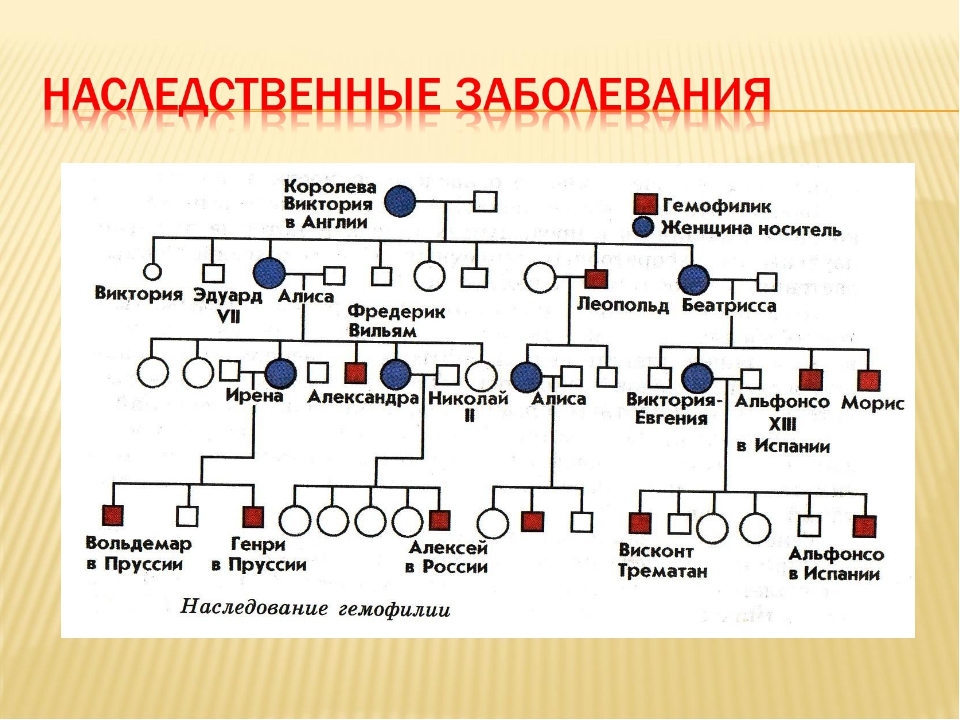
Регистрация и хранение всех этих сведений с помощью бумажных носителей неудобна. Намного проще использовать электронные базы данных. Можно самостоятельно создать необходимые файлы в Excel или Access. Или же воспользоваться специализированными программами, которые изначально настроены так, чтобы максимально легко скомпоновать информацию в Вашей семье, отобразить и вывести ее в красивом и понятном виде.
Существуют много интернет-сервисов по родословной тематике. Они правильно составят Ваше генеалогическое древо, помогут с поиском информации о родственниках, предоставят образцы оформления.
- Некоторые из них предоставляют возможность создать схему Вашего рода онлайн. На них после бесплатной регистрации нужно ввести информацию о каждом родственнике, указать его семейные связи, предоставить фотографии, а сервис уже сам графически построит необходимую структуру.
- Есть более профессиональные сайты с большим количеством настроек. Они автоматически проводят дополнительный анализ фамилии и даже ищут сведения в архивах.
Удобное решение, но, к несчастью, подобные сервисы существуют относительно недолго, обычно около 5 лет, после чего Вы, скорее всего, потеряете доступ к введенной информации.
- Для более глубокой работы лучше использовать специальные программы, работающие в независимо от интернета. Они бывают платными и бесплатными. Последние имеют более ограниченный функционал.
- Или обратиться в специальную фирму, занимающуюся генеалогией, с ее помощью найти сведения о своих родственных связях, и красиво их оформить генеалогическое древо или родовую книгу.
Страница не найдена — Саянский медицинский колледж
Я, субъект персональных данных, в соответствии с Федеральным законом от 27 июля 2006 года № 152 «О персональных данных» предоставляю ОГБПОУ «Саянский медицинский колледж» (далее — Оператор), расположенному по адресу Иркутская обл., г.Саянск, м/он Южный, 120, согласие на обработку персональных данных, указанных мной в форме веб-чата, обратной связи на сайте в сети «Интернет», владельцем которого является Оператор.
- Состав предоставляемых мной персональных данных является следующим: Имя, адрес электронной почты.
- Целями обработки моих персональных данных являются: обеспечение обмена короткими текстовыми сообщениями в режиме онлайн-диалога или обмена текстовыми сообщениями через электронную почту.
- Согласие предоставляется на совершение следующих действий (операций) с указанными в настоящем согласии персональными данными: сбор, систематизацию, накопление, хранение, уточнение (обновление, изменение), использование, передачу (предоставление, доступ), блокирование, удаление, уничтожение, осуществляемых как с использованием средств автоматизации (автоматизированная обработка), так и без использования таких средств (неавтоматизированная обработка).
- Я понимаю и соглашаюсь с тем, что предоставление Оператору какой-либо информации о себе, не являющейся контактной и не относящейся к целям настоящего согласия, а равно предоставление информации, относящейся к государственной, банковской и/или коммерческой тайне, информации о расовой и/или национальной принадлежности, политических взглядах, религиозных или философских убеждениях, состоянии здоровья, интимной жизни запрещено.

- В случае принятия мной решения о предоставлении Оператору какой-либо информации (каких-либо данных), я обязуюсь предоставлять исключительно достоверную и актуальную информацию и не вправе вводить Оператора в заблуждение в отношении своей личности, сообщать ложную или недостоверную информацию о себе.
- Я понимаю и соглашаюсь с тем, что Оператор не проверяет достоверность персональных данных, предоставляемых мной, и не имеет возможности оценивать мою дееспособность и исходит из того, что я предоставляю достоверные персональные данные и поддерживаю такие данные в актуальном состоянии.
- Согласие действует по достижении целей обработки или в случае утраты необходимости в достижении этих целей, если иное не предусмотрено федеральным законом.
- Согласие может быть отозвано мною в любое время на основании моего письменного заявления.
Наука: Наука и техника: Lenta.ru
Международная группа ученых, включающая российских исследователей, прочла геном женщины-неандертальца из Денисовой пещеры на Алтае. Эта работа, опубликованная на страницах Nature и кратко пересказанная на сайте университета Калифорнии в Беркли, подтверждает скрещивание неандертальцев как с Homo sapiens, так и другими видами.
Эта работа, опубликованная на страницах Nature и кратко пересказанная на сайте университета Калифорнии в Беркли, подтверждает скрещивание неандертальцев как с Homo sapiens, так и другими видами.
Исследователи из Германии, Китая, России (Институт археологии и этнографии СО РАН) и США выделили ДНК из небольшого фрагмента кости стопы. Эта кость принадлежала женщине-неандертальцу, жившей около сорока тысячелетий назад: ее нашли во время раскопок в Денисовой пещере. Эта пещера на Алтае стала известна после того, как в 2010 году там были обнаружены останки неизвестного вида людей («денисовский человек», латинское название пока не присвоено), но кроме «денисовцев» в ней обитали и неандертальцы, и кроманьонцы.
Молекулярно-генетический анализ подтвердил, что все три известных вида и еще какой-то, пока не выявленный вид человека, не просто поочередно жили в одной пещере на протяжении более чем десяти тысяч лет. Между этими видами происходил обмен генами, то есть представители одного иногда скрещивались с представителями другого.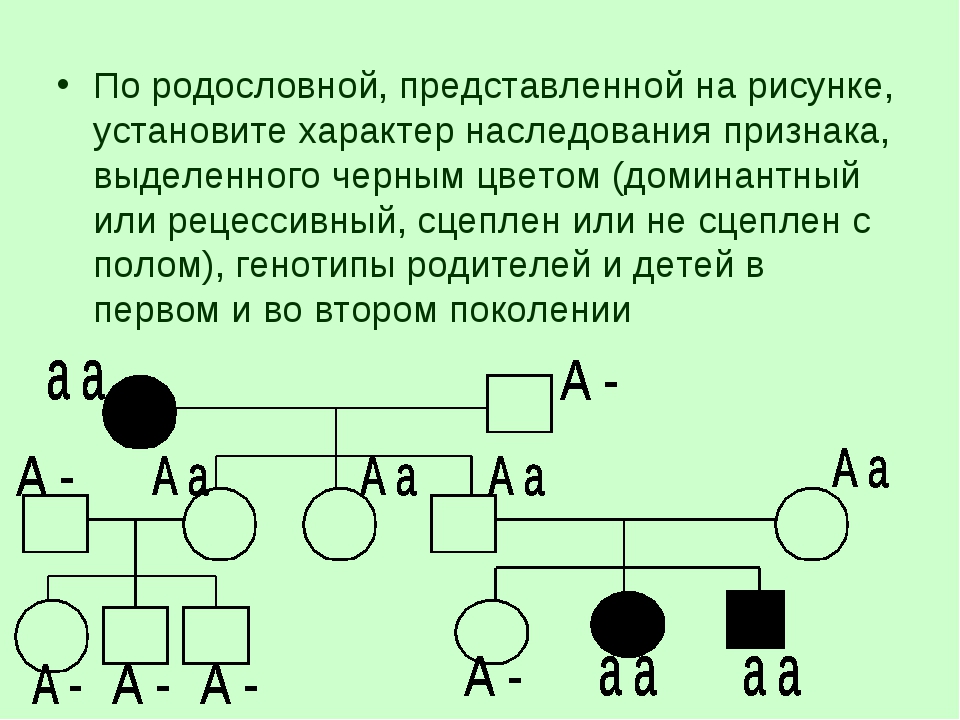 Разделившись около 400 тысяч лет назад, эти виды так и не стали полностью изолированы друг от друга. Денисовцы передали часть своей ДНК и современному человечеству: некоторые этнические группы Океании несут до нескольких процентов денисовских генов.
Разделившись около 400 тысяч лет назад, эти виды так и не стали полностью изолированы друг от друга. Денисовцы передали часть своей ДНК и современному человечеству: некоторые этнические группы Океании несут до нескольких процентов денисовских генов.
Неандертальцы, жившие на Алтае, передали соседям-денисовцам как минимум полпроцента генов. Денисовцы, как было показано ранее, могли унаследовать от некоторого неизвестного вида до восьми процентов своих генов. Кроме того, на сегодняшний день в распоряжении ученых имеются данные о том, что неандертальцы скрещивались и с покинувшими пределы Африки кроманьонцами, Homo sapiens. По современным представлениям, только жители Африки могут называть себя чистокровными представителями вида «человек разумный» — азиаты и европейцы, наряду с народами Америки или Океании, являются метисами, потомками как кроманьонцев, так и неандертальцев с денисовцами.
границ | Геномная селекция с использованием родословной и взаимодействия маркеров с окружающей средой для определения качественных признаков семян ячменя из двух программ коммерческой селекции
Введение
За последние два десятилетия программы селекции растений продвинулись от традиционных подходов, включающих визуальный отбор и проверку признаков на протяжении нескольких поколений, до потенциально более быстрых методов с помощью маркерных технологий (Crossa et al. , 2017). Геномный отбор, концепция использования плотных молекулярных данных всего генома для прогнозирования продуктивности особей в племенной популяции (Meuwissen et al., 2001), в последние годы стала более популярной в селекции зерновых культур. Эмпирические исследования на ячмене (Zhong et al., 2009; Sallam et al., 2015; Nielsen et al., 2016; Thorwarth et al., 2017), пшенице ( Triticum aestivum ; Crossa et al., 2010; Dong et al., al., 2018; Haile et al., 2018; Norman et al., 2018), кукуруза ( Zea mays ; Zhao et al., 2012; Shikha et al., 2017; Vélez-Torres et al., 2018) , рис ( Oryza sativa ; Spindel et al., 2015; Xu et al., 2018) и сорго ( Sorghum bicolor ; De Oliveira et al., 2018; Hunt et al., 2018) недавно доказали, что благодаря текущим достижениям в разработке технологий маркеров ДНК на основе массивов высокой плотности и снижению затрат геномный отбор стал важным инструментом в селекции зерновых.
, 2017). Геномный отбор, концепция использования плотных молекулярных данных всего генома для прогнозирования продуктивности особей в племенной популяции (Meuwissen et al., 2001), в последние годы стала более популярной в селекции зерновых культур. Эмпирические исследования на ячмене (Zhong et al., 2009; Sallam et al., 2015; Nielsen et al., 2016; Thorwarth et al., 2017), пшенице ( Triticum aestivum ; Crossa et al., 2010; Dong et al., al., 2018; Haile et al., 2018; Norman et al., 2018), кукуруза ( Zea mays ; Zhao et al., 2012; Shikha et al., 2017; Vélez-Torres et al., 2018) , рис ( Oryza sativa ; Spindel et al., 2015; Xu et al., 2018) и сорго ( Sorghum bicolor ; De Oliveira et al., 2018; Hunt et al., 2018) недавно доказали, что благодаря текущим достижениям в разработке технологий маркеров ДНК на основе массивов высокой плотности и снижению затрат геномный отбор стал важным инструментом в селекции зерновых.
Модели прогнозирования, в которых используются реализованные взаимосвязи на основе информации маркеров, приводят к существенному увеличению точности прогнозирования сложных признаков по сравнению с моделями, использующими взаимосвязи, основанные на информации о родословной (VanRaden et al. , 2009), и это наблюдалось в нескольких случаях геномной селекции. исследования (Crossa et al., 2010; Альбрехт и др., 2011; Burgueño et al., 2012). Предполагается, что с помощью связанной матрицы, основанной на маркерах, можно учесть менделевскую сегрегацию аллелей наряду с полными братьями и сестрами, которые более или менее ожидаются из-за случайности. Следовательно, в то время как племенная ценность нефенотипированных линий будет отражать только генетический вклад среднего родителя, геномно оцененная селекционная ценность нефенотипированных полных сибсов будет отражать генетические различия, вызванные менделевской выборкой (Velazco et al., 2019).
, 2009), и это наблюдалось в нескольких случаях геномной селекции. исследования (Crossa et al., 2010; Альбрехт и др., 2011; Burgueño et al., 2012). Предполагается, что с помощью связанной матрицы, основанной на маркерах, можно учесть менделевскую сегрегацию аллелей наряду с полными братьями и сестрами, которые более или менее ожидаются из-за случайности. Следовательно, в то время как племенная ценность нефенотипированных линий будет отражать только генетический вклад среднего родителя, геномно оцененная селекционная ценность нефенотипированных полных сибсов будет отражать генетические различия, вызванные менделевской выборкой (Velazco et al., 2019).
Другие исследователи получили менее убедительные результаты, которые показывают, что в некоторых случаях родословные отношения могут работать так же или даже лучше, чем отношения на основе маркеров с точки зрения точности прогнозов (Juliana et al., 2017; Hunt et al., 2018). Это особенно верно, когда данные по родословной очень точны и включают несколько поколений (Juliana et al. , 2017). В многочисленных исследованиях также сообщалось о преимуществах совместного использования взаимосвязей на основе маркеров и родословных в моделях прогнозирования (Crossa et al., 2010; Альбрехт и др., 2011; Burgueño et al., 2012; Родригес-Рамило и др., 2014; Сукумаран и др., 2017). Включение как маркера, так и родословной может повысить эффективность прогнозирования, поскольку информация о родословной может учитывать вариации, которые не могут быть зафиксированы маркерами на уровне популяции и семьи. Следовательно, они обеспечивают более точные оценки генетических вариаций, тем самым улучшая прогностическую эффективность (Velazco et al., 2019). Тем не менее, также было продемонстрировано, что при наличии высококачественных полногеномных маркеров и данных родословной не всегда ожидается, что комбинация маркерной и родословной информации превзойдет использование только маркерной информации в смешанных моделях из-за информационной матрицы. избыточность (Альбрехт и др., 2011).
, 2017). В многочисленных исследованиях также сообщалось о преимуществах совместного использования взаимосвязей на основе маркеров и родословных в моделях прогнозирования (Crossa et al., 2010; Альбрехт и др., 2011; Burgueño et al., 2012; Родригес-Рамило и др., 2014; Сукумаран и др., 2017). Включение как маркера, так и родословной может повысить эффективность прогнозирования, поскольку информация о родословной может учитывать вариации, которые не могут быть зафиксированы маркерами на уровне популяции и семьи. Следовательно, они обеспечивают более точные оценки генетических вариаций, тем самым улучшая прогностическую эффективность (Velazco et al., 2019). Тем не менее, также было продемонстрировано, что при наличии высококачественных полногеномных маркеров и данных родословной не всегда ожидается, что комбинация маркерной и родословной информации превзойдет использование только маркерной информации в смешанных моделях из-за информационной матрицы. избыточность (Альбрехт и др., 2011).
В прошлом модели геномного прогнозирования были разработаны, чтобы соответствовать прогнозам для одной среды. Однако в большинстве программ селекции растений испытания в нескольких средах играют решающую роль в оценке линий для определения характеристик стабильности в средах перспективного сорта. Влияние генов на признаки обычно зависит от условий окружающей среды, что приводит к высокому уровню взаимодействий между генотипами и средой (Burgueño et al., 2012). Поэтому модели геномного отбора были расширены, чтобы соответствовать многопользовательским условиям.Было обнаружено, что включение взаимодействий между генотипом и средой (маркер за средой; GxE и родословная за средой; ax) в модели прогнозирования повышает эффективность таких моделей по сравнению с моделями из одной среды (Burgueño et al. , 2012). Кроме того, было показано, что точность прогноза для ячменя повышается при рассмотрении взаимодействия маркеров и маркеров с окружением с использованием наилучшего линейного несмещенного предсказания гребневой регрессии для распространения геномного отбора на несколько сред (Oakey et al., 2016).
