
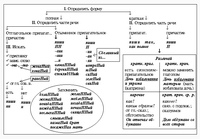
Правописание н и нн в разных частях речи. Практикум
Правописание Н и НН в разных частях речи
Скоше…ый, выровне…ый, естестве..ый, обиже..ый ученик, непроше..ый гость, отпуще..ый, пута..ый ответ, кури..ый, освеще..ый, посвяще..ый, рассмотре..ый, обыкнове..ый, кожа..ый, застреле..ый, расстреля..ый, жева..ая ткань, искусстве..ый, стари..ый, развеша..ый, купле..ый, броше..ый, увенча..ый, ю..ые спортсмены, искре..яя радость, пораже..ый, муравьи..ый укус, постоя..ая работа, обстреля..ый, недрема..ое око, раскрое..ый, посея..ый, склее..ый, обвеше..ый, плавле..ый сырок, овощи замороже..ы, полукопче..ая колбаса, дискуссио..ый вопрос, запута..ый вопрос, пуга..ая птица, свежемороже..ая рыба, ветре..ое утро, листве..ые деревья, конопля..ое семя, станцио..ый подъезд, завеше..ый, глиня..ая ваза, кожеве..ый завод, согласова..ое решение, дикови..ая окраска, агитацио.
Бессребре..ик, племя..ик, листве..ица, нефтя..ик, поле..ица, ряби..ик, дальто..ик, ко..ица, воспита..ик, моше..ик, бесприда.
Лист самопроверки
Скошенный, выровненный, естественный, обиженный ученик, непрошеный гость, отпущенный, путаный ответ, куриный, освещенный, посвященный, рассмотренный, обыкновенный, кожаный, застреленный, расстрелянный, жеваная ткань, искусственный, старинный, развешанный, купленный, брошенный, увенчанный, юные спортсмены, искренняя радость, пораженный, муравьиный укус, постоянная работа, обстрелянный, недреманное око, раскроенный, посеянный, склеенный, обвешенный, плавленый сырок, овощи заморожены, полукопченая колбаса, дискуссионный вопрос, запутанный вопрос, пуганая птица, свежемороженая рыба, ветреное утро, лиственные деревья, конопляное семя, станционный подъезд, завешенный, глиняная ваза, кожевенный завод, согласованное решение, диковинная окраска, агитационный пункт, румяные щеки, свиная тушенка, клюквенный сок, брошенный в ворота мяч, безветренный день, петушиный крик, нечаянный проступок, священный обет, нежданный гость, балованный мальчик, взбешенный пес, данные условия, груженная сеном телега, невиданный успех, сдержанный ответ, негаданный визит, златокованый меч, неслыханная дерзость, нетканые материалы, тяжело раненный боец, прогулянный урок, груженая машина, отчаянный шаг, подклеенные обои, взволнованный вид, искусно плетенная корзина, холеное лицо, верченный резко, квашенная умело капуста, стриженные под горшок волосы, крашенный давно пол, сортированные фрукты, путаный ответ, припаянная деталь, тисненная золотом бумага, решенный вопрос, раненый боец, неписаные законы, свежемороженая рыба, графленый лист, штопаные – перештопаные носки, слоеный пирог, малоезженые дороги.
Бессребреник, племянник, лиственница, нефтяник, поленница, рябинник, дальтоник, конница, воспитанник, мошенник, бесприданница, путешественник, ставленник, длина, гостиница, дровяник, сонник, сторонник, гривенник, мудреность, язвенник, сработанность, конопляник, родственник, ремесленник, избранник.
Дидактический материал по теме: «Правописание -Н- -НН- в частях речи» (русский язык, 6-9 класс) — К уроку — Технология
В соответствии с
требованиями государственного образовательного стандарта школа должна
обеспечить условия для получения знаний по предметам. Не исключением является
русский язык. Учитывая, что это один из основных школьных предметов, учитель
должен не только сформировать знания по предмету, но и обеспечить выработку
навыки и максимальный уровень развития ключевых компетенций: коммуникативных,
учебно-познавательных, общекультурных и других.
Одной из трудных тем
в курсе русского языка является правописание –Н- -НН- в разных частях речи.
Системное изучение этой темы начинается в 6 классе с изучения правописания –Н-
-НН- в именах прилагательных, существительных,
продолжается в 7 классе изучением правописания –Н- -НН- в причастиях,
наречиях, затем навык отрабатывается в
течение реализации всей программы по русскому языку (вплоть до 11 класса).
Следует обратить особое внимание на тот факт, что задания подобного типа
включены в содержание материалов ЕГЭ.
Весь представленный
дидактический материал по теме «Одна и две буквы Н в частях речи» может служить
пособием для учителей общеобразовательных школ в соответствии с требованиями
государственного образовательного стандарта и использоваться на разных стадиях
работы по данной теме: объяснение нового материала, закрепление изученного,
систематизация и обобщение полученных знаний, контроль — и, что особенно важно, с разным уровнем
подготовки школьников.
Изучение нового
материала строится на установлении внутрипредметных связей. Это особенно важно,
поскольку новые лингвистические знания основываются на том материале, который
был изучен ранее. Правописание –Н- -НН- в причастиях и наречиях соотносятся с
правописание –Н- -НН- в прилагательных и существительных. Вследствие этого представленный
материал включает задания на различение букв Н в разных частях речи:
существительных, прилагательных, причастиях, наречиях, а также в кратких формах
этих частей речи. Такой подход оправдан в силу того, что одним из принципов
русской орфографии является морфологический принцип.
В целях
систематизации и обобщения знаний по этой теме учащиеся совместно с учителем
постепенно заполняют таблицу с опорным материалом (Приложение 1). Данная
таблица впоследствии может быть использована
в виде памятки на последующих уроках.
Данная
таблица впоследствии может быть использована
в виде памятки на последующих уроках.
После того, как учащиеся усвоили алгоритм выбора –Н- -НН- в разных частях речи, предлагается набор заданий (Приложение 3-4). Они предлагаются с целью совершенствования умения правильно выбрать орфограмму –Н- -НН- в частях речи. Хочется обратить внимание на то, что все задания кроме формирования навыка преследуют также цель развития школьников и обеспечивают дифференцированный подход в обучении. При проведении орфографических (словарных) диктантов (Приложение 4) возможны варианты:
· Написать словарный диктант;
· Провести орфографическую пятиминутку;
· Провести орфографическую пятиминутку с использованием сигнальных карточек;
· Дать задание по вариантам;
· Предложить учащимся составить предложения, рассказ с 3-5 словосочетаниями;
С целью контроля за
уровнем сформированности знаний по теме можно использовать небольшой тест
(Приложение 5), который выявит уровень навыка и позволит организовать
индивидуальную работу по ликвидации пробелов.
Контрольная работа
(Приложение 6) проводится после изучения материала по теме. Учащимся
предлагается три варианта: 1 и 2 одинаковые по трудности, 3 – повышенный. Это
дает возможность учителю подойти к проведению контрольной работы
дифференцированно, а также проверить навык работы с текстами, что является
наиболее трудным, чем работа на уровне слова, словосочетания и предложения.
Для последнего этапа работы предлагаются диктанты, так как это одна из основных форм проверки пунктуационной и орфографической грамотности. Предлагается несколько вариантов диктантов (Приложение 7), которые можно использовать как в качестве контрольных, так и проверочных.
В целях поддержания
интереса учащихся к предмету возможно
использовать на уроках русского языка задания из раздела «Веселая грамматика».
Например, «Этимологическая страничка» знакомит учащихся с происхождением слов (Приложение 8),
сообщает информацию о том, как возникло то или иное слово. Можно предложить
учащимся самим заглянуть в «Этимологический словарь», найти слово на нужную
орфограмму и провести с ним аналогичную работу. Данная работа способствует
Лучшему запоминанию способствуют веселые рифмы о суффиксах -Н- -НН-, грамматические сказки (Приложение 9).
Возможно предложить учащимся проявить свои творческие способности и сочинить грамматическую
сказку.
Данная работа способствует
Лучшему запоминанию способствуют веселые рифмы о суффиксах -Н- -НН-, грамматические сказки (Приложение 9).
Возможно предложить учащимся проявить свои творческие способности и сочинить грамматическую
сказку.
Особое внимание хочется обратить на задания (Приложение 10), направленные на создание проблемной ситуации при изучении данной темы. Такие задания предполагают изучение орфограммы с помощью доказательства и способствуют более глубокому осмыслению знаний по теме.
После изучения орфограмм «Одна и две буквы Н в частях речи» таким способом у учащихся повысилась орфографическая зоркость, они научились объяснять данную орфограмму устно и графически, делая правильный выбор написания, проявили себя знатоками теории, выступали в качестве писателей, улучшили знания по теме.
Полный текст материала Дидактический материал по теме: «Правописание -Н- -НН- в частях речи» (русский язык, 6-9 класс) смотрите в скачиваемом файле.
На странице приведен фрагмент.

Спасибо за Вашу оценку. Если хотите, чтобы Ваше имя
стало известно автору, войдите на сайт как пользователь
Есть мнение?