Однако в большинстве программ селекции растений испытания в нескольких средах играют решающую роль в оценке линий для определения характеристик стабильности в средах перспективного сорта. Влияние генов на признаки обычно зависит от условий окружающей среды, что приводит к высокому уровню взаимодействий между генотипами и средой (Burgueño et al., 2012). Поэтому модели геномного отбора были расширены, чтобы соответствовать многопользовательским условиям.Было обнаружено, что включение взаимодействий между генотипом и средой (маркер за средой; GxE и родословная за средой; ax) в модели прогнозирования повышает эффективность таких моделей по сравнению с моделями из одной среды (Burgueño et al. , 2012). Кроме того, было показано, что точность прогноза для ячменя повышается при рассмотрении взаимодействия маркеров и маркеров с окружением с использованием наилучшего линейного несмещенного предсказания гребневой регрессии для распространения геномного отбора на несколько сред (Oakey et al., 2016).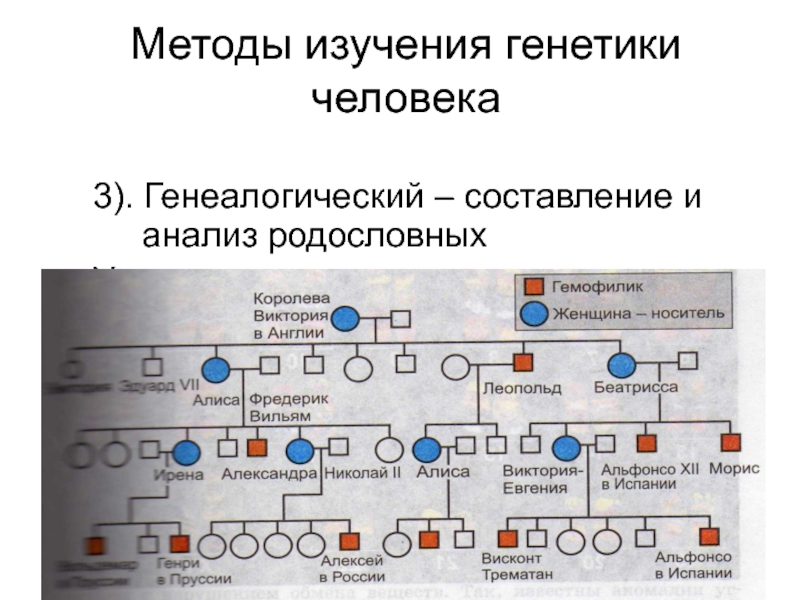 Однако, когда задействованы многомерные генетические переменные и переменные среды, моделирование всех возможных взаимодействий становится проблемой. Другие исследования (Jarquín et al., 2014; Pérez-Rodríguez et al., 2015) также показали, что включение взаимодействий между генетической информацией и окружающей средой значительно повысило точность прогнозов. В аналогичных исследованиях взаимодействие между генетической информацией, основанной как на родословной, так и на маркере, а также на 18 переменных окружающей среды, повысило предсказательную способность (Sukumaran et al., 2017).
Однако, когда задействованы многомерные генетические переменные и переменные среды, моделирование всех возможных взаимодействий становится проблемой. Другие исследования (Jarquín et al., 2014; Pérez-Rodríguez et al., 2015) также показали, что включение взаимодействий между генетической информацией и окружающей средой значительно повысило точность прогнозов. В аналогичных исследованиях взаимодействие между генетической информацией, основанной как на родословной, так и на маркере, а также на 18 переменных окружающей среды, повысило предсказательную способность (Sukumaran et al., 2017).
В настоящем исследовании оценивалась эффективность моделей прогнозирования по четырем признакам качества семян озимого ячменя от двух селекционных компаний в Дании: Nordic Seed (далее NS) и Sejet Plant Breeding (далее SJ). В частности, в этом исследовании: (i) оценивалось индивидуальное и комбинированное влияние маркерных и родословных данных на способность к прогнозированию при различных схемах перекрестной проверки, (ii) определялось генетическое (маркер и родословная) и влияние взаимодействия с окружающей средой на способность прогнозирования при различных перекрестных проверках. схемы проверки и (iii) оценили преимущество увеличения размера обучающей выборки путем комбинирования линий из разных программ разведения.
схемы проверки и (iii) оценили преимущество увеличения размера обучающей выборки путем комбинирования линий из разных программ разведения.
Материалы и методы
Фенотипические данные
Данные были предоставлены двумя коммерческими племенными компаниями в Дании: NS и SJ (Таблица дополнительных материалов 1: «Фенотипические данные»). Записи о ячменях (всего 1850) были получены от 484 коммерческих элитных двухрядных линий озимого ячменя от NS и оценивались в течение 3 лет (2015, 2016 и 2017) в трех местах в Дании. Все три локации были одинаковыми в течение 3 лет. Данные SJ состояли из 964 записей по 428 линиям, фенотипированных по содержанию белка и тестовой массе.Рекорды веса фракции семян для SJ были измерены в Департаменте наук о растениях и окружающей среде Копенгагенского университета, Дания. 428 линий от SJ также были выращены за 3 года (2015, 2016 и 2017) в двух местах в Дании (за исключением 2016 года, когда линии оценивались только в одном месте).
В каждом месте в племенных компаниях линии выращивали в индивидуальных экспериментах, состоящих из 5-20 небольших испытаний, при этом количество линий в каждом испытании варьировалось от 25 до 30. В каждом эксперименте в качестве проверок использовали от двух до шести строк. Каждое испытание представляло собой рандомизированный блочный дизайн с тремя повторами на каждую строку. Управление экспериментами было одинаковым для всех мест внутри конкретных племенных компаний. Из-за этого существует вероятность различий в методах управления, наблюдаемых в разных программах разведения.
В каждом эксперименте в качестве проверок использовали от двух до шести строк. Каждое испытание представляло собой рандомизированный блочный дизайн с тремя повторами на каждую строку. Управление экспериментами было одинаковым для всех мест внутри конкретных племенных компаний. Из-за этого существует вероятность различий в методах управления, наблюдаемых в разных программах разведения.
Пять линий были общими между двумя компаниями. Всего в анализе было использовано 2814 записей из 907 строк. В среднем было 14 различных сред (компания-год-местоположения).Количество наблюдений, записанных в каждой среде, представлено в Таблице 1. Каждая запись линии была фенотипирована по содержанию белка (% сухого вещества), тестовой массе (кг / гл), процентной массе фракций семян диаметром более 2,5 мм (далее именуемые как SF_abv2.5), и фракции семян диаметром более 2,2 мм (далее SF_abv2.2). Содержание белка и тестовый вес измеряли с помощью прибора FOSS Grain Analyzer, основанного на технологии передачи в ближнем инфракрасном диапазоне. Фракции семян были получены с использованием прибора для скрининга SORTIMAT для разделения образцов семян приблизительно 100 г на четыре класса размера семян> 2.8, 2,8–2,5, 2,5–2,2 и <2,2 мм в диаметре. Классы крупности семян были разделены на два основных класса: семена диаметром более 2,5 мм (классы> 2,8 и 2,8–2,5 мм) и классы диаметром более 2,2 мм (классы> 2,8, 2,8–2,5 и 2,5–2,2). Их процентные веса были рассчитаны и использованы в анализе.
Фракции семян были получены с использованием прибора для скрининга SORTIMAT для разделения образцов семян приблизительно 100 г на четыре класса размера семян> 2.8, 2,8–2,5, 2,5–2,2 и <2,2 мм в диаметре. Классы крупности семян были разделены на два основных класса: семена диаметром более 2,5 мм (классы> 2,8 и 2,8–2,5 мм) и классы диаметром более 2,2 мм (классы> 2,8, 2,8–2,5 и 2,5–2,2). Их процентные веса были рассчитаны и использованы в анализе.
Таблица 1. Описание среды и количество наблюдений в каждой среде.
Информация о генотипе
линий от обеих компаний были генотипированы с помощью чипа 9K iSelect с однонуклеотидным полиморфизмом (SNP) от TraitGenetics.Фильтрация мономорфных сайтов и более чем 10% отсутствующих маркеров уменьшила количество маркеров SNP до 4830 для анализа (таблица дополнительных материалов 1: «Генотипические данные»). Оставшиеся отсутствующие SNP были импортированы с помощью «синбридинга» с использованием «случайного» алгоритма, при котором недостающие значения для маркера были взяты из маргинального распределения аллелей этого маркера (Wimmer et al. , 2012). Была вычислена реализованная матрица геномных отношений на основе информации о маркерах (VanRaden, 2008).
, 2012). Была вычислена реализованная матрица геномных отношений на основе информации о маркерах (VanRaden, 2008).
Информация о родословной
Для анализа предоставлена племенная информация по всем линиям.Информация о родословной 484 линий в данных NS расширена до пяти поколений. Всего он включал 80 подсемейств, с количеством потомков на подсемейство (полные братья и сестры) от 2 до 24, и 19 строк, представляющих отдельные скрещивания (Таблица дополнительных материалов 1: «Данные Родословной матрицы_NS»). Информация о родословной для всех 428 линий от SJ до семи поколений включала в общей сложности 106 подсемейств (Таблица дополнительных материалов 1: «Данные Matrix_SJ родословной»). Число потомков на подсемейство варьировало от 2 до 13 полных братьев и сестер, с 67 линиями с отдельными скрещиваниями (без братьев и сестер).Это показывает, что хотя количество подсемейств в NS было небольшим по сравнению с SJ, единицы подсемейства в NS имели больше братьев и сестер, чем SJ.
Статистические модели
Данные были проанализированы с использованием смешанных линейных моделей, в которых основное влияние линий, окружающей среды, маркеров, родословной и их взаимодействия с окружающей средой моделировалось с использованием случайных ковариационных структур. Поскольку использовались данные о линиях, маркерах и информации о родословной, линия была включена в качестве основного эффекта во все модели, чтобы разделить компоненты дисперсии на аддитивные (маркер и родословная) и неаддитивные (остаточные генетические) эффекты.Анализируемые характеристики качества семян включали содержание белка, тестовую массу и вес двух фракций семян. Ниже приводится краткое описание моделей, использованных для оценки.
Модель 1: ELG
В этой модели была использована линейная смешанная модель, которая учитывает основные эффекты окружающей среды, линейные эффекты и эффекты маркеров, как показано ниже:
yij = μ + Ei + Lj + gj + εij (1)
, где y ij , — фенотип, μ — пересечение, E i — случайный эффект среды i -й (компания-год-местоположение), L j — это случайный эффект строки j , а ε ij — остаточная ошибка. g j — случайная «геномная селекционная ценность» j -й линии. Это учитывает основанные на маркерах отношения линий, следуя многомерной нормальной плотности, с нулевым средним и ковариационной матрицей Cov (g) = Gσg2, где G — реализованная матрица геномных отношений, полученная по формуле ВанРадена X X′2∑pm (1-pm) (VanRaden, 2008), где X — центрированная и стандартизованная матрица маркеров, p m — частота аллеля m -го маркера. , σg2 — генетическая дисперсия маркера.Все другие случайные эффекты в вышеупомянутой модели подчиняются нормальным независимым и идентичным распределениям, так что Ei∼N (0, IσE2), Lj∼N (0, IσL2) и εij∼N (0 , Iσε2).
g j — случайная «геномная селекционная ценность» j -й линии. Это учитывает основанные на маркерах отношения линий, следуя многомерной нормальной плотности, с нулевым средним и ковариационной матрицей Cov (g) = Gσg2, где G — реализованная матрица геномных отношений, полученная по формуле ВанРадена X X′2∑pm (1-pm) (VanRaden, 2008), где X — центрированная и стандартизованная матрица маркеров, p m — частота аллеля m -го маркера. , σg2 — генетическая дисперсия маркера.Все другие случайные эффекты в вышеупомянутой модели подчиняются нормальным независимым и идентичным распределениям, так что Ei∼N (0, IσE2), Lj∼N (0, IσL2) и εij∼N (0 , Iσε2).
Модель 2: ELG-GxE
Эта модель была получена путем расширения модели 1 путем включения взаимодействия между случайными эффектами маркеров и окружающей среды, так что модель учитывает основные эффекты окружающей среды, основные эффекты линий, основные эффекты маркеров. , и взаимодействия между маркерами и окружающей средой.Термин взаимодействия включен как произведение Адамара двух ковариационных структур ( E i и g j ), описывающих отношения между средами и линиями на основе информации маркера. Модель 2 обозначается как:
, и взаимодействия между маркерами и окружающей средой.Термин взаимодействия включен как произведение Адамара двух ковариационных структур ( E i и g j ), описывающих отношения между средами и линиями на основе информации маркера. Модель 2 обозначается как:
yij = μ + Ei + Lj + gj + gEij + εij (2)
, где gE ij — это взаимодействие между строкой j -й на основе данных маркера в среде i -й.Остальные компоненты модели определены ранее. Предполагается, что случайный вектор, содержащий член взаимодействия, следует многомерному нормальному распределению gEij∼N (0, [ZgGZg ′] [ZEZE ′] ∘σgE2), где Z g — матрица инцидентности. для вектора маркерных эффектов Z E — матрица инцидентности эффектов окружающей среды, σgE2 — дисперсия члена взаимодействия gE ij , а ° — ячейка-по -элемент или произведение Адамара между двумя матрицами.
Модель 3: ELA
Модель 3 была получена путем замены случайного эффекта ковариаты маркера в модели 1 на случайную аддитивную взаимосвязь линий на основе информации о родословной ( a ). Модель 3 представлена как:
yij = μ + Ei + Lj + aj + εij (3)
, где a j — случайный аддитивный эффект j -й строки с ковариационной структурой, основанной на родословных отношениях между строками, так что a j следует многомерной нормали плотность с нулевым средним и ковариационной матрицей Cov (a) = Aσa2, где A — это аддитивная матрица родовых отношений, а σa2 — генетическая вариация родословных.
Модель 4: ELA-ax
Модель 4 была получена путем добавления взаимодействия между линиями на основе информации об их родословной ( a ) и окружающей среды ( E ) в модель 3. Как и в модели 2, взаимодействие было включено как произведение Адамара ковариации. структуры для E i и a j и, таким образом, представлены как:
структуры для E i и a j и, таким образом, представлены как:
yij = μ + Ei + Lj + aj + aEij + εij (4)
, где aE ij — член взаимодействия между строкой j на основе информации о родословной в среде i , которая, как предполагается, следует многомерному нормальному распределению в форме aEij∼N (0 , [ZaAZa ′] [ZEZE ′] ∘σaE2). Z a — матрица инцидентности для вектора родовых эффектов, а σaE2 — дисперсия члена взаимодействия a E i j .
Модель 5: ELGA
Эта модель была получена путем объединения компонентов модели 1 и модели 3, так что модель учитывает случайные эффекты окружающей среды ( E ), линий ( L ), маркера ( g ) и родословной ( а ).Модель 5 представлена как:
yij = μ + Ei + Lj + gj + aj + εij (5)
, где все условия данной модели соответствуют описанию ранее.
Модель 6: ELGA-GxE-ax
Модель 6 — это буквально комбинация компонентов моделей с 1 по 5, что делает ее наиболее полной моделью. Со всеми ранее определенными терминами модель выражается как.
yij = μ + Ei + Lj + gj + aj + gEij + aEij + εij (6)
Все вышеперечисленные модели были установлены в R с использованием пакета байесовской обобщенной линейной регрессии (BGLR) (Перес и де лос Кампос, 2014; де лос Кампос и Перес-Родригес, 2018).
Оценка эффективности прогнозирования для различных стратегий перекрестной проверки
Геномные модели прогнозирования изначально были оснащены данными от каждой компании и объединенным набором данных для оценки компонентов дисперсии для каждой модели. Чтобы оценить эффективность всех моделей для каждой программы разведения в отдельности, были реализованы три схемы перекрестной проверки.
(i) CV1: случайная 10-кратная перекрестная проверка. Эта схема имитирует проблему селекции, заключающуюся в прогнозировании продуктивности вновь созданных линий, которые еще не наблюдались в какой-либо среде (Jarquín et al. определяется применительно к конкретной используемой модели. Регистрировали стандартную ошибку от среднего 10-кратных корреляций.
определяется применительно к конкретной используемой модели. Регистрировали стандартную ошибку от среднего 10-кратных корреляций.
(ii) CV0: Прогнозирование ненаблюдаемого нового года. Эта схема позволяет прогнозировать урожайность всех линий в ненаблюдаемый (будущий) год. Эта схема, также называемая упреждающим прогнозом или выходом на один год, позволяет прогнозировать условия окружающей среды в данном году с использованием всех сред прошлых лет. В этом исследовании данные за 2015 и 2016 годы были объединены для формирования обучающего набора, а 2017 год использовался в качестве набора для проверки.Для прогнозирования с данными SJ их было 303 и 125 в наборах для обучения и проверки, соответственно, в то время как для NS было 317 и 167 строк в наборах для обучения и проверки, соответственно. Эта схема представляет собой более реалистичную проблему, с которой часто сталкиваются селекционеры, которая связана с годами отсутствия наблюдения. Успех этой стратегии зависит не только от количества связанных линий в наборах для обучения и проверки, но в основном от корреляции между условиями окружающей среды в ненаблюдаемые годы и в предыдущие годы (Jarquín et al. , 2017).
, 2017).