Оставьте комментарий
«Правописание –н- и –нн- в суффиксах разных частях речи»
Конспект урока русского языка на тему:
«Правописание –н- и –нн- в суффиксах разных част речи»
Учитель русского языка и литературы Самедова Л.В.
10 класс
Цели урока:
— закрепить навыки правописания –н- и –нн- в разных частях речи;
-выработать навык определения именных и отглагольных образований выбора –н- и –нн- в суффиксах;
— расширить полученные сведения о правописании –н- -нн- в наречиях, прилагательных и причастиях;
— различать краткие формы причастий и прилагательных, образованных от полных причастий;
— совершенствовать орфографическую, пунктуационную и речевую грамотность обучающихся;
— закрепить знания о правописании слов-исключений.
Ход урока
Приветствие
Проверка готовности к уроку
Орфоэпическая разминка по вариантам.
1 вариант 2 вариант
Алкоголь Аргумент
Егоза Бармен
Жалюзи Грушевый
Красивее Договор
Каталог Звонить
Апостроф Атлас (ткань)
Завидно Баловать
Заговор Газопровод
Искра Дремота
Мизерный Задолго
После орфографической разминки проецируется текст. Один ученик работает у доски.
Один ученик работает у доски.
Лермонтовский Кавказ
Вдохновен..о воспетый Лермонтовым Кавказ давно уже стал об..тован..й землей мил..ионов читателей великого поэта. (Не)возможно представить себе этот чудесный край (не)думая о Лермонтове. Где бы вы (н..) были в походе или на отдыхе в диких ущел..ях на горных тропинках в Грузи.. или Дагестане всюду с благодарностью вспомните Лермонтова. Любуясь живописными пейзажами в..личествен..ной красотой Кавказа вы (не)вольно подумаете о том что когда-то уже познакомились с ними и навсегда полюбили их читая произв..дения поэта… На всем Кавказе из..е..жен..ом и и..хожен..ом Лермонтовым нет другого места где (бы) так же тесно как и в Пятигорске переплетались нити личной и творческой б..ографии поэта. Вот почему так влеч..т к себе всех этот уголок земли.
Здесь многое напоминает о Лермонтове потому что Пятигорск
это частица жизни поэта (на) веки запечатлён..ая в
старин. .ых домах и памятниках и в с..неющих горах и в прозрачной лазур.. неба…
.ых домах и памятниках и в с..неющих горах и в прозрачной лазур.. неба…
Задания к тексту:
1.Ученику у доски вставить пропущенные буквы, объяснить орфограммы, постановку знаков препинания.
2.Синтаксический разбор предложений:
Один ученик разбирает первое предложение и определяет тип сказуемого. Вдохновенно воспетый Лермонтовым Кавказ давно уже стал обетованной землей миллионов читателей великого поэта.
Второй – первое предложение второго абзаца и определяет вид односоставного предложения.
На всем Кавказе, изъезженном и исхоженном Лермонтовым, нет другого места, где бы так же тесно, как в Пятигорске, переплетались нити личной и творческой биографии поэта.
3. Выписать слова, в которых пропущены –н- и –нн- и разобрать их по составу:
Изъезженном, старинных, вдохновенно, величественный, исхоженном, обетованной, туманный.
— Что объединяет эти слова?
— О каких частях речи мы говорим?
-Каким способом образованы эти слова?
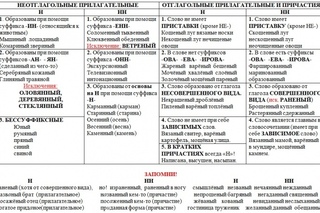
— Вспомним, когда пишется одна буква Н, когда – две.![]()
Есть прилагательные отыменные (т.е.) образованные от имени прилагательного) ветер – ветреный, серебро- серебряный и отглагольные (воспитать – воспитанный).
На доске проецируется таблица.
-н- и –нн- в суффиксах прилагательных.
|
-н- пишется: |
-нн- пишется: |
|
1) в отыменных прилагательных: А)в суффиксах –ан-, -ян- Кожа – кожаный Серебро – серебряный Исключения: стеклянный, оловянный, деревянный; Б) в отыменных прилагательных с суффиксом –ин- Гусиный, гостиная
|
1) на стыке корня и суффикса: Луна – лунный; стена – настенный,
|
|
2) в отглагольных прилагательных: А) образованных от форм несовершенного вида в суффиксах –ен-, -ён-, -ан-, -ян-: Ходить – хоженый Носит – ношены Мудрить – мудреный Звать – званый Рдеть –рдяный Исключения:
желанный, деланный, невиданный, неслыханный, нежданный, негаданный,
нечаянный. Б) в составе сложных слов: Гладкокрашеный, домотканый, малоношеный
|
2) в отыменных прилагательных с суффиксами –енн- и –онн-: Буква- буквенный, свойство- свойственный, лекция- лекционный |
|
|
3) в суффиксах –енн-, -ённ-, -анн-, -янн- в отглагольных прилагательных, образованных от форм совершенного вида: Выходить – выхоженный Поносить – поношенный Смирить- смиренный Растерять- растерянный Исключения: названый брат, посаженый отец, приданое (невесты)
|
|
|
4) в отглагольных прилагательных с суффиксами –ованн- (ёванн): Рисковать –рискованный Циклевать – циклеванный |
|
В
сочетаниях «глаженые-переглаженые брюки», «латаная-перелатаная шуба»,
«ношеный-переношеный костюм». |
Примечание: в прилагательных кованый, жёваный пишется одна буква –н- |
 Отчаянный, священный, нетленный, недреманный;
Отчаянный, священный, нетленный, недреманный; «штопаные-перештопаные носки»
«штопаные-перештопаные носки»
А чтобы вы хотели добавить сами? (масленый, масляной, слова-исключения, не указанные в учебнике: пряный, румяный, юный, ветреный, ветряная мельница).
Различие написания слов:
1) ветреный (день, юноша) (т.е. легкомысленный), ветряная (мельница, оспа), но безветренный;
2)масленый (блин, каша) (т.е. смазанный маслом), — масленый взгляд (образное словоупотребление)
Масляный (из масла, от масла) – масляное пятно, краски.
Запомни: в словах, образованных от основ на –ск-, -ч-, -ц- перед суффиксом –н- или перед суффиксами, начинающимися с –н-, пишется –ч- (хотя в некоторых из этих слов произносится –ш-):
Скука – скучный, скворец – скворечня. Так же пишутся женские отчества, образованные от мужских на –ич- (Никитич – Никитична).
В отдельных словах пишется – шн-: двурушник
(ср.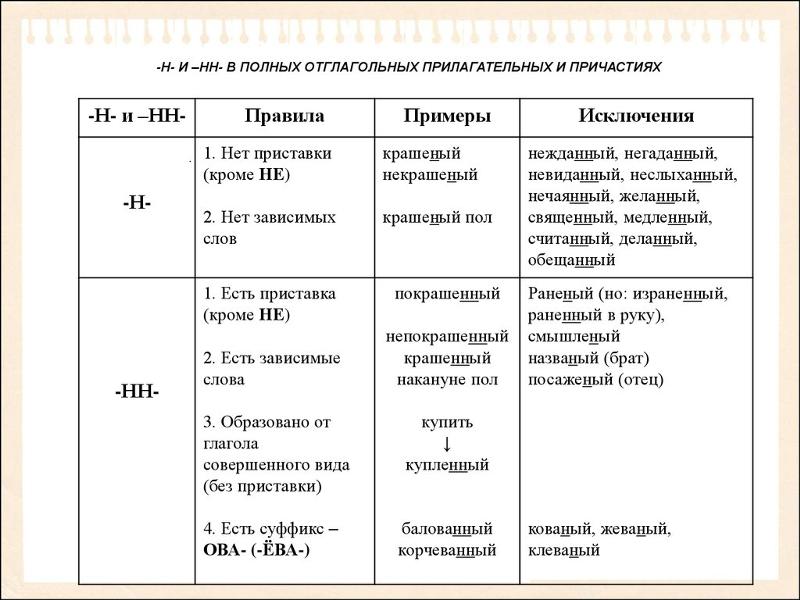 рука). В словах, образованных от основ на –х-, перед суффиксом –н- пишется-
ш- (золотуха – золотушный).
рука). В словах, образованных от основ на –х-, перед суффиксом –н- пишется-
ш- (золотуха – золотушный).
Вспомним также о правописании существительных: труженик, масленица, пудреница, вареник, ветреница, мудреность, смышленость (все эти слова записываются в тетради).
. Появляется первый тест на интерактивной доске. Он выполняется на доске с комментариями.
Пчели..ый, бараба..ый, оловя..ый, песча..ый, лекарстве..ый, комари..ый, урага..ый, ледя..ой, це..ый, деревя..ый, клюкве..ый, осе..ий, революцио..ый, плятя..ой, лу..ый.
— Сейчас вспомним суффиксы –н и –нн- в причастиях (по учебнику)
Как можно отличить прилагательное от причастия? (Если нет зависимых слов и нет приставки, то это прилагательное: груженый вагон, вязаная кофта. В кратких прилагательных пишется столько –н-, сколько в полных). Но в кратких причастиях всегда пишется одна буква –н-.