(iii) CV00: Прогнозирование новых разработок в новом году. Эта схема направлена на прогнозирование производительности всех новых линий в будущем году. Эта схема похожа на CV0, однако предсказываемые линии никогда ранее не наблюдались. Эта схема применяется к ситуациям разведения, когда большая часть материалов не наблюдалась на предыдущих полях, но их производительность необходимо оценить на следующий год (Jarquín et al., 2017; Howard et al., 2019). Здесь строки, которые были оценены только в 2017 году, но не в какой-либо из предыдущих лет, использовались в качестве набора для проверки, а остальные использовались как набор для обучения.Для прогнозов SJ было 348 и 80 строк в наборах для обучения и проверки, соответственно, в то время как для NS было 374 и 110 строк в наборах для обучения и проверки, соответственно.
В CV0 и CV00 процедура не включала случайное разбиение и, следовательно, реализовывалась один раз. Способность к предсказанию оценивалась как корреляция между предсказанными значениями и наблюдаемыми фенотипическими значениями. Прогнозы с использованием данных индивидуальных программ разведения назывались внутрикорпоративными прогнозами.
Прогнозы с использованием данных индивидуальных программ разведения назывались внутрикорпоративными прогнозами.
Впоследствии мы оценили эффект объединения разных популяций, происходящих из разных программ, для увеличения размера обучающей популяции для прогнозирования. Мы назвали эти сценарии прогнозами внутри компании, а сценарии, в которых используются данные, относящиеся к различным программам разведения, — прогнозами внутри компании. В прогнозах для всей компании данные обеих программ разведения были объединены, и линии были случайным образом разделены на десять частей. Сгибы были созданы таким образом, что девять из них содержат строки от обеих компаний, а оставшаяся сгиб содержит либо (i) только строки из SJ в качестве набора проверки, либо (ii) только строки из NS как набор проверки.Все ранее обсуждавшиеся модели были изменены путем включения программы разведения в качестве фиксированного эффекта в прогнозы для всей компании. Прогнозы, полученные на основе этого подхода, сравнивались с прогнозами, полученными в CV1 внутрифирменных прогнозов, описанных выше.
Оценка наследуемости по несбалансированным данным
Наследственность в широком смысле ( H 2 ) и в узком смысле ( h 2 ) оценивалась, соответственно, как:
h3 = σL2 + σg2 + σa2σy2andh3 = σg2 + σa2σy2 (7)
, где фенотипическая дисперсия рассчитывалась как σy2 = σg2 + σa2 + (σgE2 / mh) + (σaE2 / mh) + (σR2 / ph).Для моделей, содержащих только отношения маркеров, использовалось значение σa2 = 0, а для моделей, содержащих только родословные отношения, использовалось значение σg2 = 0. Кроме того, значения σgE2 = 0 и σaE2 = 0 использовались для моделей без взаимодействия с окружающей средой. Учитывая, что анализ был основан на несбалансированных данных, уравнение было выполнено с определением mh = n∑i = 1n1mi и ph = n∑i = 1n1pi, где n — количество генотипов, m i — это количество сред для каждого генотипа, а p i — количество участков по средам для каждого генотипа (Holland et al.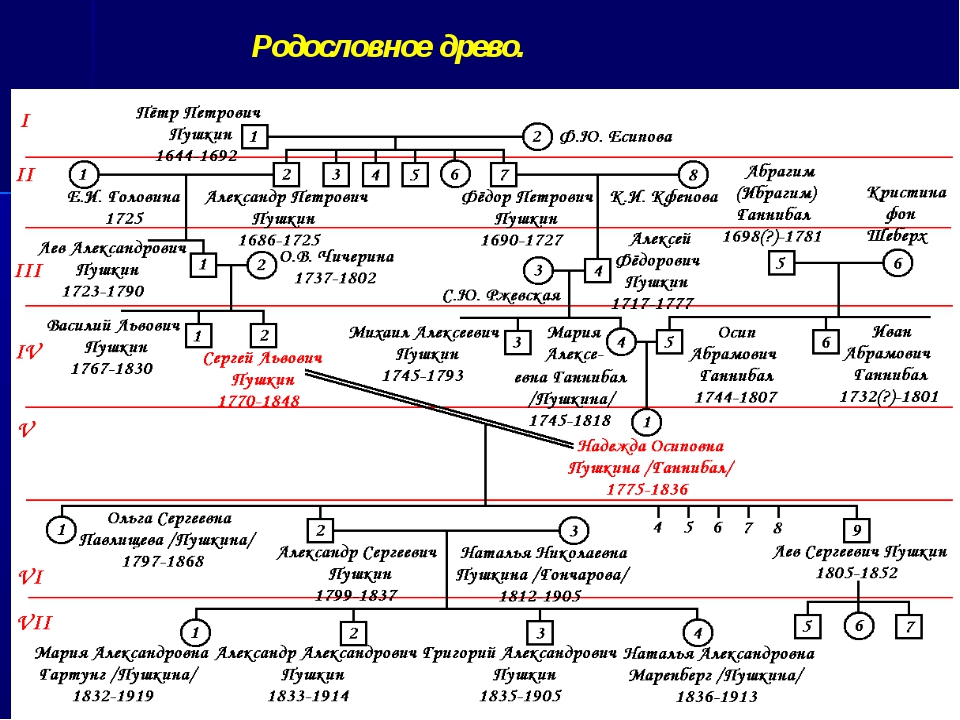 , 2003).
, 2003).
Результаты
Описательная статистика
Линии, использованные в этом исследовании, были получены в результате активных программ селекции ячменя, проводимых двумя селекционными компаниями. В каждой племенной компании линии выращивались от одного до трех мест в течение трех лет, включая в общей сложности 14 сред (комбинации компания-год-местоположение), при этом NS — девять сред, а SJ — пять сред. В таблице 2 дано краткое описание соответствующих признаков. В целом, среднее содержание белка было 10.48% (SD = 0,83), а NS и SJ составили 10,54% (SD = 0,69) и 10,36% (SD = 1,04), соответственно. Оценки среднего и стандартного отклонения остальных признаков, приведенные в таблице, показывают, что фракция семян SF_abv2.5 была наиболее изменчивой, за ней следовал белок, а наименьшей переменной была фракция семян SF_abv2.2.
Таблица 2. Краткое описание признаков для общих данных и по племенной компании.
На рис. 1 представлена диаграмма всех характеристик, проанализированных для каждой из 14 сред в исследовании. За исключением содержания белка, все признаки показали более высокие значения в 2015 году, чем в 2017 году для обеих племенных компаний. Что касается протеина и тестового веса, то различия в окружающей среде, по-видимому, зависят как от года, так и от местоположения, тогда как для фракций семян они в большей степени зависят от года в обеих селекционных компаниях. Коробчатая диаграмма показывает значительное влияние окружающей среды на все признаки. Анализ дисперсии 14 сред показывает значения F 510, 443, 260 и 163 для белка, тестовой массы, SF_abv2.5 и SF_abv2.2 соответственно.
За исключением содержания белка, все признаки показали более высокие значения в 2015 году, чем в 2017 году для обеих племенных компаний. Что касается протеина и тестового веса, то различия в окружающей среде, по-видимому, зависят как от года, так и от местоположения, тогда как для фракций семян они в большей степени зависят от года в обеих селекционных компаниях. Коробчатая диаграмма показывает значительное влияние окружающей среды на все признаки. Анализ дисперсии 14 сред показывает значения F 510, 443, 260 и 163 для белка, тестовой массы, SF_abv2.5 и SF_abv2.2 соответственно.
Рис. 1. Коробчатая диаграмма распределения признаков качества семян среди 14 сред (компания-год-местоположение). (A) Содержание белка, (B) пробная масса, (C) фракция семян SF_abv2.5; и (D) затравочная фракция SF_abv2.2.
Связь между строками
Степень родства линий на основе информации на основе родословной и на основе маркеров изображена на тепловых картах на Рисунке 2. Значения матрицы родословных родословных выводятся из вероятности идентичности по происхождению (IBD), и поэтому значения находятся между нулем и единицей. Нулевые значения означают отсутствие связи, а единица — идентичную взаимосвязь. В отличие от матрицы на основе родословной, значения матрицы маркеров состоят из отрицательных и положительных значений. Отрицательные отношения объясняются центрированием ковариат маркера, приводящим к центрированию всей матрицы на основе маркеров, так что сумма всех элементов в матрице равна нулю.Отрицательные значения в матрице взаимосвязей на основе маркеров означают, что обнаружение аллеля в одной строке снижает вероятность его обнаружения в другой строке, ноль означает отсутствие зависимости, а положительные значения указывают на повышенную вероятность обнаружения аллеля в другая линия.
Значения матрицы родословных родословных выводятся из вероятности идентичности по происхождению (IBD), и поэтому значения находятся между нулем и единицей. Нулевые значения означают отсутствие связи, а единица — идентичную взаимосвязь. В отличие от матрицы на основе родословной, значения матрицы маркеров состоят из отрицательных и положительных значений. Отрицательные отношения объясняются центрированием ковариат маркера, приводящим к центрированию всей матрицы на основе маркеров, так что сумма всех элементов в матрице равна нулю.Отрицательные значения в матрице взаимосвязей на основе маркеров означают, что обнаружение аллеля в одной строке снижает вероятность его обнаружения в другой строке, ноль означает отсутствие зависимости, а положительные значения указывают на повышенную вероятность обнаружения аллеля в другая линия.
Рис. 2. Тепловая карта матриц отношений маркеров (слева) и родословных (справа) для Nordic Seed (NS), Sejet (SJ) и комбинированных данных. (A) данные NS, (B) данные SJ и (C) объединенные данные.
(A) данные NS, (B) данные SJ и (C) объединенные данные.
Родословная тепловая карта показывает меньше групп из-за допущений о ВЗК, которые позволяют полным братьям и сестрам, полученным от одного и того же скрещивания, быть похожими. Однако тепловая карта маркера показывает гораздо больше группировок. Этого следовало ожидать, потому что матрица маркеров учитывает менделевскую сегрегацию аллелей, так что можно выделить полных братьев и сестер, более или менее ожидаемых из-за случайной выборки. Тепловые карты обеих матриц показали более тесную взаимосвязь между линиями NS (Рисунок 2A), чем линии SJ (Рисунок 2B), что очевидно из большей плотности синих и желтых оттенков на тепловых картах NS по сравнению с SJ.Более того, масса линий SJ при нуле (отсутствие зависимости), как показано на графике плотности цветных ключей для матрицы маркеров, была выше, чем масса линий NS, что указывает на более высокую степень родства линий NS по сравнению с линиями SJ.
Оценка компонента отклонения
Сводная информация о компонентах дисперсии для исследуемых признаков, оцененных по всем шести моделям с использованием объединенных данных и данных по отдельным компаниям, представлена в таблицах 3A – C, соответственно. Основные эффекты окружающей среды последовательно объясняют большую часть общей дисперсии всех черт.Используя только данные SJ, средовая дисперсия ( E ) объясняется между 42% (в модели SF_abv2.2 ELGA-GxE-ax ) и 81% (в модели белка ELG ) примерно от общей дисперсии (Таблица 3B) . Дисперсия окружающей среды объяснена между 36% (в SF_abv2.2 для модели ELA-ax ) и 63% (в модели ELG белка ) приблизительно от общей дисперсии с использованием данных NS (Таблица 3C). Из-за большой доли дисперсии, объясняемой средой в различных моделях, был оценен пропорциональный вклад каждого из случайных эффектов в общую фенотипическую (внутрисредовую) дисперсию, как предложено в литературе (Jarquín et al.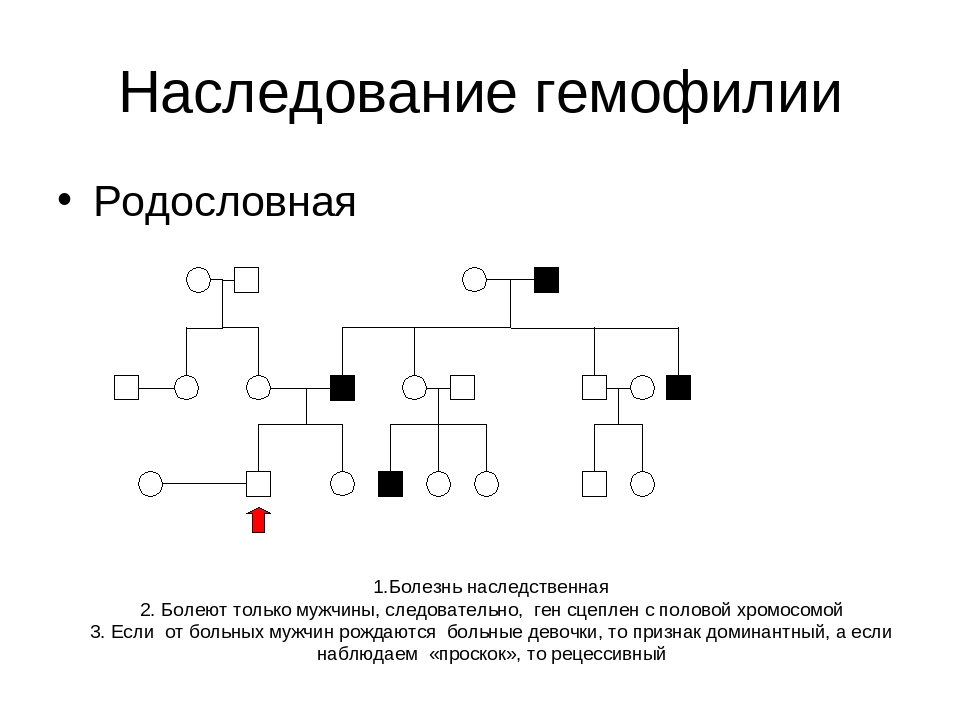 , 2014; Перес-Родригес и др., 2015).
, 2014; Перес-Родригес и др., 2015).
Таблица 3A Компоненты отклонения и процентное отклонение внутри среды для случайных эффектов в моделях с комбинированными данными.
ТАБЛИЦА 3B Компоненты отклонения и процентное отклонение внутри среды для случайных эффектов в моделях с данными SJ.
ТАБЛИЦА 3C Компоненты отклонения и процентное отклонение внутри среды для случайных эффектов в моделях с данными NS.
В зависимости от модели и признака, линии объясняют от 8% до 19% (с данными SJ) и от 8,5 до 28% (с данными NS) отклонения внутри среды. Информация о маркерах объясняется от 12,9 до 34,7% дисперсии внутри среды, в то время как информация о родословной объясняется от 12,8 до 44,5% (для данных SJ) и в зависимости от признака и включения (или отсутствия) эффектов взаимодействия. С другой стороны, с данными NS, информация о маркерах объяснена между 15,4 и 43,8%, а информация о родословной — между 13 и 49. 5% отклонения внутри среды.
5% отклонения внутри среды.
Произошло уменьшение оценочной дисперсии ошибок внутри среды ( R ), когда условия взаимодействия были включены в модели основных эффектов для всех характеристик. Принимая во внимание белок в данных SJ, включение условий взаимодействия GxE и ax в модели ELG и ELA привело к снижению примерно на 10% и 8,7% в оценочной остаточной дисперсии, соответственно. Наибольшее снижение остаточной дисперсии (14.7%) за счет эффектов взаимодействия наблюдалось в наиболее полной модели. Аналогичная тенденция наблюдалась и для всех остальных признаков в данных SJ и NS. Однако процент общей дисперсии, объясняемой эффектом взаимодействия, у SJ был немного выше, чем у NS. Это указывало на то, что не все фенотипические вариации могут быть полностью уловлены одними только основными эффектами. Существенное уменьшение дисперсии ошибок, связанное с моделями ELG , ELA и ELGA , можно отнести к взаимодействию генетики и окружающей среды, следовательно, необходимо учитывать их в исследовании.
В моделях, которые включали как маркерные, так и родословные эффекты, общая аддитивная генетическая дисперсия была разделена на фракции из-за информации о маркере и родословной (Таблица 4). Были проанализированы как модели основных эффектов, так и модели эффектов взаимодействия. Доля аддитивной дисперсии из-за маркеров и информации о родословной оценивалась как отношение маркерной (геномной) или родословной дисперсии к общей аддитивной дисперсии, соответственно. В объединенных данных большая часть общей аддитивной генетической дисперсии (в среднем 60% по трем признакам) была приписана эффектам маркеров.
Таблица 4. Разделение общей аддитивной генетической дисперсии.
Однако другой сценарий наблюдался, когда данные от разных племенных компаний анализировались отдельно. При усреднении по всем четырем признакам в данных SJ, 53% общей аддитивной генетической дисперсии в модели основного эффекта было приписано родословным отношениям между линиями. Однако в данных NS более половины общей аддитивной генетической дисперсии по всем признакам, за исключением белка, в модели основного эффекта было отнесено на счет геномных / маркерных отношений между линиями.Сценарии, наблюдаемые с моделями взаимодействия, были аналогичны моделям основных эффектов. Это указывает на то, что как матрицы геномных, так и родословных родственных связей смогли уловить значительные доли аддитивной генетической изменчивости в популяции с относительной важностью геномной и родословной информации, варьирующейся в зависимости от признака и племенной компании, используемой в текущем исследовании.
Однако в данных NS более половины общей аддитивной генетической дисперсии по всем признакам, за исключением белка, в модели основного эффекта было отнесено на счет геномных / маркерных отношений между линиями.Сценарии, наблюдаемые с моделями взаимодействия, были аналогичны моделям основных эффектов. Это указывает на то, что как матрицы геномных, так и родословных родственных связей смогли уловить значительные доли аддитивной генетической изменчивости в популяции с относительной важностью геномной и родословной информации, варьирующейся в зависимости от признака и племенной компании, используемой в текущем исследовании.
Наследственность
Наследуемость в широком смысле и в узком смысле были оценены на основе анализа компонентов дисперсии, причем первый был основан на сумме дисперсии линии и дисперсии родословной и / или маркера.В то время как маркер и родословная отражают истинный аддитивный генетический эффект, линии фиксируют генетический остаточный эффект (Oakey et al. , 2016; Hunt et al., 2018). Для корректировки предсказательной способности при вычислении точности предсказания необходима широкая наследуемость, и они могут быть выведены из оценок компонентов дисперсии (данные не показаны).
, 2016; Hunt et al., 2018). Для корректировки предсказательной способности при вычислении точности предсказания необходима широкая наследуемость, и они могут быть выведены из оценок компонентов дисперсии (данные не показаны).
На рис. 3 показана наследуемость в узком смысле h 2 , основанная на записях отдельных линий, оцененных на основе моделей основных эффектов для всех признаков для отдельных программ разведения.Сравнивались модели, в которых использовались только отношения маркеров, только родословные и комбинированные отношения маркеров и родословных для всех признаков.
Рис. 3. Узкие оценки наследуемости для всех признаков, оцененные с помощью SJ и NS.
В целом, ч 2 в NS было выше, чем в SJ по всем измеренным признакам. В SJ ч 2 было самым высоким для SF_abv2.5, за которым следовали SF_abv2.2, тестовая масса и белок.В NS h 2 было самым высоким для тестового веса, за ним следовали SF_abv2. 5, белок и SF_abv2.2. Как и ожидалось, значение h 2 , отслеженное по информации о родословной, было выше, чем значение, отслеженное с помощью маркерной информации для всех признаков в данных SJ. В целом, ч 2 было уменьшено почти на 29, 19, 20 и 25% для белка, тестовой массы, SF_abv2.5 и SF_abv2.2, соответственно, когда использовалась матрица взаимосвязи маркеров ELG , а не матрица родословных ( ELA ).Также было замечено, что h 2 , отслеженное с помощью комбинированной информации о родословной и маркере, было выше, чем при использовании любой из матриц по отдельности.
5, белок и SF_abv2.2. Как и ожидалось, значение h 2 , отслеженное по информации о родословной, было выше, чем значение, отслеженное с помощью маркерной информации для всех признаков в данных SJ. В целом, ч 2 было уменьшено почти на 29, 19, 20 и 25% для белка, тестовой массы, SF_abv2.5 и SF_abv2.2, соответственно, когда использовалась матрица взаимосвязи маркеров ELG , а не матрица родословных ( ELA ).Также было замечено, что h 2 , отслеженное с помощью комбинированной информации о родословной и маркере, было выше, чем при использовании любой из матриц по отдельности.
В NS, однако, за исключением тестовой массы ч 2 , отслеживаемая только по родословной, была выше, чем только по маркерной информации для белка, SF_abv2.5 и SF_abv2.2. Кроме того, объединение информации о родословной и маркере улучшило h 2 по сравнению с только маркером или информацией о родословной для белка и тестовой массы; однако по семенным фракциям не было никакого выигрыша по сравнению с данными по родословной.
Прогнозы внутри компании с использованием различных перекрестных проверок
Результаты прогнозов для различных схем перекрестной проверки из шести моделей с использованием данных из двух селекционных программ (NS и SJ) отдельно (внутрифирменные прогнозы) для всех признаков представлены на Рисунке 4.
Рис. 4. Предсказательная способность, полученная с использованием шести моделей для трех схем перекрестной проверки в двух программах разведения по всем признакам. CV1; прогнозирование новых разработанных линий в известных средах, CV0; прогнозирование неизвестного (будущего) года и CV00; предсказание вновь созданных линий в неизвестных будущих возможностях предсказания года для (A) Белка, (B) Пробная масса, (C) Фракция семян SF_abv2.5 и (D) Фракция семян SF_abv2.2. Планки погрешностей отображают стандартную ошибку от среднего значения 10-кратной корреляции.
В целом прогнозы во всех схемах перекрестной проверки для NS были лучше, чем в SJ. Например, учитывая белок, средняя предсказательная способность по моделям составила 0,32, 0,12 и 0,14 для CV1, CV0 и CV00, соответственно, для SJ по сравнению с 0,47, 0,17 и 0,13 для CV1, CV0 и CV00, соответственно, в NS. В тестовом весе средние предсказательные способности по моделям были равны 0.50 (CV1), 0,16 (CV0) и 0,21 (CV00) для SJ, но 0,62 (CV1), 0,53 (CV0) и 0,38 (CV00). В SF-abv2.5 прогностическая способность моделей в SJ составляла 0,60. 0,48, 0,37 для CV1, CV0 и CV00 соответственно. Точно так же в SF_abv2.2 средняя прогностическая способность по моделям составляла 0,63, 0,73 и 0,65 для CV1, CV0 и CV00 соответственно в NS.
Например, учитывая белок, средняя предсказательная способность по моделям составила 0,32, 0,12 и 0,14 для CV1, CV0 и CV00, соответственно, для SJ по сравнению с 0,47, 0,17 и 0,13 для CV1, CV0 и CV00, соответственно, в NS. В тестовом весе средние предсказательные способности по моделям были равны 0.50 (CV1), 0,16 (CV0) и 0,21 (CV00) для SJ, но 0,62 (CV1), 0,53 (CV0) и 0,38 (CV00). В SF-abv2.5 прогностическая способность моделей в SJ составляла 0,60. 0,48, 0,37 для CV1, CV0 и CV00 соответственно. Точно так же в SF_abv2.2 средняя прогностическая способность по моделям составляла 0,63, 0,73 и 0,65 для CV1, CV0 и CV00 соответственно в NS.
Прогноз по схеме перекрестной проверки CV1
При прогнозировании недавно разработанных линий в CV1 модели с только информацией о родословной ( ELA ) показали лучшие результаты (данные SJ) или аналогичные (данные NS) модели с только маркерной информацией ( ELG ) по всем признакам.В SJ предсказательная способность для ELG в CV1 составляла 0,27, 0,46, 0,58 и 0,54 для белка, тестового веса, SF_abv2.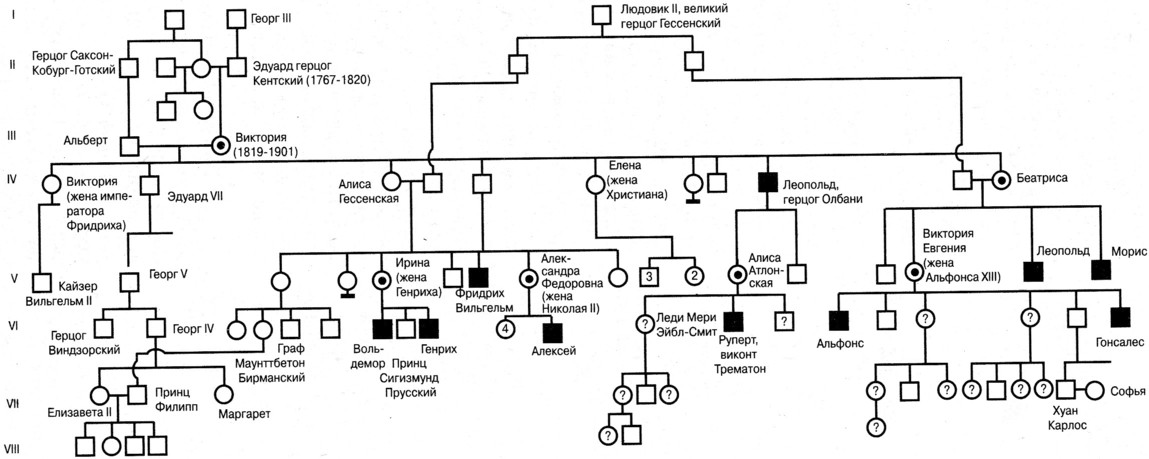 5 и SF_abv2.2, соответственно, в то время как предсказательная способность для ELA в CV1 составляла 0,31, 0,50. , 0,60 и 0,58 для белка, контрольной массы, SF_abv2.5 и SF_abv2.2 соответственно (рисунок 4). С другой стороны, в NS способность предсказания для ELG в CV1 составляла 0,44, 0,60, 0,62 и 0,64 для белка, тестового веса, SF_abv2.5 и SF_abv2.2, соответственно, в то время как способность предсказания для ELA в CV1 была По всем признакам аналогичен ELG .Объединение информации о родословной и маркере ( ELGA ) улучшило способность прогнозирования по сравнению с моделями, использующими только информацию маркера, но не по сравнению с моделями, использующими только информацию о родословной для данных SJ для всех признаков. В NS модели ELGA показали себя аналогично моделям ELG и ELA по всем признакам.
5 и SF_abv2.2, соответственно, в то время как предсказательная способность для ELA в CV1 составляла 0,31, 0,50. , 0,60 и 0,58 для белка, контрольной массы, SF_abv2.5 и SF_abv2.2 соответственно (рисунок 4). С другой стороны, в NS способность предсказания для ELG в CV1 составляла 0,44, 0,60, 0,62 и 0,64 для белка, тестового веса, SF_abv2.5 и SF_abv2.2, соответственно, в то время как способность предсказания для ELA в CV1 была По всем признакам аналогичен ELG .Объединение информации о родословной и маркере ( ELGA ) улучшило способность прогнозирования по сравнению с моделями, использующими только информацию маркера, но не по сравнению с моделями, использующими только информацию о родословной для данных SJ для всех признаков. В NS модели ELGA показали себя аналогично моделям ELG и ELA по всем признакам.
Включение эффектов взаимодействия улучшило прогнозы по сравнению с моделями основных эффектов для всех признаков в схеме CV1 как для SJ, так и для NS. Было обнаружено, что более высокая эффективность прогнозирования за счет включения эффекта взаимодействия с моделями основных эффектов оказалась самой высокой для белка как в SJ, так и в NS. Кроме того, выигрыш в производительности прогнозирования за счет добавления взаимодействия был лучше у SJ, чем у NS по большинству признаков. Например, в SJ GxE улучшил предсказательную способность модели ELG примерно на 26, 9, 4 и 5% для белка, тестового веса, SF_abv2.5 и SF_abv2.2, соответственно, в то время как ax улучшили способность модели ELA на 21, 6, 4 и 6% для белка, тестовая масса, SF_abv2.5 и SF_abv2.2 соответственно. В NS включение GxE в модель ELG увеличило предсказательную способность на 12, 6, 4 и 6%, в то время как ax увеличило предсказательную способность модели ELA на 11, 5, 3 и 5%. для белка — контрольная масса — SF_abv2.5 и SF_abv2.2 соответственно. Таким образом, модели, отражающие взаимодействия, работали лучше, чем соответствующие им модели основных эффектов по всем признакам.
Было обнаружено, что более высокая эффективность прогнозирования за счет включения эффекта взаимодействия с моделями основных эффектов оказалась самой высокой для белка как в SJ, так и в NS. Кроме того, выигрыш в производительности прогнозирования за счет добавления взаимодействия был лучше у SJ, чем у NS по большинству признаков. Например, в SJ GxE улучшил предсказательную способность модели ELG примерно на 26, 9, 4 и 5% для белка, тестового веса, SF_abv2.5 и SF_abv2.2, соответственно, в то время как ax улучшили способность модели ELA на 21, 6, 4 и 6% для белка, тестовая масса, SF_abv2.5 и SF_abv2.2 соответственно. В NS включение GxE в модель ELG увеличило предсказательную способность на 12, 6, 4 и 6%, в то время как ax увеличило предсказательную способность модели ELA на 11, 5, 3 и 5%. для белка — контрольная масса — SF_abv2.5 и SF_abv2.2 соответственно. Таким образом, модели, отражающие взаимодействия, работали лучше, чем соответствующие им модели основных эффектов по всем признакам.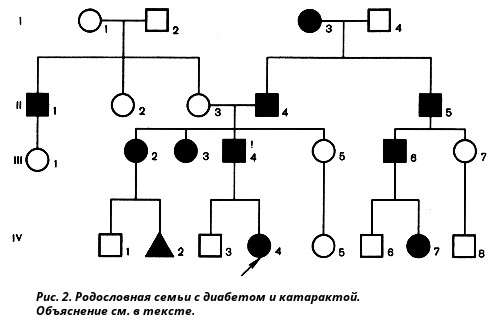
Прогнозирование схем перекрестной проверки CV0 и CV00
Схема прогнозирования производительности линий в будущем году (CV0) и схема прогнозирования производительности новых линий в будущем году (CV00) показали другую картину по сравнению с CVI.По всем признакам как в SJ, так и в NS модели только по маркерам превзошли модели по родословной. Средняя прогностическая способность по содержанию протеина в обеих компаниях составляла 0,19 и 0,21 для моделей маркеров в CV0 и CV00, соответственно, в то время как с родословными моделями; оно составило 0,07 и 0,03 для CV0 и CV00 соответственно. В тестовом весе средняя прогностическая способность для моделей маркеров в обеих программах разведения составляла 0,36 (CV0) и 0,34 (CV00), в то время как средняя прогностическая способность для племенных моделей составляла 0,30 (CV0) и 0.18 (CV00). Аналогичная тенденция наблюдалась и по другим признакам.
В NS, хотя модели ELGA работали лучше, чем модели ELA , не было никакого преимущества в прогностической способности по сравнению с моделями ELG для всех признаков в схемах CV0 и CV00. В SJ, с другой стороны, ELGA всегда работал лучше, чем ELA , но его производительность по сравнению с ELG была непостоянной в зависимости от признака. В отношении белка ELGA показала хуже, чем ELG , тогда как в тестовой массе ELGA показала аналогичные ELG как для CV0, так и для CV00.В SF_abv2.5 и SF_abv2.2 ELGA работал аналогично ELG в CV0, но лучше в CV00.
В SJ, с другой стороны, ELGA всегда работал лучше, чем ELA , но его производительность по сравнению с ELG была непостоянной в зависимости от признака. В отношении белка ELGA показала хуже, чем ELG , тогда как в тестовой массе ELGA показала аналогичные ELG как для CV0, так и для CV00.В SF_abv2.5 и SF_abv2.2 ELGA работал аналогично ELG в CV0, но лучше в CV00.
Интересно, что в CV0 и CV00 включение эффектов взаимодействия не всегда улучшало производительность прогнозирования, как это видно в случае CV1 (таблица 5). В большинстве случаев добавление эффекта взаимодействия в CV0 и CV00 вызывало снижение эффективности прогнозирования. В случаях, когда происходило увеличение из-за взаимодействия, выигрыши всегда были ниже по сравнению с CV1, за некоторыми исключениями в SF_abv2.5 и SF_abv2.2. Например, в SJ процентное изменение предсказательной способности составляло примерно от -158% (CV00 ax ) до 10% (CV00 GxE ), а в CV1 — примерно от 21% ( ax ) до 33% ( GxE-ax ). В NS процентное изменение предсказательной способности из-за взаимодействия варьировалось от примерно 11% ( ax ) до 15% ( GxE-ax ) для содержания белка в CV1 и от -6% (CV00 ax ) до 5. % (CV00 GxE ) для будущих прогнозов.
В NS процентное изменение предсказательной способности из-за взаимодействия варьировалось от примерно 11% ( ax ) до 15% ( GxE-ax ) для содержания белка в CV1 и от -6% (CV00 ax ) до 5. % (CV00 GxE ) для будущих прогнозов.
Таблица 5. Процентное изменение предсказательной способности моделей основных эффектов с учетом эффектов взаимодействия.
Сравнение прогнозов внутри компании и внутри компании с использованием CV1
Эффект объединения популяций для увеличения размера обучающей выборки при прогнозировании оценивался путем сравнения прогнозирующей способности, оцененной с использованием внутри компании (линии из одной программы разведения) или внутри компании (линии из обеих программ разведения).Учебные наборы, которые включали линии из комбинированных программ разведения, увеличили количество записей в этом учебном наборе почти в два раза по сравнению с учебными наборами, которые включали линии из одной племенной компании. Наборы для проверки всегда содержали линии из любой из программ разведения. Гипотеза здесь заключалась в том, что обучающие наборы из комбинированных популяций повысят производительность прогнозирования по сравнению с обучающими наборами из одиночных популяций, поскольку при объединении популяций размер обучающего набора увеличивается.
Наборы для проверки всегда содержали линии из любой из программ разведения. Гипотеза здесь заключалась в том, что обучающие наборы из комбинированных популяций повысят производительность прогнозирования по сравнению с обучающими наборами из одиночных популяций, поскольку при объединении популяций размер обучающего набора увеличивается.
Наши результаты касались в основном популяций и признаков. Если подтверждение от SJ, то объединение популяций из NS и SJ либо не изменилось, либо немного увеличило предсказательную способность в большинстве моделей (за исключением наиболее полной модели) для белка и тестового веса. В SF_abv2.5 и SF_abv2.2 увеличение размера обучающего набора путем объединения популяций из SJ и NS уменьшило способность прогнозирования в большинстве моделей (рисунок 5). Когда набор для проверки взят из NS, увеличение размера обучающего набора за счет комбинирования SJ и NS снижает способность прогнозирования по всем признакам для всех моделей.В наиболее полной модели ELGA-GxA-ax наблюдалось последовательное снижение способности прогнозирования за счет объединения популяций из обеих программ разведения для прогнозирования характеристик линий из любой из программ. За исключением ELGA-GxA-ax , характеристики других моделей были аналогичны результатам, полученным на основе прогнозов внутри компании.