1) Краткие отглагольные прилагательные можно отличить
от кратких причастий тем, что они не имеют после себя дополнения, отвечающего
на вопрос «чем? Кем?».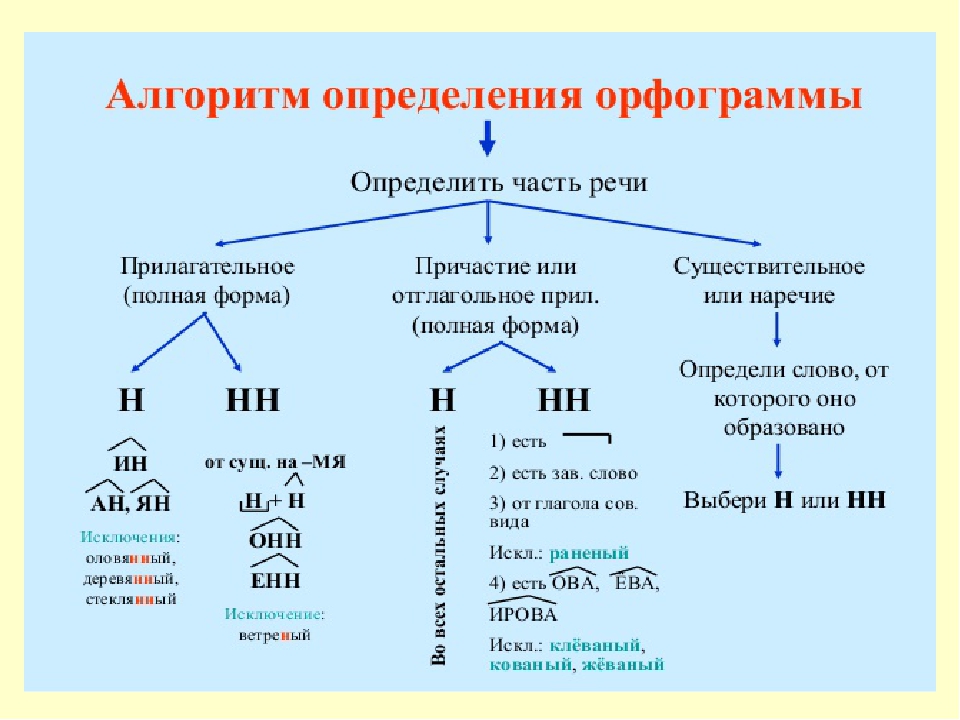
Например. Население было собрано начальником гарнизона. Она воспитана в строгих правилах. Краткие причастия отличаются возможностью трансформации в глагол.
2) Краткие прилагательных можно заменить другими прилагательными.
Девушка начитанна (умна, эрудированна).
Закрепим наши теоретические знания практическим заданием.
Выполним тест №2.
Стулья завале..ы книгами
Лома..ая линия
Копче..ая рыба
Замороже..ое филе
Поджаре..ая колбаса
Гримирова..ый артист
Лица вымаза..ы сажей
Лома..ый грош
Машина заправле..а
Ягоды подавле..ы в корзине
Каша сваре..а
Запута..ые нитки
Пута..ые мысли
Плете..ая из ивняка корзина
— Усложнение задачи: необходимо определить, в какой части речи прощена буква.
Тест №3
Бесчисле..ое ( ) Фарширова..ый ( )
Письме..ый (
) Слома.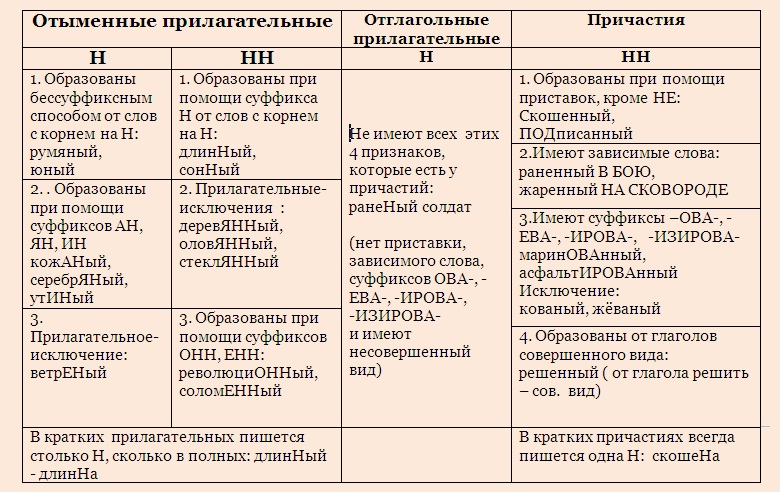 .ый ( )
.ый ( )
Провере..ый ( ) Бесце..ый ( )
Перегруже..ый ( ) Купле..ый ( )
Рва..ый ( ) Порва..ый ( 0
Ветре..ый ( ) Соломе..ый ( )
Закопче..ый ( ) Разорва..ый ( )
Чем вы руководствовались при определении частей речи? Сколько –н- пишется в наречиях? )в наречиях пишется столько –н-, сколько в словах, от которых они образованы. В предложении наречие всегда является обстоятельством).
В следующем тесте необходимо отличить наречие от прилагательного и причастия.
Тест №4
Распределите словосочетания по колонкам таблицы
|
Наречия отвечают на вопрос КАК?
|
Краткие прилагательные и причастия отвечают на вопрос КАКОВ? |
|
|
|
Смотрел удивленно, раздражен шумом, мышцы напряжены,
походка медленна, помощь обеспечена, все удивлены, поступил совершенно
правильно, жил обеспеченно, говорил раздраженно, работали напряженно, шел
медленно, конструкция совершенна.
Обобщение.
— Какие разделы науки о языке мы вспомнили? (Орфоэпия, словообразование, морфология, морфемика, синтаксис).
Домашнее задание.
Подведение итогов урока
ПРАВОПИСАНИЕ -Н-, -НН- В СУФФИКСАХ ПРИЧАСТИЙ И ОТГЛАГОЛЬНЫХ ПРИЛАГАТЕЛЬНЫХ. ТРУДНЫЕ ВОПРОСЫ ПРАВОПИСАНИЯ ОКОНЧАНИЙ РАЗНЫХ ЧАСТЕЙ РЕЧИ | Поурочные планы по русскому языку 10 класс
Урок 24. ПРАВОПИСАНИЕ —Н-, -НН- В СУФФИКСАХ
ПРИЧАСТИЙ И ОТГЛАГОЛЬНЫХ ПРИЛАГАТЕЛЬНЫХ.
ТРУДНЫЕ ВОПРОСЫ ПРАВОПИСАНИЯ ОКОНЧАНИЙ
РАЗНЫХ ЧАСТЕЙ РЕЧИ
Цель: совершенствовать навык применения
основных типов орфограмм – правописания -н- и -нн- в суффиксах
причастий и отглагольных прилагательных, правописания окончаний разных частей
речи, изученных в 5–9 классах, порядок действий при решении орфографических
задач.
Тип урока: комбинированный.
Методы: исследовательский, самостоятельная работа, письменный самоконтроль, выработка и совершенствование усвоенных навыков.
Ход урока
1. Этап актуализации субъектного опыта учащихся.
1. Орфоэпическая пятиминутка в рамках подготовки к ЕГЭ (задание А1).
2. Задание «Дай толкование слова» (задание А2).
3. Проверка знаний по теме «-н- и -нн- в существительных, прилагательных и наречиях».
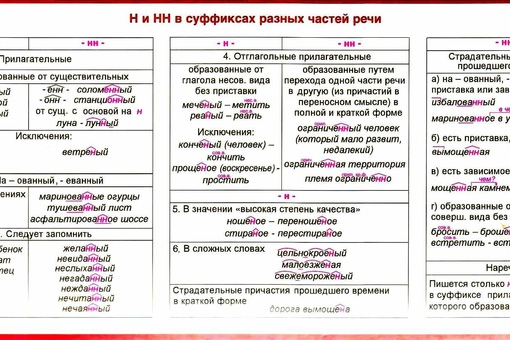
С этой целью учитель отводит специальное время для самостоятельной работы с таблицей. Учащиеся воспроизводят в памяти основные правила, зафиксированные в левой части таблицы (по вертикали) и, сопоставляя их (записи по горизонтали), находят общие и отличительные черты.
После самостоятельной работы важно
проверить уровень понимания материала всеми учащимися класса. К доске
вызывается сильный ученик, который записывает формулы изученных правил и
примеры к ним. (Впоследствии запись будет проанализирована всеми учащимися.)
(Впоследствии запись будет проанализирована всеми учащимися.)
Пока ученик готовится у доски, класс под диктовку учителя записывает слова, комментирует правописание -н- и -нн-, указывая в скобках формулы правил (слова: картинный, серебряный, мышиный, революционный, государственный, оловянный, ценно и др.).