За исключением ELGA-GxA-ax , характеристики других моделей были аналогичны результатам, полученным на основе прогнозов внутри компании.
Рис. 5. Возможности прогнозирования ( y -ось), полученные, когда обучающая выборка состоит из линий либо одной программы разведения, либо комбинированных программ разведения.Используя схему CV1 (прогнозирование новых линий в известных условиях), все шесть моделей сравнивали по всем признакам. На оси x отображаются различные обучающие наборы. Для левых панелей (набор проверки = SJ) N = 392 для обучающего набора SJ и N = 826 для обучающего набора NS + SJ. Для правых панелей (набор проверки = NS) N = 438 для обучающего набора NS и N = 826 для обучающего набора NS + SJ. Планки погрешностей отображают стандартную ошибку от среднего значения 10-кратной корреляции.
Обсуждение
Компоненты вариативности и наследуемость
В этом исследовании изучалось несколько моделей для определения влияния независимых и комбинированных маркеров и родословных взаимосвязей на прогноз, а также влияния условий взаимодействия с окружающей средой. По результатам анализа компонентов дисперсии было обнаружено, что включение взаимодействия маркеров и окружающей среды или родословной и окружающей среды привело к значительному снижению необъяснимой дисперсии для всех признаков.Аналогичное снижение также наблюдалось в предыдущих исследованиях пшеницы (Burgueño et al., 2012; Jarquín et al., 2014; Sukumaran et al., 2017) и хлопка (Pérez-Rodríguez et al., 2015). Также было замечено, что условия взаимодействия вносят вклад в общую фенотипическую дисперсию внутри среды в разной степени. Это указывало на то, что модели только с основными эффектами не подходили для отражения большей части дисперсии модели. Следовательно, введение условий взаимодействия означало, что можно было уловить увеличенную долю дисперсии модели, что, вероятно, повысит способность прогнозирования.
По результатам анализа компонентов дисперсии было обнаружено, что включение взаимодействия маркеров и окружающей среды или родословной и окружающей среды привело к значительному снижению необъяснимой дисперсии для всех признаков.Аналогичное снижение также наблюдалось в предыдущих исследованиях пшеницы (Burgueño et al., 2012; Jarquín et al., 2014; Sukumaran et al., 2017) и хлопка (Pérez-Rodríguez et al., 2015). Также было замечено, что условия взаимодействия вносят вклад в общую фенотипическую дисперсию внутри среды в разной степени. Это указывало на то, что модели только с основными эффектами не подходили для отражения большей части дисперсии модели. Следовательно, введение условий взаимодействия означало, что можно было уловить увеличенную долю дисперсии модели, что, вероятно, повысит способность прогнозирования.
Модели, использующие как маркерную, так и родословную информацию, увеличили наследуемость по большинству признаков по сравнению с моделями только с маркерной или родословной информацией.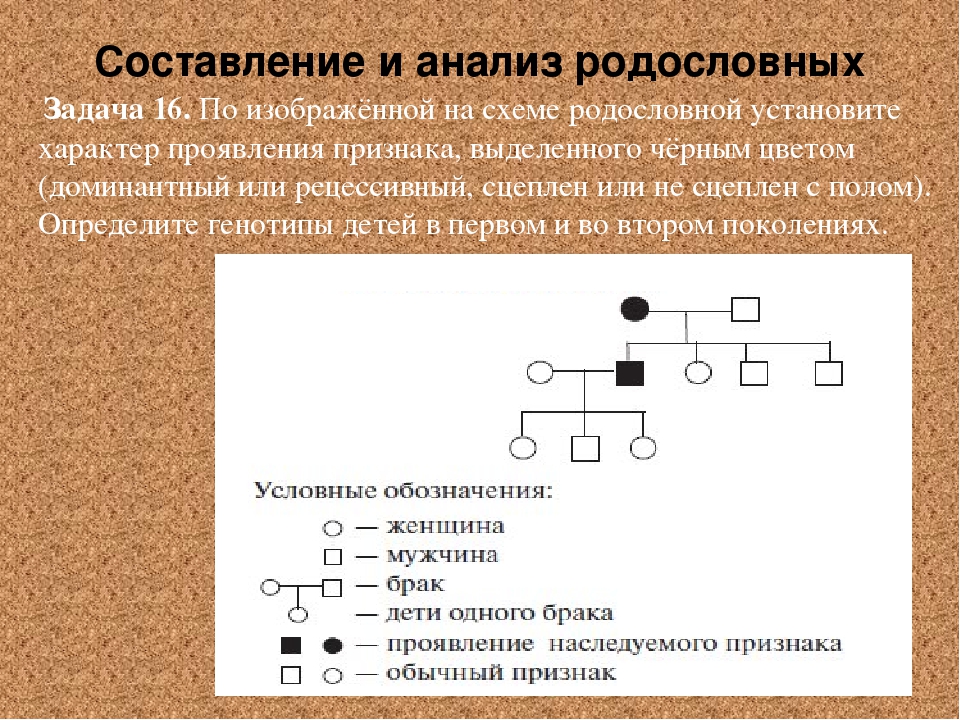 Аналогичные результаты наблюдались и для сорго (Velazco et al., 2019), где матрица k , составленная из комбинированной информации о родословной и маркерах, увеличивала наследуемость признаков. Повышенная наследуемость из-за комбинированных родословных маркеров и родословных показала, что такие модели имеют тенденцию улавливать большую генетическую изменчивость, чем использование только маркера или информации о родословной.
Аналогичные результаты наблюдались и для сорго (Velazco et al., 2019), где матрица k , составленная из комбинированной информации о родословной и маркерах, увеличивала наследуемость признаков. Повышенная наследуемость из-за комбинированных родословных маркеров и родословных показала, что такие модели имеют тенденцию улавливать большую генетическую изменчивость, чем использование только маркера или информации о родословной.
Снижение общей наследственности в узком смысле при использовании ELG по сравнению с ELA в этом исследовании отражает понятие матрицы родословных родственных отношений, не корректирующейся для менделевской выборки, что приводит к вероятной переоценке аддитивной генетической дисперсии. В литературе существует общее мнение, что информация о взаимоотношениях, полученных от маркеров, становится все более предпочтительной в исследованиях геномного прогнозирования информации о родословных (Crossa et al., 2010; Альбрехт и др., 2011; Burgueño et al. , 2012; Auinger et al., 2016; Веласко и др., 2019). Это связано с тем, что, в отличие от информации о родословной родословной, полученная от маркера информация о родстве учитывает общее происхождение, которое в противном случае не учитывается в родословной. Более того, матрица, полученная из маркеров, в частности, учитывает отклонения реализованных генетических отношений от ожидаемых значений из-за менделевской сегрегации (Burgueño et al., 2012; Velazco et al., 2019), и, таким образом, обеспечивает относительно точные компоненты генетической дисперсии по сравнению с родословная матрица (El-Dien et al., 2016).
, 2012; Auinger et al., 2016; Веласко и др., 2019). Это связано с тем, что, в отличие от информации о родословной родословной, полученная от маркера информация о родстве учитывает общее происхождение, которое в противном случае не учитывается в родословной. Более того, матрица, полученная из маркеров, в частности, учитывает отклонения реализованных генетических отношений от ожидаемых значений из-за менделевской сегрегации (Burgueño et al., 2012; Velazco et al., 2019), и, таким образом, обеспечивает относительно точные компоненты генетической дисперсии по сравнению с родословная матрица (El-Dien et al., 2016).
при различных схемах перекрестной проверки
Тенденция к производительности модели с точки зрения способности прогнозирования была одинаковой для всех признаков, при этом разные схемы демонстрировали различия в том, как модели работали. Результаты этого исследования показали, что производительность модели зависит от используемой схемы перекрестной проверки. В целом, предсказание линий NS по большинству признаков было лучше, чем линий SJ. Это было вызвано тесной взаимосвязью, наблюдаемой между линиями в матрицах для NS, как показано на рисунке 2.При небольшом количестве подсемейств в NS по сравнению с SJ количество полных братьев и сестер в каждой подсемейной единице в NS было относительно большим по сравнению с SJ, что способствовало более точному предсказанию линий из NS, чем SJ. Этого следовало ожидать, потому что NS имеет более позднюю селекцию ячменя с более узкой генетической базой, состоящей в основном из разновидностей Северной Европы, в то время как селекция ячменя SJ имеет гораздо более долгую историю с более широкой генетической базой, состоящей из генотипов, происходящих со всей Европы.
В целом, предсказание линий NS по большинству признаков было лучше, чем линий SJ. Это было вызвано тесной взаимосвязью, наблюдаемой между линиями в матрицах для NS, как показано на рисунке 2.При небольшом количестве подсемейств в NS по сравнению с SJ количество полных братьев и сестер в каждой подсемейной единице в NS было относительно большим по сравнению с SJ, что способствовало более точному предсказанию линий из NS, чем SJ. Этого следовало ожидать, потому что NS имеет более позднюю селекцию ячменя с более узкой генетической базой, состоящей в основном из разновидностей Северной Европы, в то время как селекция ячменя SJ имеет гораздо более долгую историю с более широкой генетической базой, состоящей из генотипов, происходящих со всей Европы.
В CV1 информация о родословной превосходила или конкурировала с информацией о маркерах. В данных SJ родословные модели работали лучше, чем модели-маркеры, в то время как в NS родословные модели работали так же, как модели-маркеры. Этот результат согласуется с предыдущими наблюдениями на пшенице и сорго (Juliana et al. , 2017; Hunt et al., 2018; Howard et al., 2019). CV0 и CV00 включают более сложные ситуации прогнозирования, которые охватывают разные среды (годы), и в этих ситуациях информационные модели маркеров работают лучше, чем информационные модели родословных.В этих сложных ситуациях количество связанных линий (полных и половинных братьев и сестер) в обучающем наборе уменьшается при выборке по годам, и, следовательно, видно явное преимущество реализованной взаимосвязи, зафиксированной маркером (Juliana et al., 2018). Когда ведется исключительный учет родословных, который насчитывает несколько поколений, модели на основе родословных могут работать лучше, чем модели на основе маркеров (Juliana et al., 2017). Однако это будет выполняться только в том случае, если количество связанных строк в наборах для обучения и проверки будет оптимальным.Таким образом, когда линии выводятся из родословной, содержащей различных братьев и сестер, они с большей вероятностью будут точно предсказаны с использованием информации маркера, чем с использованием информации о родословной, и в этом случае все полные братья и сестры в одном подсемействе будут иметь одинаковые прогнозы (Hunt et al.
, 2017; Hunt et al., 2018; Howard et al., 2019). CV0 и CV00 включают более сложные ситуации прогнозирования, которые охватывают разные среды (годы), и в этих ситуациях информационные модели маркеров работают лучше, чем информационные модели родословных.В этих сложных ситуациях количество связанных линий (полных и половинных братьев и сестер) в обучающем наборе уменьшается при выборке по годам, и, следовательно, видно явное преимущество реализованной взаимосвязи, зафиксированной маркером (Juliana et al., 2018). Когда ведется исключительный учет родословных, который насчитывает несколько поколений, модели на основе родословных могут работать лучше, чем модели на основе маркеров (Juliana et al., 2017). Однако это будет выполняться только в том случае, если количество связанных строк в наборах для обучения и проверки будет оптимальным.Таким образом, когда линии выводятся из родословной, содержащей различных братьев и сестер, они с большей вероятностью будут точно предсказаны с использованием информации маркера, чем с использованием информации о родословной, и в этом случае все полные братья и сестры в одном подсемействе будут иметь одинаковые прогнозы (Hunt et al.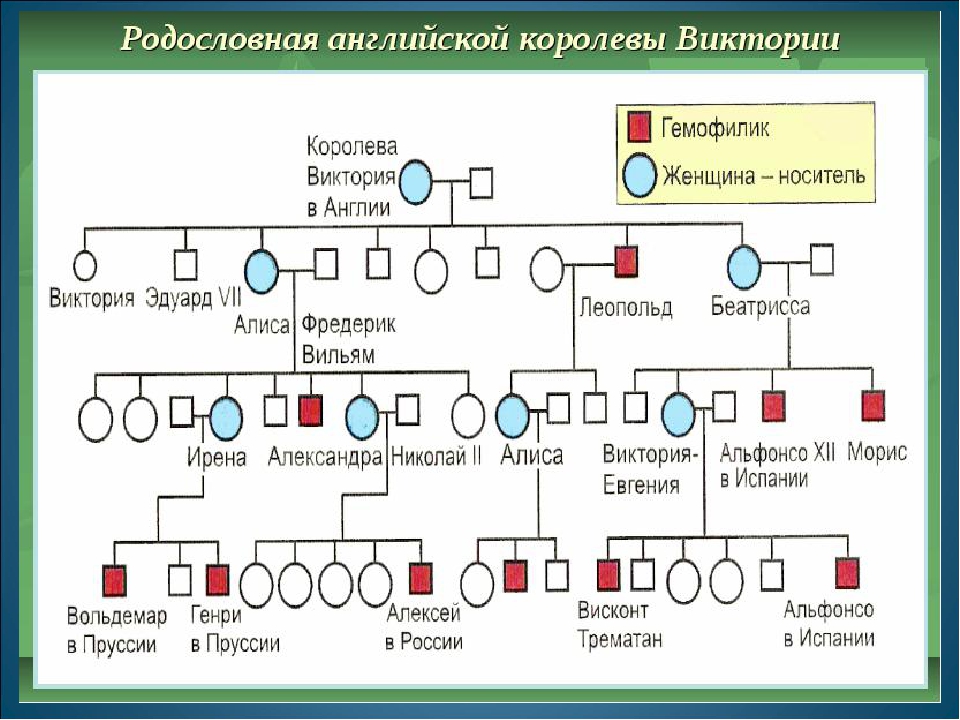 , 2018).
, 2018).
Плотное покрытие маркером является предпосылкой для повышения точности прогнозов (Heffner et al., 2009). Однако степень аддитивной генетической изменчивости, которую можно объяснить с помощью маркеров, зависит не только от плотного покрытия маркеров, но и от количества маркеров в неравновесном сцеплении (LD) с причинными генами (Jensen et al., 2012). Это означает, что при низком уровне маркеров LD с причинными генами модели, основанные исключительно на маркерах, могут работать хуже, чем их соответствующие модели, основанные только на родословной. Хотя предполагалось, что количество маркеров, использованных в этом исследовании, обеспечивает превосходный охват всего генома, существует вероятность, что эти маркеры недостаточно покрывают некоторые основные области, связанные с признаками, что приводит к более низкой точности прогнозов в некоторых моделях, основанных только на по маркерам. Это было очевидно из-за того, что большая часть общей аддитивной генетической дисперсии объяснялась родословными, а не отношениями маркеров (Таблица 4), когда модели включали обе матрицы, особенно в данные SJ.
Объединение маркеров и информации о родословной не показало никаких преимуществ в предсказательной способности. В нескольких исследованиях сообщалось об улучшении прогнозов за счет сочетания маркерных и родословных отношений по сравнению с моделями с маркером или только информацией о родословной (Crossa et al., 2010; Albrecht et al., 2011; Burgueño et al., 2012; Auinger et al., al., 2016; Juliana et al., 2017; Velazco et al., 2019). Сообщаемое улучшение прогнозирования комбинированных информационных моделей маркеров и родословных основано на предположении, что, если маркеры не находятся в полной LD с QTL, добавление информации родословных отношений будет способствовать выявлению ассоциаций между причинными аллелями из-за общей идентичности родословных, что может повысить точность прогнозов (Velazco et al., 2019). Однако при наличии высококачественных геномных маркеров и информации о родословной существует вероятность некоторой избыточности между регрессией по маркерам и регрессией по родословной, что приводит к отсутствию или лишь незначительному выигрышу (Albrecht et al. , 2011; Juliana et al. др., 2017). Отсутствие преимущества при объединении обеих матриц в этом исследовании может быть связано с избыточностью информации, полученной обеими (Crossa et al., 2017), или с проблемами коллинеарности, возникающими из них, поскольку они не являются взаимно ортогональными (Howard et al. ., 2019).
, 2011; Juliana et al. др., 2017). Отсутствие преимущества при объединении обеих матриц в этом исследовании может быть связано с избыточностью информации, полученной обеими (Crossa et al., 2017), или с проблемами коллинеарности, возникающими из них, поскольку они не являются взаимно ортогональными (Howard et al. ., 2019).
Оценка и количественная оценка взаимодействия генотипа с окружающей средой является неотъемлемой частью GS и, как было показано, приводит к повышению способности прогнозирования (Jarquín et al., 2017). В этом исследовании включение условий взаимодействия между генотипом и средой в модели основных эффектов привело к увеличению предсказательной способности для всех признаков в CV1. Белок, у которого было наиболее резкое сокращение дисперсии ошибок внутри среды после добавления условий взаимодействия, получил наиболее значительный выигрыш от условий взаимодействия в отношении способности прогнозирования как в NS, так и в SJ.Это улучшение предсказательной способности не было неожиданностью, учитывая вклад условий взаимодействия в модели основных эффектов в анализе компонентов дисперсии, как обсуждалось ранее. Более того, в CV1 наиболее полная модель ( ELGA-GxE-ax ) имела самую высокую предсказательную способность по всем признакам. Принимая во внимание степень вклада дисперсии GxE и ax в каждую из характеристик, это увеличение не было неожиданностью. Таким образом, оказывается, что если сочетание маркера и родословной является благоприятным, значительный выигрыш в предсказательной способности может быть достигнут путем совместного рассмотрения их взаимодействия с окружающей средой в ячмене, что также наблюдалось в предыдущих исследованиях пшеницы (Burgueño et al., 2012; Сукумаран и др., 2017).