Возможны и небольшие индивидуальные задания на карточках, проверяющие, как усвоили правила отдельные ученики. В карточки могут быть включены задания такого типа: заполнить таблицу; объяснить графически правописание —н— и —нн— в прилагательных: деревянный, жестяной, муравьиный, стеклянный, оккупационный, юный, сонный, лошадиный, лиственный, серебряный. Другой тип задания: продолжить перечень примеров, записать формулу правила к каждому из них: гусиный; земляной; конституционный; покажите, как образовались слова: петушиный, длинный, жизненный, лебединый, миллионный, водяной, ценно, законно.
Рядом со словом записать формулу
правила.
2. Этап организации совместной деятельности по освоению материала урока.
Материал для наблюдения.
Учитывая сложность этого материала, учитель большую часть работы должен взять на себя, а все записи в таблицу лучше сделать после анализа примеров, наблюдений и выводов.
Вначале на доске и в тетрадях записываются словосочетания, в которые входят прилагательные и причастия: беленая комната – беленная хозяйкой комната, груженая баржа – груженная арбузами баржа.
– Посмотрите, чем отличаются эти словосочетания? (Во второй группе словосочетаний (справа) есть зависимые слова, в первой – их нет.)
– В каких случаях пишется —н— и —нн-?
– Какой вывод можно сделать? (В отглагольных прилагательных пишем —н-, при них нет зависимого слова; в полных причастиях пишем —нн— при них есть зависимое слово.)
Проанализируем еще несколько
примеров отглагольных прилагательных с -н- и причастий с -нн-:
путаный ответ – запутанный ответ; кошеная трава – скошенная трава (но: некошеная
трава).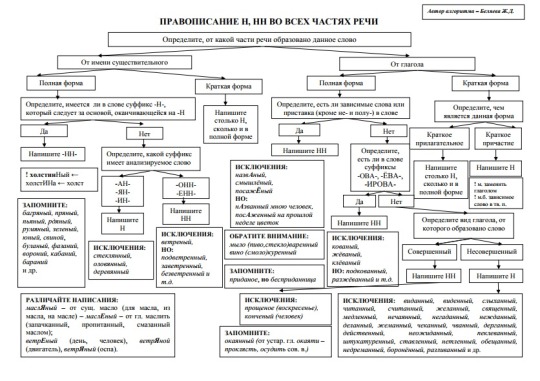
– Чем еще, кроме -н- и -нн-, отличаются по составу однокоренные слова? Обозначьте графически эту часть. Выделите приставки за-, с-.
– Сколько -н- в словах первой группы и второй? (В первой -н-, во второй -нн-.)
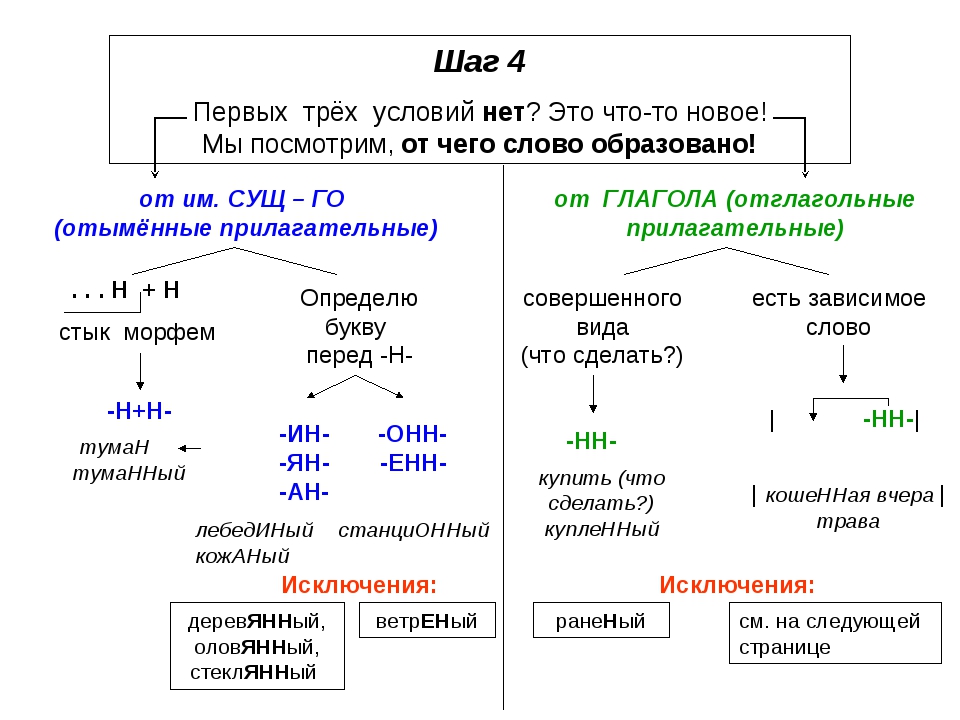
– Сделайте вывод о правописании -н- и -нн-. (В отглагольных прилагательных без приставки пишется н, в причастиях и отглагольных прилагательных с приставкой – —нн-, но это не относится к приставке не-, кроме того, есть слова-исключения: смышленый, посаженый.)
Формула правила:
– Причастия могут употребляться как в полной, так и в краткой форме. Запишите примеры: трава скошена, книги прочитаны.
– Сколько -н- написано в подчеркнутых словах? (Одна буква -н-.) Какой вывод напрашивается? (В кратких причастиях всегда -н-.)
– Выполните словообразовательный
разбор следующих слов: рискованный – рисковать; образованный – образовать. Обратите внимание на то, что в отглагольных прилагательных с -ованн-, -еванн-
пишется -нн- (исключения: кованый, жеваный).
Обратите внимание на то, что в отглагольных прилагательных с -ованн-, -еванн-
пишется -нн- (исключения: кованый, жеваный).
3. Этап первичной проверки понимания изученного.
Подведем итоги теоретического анализа темы:
– в полных причастиях с зависимыми словами или приставками и в отглагольных прилагательных с приставками (кроме не-) пишется -нн-;
– в кратких причастиях -н-;
– в отглагольных прилагательных с -ованн-, -еванн- пишется -нн-.
Таблица приобретает следующий вид:
|
Основные |
Части речи |
Формула |
||||
|
Первый блок |
Второй блок |
|||||
|
прилагательное |
существительное |
наречие |
причастие (полное, |
отглагольные прилагательные |
||
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
1. |
пленный ? плен + + ый |
пленник ? плен + + ник |
|
|
|
|
|
2. Слова, образованные с по-мощью |
станци-? станция, торжест? торжество |
|
|
|
|
|
|
3. Слова, образованные от существительных с помощью ? н Исключения: |
но: стеклянный, оловянный, деревянный |
|
|
|
|
|
|
4. |
|
|
торжественно ? торжественный, искренне ? искренний, плотно ? плотный |
|
|
нн ? нн н ? н |
 Слова, образованные с помощью н от ос-новы
на н ? нн
Слова, образованные с помощью н от ос-новы
на н ? нн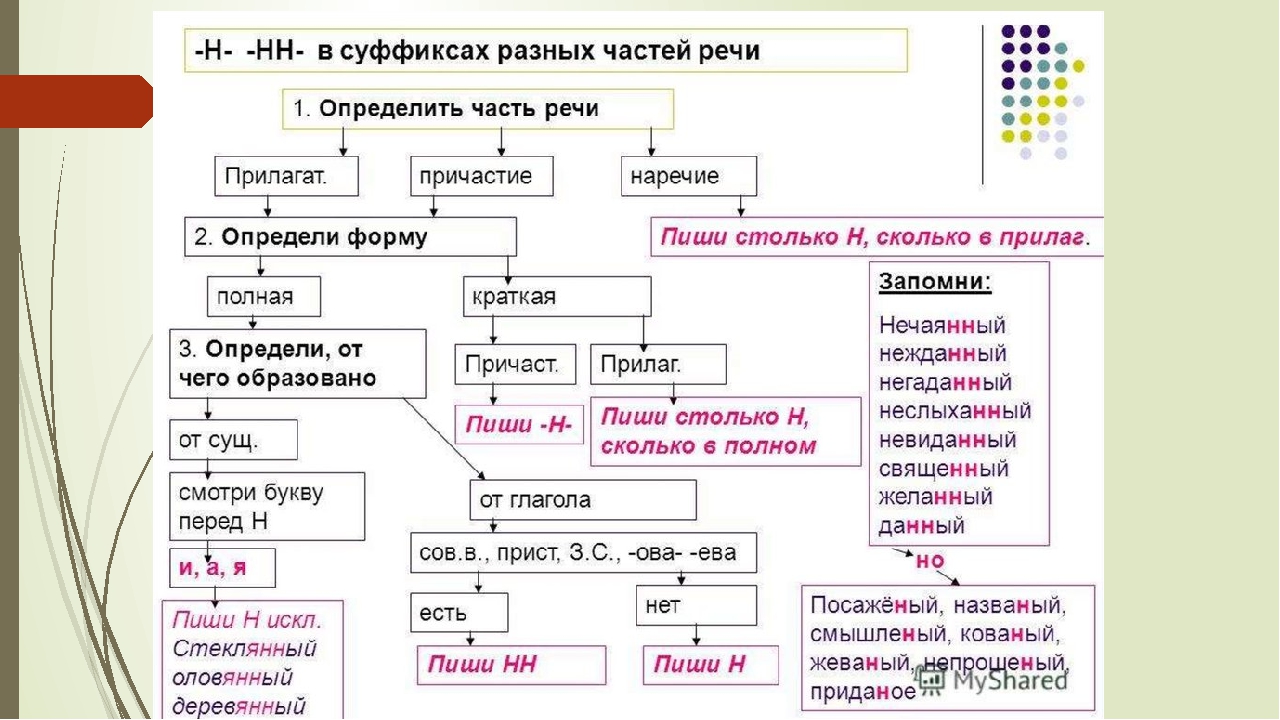 Столько н, сколько в слове, от которого оно
образовано
Столько н, сколько в слове, от которого оно
образованоОкончание табл.