Более того, в CV1 наиболее полная модель ( ELGA-GxE-ax ) имела самую высокую предсказательную способность по всем признакам. Принимая во внимание степень вклада дисперсии GxE и ax в каждую из характеристик, это увеличение не было неожиданностью. Таким образом, оказывается, что если сочетание маркера и родословной является благоприятным, значительный выигрыш в предсказательной способности может быть достигнут путем совместного рассмотрения их взаимодействия с окружающей средой в ячмене, что также наблюдалось в предыдущих исследованиях пшеницы (Burgueño et al., 2012; Сукумаран и др., 2017).
Интересно, что учет взаимодействия между генотипом и средой не всегда улучшал предсказательную способность по CV0 и CV00. Аналогичные результаты были получены для пшеницы (Howard et al., 2019), и это может быть связано с тем, что CV1, который включает прогнозирование новых линий в тестируемых средах, позволяет заимствовать информацию из других сред (годы), тогда как CV0 и CV00, которые включают прогноз производительности ненаблюдаемых сред, гораздо более сложной ситуации нет.
Увеличение размера обучающей выборки путем объединения популяций
Несколько исследований показали, что увеличение размера обучающей выборки улучшает способность прогнозирования (Zhong et al., 2009; Asoro et al., 2011; Zhang et al., 2017). В связи с этим представлением было высказано предположение, что увеличение размера обучающей выборки путем комбинирования линий из разных программ разведения улучшит способность прогнозирования.
Результаты показали, что увеличение размера обучающей выборки за счет комбинирования различных популяций не принесло пользы с точки зрения прогнозирования каждой совокупности тестовых наборов.В большинстве случаев это приводило либо к отсутствию изменений в предсказательной способности, либо к снижению. Потеря способности прогнозирования внутри компании по сравнению с внутрикорпоративной составляла в среднем от 0,7 до 4,6%, когда набор проверки состоял из данных SJ, и от 3,5 до 4,7%, когда набор проверки содержал данные NS. Этот результат аналогичен тому, что наблюдалось в GS для устойчивости к фузариозу шестирядного ячменя (Lorenz et al.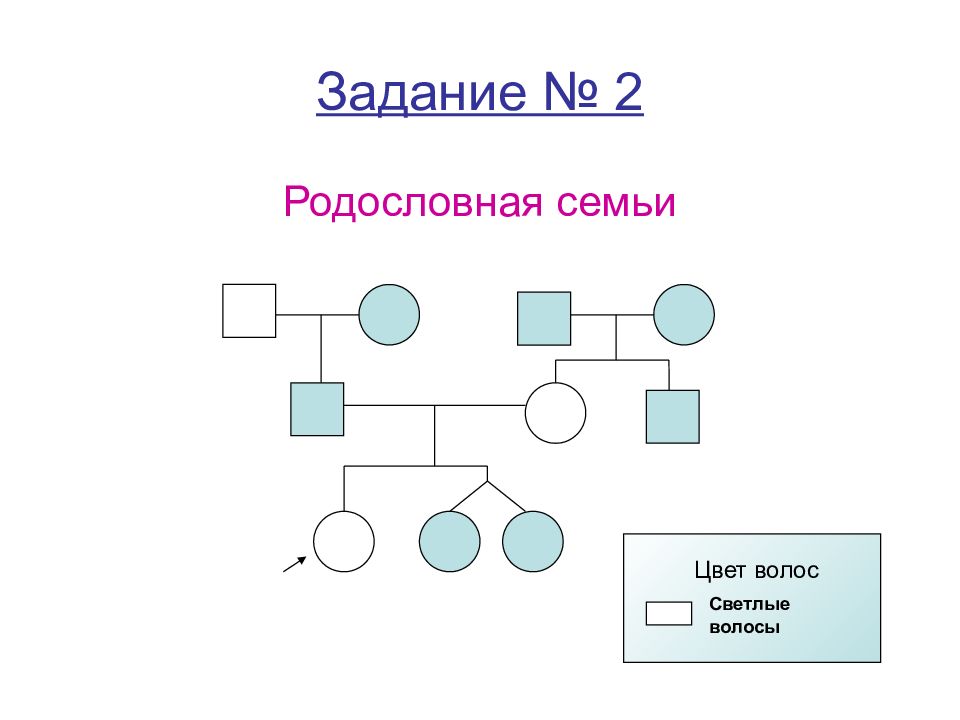 , 2012) и GS для урожайности зерна мягкой пшеницы (Juliana et al., 2018). Выводы из обоих исследований предполагают, что отсутствие преимущества в объединении популяций, соответствующих различным программам разведения, для увеличения обучающей популяции, может быть связано с возможностью маркерных эффектов, различающихся в популяциях, и, следовательно, вызывающих существенное взаимодействие QTL с окружающей средой.Другие причины могут быть связаны с разными QTL, сегрегированными между двумя популяциями, и разными эффектами QTL между разными популяциями из-за эпистаза (Lorenz et al., 2012).
, 2012) и GS для урожайности зерна мягкой пшеницы (Juliana et al., 2018). Выводы из обоих исследований предполагают, что отсутствие преимущества в объединении популяций, соответствующих различным программам разведения, для увеличения обучающей популяции, может быть связано с возможностью маркерных эффектов, различающихся в популяциях, и, следовательно, вызывающих существенное взаимодействие QTL с окружающей средой.Другие причины могут быть связаны с разными QTL, сегрегированными между двумя популяциями, и разными эффектами QTL между разными популяциями из-за эпистаза (Lorenz et al., 2012).
В отличие от этих результатов, другие показали, что способность прогнозирования может быть увеличена путем объединения нескольких популяций. Было показано, что в селекции животных геномный отбор приносит пользу от объединения популяций, когда генетическая дистанция между породами близка. Для пород, родственных на расстоянии, геномное прогнозирование можно улучшить, если использовать модели, которые уделяют больше внимания геномным маркерам в сильной LD с причинными вариантами (Lund et al. , 2014). Точно так же преимущество объединения популяций может возрасти с увеличением количества маркеров, увеличивая наследуемость и уменьшая время расхождения между популяциями. С повышенной плотностью маркеров даже очень дивергентные популяции, вероятно, будут иметь общую структуру маркера-QTL LD, которая была сгенерирована из-за мутационных событий, которые произошли до дивергенции популяции (de Roos et al., 2009). По сути, это снижает негативное влияние контрастных эффектов маркеров QTL между популяциями и, следовательно, снижает частоту рекомбинации между маркерами и QTL.
, 2014). Точно так же преимущество объединения популяций может возрасти с увеличением количества маркеров, увеличивая наследуемость и уменьшая время расхождения между популяциями. С повышенной плотностью маркеров даже очень дивергентные популяции, вероятно, будут иметь общую структуру маркера-QTL LD, которая была сгенерирована из-за мутационных событий, которые произошли до дивергенции популяции (de Roos et al., 2009). По сути, это снижает негативное влияние контрастных эффектов маркеров QTL между популяциями и, следовательно, снижает частоту рекомбинации между маркерами и QTL.
Предполагается, что популяции, использованные в этом исследовании, являются весьма родственными, поскольку они происходят от конкурирующих племенных компаний, находящихся в непосредственной близости и нацеленных на агроклиматические зоны Северной Европы. Существует высокая вероятность того, что обе компании будут использовать общие линии в качестве учредителей, поскольку они имеют одну и ту же целевую аудиторию, и возможность того, что сорта, выпущенные одной компанией, будут использоваться в качестве источника нового генетического материала для скрещиваний в популяции другой (Robertsen et al. , 2019). Однако из наших результатов мы можем сделать вывод, что популяции недостаточно связаны между собой, чтобы извлечь выгоду из этой комбинации.Изучая более сложные методы отбора переменных, можно реализовать преимущество увеличения размера обучающей популяции путем комбинирования линий из обеих программ разведения, поскольку такие модели способны улавливать тесно связанные эффекты маркеров QTL.
, 2019). Однако из наших результатов мы можем сделать вывод, что популяции недостаточно связаны между собой, чтобы извлечь выгоду из этой комбинации.Изучая более сложные методы отбора переменных, можно реализовать преимущество увеличения размера обучающей популяции путем комбинирования линий из обеих программ разведения, поскольку такие модели способны улавливать тесно связанные эффекты маркеров QTL.
Заявление о доступности данных
Наборы данных, созданные для этого исследования, можно найти в статье / Дополнительные материалы.
Авторские взносы
TA-Y, SR и LJ концептуализировали идею рукописи.TA-Y проанализировал данные и написал рукопись. ЖЖ поддержан статистическим анализом. RH и JJ разработали полевые испытания и предоставили геномные и родословные данные. RH, JJ и TA-Y собрали фенотипические данные. Все авторы прочитали и одобрили окончательную рукопись.
Финансирование
Исследование финансировалось Центром геномной селекции животных и растений (GenSAP) в 2013-2018 гг. И грантом № 12-132452 при поддержке Датского инновационного фонда.
И грантом № 12-132452 при поддержке Датского инновационного фонда.
Конфликт интересов
JJ работал в компании Nordic Seed A / S, а автор RH работал в компании Sejet Plant Breeding A / S.
Остальные авторы заявляют, что исследование проводилось при отсутствии каких-либо коммерческих или финансовых отношений, которые могли бы быть истолкованы как потенциальный конфликт интересов.
Благодарности
Авторы хотели бы поблагодарить членов GenSAP за научное обсуждение, а также Sejet Breeding Company и Nordic Seed Company за предоставление данных из их активных селекционных программ.
Дополнительные материалы
Дополнительные материалы к этой статье можно найти в Интернете по адресу: https: // www.frontiersin.org/articles/10.3389/fpls.2020.00539/full#supplementary-material
Материал S1 | Фенотипические данные, генотипические данные и матрицы родства, основанные на информации о родословных от двух племенных компаний.
Список литературы
Альбрехт Т., Виммер В., Ауингер Х.-Дж., Эрбе М., Кнаак К., Узунова М. и др. (2011). Прогнозирование значений тест-кросса кукурузы на основе генома. Теор. Прил. Genet. 123: 339. DOI: 10.1007 / s00122-011-1587-7
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Асоро, Ф.Дж., Ньюэлл, М. А., Бивис, В. Д., Скотт, М. П., и Джаннинк, Ж.-Л. (2011). Точность и обучающий дизайн популяций для геномной селекции по количественным признакам элитного североамериканского овса. Геном растений 4, 132–144.
Google Scholar
Auinger, H.-J., Schönleben, M., Lehermeier, C., Schmidt, M., Korzun, V., Geiger, H.H., et al. (2016). Обучение модели в нескольких циклах разведения значительно повышает точность прогнозирования генома у ржи ( Secale cereale L.). Теор. Прил. Genet. 129, 2043–2053. DOI: 10.1007 / s00122-016-2756-5
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Бургеньо Дж. , Де лос Кампос Г., Вейгель К. и Кросса Дж. (2012). Геномное прогнозирование племенной ценности при моделировании взаимодействия генотип × среда с использованием родословных и плотных молекулярных маркеров. Crop Sci. 52, 707–719.
, Де лос Кампос Г., Вейгель К. и Кросса Дж. (2012). Геномное прогнозирование племенной ценности при моделировании взаимодействия генотип × среда с использованием родословных и плотных молекулярных маркеров. Crop Sci. 52, 707–719.
Google Scholar
Crossa, J., de los Campos, G., Pérez, P., Gianola, D., Бургеньо, Дж., Араус, Дж. Л. и др. (2010). Прогнозирование генетической ценности количественных признаков в селекции растений с использованием родословных и молекулярных маркеров. Генетика 186, 713–724. DOI: 10.1534 / genetics.110.118521
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Кросса, Х., Перес-Родригес, П., Куэвас, Х., Монтесинос-Лопес, О., Яркин, Д., и де лос Кампос, Г. (2017). Геномная селекция в селекции растений: методы, модели, перспективы. Trends Plant Sci. 22, 961–975. DOI: 10.1016 / j.tplants.2017.08.011
PubMed Аннотация | CrossRef Полный текст | Google Scholar
-де-лос-Кампос, Г. , и Перес-Родригес, П. (2018). Байесовская обобщенная линейная регрессия. Пакет R версии 1.0.8.
, и Перес-Родригес, П. (2018). Байесовская обобщенная линейная регрессия. Пакет R версии 1.0.8.
Google Scholar
Де Оливейра, А.А., Пастина, М.М., Да Коста Паррелла, Р.А., Нода, Р.В., Симеоне, М.Л.Ф., Шафферт, Р.Э. и др. (2018). Геномный прогноз применяется к сорго с высоким содержанием биомассы для производства биоэнергетики. Мол. Порода. 38:49. DOI: 10.1007 / s11032-018-0802-5
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Dong, H., Wang, R., Yuan, Y., Anderson, J., Pumphrey, M.O., Zhang, Z., et al. (2018). Оценка потенциала геномной селекции для повышения устойчивости яровой пшеницы к фузариозу на северо-западе Тихого океана. Фронт. Plant Sci. 9: 911. DOI: 10.3389 / fpls.2018.00911
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Эль-Дьен, О.Г., Ратклифф, Б., Клапште, Дж., Порт, И., Чен, К., и Эль-Кассаби, Ю. А. (2016). Внедрение реализованной матрицы геномных взаимоотношений для тестирования семейств ели белой с открытым опылением для отделения аддитивных генетических эффектов от неаддитивных. G3 Genes Genom. Genet. 6, 743–753. DOI: 10.1534 / g3.115.025957
G3 Genes Genom. Genet. 6, 743–753. DOI: 10.1534 / g3.115.025957
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Хайле, Дж. К., Ндиай, А., Кларк, Ф., Кларк, Дж., Нокс, Р., Руткоски, Дж., И др. (2018). Геномная селекция по урожайности и качеству зерна твердой пшеницы. Мол. Порода. 38:75. DOI: 10.1007 / s00122-018-3248-6
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Холланд, Дж. Б., Найквист, В. Э., и Сервантес-Мартинес, К. Т. (2003). Оценка и интерпретация наследственности для селекции растений: обновленная информация. Заводская порода. Ред. 22, 9–111.
Google Scholar
Ховард Р., Джанола Д., Монтесинос-Лопес О., Джулиана П., Сингх Р., Польша, Дж. И др. (2019). Совместное использование генома, родословной и их взаимодействия с окружающей средой для прогнозирования производительности линий пшеницы в новых условиях. G3 9, 2925–2934. DOI: 10.1534 / g3.119.400508
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Хант, К. Х., Ван Иувейк, Ф. А., Мейс, Э. С., Хейс, Б. Дж., И Джордан, Д. Р. (2018). Развитие геномного прогноза сорго. Crop Sci. 58, 690–700.
Х., Ван Иувейк, Ф. А., Мейс, Э. С., Хейс, Б. Дж., И Джордан, Д. Р. (2018). Развитие геномного прогноза сорго. Crop Sci. 58, 690–700.
Google Scholar
Jarquín, D., Crossa, J., Lacaze, X., Du Cheyron, P., Daucour, J., Lorgeou, J., et al. (2014). Модель нормы реакции для геномного отбора с использованием многомерных геномных и экологических данных. Теор. Прил. Genet. 127, 595–607. DOI: 10.1007 / s00122-013-2243-1
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Яркин, Д., Лемес да Силва, К., Гейнор, Р. К., Польша, Дж., Фриц, А., Ховард, Р. и др. (2017). Повышение точности прогнозов на основе генома путем моделирования взаимодействий генотип × среда у канзасской пшеницы. Геном растений 10, 1–15. DOI: 10.3835 / plantgenome2016.12.0130
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Дженсен, Дж., Су, Г., и Мэдсен, П. (2012). Разделение аддитивной генетической изменчивости на геномные и оставшиеся полигенные компоненты для сложных признаков молочного скота. BMC Genet. 13:44. DOI: 10.1186 / 1471-2156-13-44
BMC Genet. 13:44. DOI: 10.1186 / 1471-2156-13-44
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Джулиана П., Сингх Р. П., Польша, Дж., Мондаль, С., Кросса, Дж., Монтесинос-Лопес, О. А. и др. (2018). Перспективы и проблемы прикладной геномной селекции — новой парадигмы селекции на урожайность зерна мягкой пшеницы. Геном растений 11: art18001. DOI: 10.3835 / plantgenome2018.03.0017
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Джулиана П., Сингх Р. П., Сингх П. К., Кросса Дж., Уэрта-Эспино Дж., Лан К. и др. (2017). Прогнозирование устойчивости к листовой, стеблевой и полосовой ржавчине пшеницы на основе генома и родословной. Теор. Прил. Genet. 130, 1415–1430. DOI: 10.1007 / s00122-017-2897-1
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Лоренц, А.Дж., Смит, К. П., и Джаннинк, Ж.-Л. (2012). Возможности и оптимизация геномной селекции на устойчивость к фузариозу у шестирядного ячменя. Crop Sci. 52, 1609–1621.
Crop Sci. 52, 1609–1621.
Google Scholar
Лунд, М., Су, Г., Янсс, Л., Гулдбрандцен, Б., и Брондум, Р. (2014). Приглашенный обзор: геномная оценка крупного рогатого скота в контексте различных пород. Науки о животноводстве. 166, 101–110.