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
5. Наличие (+), отсутствие (–) приставок, зависимых слов
Исключения: |
|
|
|
Запутанный ответ, |
|
+ (кроме не-) ? нн + ? нн – (+ не-)? н – ? н |
|
6. Всегда н |
|
|
|
Задача решена (краткое страдательное причас-тие) |
|
н (всегда) только |
|
7. Наличие (+), отсутствие (–) -ованн-, —еванн— Исключения: |
|
|
|
Организационная работа |
|
+ —ованн— (-еванн-) ? нн |
 Смышленый, названый (брат), посаженый
(отец)
Смышленый, названый (брат), посаженый
(отец)
Визуализация PosTag — Документация Yellowbrick v1.
 3.post1
3.post1 from yellowbrick.text import PosTagVisualizer
tagged_stanzas = [
[
[
(«Чей», «JJ»), («лес», «NNS»), («эти», «DT»),
('являются', 'ВБП'),('Я', 'ПРП'),('думаю', 'ВБП'),('Я', 'ПРП'),
('знать', 'ВБП'), ('.', '.')
],
[
('Его', 'PRP$'),('дом', 'NN'),('есть', 'ВБЗ'),('в', 'В'),
('the', 'DT'), ('деревня', 'NN'), ('хотя', 'IN'), (';', ':'),
(«Он», «PRP»), («будет», «MD»), («не», «RB»), («см.», «VB»),
('я', 'PRP'), ('остановка', 'VBG'), ('здесь', 'RB'), ('Куда', 'Куда'),
('смотреть', 'VB'),('его', 'PRP$'),('лес', 'NNS'),('заполнить', 'VB'),
('вверх', 'RP'),('с', 'IN'),('снег', 'NNS'),('.', '.')
]
],
[
[
('Мой', 'PRP$'),('маленький', 'JJ'),('лошадь', 'NN'),('должен', 'MD'),
(«думаю», «VB»), («это», «PRP»), («педик», «JJR»), («до», «до»),
('стоп', 'VB'),('без', 'IN'),('a', 'DT'),('ферма', 'NN'),
('рядом', 'В'), ('Между', 'NNP'), ('the', 'DT'), ('лес', 'NNS'),
('и', 'CC'), ('замороженный', 'JJ'), ('озеро', 'VB'), ('The', 'DT'),
(«Самый темный», «JJS»), («Вечер», «NN»), («Из», «В»), («The», «DT»),
('год', 'NN'),('. ', '.')
]
],
[
[
('Он', 'ПРП'),('дает', 'ВБЗ'),('его', 'ПРП$'),('упряжь', 'НН'),
('колокольчики', 'ВБЗ'),('а', 'ДТ'),('трясти', 'НН'),('Ку', 'К'),
('спросить', 'ВБ'),('если', 'В'),('там', 'EX'),('есть', 'ВБЗ'),
('некоторые', 'DT'),('ошибка', 'NN'),('.', '.')
],
[
(«The», «DT»), («только», «JJ»), («другое», «JJ»), («звук», «NN»),
(''', 'NNP'), ('s', 'VBZ'), ('the', 'DT'), ('развертка', 'NN'),
('Из', 'В'),('легко', 'JJ'),('ветер', 'NN'),('и', 'CC'),
('пушистый', 'JJ'),('чешуйчатый', 'NN'),('.', '.')
]
],
[
[
(«The», «DT»), («woods», «NNS»), («are», «VBP»), («прекрасный», «RB»),
(',', ','),('темный', 'JJ'),('и', 'CC'),('глубокий', 'JJ'),(',', ','),
(«Но», «КК»), («Я», «ПРП»), («имею», «ВБП»), («обещает», «ННС»),
('to', 'TO'),('держать', 'VB'),(',', ','),('И', 'CC'),('мили', 'NNS'),
('до', 'ДО'), ('идти', 'ВБ'), ('до', 'В'), ('я', 'ПРП'),
('сон', 'VBP'), (',', ','), ('И', 'CC'), ('мили', 'NNS'),
('до', 'ДО'), ('идти', 'ВБ'), ('до', 'В'), ('я', 'ПРП'),
('сон', 'ВБП'),('.
', '.')
]
],
[
[
('Он', 'ПРП'),('дает', 'ВБЗ'),('его', 'ПРП$'),('упряжь', 'НН'),
('колокольчики', 'ВБЗ'),('а', 'ДТ'),('трясти', 'НН'),('Ку', 'К'),
('спросить', 'ВБ'),('если', 'В'),('там', 'EX'),('есть', 'ВБЗ'),
('некоторые', 'DT'),('ошибка', 'NN'),('.', '.')
],
[
(«The», «DT»), («только», «JJ»), («другое», «JJ»), («звук», «NN»),
(''', 'NNP'), ('s', 'VBZ'), ('the', 'DT'), ('развертка', 'NN'),
('Из', 'В'),('легко', 'JJ'),('ветер', 'NN'),('и', 'CC'),
('пушистый', 'JJ'),('чешуйчатый', 'NN'),('.', '.')
]
],
[
[
(«The», «DT»), («woods», «NNS»), («are», «VBP»), («прекрасный», «RB»),
(',', ','),('темный', 'JJ'),('и', 'CC'),('глубокий', 'JJ'),(',', ','),
(«Но», «КК»), («Я», «ПРП»), («имею», «ВБП»), («обещает», «ННС»),
('to', 'TO'),('держать', 'VB'),(',', ','),('И', 'CC'),('мили', 'NNS'),
('до', 'ДО'), ('идти', 'ВБ'), ('до', 'В'), ('я', 'ПРП'),
('сон', 'VBP'), (',', ','), ('И', 'CC'), ('мили', 'NNS'),
('до', 'ДО'), ('идти', 'ВБ'), ('до', 'В'), ('я', 'ПРП'),
('сон', 'ВБП'),('.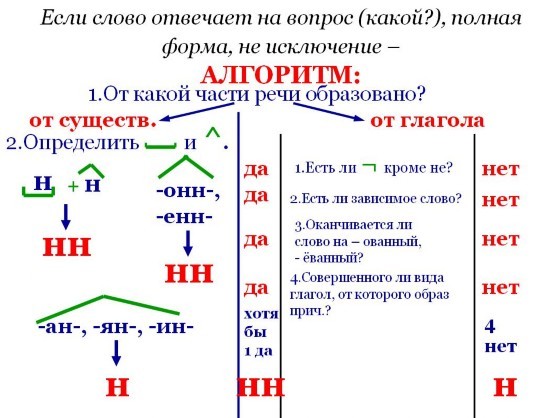 ', '.')
]
]
]
# Создайте визуализатор, подгоните, оцените и покажите его
а именно = PosTagVisualizer()
а именно.fit(tagged_stanzas)
а именно.show()
', '.')
]
]
]
# Создайте визуализатор, подгоните, оцените и покажите его
а именно = PosTagVisualizer()
а именно.fit(tagged_stanzas)
а именно.show()
Маркировка POS с помощью NLTK и фрагментация в NLP [ПРИМЕРЫ]
Маркировка POS
Маркировка POS (маркировка частей речи) — это процесс разметки слов в текстовом формате для определенной части речи на основе ее определения и контекста. Он отвечает за чтение текста на языке и присвоение каждому слову определенного токена (части речи).Это также называется грамматической маркировкой.
Давайте научимся на примере части речи NLTK:
Ввод: Все, что нам разрешат.
Вывод: [(‘Все’, NN),(‘to’, TO), (‘разрешение’, VB), (‘нас’, PRP)]
В этом уроке вы узнаете —
шагов, задействованных в примере с маркировкой POS:
- Токенизировать текст (word_tokenize)
- применить pos_tag к предыдущему шагу, то есть nltk.
 pos_tag(tokenize_text)
pos_tag(tokenize_text)
Теги NLTK POS Примеры приведены ниже:
| Сокращение | Значение |
|---|---|
| СС | координационное соединение |
| CD | кардинальное число |
| ДТ | определитель |
| ЕХ | экзистенциальный там |
| ФВ | иностранное слово |
| В | предлог/подчинительный союз |
| ДЖ | Этот тег NLTK POS является прилагательным (большим) |
| Дж.Дж.Р. | прилагательное, сравнительное (большее) |
| JJS | прилагательное в превосходной степени (самый большой) |
| ЛС | рынок списка |
| МД | модальный (может, будет) |
| НН | существительное в единственном числе (кошка, дерево) |
| ННС | существительное во множественном числе (столы) |
| ННП | имя собственное, единственное число (сара) |
| NNPS | имя собственное во множественном числе (индейцы или американцы) |
| ФДТ | предопределитель (все, оба, половина) |
| POS | притяжательное окончание (родительское) |
| ПРП | личное местоимение (её, сама, он, сам) |
| PRP$ | притяжательное местоимение (ее, его, мой, мой, наш) |
| РБ | наречие (иногда быстро) |
| РБР | наречие, сравнительное (большее) |
| РБС | наречие в превосходной степени (самый большой) |
| РП | частица (о) |
| К | бесконечный маркер (до) |
| UH | междометие (до свидания) |
| ВБ | глагол (спросить) |
| ВБГ | глагол герундий (суждение) |
| ВБД | глагол в прошедшем времени (умоляющий) |
| ВБН | причастие прошедшего времени глагола (воссоединенное) |
| ВБП | глагол в настоящем времени, а не в 3-м лице единственного числа (обтекание) |
| ВБЗ | глагол в настоящем времени с 3-м лицом единственного числа (основания) |
| ВДТ | бел-определитель (что, что) |
| WP | WH- местоимение (кто) |
| ВРБ | WH- наречие (как) |
Приведенный выше список тегов NLTK POS содержит все теги NLTK POS. Теггер NLTK POS используется для присвоения грамматической информации каждому слову предложения. Установка, импорт и загрузка всех пакетов POS NLTK завершены.
Теггер NLTK POS используется для присвоения грамматической информации каждому слову предложения. Установка, импорт и загрузка всех пакетов POS NLTK завершены.
Что такое фрагментация в НЛП?
Разделение на фрагменты в НЛП — это процесс, при котором небольшие фрагменты информации объединяются в большие блоки. Основное использование Chunking — это создание групп «именных словосочетаний». Он используется для добавления структуры к предложению, следуя тегам POS в сочетании с регулярными выражениями.Полученная группа слов называется «кусками». Его также называют поверхностным разбором.
При неглубоком разборе между корнями и листьями может быть максимум один уровень, а при глубоком анализе более одного уровня. Поверхностный синтаксический анализ также называется легким синтаксическим анализом или фрагментированием.
Правила разделения:
Предустановленных правил нет, но вы можете комбинировать их по мере необходимости.
Например, вам нужно пометить существительное, глагол (прошедшее время), прилагательное и координирующее соединение из предложения. Вы можете использовать правило, как показано ниже
Вы можете использовать правило, как показано ниже
чанк: {
В следующей таблице показано, что означают различные символы:
| Наименование символа | Описание |
|---|---|
| . | Любой символ, кроме новой строки |
| * | Совпадение с 0 или более повторениями |
| ? | Совпадение с 0 или 1 повторением |
Теперь давайте напишем код, чтобы лучше понять правило
из nltk импортировать pos_tag
из nltk импортировать RegexpParser
text ="Изучай php у guru99 и учись легко".расколоть()
print("После разделения:",текст)
tokens_tag = pos_tag(текст)
print("После токена:",tokens_tag)
Patterns= """mychunk:{***?}"""
чанкер = RegexpParser(шаблоны)
print("После регулярного выражения:",чанкер)
вывод = chunker.parse (токен_тег)
print("После разбивки", вывод)
Вывод:
После разделения: ['учиться', 'php', 'от', 'guru99', 'и', 'сделать', 'изучить', 'легко']
После токена: [('learn', 'JJ'), ('php', 'NN'), ('from', 'IN'), ('guru99', 'NN'), ('and', ' CC'), ('сделать', 'VB'), ('учиться', 'NN'), ('легко', 'JJ')]
После регулярного выражения: chunk. RegexpParser с 1 этапом:
RegexpChunkParser с 1 правилом:
RegexpParser с 1 этапом:
RegexpChunkParser с 1 правилом:
***?'>
После разделения (S
(mychunk учиться/JJ)
(mychunk php/NN)
из/в
(mychunk guru99/NN и/CC)
сделать/VB
(mychunk этюд/NN easy/JJ))
Вывод из приведенного выше примера с тегами частей речи Python: «make» — это глагол, который не включен в правило, поэтому он не помечен как mychunk
Вариант использования фрагментации
Чанкирование используется для обнаружения объектов.Сущность — это часть предложения, с помощью которой машина получает значение для любого намерения.
Пример: Температура Нью-Йорка. Здесь Температура — это намерение, а Нью-Йорк — сущность.
Другими словами, фрагментация используется для выбора подмножества токенов. Пожалуйста, следуйте приведенному ниже коду, чтобы понять, как используется фрагментация для выбора токенов. В этом примере вы увидите график, который будет соответствовать фрагменту словосочетания. Напишем код и нарисуем график для лучшего понимания.
Напишем код и нарисуем график для лучшего понимания.
Код для демонстрации варианта использования
импорт нлтк
text = "изучайте php у guru99"
токены = nltk.word_tokenize(текст)
печать (токены)
тег = nltk.pos_tag (токены)
печать (тег)
грамматика = "NP: {Вывод:
['learn', 'php', 'from', 'guru99'] -- это токены
[('learn', 'JJ'), ('php', 'NN'), ('from', 'IN'), ('guru99', 'NN')] -- это pos_tag
(S (NP Learn/JJ php/NN) from/IN (NP guru99/NN)) -- Разделение именных фраз
График
Фраза существительного фрагментация графика
Из графика можно сделать вывод, что «learn» и «guru99» — это две разные лексемы, но они классифицируются как фраза существительного, тогда как лексема «от» не принадлежит фразе существительного.
Разделение на фрагменты используется для группировки различных токенов в один и тот же фрагмент. Результат будет зависеть от выбранной грамматики. Дальнейшее разделение NLTK используется для маркировки шаблонов и изучения текстовых корпусов.
СЧЁТНЫЕ POS-ТЕГИ
Мы обсуждали различные pos_tag в предыдущем разделе. В этом конкретном руководстве вы узнаете, как считать эти теги. Теги подсчета имеют решающее значение для классификации текста, а также для подготовки функций к операциям на основе естественного языка.Я буду обсуждать с вами подход, которого придерживался guru99 при подготовке кода, а также обсуждение вывода. Надеюсь, что это поможет вам.
Как считать Метки:
Сначала мы напишем рабочий код, а затем напишем различные шаги для объяснения кода.
из коллекций Счетчик импорта импортировать нлтк text = "Guru99 — один из лучших сайтов для изучения WEB, SAP, этического взлома и многого другого в Интернете." нижний регистр = текст.нижний() токены = nltk.word_tokenize (нижний регистр) теги = nltk.pos_tag (токены) counts = Counter(тег для слова, тег в тегах) печать (количество)
Вывод:
Counter({‘NN’: 5, ‘,’: 2, ‘TO’: 1, ‘CC’: 1, ‘VBZ’: 1, ‘NNS’: 1, ‘CD’: 1, ‘.’: 1, ‘DT’: 1, ‘JJS’: 1, ‘JJ’: 1, ‘JJR’: 1, ‘IN’: 1, ‘VB’: 1, ‘RB’: 1})
Разработка кода
- Для подсчета тегов можно использовать пакет Counter из модуля коллекции. Счетчик — это подкласс словаря, который работает по принципу операции ключ-значение.Это неупорядоченная коллекция, в которой элементы хранятся в виде ключа словаря, а количество — это их значение.
- Импортировать nltk, который содержит модули для разметки текста.
- Напишите текст, pos_tag которого вы хотите подсчитать.
- Некоторые слова в верхнем регистре, а некоторые в нижнем регистре, поэтому целесообразно преобразовать все слова в нижний регистр перед применением токенизации.

- Передайте слова через word_tokenize из nltk.
- Рассчитать pos_tag каждого токена
Вывод = [('guru99', 'NN'), ('is', 'VBZ'), ('one', 'CD'), ('of', 'IN'), ('the', ' DT'), ('лучший', 'JJS'), ('сайт', 'NN'), ('куда', 'КОМУ'), ('учиться', 'VB'), ('веб', ' NN'), (',', ','), ('sap', 'NN'), (',', ','), ('этический', 'JJ'), ('взлом', ' NN'), ('и', 'CC'), ('много', 'RB'), ('больше', 'JJR'), ('онлайн', 'JJ')] - Теперь приходит роль счетчика словаря.Мы импортировали в строку кода 1. Слова — это ключ, а теги — это значение, и счетчик будет подсчитывать общее количество тегов, присутствующих в тексте.
Распределение частот
Распределение частоты определяется как количество раз, когда результат эксперимента встречается. Он используется для определения частоты встречаемости каждого слова в документе. Он использует FreqDistclass и определяется модулем nltk.probabilty .
Частотное распределение обычно создается путем подсчета выборок многократно проводимого эксперимента. Количество счетчиков увеличивается на единицу каждый раз. Например.