Google Scholar
Meuwissen, T., Hayes, B., and Goddard, M.(2001). Прогнозирование общей генетической ценности с использованием плотных карт маркеров для всего генома. Генетика 157, 1819–1829.
Google Scholar
Nielsen, N.H., Jahoor, A., Jensen, J.D., Orabi, J., Cericola, F., Edriss, V., et al. (2016). Геномное прогнозирование признаков качества семян с использованием передовых селекционных линий ячменя. PLoS One 11: e0164494. DOI: 10.1371 / journal.pone.0164494
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Норман, А., Тейлор, Дж., Эдвардс, Дж., И Кучел, Х. (2018). Оптимизация геномной селекции пшеницы: влияние плотности маркеров, размера популяции и структуры популяции на точность прогнозов.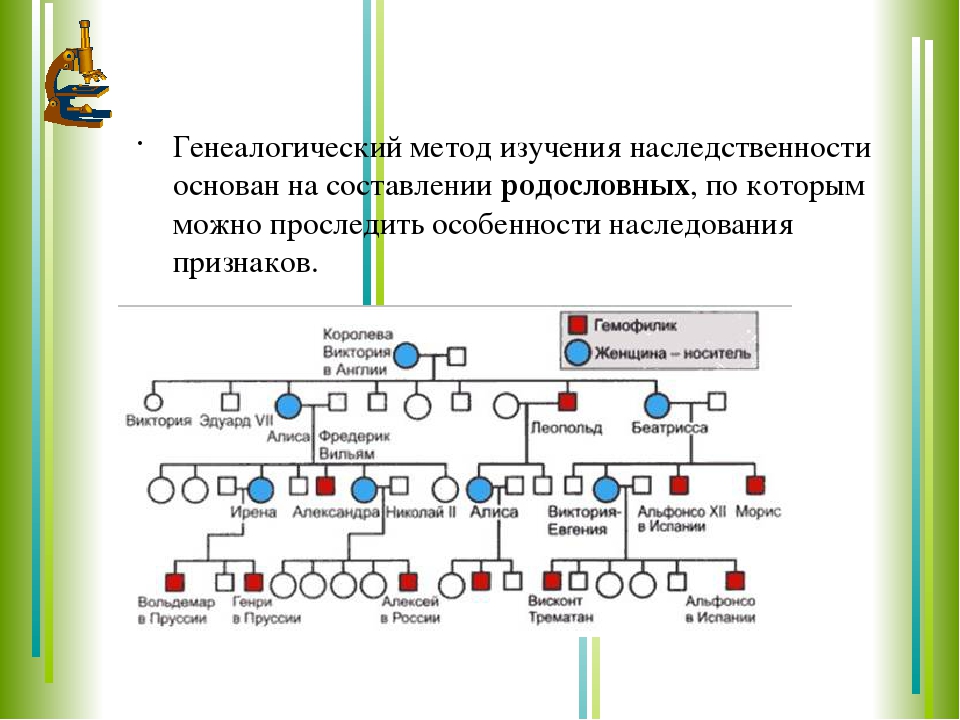 G3 8, 2889–2899. DOI: 10.1534 / g3.118.200311
G3 8, 2889–2899. DOI: 10.1534 / g3.118.200311
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Оки, Х., Куллис, Б., Томпсон, Р., Комадран, Дж., Халпин, К., и Во, Р. (2016). Геномный отбор в испытаниях культур в различных средах. G3 6, 1313–1326. DOI: 10.1007 / s00122-017-2922-4
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Перес-Родригес, П., Кросса, Дж., Бондалапати, К., Де Мейер, Дж., Пита, Ф., и Кампос, Дж. Д. Л. (2015). Модель нормы реакции на основе родословной для прогнозирования урожайности хлопка в испытаниях в разных средах. Crop Sci. 55, 1143–1151.
Google Scholar
Робертсен, К. Д., Хьортсхой, Р. Л., и Янсс, Л. Л. (2019). Геномная селекция в селекции зерновых. Агрономия 9:95.
Google Scholar
Родригес-Рамило, С. Т., Гарсия-Кортес, Л. А., и Гонсалес-Ресио, Ó (2014).Объединение геномной и генеалогической информации в модели регрессии гильбертовых пространств воспроизводящего ядра для прогнозирования на основе генома молочного скота. PLoS One 9: e93424. DOI: 10.1371 / journal.pone.0093424
PLoS One 9: e93424. DOI: 10.1371 / journal.pone.0093424
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Саллам, А. Х., Эндельман, Дж., Джаннинк, Дж .-Л., и Смит, К. П. (2015). Оценка точности предсказания геномной селекции в динамической селекционной популяции ячменя. Геном растений 8, 1–15.
Google Scholar
Шиха, м., Каника, А., Рао, А. Р., Малликарджуна, М. Г., Гупта, Х. С., и Неполеан, Т. (2017). Геномный отбор на устойчивость к засухе с использованием полногеномных SNP кукурузы. Фронт. Plant Sci. 8: 550. DOI: 10.3389 / fpls.2018.550
CrossRef Полный текст | Google Scholar
Spindel, J., Begum, H., Akdemir, D., Virk, P., Collard, B., Redona, E., et al. (2015). Геномная селекция и картирование ассоциаций риса (Oryza sativa): влияние генетической архитектуры признаков, состава обучающей популяции, количества маркеров и статистической модели на точность геномной селекции риса в элитных селекционных линиях тропического риса.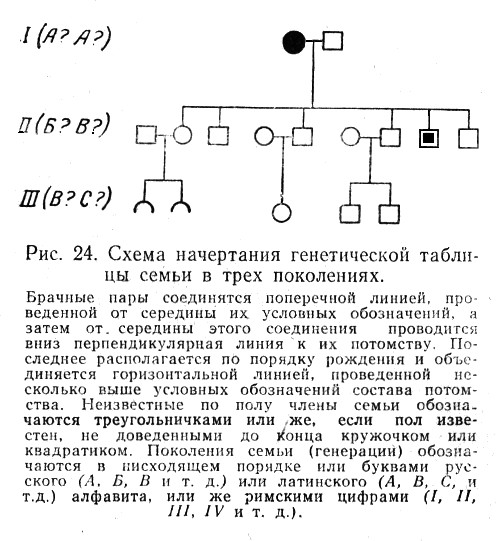 PLoS Genet. 11: e1004982. DOI: 10.1371 / journal.pone.1004982
PLoS Genet. 11: e1004982. DOI: 10.1371 / journal.pone.1004982
CrossRef Полный текст | Google Scholar
Сукумаран, С., Кросса, Дж., Джаркин, Д., Лопес, М., и Рейнольдс, М. П. (2017). Геномное предсказание с взаимодействием родословной и генотипа × среда у яровой пшеницы, выращиваемой в Южной и Западной Азии, Северной Африке и Мексике. G3 7, 481–495. DOI: 10.1534 / g3.116.036251
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Торварт, П., Ahlemeyer, J., Bochard, A.-M., Krumnacker, K., Blümel, H., Laubach, E., et al. (2017). Возможность геномного прогнозирования признаков, связанных с урожайностью, в элитном материале немецкого озимого ячменя. Теор. Прил. Genet. 130, 1669–1683. DOI: 10.1007 / s00122-017-2917-1
PubMed Аннотация | CrossRef Полный текст | Google Scholar
ВанРаден П., Ван Тасселл К., Вигганс Г., Сонстегард Т., Шнабель Р., Тейлор Дж. И др. (2009). Приглашенный обзор: надежность геномных прогнозов быков североамериканской голштинской породы. J. Dairy Sci. 92, 16–24. DOI: 10.3168 / jds.2008-1514
J. Dairy Sci. 92, 16–24. DOI: 10.3168 / jds.2008-1514
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Веласко, Дж. Г., Малосетти, М., Хант, К. Х., Мейс, Э. С., Джордан, Д. Р., и Ван Иувийк, Ф. А. (2019). Объединение информации о происхождении и геноме для повышения качества прогнозов: пример на сорго. Теор. Прил. Genet. 132, 1–13. DOI: 10.1007 / s00122-019-03337-w
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Велес-Торрес, М., Гарсиа-Завала, Дж. Дж., Эрнандес-Родригес, М., Лобато-Ортис, Р., Лопес-Рейносо, Дж. Дж., Бенитес-Рикельме, И. и др. (2018). Геномное предсказание общей комбинационной способности линий кукурузы ( Zea mays L.) и продуктивности их одиночных скрещиваний. Заводская порода. 137, 379–387.
Google Scholar
Wimmer, V., Albrecht, T., Auinger, H.-J., and Schön, C.-C. (2012). synbreed: структура для анализа данных геномного прогнозирования с использованием R. Bioinformatics 28, 2086–2087.DOI: 10.1093 / биоинформатика / bts335
Bioinformatics 28, 2086–2087.DOI: 10.1093 / биоинформатика / bts335
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Xu, Y., Wang, X., Ding, X., Zheng, X., Yang, Z., Xu, C., et al. (2018). Геномный отбор агрономических признаков гибридного риса с использованием популяции NCII. Рис 11:32. DOI: 10.1186 / s12284-018-0223-4
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Zhang, A., Wang, H., Beyene, Y., Semagn, K., Liu, Y., Cao, S., et al. (2017). Влияние наследуемости признака, размера обучаемой популяции и плотности маркеров на оценку точности геномного прогнозирования в 22 двух родительских популяциях тропической кукурузы. Фронт. Plant Sci. 8: 1916. DOI: 10.3389 / fpls.2018.1916
CrossRef Полный текст | Google Scholar
Zhao, Y., Gowda, M., Liu, W., Würschum, T., Maurer, H.P., Longin, F.H., et al. (2012). Точность геномной селекции в элитных селекционных популяциях европейской кукурузы.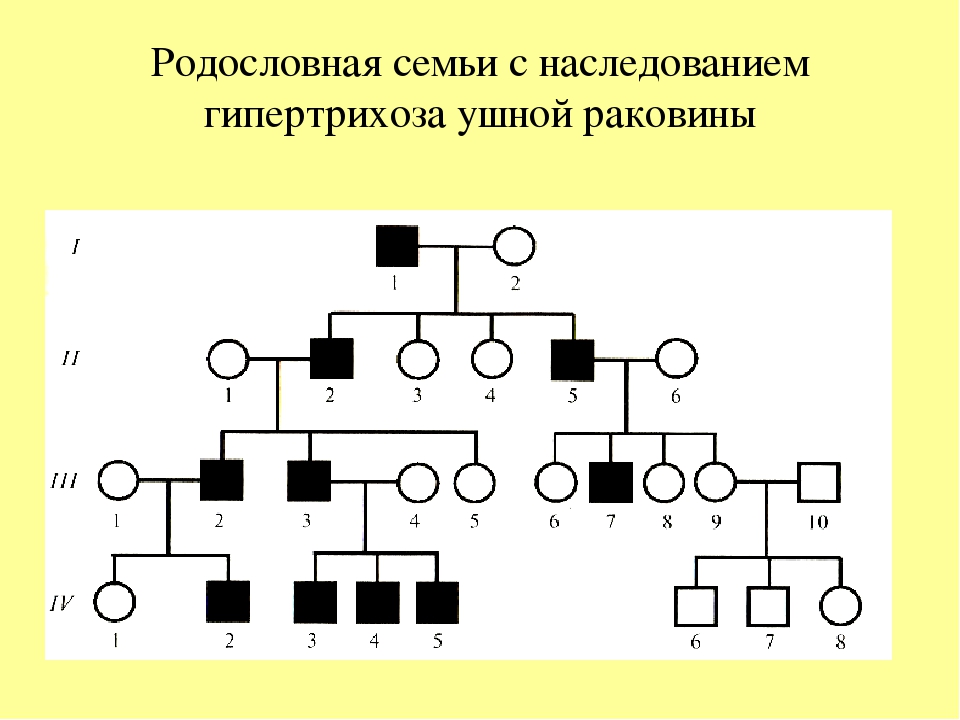 Теорет. Прил. Genet. 124, 769–776.
Теорет. Прил. Genet. 124, 769–776.
Google Scholar
Чжун С., Деккерс Дж. К., Фернандо Р. Л. и Джаннинк Ж.-Л. (2009). Факторы, влияющие на точность геномной селекции в популяциях, полученных от нескольких инбредных линий: тематическое исследование ячменя. Генетика 182, 355–364. DOI: 10.1534 / genetics.108.098277
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Инструкции по рисованию родословной
Начните с рисования сплошного квадрата (мужчина) или круга (женщина) для первого человека с болезнью, который обратился за медицинской помощью. Этого человека называют пробандом . Поместите стрелку в нижний левый угол этого человека, чтобы указать, что он / она пробанд.
Напишите имя или инициалы человека под символом.
Напишите текущий возраст человека под символом.
Укажите заболевание или расстройство, которым обладает человек, а также возраст начала под символом.
Затем нарисуйте родителей человека. Чтобы обозначить партнеров / брак, проведите горизонтальную линию, соединяющую два символа (см. Ниже). Если лица кровнородственных, (т. Е. Родственных) указывают кровное родство двойной горизонтальной линией. Если степень кровного родства не ясна в родословной, укажите над линией родства, т.е.е. «Вторые кузены».
Добавьте текущий возраст родителей или возраст на момент смерти (d. Возраст или год) с причиной смерти. Также укажите любые диагнозы (dx. Болезнь X), которые могут иметь люди, а также возраст на момент постановки диагноза (dx. Болезнь X 50 лет).
Нарисуйте всех братьев и сестер в порядке рождения слева (старший) направо (младший). Братья и сестры соединяются горизонтальной линией над символами, а вертикальные линии соединяют символы с горизонтальной линией. Оставьте место, чтобы добавить партнеров и детей.
Таким же образом добавьте тетушек, дядюшек, бабушек и дедушек. В родословную следует включить всех затронутых лиц и как можно больше незатронутых лиц (родители, дедушки и бабушки, а также братья и сестры любого пораженного человека).
В родословную следует включить всех затронутых лиц и как можно больше незатронутых лиц (родители, дедушки и бабушки, а также братья и сестры любого пораженного человека).
Для каждого отдельного человека добавить следующий символ под его символом
- Инициалы или номер поколения
- Текущий возраст (если известен)
- Любые диагнозы, полученные пациентом с указанием возраста начала заболевания.
- Звездочка (*) рядом с лицами, желающими участвовать в исследовании.
** Текущее место жительства (город, штат) каждого человека, желающего участвовать в исследовании, может быть указано в родословной или должно быть предоставлено в IIHG в виде отдельного списка.
В верхней части родословной укажите этническую принадлежность каждого дедушки и бабушки. Запишите дату получения родословной.
Наконец, нарисуйте ключ в нижнем левом углу, указывающий, что представляет собой затенение.
Родословная — обзор
IV.
Вероятно, наиболее частым источником генетической изменчивости в колониях грызунов является человеческая ошибка. Надлежащие методы управления колонией жизненно важны как для уменьшения количества ошибок, так и для отслеживания и исправления ошибки, когда она произошла. Хорошее управление включает в себя ведение точной системы учета (племенные таблицы), создание надлежащей системы разведения для каждой колонии и реализацию программы обучения техников-животных, которые являются первой линией защиты в любой системе генетического контроля качества.
Надлежащая система разведения необходима для обеспечения стандартизованного генетического качества. В крупных селекционных и исследовательских учреждениях предпочтительной системой является пирамидальная система разведения, включающая в себя основной фонд (FS), племенной разведение (PES) и колонию производственного поголовья (PS) (Fox and Witham, 1997). Относительные размеры этих колоний увеличиваются от FS к PS, отсюда и терминология пирамиды.
На вершине пирамиды находится колония основного стада (FS), где все животные являются племенными, а инбредные линии содержатся в строгом браке с сестрой.Записи о родословных традиционно ведутся с использованием рукописных родословных книг в переплете. Сегодня существует несколько пакетов компьютерного программного обеспечения, которые ведут учет родословных, а также могут управлять исследовательскими проектами (например, Locus Technology 
Штаммы в PES также содержатся как племенные пары, а потомство от вязок PES обеспечивает производителей для колонии производственного стада (PS). Вязки PS не являются породистыми и часто состоят из трех вязок (две девочки и один мальчик).Спаривания могут быть спариваниями между братьями и сестрами [брат-сестра (-и)] или случайными вязками для линий, которые находятся на продвинутых поколениях инбридинга. Потомство от случайных вязок PS никогда не должно использоваться в качестве заводчиков. Модифицированные версии этой схемы могут использоваться для небольших колоний при условии, что всегда должны вестись родословные.
В помещениях для животных необходимо принимать меры для защиты от генетического заражения в результате ошибки разведения. Для каждого штамма можно использовать карты разного цвета, с напечатанными на карте названием штамма и кодом штамма.В идеале, штаммы одного цвета шерсти не должны находиться в одной комнате. Если они должны быть размещены таким образом, они должны быть разделены штаммом другого цвета шерсти. Поимка беглецов снизит вероятность случайного генетического заражения. Бродячих мышей, обнаруженных в комнате, следует гуманно усыпить и никогда не возвращать в клетку. Использование индивидуально вентилируемых систем содержания в клетках еще больше снизит случайное генетическое заражение. Известно, что мыши спариваются через обычные крышки клеток, и такой доступ невозможен при использовании вентилируемых клеток.
Поимка беглецов снизит вероятность случайного генетического заражения. Бродячих мышей, обнаруженных в комнате, следует гуманно усыпить и никогда не возвращать в клетку. Использование индивидуально вентилируемых систем содержания в клетках еще больше снизит случайное генетическое заражение. Известно, что мыши спариваются через обычные крышки клеток, и такой доступ невозможен при использовании вентилируемых клеток.