Количество счетчиков увеличивается на единицу каждый раз. Например.
freq_dist = FreqDist()
для токена в документе:
freq_dist.inc(токен.тип())
Для любого слова мы можем проверить, сколько раз оно встречалось в том или ином документе. Например.
- Метод подсчета: freq_dist.count(‘and’) Это выражение возвращает значение количества раз, когда встречается ‘and’. Он называется методом подсчета.
- Частотный метод: freq_dist.freq(‘and’) Это выражение возвращает частоту заданной выборки.
Мы напишем небольшую программу и подробно объясним ее работу. Мы напишем какой-нибудь текст и посчитаем частотное распределение каждого слова в тексте.
импорт нлтк a = "Guru99 — это сайт, на котором можно найти лучшие учебные пособия по Учебнику по тестированию программного обеспечения, Курсу SAP для начинающих. Учебнику по Java для начинающих и многому другому. Пожалуйста, посетите сайт guru99.com и многое другое." слова = нлтк.tokenize.word_tokenize(а) fd = nltk.FreqDist(слова) fd.plot()
Расшифровка кода:
- Импорт модуля nltk.
- Напишите текст, распределение слов которого нужно найти.
- Маркировать каждое слово в тексте, который служит входом для модуля FreqDist nltk.
- Применить каждое слово к nlk.FreqDist в виде списка
- Нанесите слова на график с помощью plot()
Пожалуйста, визуализируйте график для лучшего понимания написанного текста
Частотное распределение каждого слова на графике
ПРИМЕЧАНИЕ. Для просмотра приведенного выше графика необходимо установить matplotlib.
Обратите внимание на график выше.Это соответствует подсчету появления каждого слова в тексте. Это помогает в изучении текста и в дальнейшем в реализации текстового сентиментального анализа. Вкратце можно сделать вывод, что в nltk есть модуль для подсчета встречаемости каждого слова в тексте, который помогает в подготовке статистики особенностей естественного языка. Он играет значительную роль в поиске ключевых слов в тексте. Вы также можете извлечь текст из PDF-файла, используя такие библиотеки, как Extract, PyPDF2 и отправить текст в nlk.Частот.расст.
Он играет значительную роль в поиске ключевых слов в тексте. Вы также можете извлечь текст из PDF-файла, используя такие библиотеки, как Extract, PyPDF2 и отправить текст в nlk.Частот.расст.
Ключевой термин — «токенизация». После токенизации он проверяет каждое слово в заданном абзаце или текстовом документе, чтобы определить, сколько раз оно встречалось. Для этого вам не нужен набор инструментов NLTK. Вы также можете сделать это, используя собственные навыки программирования на Python. Инструментарий NLTK предоставляет только готовый к использованию код для различных операций.
Подсчет каждого слова может оказаться бесполезным. Вместо этого следует сосредоточиться на словосочетаниях и биграммах, которые имеют дело с большим количеством слов в паре.Эти пары определяют полезные ключевые слова для улучшения функций естественного языка, которые можно передать машине. Пожалуйста, смотрите ниже для их деталей.
Словосочетания: биграммы и триграммы
Что такое словосочетания?
Словосочетания — это пары слов, многократно встречающиеся в документе вместе. Он рассчитывается по количеству этих пар, встречающихся вместе, в общем количестве слов в документе.
Он рассчитывается по количеству этих пар, встречающихся вместе, в общем количестве слов в документе.
Рассмотрите электромагнитный спектр с помощью таких слов, как ультрафиолетовые лучи, инфракрасные лучи.
Слова ультрафиолет и лучи не используются по отдельности и, следовательно, могут рассматриваться как словосочетание. Другой пример — компьютерная томография. Мы не говорим «КТ» и «Сканирование» по отдельности, поэтому они также рассматриваются как словосочетание.
Можно сказать, что поиск словосочетаний требует вычисления частоты слов и их появления в контексте других слов. Эти определенные наборы слов требуют фильтрации, чтобы сохранить термины полезного содержания. Затем каждый грамм слов может быть оценен в соответствии с некоторой ассоциативной мерой, чтобы определить относительную вероятность того, что каждый инграм является словосочетанием.
Коллокацию можно разделить на два типа:
- Биграммы c Комбинация двух слов
- Триграммы Комбинация из трех слов
Биграммы и триграммы предоставляют более значимые и полезные функции для этапа извлечения признаков. Они особенно полезны при текстовом сентиментальном анализе.
Они особенно полезны при текстовом сентиментальном анализе.
Биграмм Пример кода
импорт нлтк text = "Guru99 — это совершенно новый вид обучения." Токены = nltk.word_tokenize(текст) вывод = список (nltk.bigrams (токены)) печать (вывод)
Вывод:
[('Гуру99', 'есть'), ('есть', 'полностью'), ('совершенно', 'новый'), ('новый', 'вид'), ('вид', 'из' ), ('из', 'обучение'), ('обучение', 'опыт'), ('опыт', '.')]
Триграммы Пример кода
Иногда становится важно увидеть в предложении пару-тройку слов для статистического анализа и подсчета частоты. Это снова играет решающую роль в формировании НЛП (функций обработки естественного языка), а также сентиментального предсказания на основе текста.
Тот же код запускается для вычисления триграмм.
импорт нлтк text = «Guru99 — это совершенно новый вид обучения». Токены = nltk.word_tokenize(текст) вывод = список (nltk.trigrams (токены)) печать (вывод)
Вывод:
[('Гуру99', 'есть', 'совершенно'), ('есть', 'совершенно', 'новый'), ('совершенно', 'новый', 'вид'), ('новый', ' вид', 'из'), ('вид', 'из', 'обучение'), ('из', 'обучение', 'опыт'), ('обучение', 'опыт', '. ')]
')]
Пометка предложений
Tagged Sentence в более широком смысле относится к добавлению меток глагола, существительного и т. д., по контексту предложения. Идентификация POS-тегов — сложный процесс. Таким образом, общая маркировка POS вручную невозможна, поскольку некоторые слова могут иметь разные (неоднозначные) значения в зависимости от структуры предложения. Преобразование текста в виде списка является важным шагом перед тегированием, так как каждое слово в списке зацикливается и подсчитывается для определенного тега. Пожалуйста, посмотрите код ниже, чтобы понять его лучше
импорт нлтк text = "Здравствуйте, Guru99, Вы должны создать очень хороший сайт, и я люблю посещать ваш сайт." предложение = nltk.sent_tokenize(текст) для отправленного в предложении: печать (nltk.pos_tag (nltk.word_tokenize (отправлено)))
Вывод:
[(‘Здравствуйте’, ‘ННП’), (‘Гуру99’, ‘ННП’), (‘,’, ‘,’), (‘Вы’, ‘ПРП’), (‘есть’, ‘ВБП’) , (‘сборка’, ‘VBN’), (‘a’, ‘DT’), (‘очень’, ‘RB’), (‘хорошо’, ‘JJ’), (‘сайт’, ‘NN’) , (‘и’, ‘СС’), (‘я’, ‘ПРП’), (‘любовь’, ‘ВБП’), (‘в гостях’, ‘ВБГ’), (‘ваш’, ‘ПРП$’ ), (‘сайт’, ‘NN’), (‘. ‘, ‘.’)]
‘, ‘.’)]
Объяснение кода:
- Код для импорта nltk (набор инструментов для естественного языка, который содержит подмодули, такие как токенизация предложений и токенизация слов.)
- Текст, теги которого должны быть напечатаны.
- Токенизация предложения
- Реализован цикл For, в котором слова выделяются из предложения, а тег каждого слова печатается в качестве вывода.
В Корпусе есть два типа POS-теггеров:
- На основе правил
- Стохастические POS-теггеры
1.Теггер POS на основе правил: Для слов, имеющих неоднозначное значение, применяется подход на основе правил на основе контекстной информации.Это делается путем проверки или анализа значения предшествующего или последующего слова. Информация анализируется из окружения слова или внутри себя. Поэтому слова помечаются грамматическими правилами конкретного языка, такими как использование заглавных букв и пунктуация. например, таггер Брилла.
например, таггер Брилла.
2.Stochastic POS Tagger: В этом методе применяются различные подходы, такие как частота или вероятность. Если слово в основном помечено определенным тегом в обучающем наборе, то в тестовом предложении ему присваивается этот конкретный тег.Тег слова зависит не только от своего собственного тега, но и от предыдущего тега. Этот метод не всегда точен. Другой способ — вычислить вероятность появления определенного тега в предложении. Таким образом, окончательный тег вычисляется путем проверки наибольшей вероятности слова с конкретным тегом.
Маркировка POS со скрытой марковской моделью
Проблемы с маркировкой также можно моделировать с помощью HMM. Он рассматривает входные токены как наблюдаемую последовательность, в то время как теги рассматриваются как скрытые состояния, и цель состоит в том, чтобы определить скрытую последовательность состояний.Например, x = x 1 ,x 2 ,…………,x n , где x — последовательность токенов, а y = y 1 ,y 2 ,6y 9 ,y 4 ………y n — скрытая последовательность.