Внедрение схемы управления колонией требует хорошо обученного персонала техников по уходу за животными. Технические специалисты должны быть обучены основам генетики, надлежащей практике управления колониями, номенклатуре и ведению документации. Они также должны быть обучены распознавать характерные фенотипы штаммов и уметь обнаруживать отклоняющиеся от нормы. Сегодня требуется технический специалист для управления растущим разнообразием новых штаммов, и поэтому обучение должно быть постоянным процессом. Надлежащим образом обученный персонал по уходу за животными и поддержке исследований должен первым выявлять фенотипические отклонения, такие как изменение цвета шерсти, изменения поведения или изменение репродуктивной способности. Также должны быть созданы надлежащие механизмы для сообщения об этих событиях персоналу генетического мониторинга. Существует множество ресурсов, описывающих характеристики инбредных штаммов, в том числе онлайн-ресурсы, такие как веб-сайт Джексонской лаборатории по информатике генома мышей, который содержит «Список инбредных штаммов мышей и крыс» Майкла Фестинга (Festing, 2000).
Также должны быть созданы надлежащие механизмы для сообщения об этих событиях персоналу генетического мониторинга. Существует множество ресурсов, описывающих характеристики инбредных штаммов, в том числе онлайн-ресурсы, такие как веб-сайт Джексонской лаборатории по информатике генома мышей, который содержит «Список инбредных штаммов мышей и крыс» Майкла Фестинга (Festing, 2000).
Криоконсервация спермы или эмбрионов — эффективный метод защиты от случайной потери штамма из-за генетического заражения, внезапного бесплодия, летальной мутации, болезни, пожара или экологической катастрофы.Частота мутаций криоконсервированных эмбрионов, вероятно, равна нулю или близка к нулю, и, таким образом, генетический дрейф в замороженном штамме отсутствует (Bailey, 1977). Следовательно, штамм, хранящийся на полке в течение нескольких лет после первоначальной криоконсервации, будет отличаться от замороженных гамет или эмбрионов, и эти две линии следует рассматривать как подлинии, если криоконсервированный штамм будет восстановлен. В качестве меры контроля качества животные, предоставляющие гаметы или эмбрионы для криоконсервации, особенно те, которые несут мутантные аллели, должны быть генотипированы до их использования.Для процесса криоконсервации необходимо вести подробный учет, поскольку многие штаммы могут храниться в одной камере с жидким азотом.
В качестве меры контроля качества животные, предоставляющие гаметы или эмбрионы для криоконсервации, особенно те, которые несут мутантные аллели, должны быть генотипированы до их использования.Для процесса криоконсервации необходимо вести подробный учет, поскольку многие штаммы могут храниться в одной камере с жидким азотом.
Последовательные схемы для Sibships на JSTOR
Абстрактный Методы определения способа наследования признака из семейных данных получают широкое распространение. Поэтому важно оценить альтернативные процедуры для сбора соответствующих данных. Каннингс и Томпсон (1977, Clinical Genetics 12, 208-212) и Томпсон и Каннингс (1979.В генетическом анализе общих болезней, 363-382. New York: Liss) выступали за последовательные схемы на том основании, что они допускают простые методы коррекции функции правдоподобия для смещения установления. Здесь показано, что последовательные процедуры также могут значительно повысить эффективность, что измеряется (статистической) информацией, полученной на индивидуальной выборке. Хотя внимание ограничивается выборкой родственных братьев и простой генетической моделью, введенные меры более широко применимы.Также представлена практическая процедура построения схем через взаимосвязь между ожидаемой логарифмической вероятностью и энтропией. Это тоже более широко применимо. Численный пример демонстрирует преимущества, которые могут быть достигнуты на практике, по сравнению с альтернативными гипотезами, которые рассматривались в нескольких медико-генетических исследованиях.
Хотя внимание ограничивается выборкой родственных братьев и простой генетической моделью, введенные меры более широко применимы.Также представлена практическая процедура построения схем через взаимосвязь между ожидаемой логарифмической вероятностью и энтропией. Это тоже более широко применимо. Численный пример демонстрирует преимущества, которые могут быть достигнуты на практике, по сравнению с альтернативными гипотезами, которые рассматривались в нескольких медико-генетических исследованиях.
Biometrics — научный журнал, подчеркивающий роль статистики.
и математика в биологических науках.Его цель — продвигать и расширять
использование математических и статистических методов в чистой и прикладной биологии.
науки, описывая развитие этих методов и их приложений
в форме, легко усваиваемой учеными-экспериментаторами.
JSTOR предоставляет цифровой архив печатной версии Biometrics.
Электронная версия биометрии доступна по адресу http://www. blackwell-synergy.com/servlet/useragent?func=showIssues&code;=biom.
Авторизованные пользователи могут иметь доступ к полному тексту статей на этом сайте.
blackwell-synergy.com/servlet/useragent?func=showIssues&code;=biom.
Авторизованные пользователи могут иметь доступ к полному тексту статей на этом сайте.
Международное биометрическое общество — это международное сообщество по продвижению биологической науки через развитие количественных теорий и применение, разработка и распространение эффективных математических и статистических техники. Общество приветствует в качестве членов биологов, математиков, статистиков, и другие, заинтересованные в применении подобных методов.
Предупреждение о тестировании ДНК собак для племенных заводчиков
Разведение собак на основе одного генетического теста сопряжено с риском и не может улучшить здоровье племенных линий, предупреждают эксперты.
Только комбинированный подход, использующий анализ ДНК, схемы медицинского обследования и информацию о родословной, может значительно снизить частоту наследственных заболеваний.
Унаследованные дефекты
Этот подход также улучшит генетическое разнообразие, что помогает снизить риск заболеваний, говорят исследователи.
Ученые из Института Рослина Эдинбургского университета сделали рекомендации, проанализировав различные подходы, которые предпринимаются для минимизации потенциальных дефектов у племенных животных.
Хотя наличие определенного генетического варианта может повысить вероятность того, что животное будет страдать от ассоциированного заболевания, это не гарантируется. При принятии решения о разведении генетическое тестирование необходимо учитывать наряду со скринингом здоровья и семейным анамнезом. Это поможет сохранить как можно больше генетического разнообразия у наших племенных собак и в то же время снизит распространенность наследственных заболеваний.
Д-р Линдси Фаррелл, научный сотрудник Института Рослина
Закрытое разведение
Породные породы собак созданы с учетом желаемых физических и поведенческих характеристик, которые часто возникают в результате разведения между замкнутыми семейными линиями в течение многих лет, а в некоторых случаях — столетий.
Такой подход означает, что наследственные болезни могут стать более распространенными в племенных популяциях. Например, около половины всех кинг-чарльз-кавалер-спаниелей страдают унаследованным шумом в сердце, который может быть опасным для жизни.
Медицинское обследование
Проверка здоровья собак перед отбором животных для разведения уже помогла снизить распространенность некоторых болезней, таких как плавающая наколенник у голландской породы коикер.
ДНК-тесты
ДНК-тестов теперь доступны, чтобы помочь идентифицировать собак, несущих генные мутации, которые, как известно, вызывают некоторые тяжелые заболевания.Есть надежда, что эта технология поможет устранить болезнетворные гены из племенных линий.
Но исключение разведения собак только на основании одного неудачного результата теста ДНК сократит генофонд родословных и сделает инбридинг более распространенным, говорят исследователи. Это также может непреднамеренно увеличить распространенность других генетических заболеваний, на наличие которых не проводилось тестирование.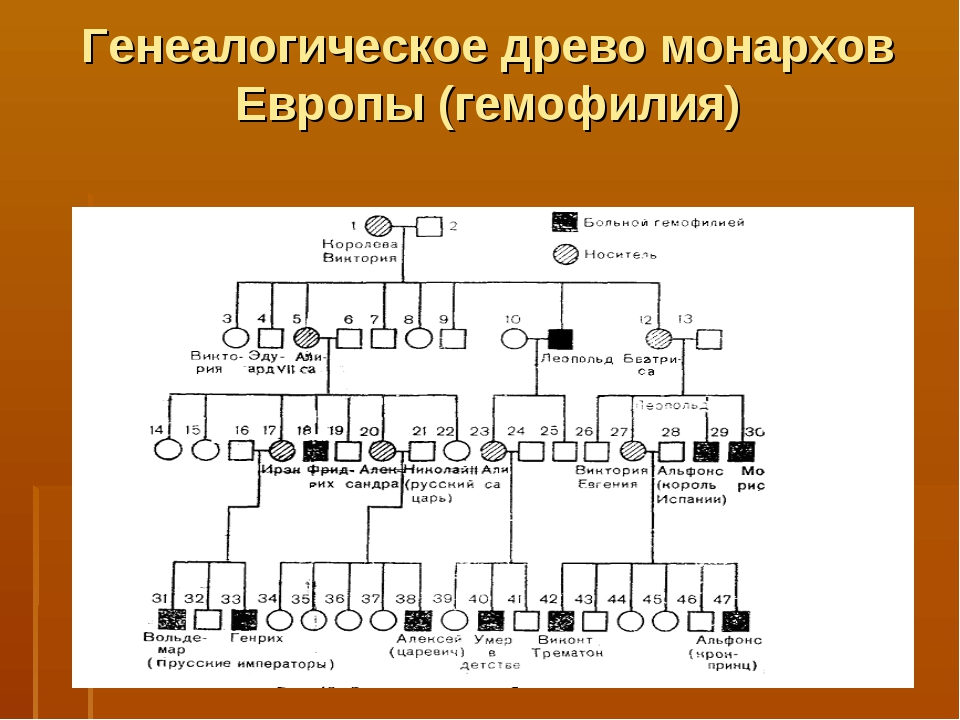
Заводчики стремятся использовать тестирование ДНК для улучшения здоровья своей породы.Мы должны убедиться, что эти мощные технологии используются с максимальной пользой.
Профессор Ким Саммерс Институт Рослина
Генетическое разнообразие
Исследователи рекомендуют ограничить использование отдельных производителей, чтобы способствовать большему разнообразию племенных линий.
Они также рекомендуют скрещивание для еще большего генетического разнообразия. Разведение потомства, полученного в результате скрещивания с исходной родословной в течение десяти поколений, может дать 99 общих животных.9 процентов их генетического материала принадлежат чистокровным животным, но у них отсутствуют генные дефекты, вызывающие болезни.
Этот подход оказался успешным в создании далматинов, лишенных генетического дефекта, который вызывает камни в почках, что является обычным явлением в этой породе.
Статья опубликована в журнале Canine Genetics and Epidemiology. Институт Рослина финансируется Исследовательским советом по биотехнологии и биологическим наукам.
Институт Рослина финансируется Исследовательским советом по биотехнологии и биологическим наукам.
тестов ДНК собак недостаточно для здоровой родословной — ScienceDaily
Разведение собак на основе одного генетического теста сопряжено с риском и не может улучшить здоровье родословных, предупреждают эксперты.
Только комбинированный подход, использующий анализ ДНК, схемы медицинского обследования и информацию о родословной, может значительно снизить частоту наследственных заболеваний.
Этот подход также улучшит генетическое разнообразие, что помогает снизить риск заболеваний, говорят исследователи.
Ученые из Института Рослина Эдинбургского университета сделали рекомендации, проанализировав различные подходы, которые предпринимаются для минимизации потенциальных дефектов у племенных животных.
Породные породы собак созданы с учетом желаемых физических и поведенческих характеристик, которые часто возникают в результате разведения между замкнутыми семейными линиями в течение многих лет, а в некоторых случаях — столетий.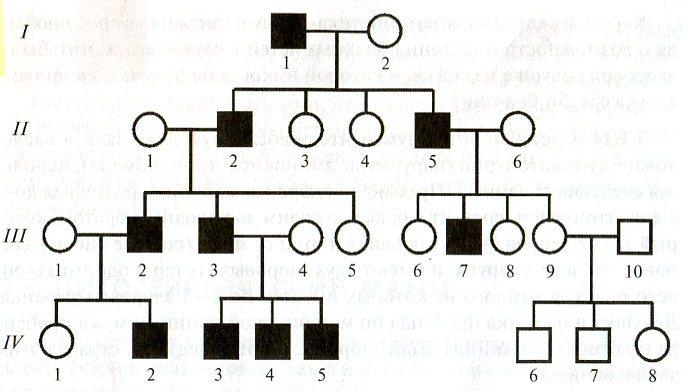
Такой подход означает, что наследственные болезни могут стать более распространенными в племенных популяциях. Например, около половины всех кинг-чарльз-кавалер-спаниелей страдают унаследованным шумом в сердце, который может быть опасным для жизни.
Проверка здоровья собак перед отбором животных для разведения уже помогла снизить распространенность некоторых болезней, таких как плавающая наколенник у голландской породы коикер.
ДНК-тестов теперь доступны, чтобы помочь идентифицировать собак, несущих генные мутации, которые, как известно, вызывают некоторые тяжелые заболевания. Есть надежда, что эта технология поможет устранить болезнетворные гены из племенных линий.
Но исключение разведения собак только на основании одного неудачного результата теста ДНК сократит генофонд родословных и сделает инбридинг более распространенным, говорят исследователи. Это также может непреднамеренно увеличить распространенность других генетических заболеваний, на наличие которых не проводилось тестирование.
Исследователи рекомендуют ограничить использование отдельных производителей, чтобы способствовать большему разнообразию племенных линий.
Они также рекомендуют скрещивание для еще большего генетического разнообразия. Выведение потомства, полученного в результате скрещивания с исходной родословной в течение десяти поколений, может привести к появлению животных, у которых 99,9% генетического материала разделяются с чистокровными животными, но у которых отсутствуют генетические дефекты, вызывающие заболевания.
Этот подход оказался успешным в создании далматинов, лишенных генетического дефекта, который вызывает камни в почках, что является обычным явлением в этой породе.
Доктор Линдси Фаррелл из Института Рослина сказал: «Хотя наличие определенного генетического варианта может повысить вероятность того, что животное будет страдать от ассоциированного заболевания, это не гарантируется. При принятии решения о разведении необходимо учитывать генетическое тестирование. медицинский осмотр и семейный анамнез. Это поможет сохранить как можно больше генетического разнообразия у наших породистых собак и, в то же время, снизить распространенность наследственных заболеваний ».
медицинский осмотр и семейный анамнез. Это поможет сохранить как можно больше генетического разнообразия у наших породистых собак и, в то же время, снизить распространенность наследственных заболеваний ».
Профессор Ким Саммерс из Института Рослина сказал: «Заводчики стремятся использовать тестирование ДНК, чтобы улучшить здоровье своей породы.Мы должны убедиться, что эти мощные технологии используются с максимальной пользой «.
История Источник:
Материалы предоставлены Эдинбургским университетом . Примечание. Содержимое можно редактировать по стилю и длине.
История здоровья семьи
Привлечь учащихся к изучению семейного истории здоровья и связи между генетикой и здоровьем. Пройдя этот модуль, студенты будут:
- Понимать основную информацию об общих (и в некоторых случаях предотвратимых) болезнях, понимать, что риск развития этих заболеваний имеет как наследственный, так и экологический компонент, и понимать, что значит «находиться в группе риска».
 «за развитие этих заболеваний.
«за развитие этих заболеваний. - Оцените личный риск развития распространенных заболеваний, заполнив онлайн-инструмент «Семейное древо здоровья» дома со своей семьей.
- Создайте рекламную кампанию «Уменьшите риск», направленную на обучение своих сверстников.
Следуйте предлагаемому ниже плану урока, чтобы пройти через этот модуль.
| Действие | Аннотация | Длина |
|---|---|---|
| Фильм перед занятием: Использование семейной истории для улучшения вашего здоровья | Используйте этот фильм, чтобы обсудить с учащимися, что значит подвергаться риску, здоровью семейный анамнез и почему это важно.Фильм также служит тизером, чтобы пробудить интерес студентов перед выполнением заданий «Континуум риска» и «Выбери риск». | 6 мин. |
| Risk Continuum | Кинестетическая демонстрация всего класса того, что значит быть в «группе риска» для развития сердечных заболеваний на основании семейного анамнеза / генетики. | 15 мин. |
| Использование семейной истории для улучшения вашего здоровья Веб-квест | Студенты изучают модуль «Использование семейной истории для улучшения вашего здоровья» на веб-сайте Учебного центра генетики, чтобы выполнить веб-квест. | 50-80 мин. |
| Выберите риск: вызов полигенной родословной | Учащиеся отслеживают и записывают прохождение помпонов (представляющих гены) через поколения в семье, используя родословную. Учащиеся узнают, что распространенные хронические заболевания (например, болезни сердца) передаются по наследству и вызываются комбинированным действием нескольких генов. | 30-45 мин. |
| Снизьте свой риск: рекламная кампания | Учащиеся разрабатывают рекламную кампанию, нацеленную на группу сверстников, чтобы научить их тому, как снизить риск развития предотвратимых заболеваний.Студенты отправляют форму заявки, в которой выделяются ключевые моменты и идеи кампании; создание продукта из предложенной ими кампании не является обязательным.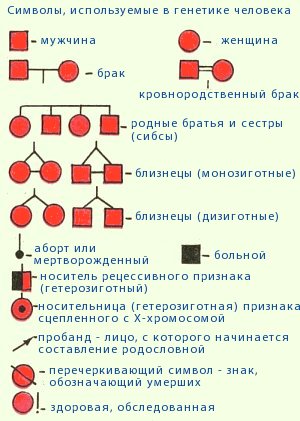

|