Как работает скрытая марковская модель (HMM)?
HMM использует распределение соединений, которое равно P(x, y), где x — входная последовательность/последовательность маркеров, а y — последовательность тегов.
Последовательность тегов для x будет иметь вид argmax y1….yn p(x1,x2,….xn,y1,y2,y3,…..). Мы классифицировали теги из текста, но статистика таких тегов жизненно важна. Итак, следующая часть — подсчет этих тегов для статистического исследования.
Резюме
- Маркировка POS в NLTK — это процесс разметки слов в текстовом формате для определенной части речи на основе ее определения и контекста.
- Некоторые примеры тегов NLTK POS: CC, CD, EX, JJ, MD, NNP, PDT, PRP$, TO и т. д. Теггер POS
- используется для присвоения грамматической информации каждому слову предложения.Установка, импорт и загрузка всех пакетов маркировки частей речи с помощью NLTK завершены.
- Разделение на фрагменты в НЛП — это процесс, при котором небольшие фрагменты информации объединяются в большие блоки.
- Предустановленных правил нет, но вы можете комбинировать их по мере необходимости.
- Фрагментирование используется для обнаружения объектов. Сущность — это часть предложения, с помощью которой машина получает значение для любого намерения.
- Фрагментация используется для группировки различных токенов в один и тот же фрагмент.
Tone-of-Voice Words
Этот список из 37 тональных слов для конкретного веб-сайта можно использовать на двух разных этапах процесса разработки контента:
- Планирование : до написания содержания
- Оценка : чтобы понять, как ваши пользователи интерпретируют тон вашего контента
Планирование
Сначала начните с решения на высоком уровне, какой тон лучше всего подойдет для вашего сайта в целом или для той части контента, которую вы готовитесь написать.Оцените, где вы хотите быть в пределах 4 измерений тона голоса:
- смешное против серьезного
- формальный и повседневный
- уважительное против непочтительного
- энтузиазм против факта
После того, как вы определили свой целевой профиль тона, уточните свою стратегию тона, выбрав из этого списка. Создайте список до со словами, которым должен соответствовать ваш тон, а также список не со словами, которым должен соответствовать ваш тон , а не .
Создайте список до со словами, которым должен соответствовать ваш тон, а также список не со словами, которым должен соответствовать ваш тон , а не .
Например, предположим, что мы готовимся написать текст для раздела сайта «Пациенты и посетители » больницы. Мы можем решить, что нам нужен профиль тона:
- Серьезно: мы не должны шутить, разговаривая с пациентами
- Формально: больница имеет традиционный и престижный бренд
- Уважительно: это не должно выглядеть так, будто мы пренебрегаем серьезной ситуацией для пациентов
- Ни энтузиазма, ни фактов: мы должны выражать некоторое чувство сопереживания, но не должны казаться чрезмерно эмоциональными
Затем мы можем выбрать несколько слов целевого тона, например:
- Сочувствующий, но не веселый
- Профессионально и заботливо
Помните, что вы всегда можете добавить свои собственные тональные слова, если в нашем списке нет слов, точно соответствующих вашим намерениям. Просто помните, что тональные слова должны описывать то, как ваша организация относится к теме.
Просто помните, что тональные слова должны описывать то, как ваша организация относится к теме.
Оценка
Вы можете быстро оценить тон голоса — самостоятельно или с другими членами вашей команды. Выполните следующие действия:
- Соберите несколько образцов контента.
- Выберите тональные слова, описывающие тон голоса для каждого из них. Вы можете сделать это самостоятельно или попросить нескольких коллег выполнить это упражнение.
- Раздайте образцы реальным пользователям и попросите их решить, какие тональные слова лучше всего описывают каждую часть вашего контента.Вы можете использовать модифицированный тест реакции продукта.
Некоторые люди пропускают шаг 3 (оценка тона с пользователями). Помните, что вы не являетесь вашими пользователями : ваша интерпретация тона почти наверняка будет отличаться от интерпретации ваших пользователей.
Независимо от того, оценивали ли вы свой контент внутри компании или совместно с пользователями, ваша основная цель – определить, соответствует ли тон вашего контента индивидуальности вашего бренда и тону, который вы хотите передать . Если это не так, измените контент, чтобы приблизить его к своей цели, и повторите тестирование.
Если это не так, измените контент, чтобы приблизить его к своей цели, и повторите тестирование.
Список подробных дескрипторов тонов
- Уполномоченный
- Забота
- Веселый
- Грубый
- Консервативный
- Разговорный
- Повседневный
- Сухой
- Острый
- Восторженный
- Официальный
- Фрэнк
- Дружелюбный
- Развлечение
- Забавный
- Юмористический
- Информативный
- Непочтительный
- Суть дела
- Ностальгия
- Страстный
- Игривый
- Профессиональный
- Провокационный
- Причудливый
- Уважительный
- Романтик
- Саркастический
- Серьезный
- Смарт
- Снарки
- Сочувствующий
- Модный
- Надежный
- Беззастенчивый
- оптимистичный
- Остроумный
В каких словах есть nn? – Легче с практикой.
 ком
ком
В каких словах есть nn?
объявление
- объявление.
- подключение. Межблочное соединение
- .
- отключен.
- фундамент.
- уничтожение.
- многоканальный.
- благовещение.
Есть слово с двойным n?
Может быть полезно создать списки слов, содержащих две согласные n, которые не являются результатом добавления суффикса….Двойное n образовано добавлением суффикса.
| neńua umassinńua | эти туфли; обувь другого |
|---|---|
| atussenanńu etati | работаем (заведомо), когда он/она рядом; |
Сколько слов содержит букву N?
Есть 130259 слов, содержащих N New !
Какая еда начинается на букву Н?
- Хлеб Наан. Хлеб Наан, также известный как Нан, представляет собой лепешку, распространенную в Западной Азии.
- Начос. Это мексиканское блюдо является популярной закуской во всем мире.
- Нантуа. Классический французский соус, названный в честь города Нантуа.
- Груша Наши.
- Наси Горенг.
- Натилла.
- Натто.
- Апельсины для пупка.
Какие вещи начинаются на букву Н?
Малыш от A до Z — предметы, начинающиеся с буквы «N»
- Начос.
- Гвоздь.
- Лак для ногтей.
- Имя.
- Салфетка.
- Подгузник.
- Груша Наши.
- Пупок.
Что в моем доме начинается на букву Н?
предметы домашнего обихода с N (67x)
- Гвоздь.
- Лак для ногтей.
- Гвозди.
- Игла.
- нетто.
- Газета.
- Ночной столик.
- Тумбочка.
Что такое слово на букву «П»?
Слово P является эвфемизмом, который может относиться к следующему: паки, уничижительный термин для человека из Южной Азии (в частности, Пакистана), в основном используемый в Соединенном Королевстве.
Какое слово на Т в аниме?
T — ЦУНДЕРЕ Персонаж, который вначале холоден и безразличен, пока вы не узнаете его поближе, а затем находите его теплый и тягучий центр.
Какое волшебное слово на букву «Ф» заводит девушку?
Волшебное слово на букву «Ф» — «друг». Судя по всему, если ты бросишь это слово в беседу, она в 3 РАЗА БОЛЬШЕ ВЕРОЯТНА, что захочет с тобой переспать. Скажите: «Ха-ха, спасибо, что сделал это со мной, друг». Или какая-то другая итерация этого. Она увидит в этом вызов, и это усилит ее влечение к вам.
Трахаться — плохое слово?
Да, «fricking» или «freaking» — это в основном более мягкие заменители «F-слова». Таким образом, они МЕНЕЕ оскорбительны, чем это слово.
JJ vs. NN — Учебник по части речи
Отношения и различия
Иногда мы используем существительное для описания другого существительного. В этом случае первое существительное «действует как» прилагательное.
Примеры:
учитель истории, билетная касса, скаковая лошадь / история, билет, скачки являются прилагательными. Если вы помните это, это поможет вам понять, о чем идет речь:
Если вы помните это, это поможет вам понять, о чем идет речь:
Примеры:
скаковая лошадь — это лошадь, которая участвует в скачках
скачки — это скачки для лошадей
лодочная гонка — это гонка на лодках
любовная история — это история о любви
военная история — это история о войне
теннисный мяч — это мяч для игры в теннис
теннисные туфли — обувь для игры в теннискомпьютерная выставка — выставка компьютеров
магазин велосипедов — магазин, торгующий велосипедами
Как и настоящее прилагательное, «существительное как прилагательное» неизменно.Обычно стоит в единственном числе (есть исключения!).
примеры: 9088 Примеры:
ПРАВИЛЬНО: Лодка гонки, лодочные гонки Неправильные: Гонки лодок
Правильно: Зубная щетка, зубные щетки Неверно: Зубная щетка , Шнурки обуви Неправильные: Обувь-кружева, обувь
ПРАВИЛЬНО: Сигаретный пакет Неправильный: Сигареты Пакет, сигареты пакеты
Исключения: Несколько существительных выглядят множественным, но мы обычно относимся к ним единственное число (например, новости, бильярд, легкая атлетика).
