
Контекстные синонимы: что такое, примеры — ЕГЭ | BingoSchool
Синонимические отношения в языке — проявление структуры лексической системы. Связи между словами возникают на основе сопоставления, тематической и профессиональной общности, противопоставления и т.д. Лексические и контекстные синонимы — большой пласт словаря русского языка.
Синонимы — слова, объединенные общностью значений, относящиеся к одной части речи и различающиеся оттенками смысла или сферой речевого использования. Например: горе — несчастье, языкознание — лингвистика, антитеза — противопоставление.
Контекстные — или контекстуальные — синонимы обладают особыми признаками.
Контекстные синонимы — это слова, синонимия которых проявляется исключительно в данном тексте.
Языковое окружение слова называется контекстом. Наиболее полно смысл языковых единиц выявляется именно в той лексике, которая с ними связана в предложении.
Контекстные синонимы это подтверждают. Общность значений этих слов становится понятной только из сопоставления с окружающим их текстом. В словарях такие отношения не фиксируются, потому что относятся к сфере авторского употребления, индивидуального отбора слов. Например, в предложении «заставить человека считать свою единственную, неповторимую жизнь бессмысленной невозможно» слова единственную, неповторимую сближаются по смыслу. В обычных же условиях они синонимами не являются.
Контекстные синонимы могут показывать примеры близких значений на протяжении всего текста или в конкретном предложении. На этом основано задание ЕГЭ.
Как определить контекстные синонимы
Знать, что такое контекстные синонимы, необходимо, чтобы найти их в тексте. Запомним, что они должны принадлежать к одной и той же части речи. Чаще всего это имена существительные, прилагательные, глаголы или наречия:
- Мы увидели лодку, пришвартованную к берегу.
 Артем помог нам разместиться в ней, взял весла, и мы отправились в путь. Наше утлое суденышко покачивало на волнах.
Артем помог нам разместиться в ней, взял весла, и мы отправились в путь. Наше утлое суденышко покачивало на волнах. - Нет, мое первое, нежное, удивительное чувство любви я никогда не забуду.
- Максим несся по улице, стремясь догнать ускользающее время. Он всем телом рассекал воздух, упорно останавливавший его силой сопротивления.
- Мутно, сурово, неприветливо взглянула на него жизнь при самом его рождении.
Найти примеры контекстуальных синонимов в определенном фрагменте текста — экзаменационное задание, которое встречается в ОГЭ и ЕГЭ по русскому языку.
Примеры для ЕГЭ
Контекстные синонимы — это примеры авторского отбора языкового материала. Внимательное чтение текста поможет их отыскать.
Посмотрим на пример задания из ЕГЭ. Найдите в тексте контекстные синонимы:
Задание:
- Гарри с усмешкой наблюдал за своим знакомым.

- Он понимал, что ему не следует сейчас говорить — не тот случай.
- Джакомо интересовал его как личность и как объект наблюдений.
- Гарри сам удивлялся тому, как повлияли на этого неуверенного в себе юношу его слова.
- Однако он с азартом опытного игрока хотел дождаться финала представления. (контекстные синонимы: Джакомо — юноша)
Задание:
- Бывали дни, когда жители поместья желали всей душой отдаться музыке — и тогда в усадебном доме начиналось действо.
- Раскрывались окна в гостиной, впуская аромат садовых цветов в дом.
- Снимался чехол со старого рояля.
- Приглашенные чинно рассаживались на венских стульях вокруг инструмента — и лились, лились из растворенных окон в парк удивительные, завораживающие звуки.
- И таяли сердца слушающих, и так хотелось любить, обнять весь мир.
 (контекстуальные синонимы: музыка — звуки, любить — обнять)
(контекстуальные синонимы: музыка — звуки, любить — обнять)
Синонимы — что это такое на примерах
Обновлено 24 июля 2021 Просмотров: 52 349 Автор: Дмитрий Петров- Синонимы — это …
- Виды синонимов (на примерах)
- Контекстные и фразеологические синонимы
- Использование синонимов в речи и письме
- Синонимы Онлайн
Здравствуйте, уважаемые читатели блога KtoNaNovenkogo.ru. Сегодня мы поговорим о синонимах. Это один из инструментов лингвистики в русском языке, который позволяет сделать нашу речь (как устную, так и письменную) более выразительной.
Синонимы — это яркий пример многообразия русского языка
Попробуйте в англо-русском словаре посмотреть значение того или иного английского слова. В подавляющем большинстве случаев вы обнаружите не один его аналог в русском языке, а сразу несколько (иногда даже десятки).
Это говорит не столько о сложности русского языка, сколько о его богатстве. На каждое иностранное слово у нас найдется как минимум несколько русских и в большинстве случаев это будут слова-синонимы.
Синонимы – это слова, которые пишутся и звучат по-разному, но при этом имеют схожее или близкое лексическое значение.
Каждое из них передает свои оттенки и благодаря их наличию можно употреблять в разных случаях более подходящие слова, чтобы избежать тавтологии (что это?). Словарь синонимов — это настольная книга любого писателя, публициста, журналиста, да и обычного школьника.
Термин этот, естественно, пришел к нам из Древней Греции, как и многие другие в русском языке. Дословно он переводится как «одноименность».
Все синонимы, как правило, относятся к одной части речи. То есть существительные заменяются существительными, глаголы глаголами, определения определениями и так далее.
Рассмотрим на примерах:
- Путник (существительное) – странник, путешественник, паломник, пилигрим;
- Бежать (глагол) – торопиться, нестись, мчаться, спешить;
- Грустный (прилагательное) – печальный, понурый, мрачный, унылый;
- Рисуя (это деепричастие) – малюя, изображая, очерчивая, описывая;
- Медленно (наречие) – не спеша, долго, не торопясь, не скоро, еле-еле.

Причиной появления в языке множества синонимов называют видоизменение (устаревание) некоторых слов, а также наличие в русском языке множества диалектов (что такое диалектизмы), которые тоже вносят свое разнообразие.
Слова-синонимы с одинаковым лексическим значением образуют так называемые ряды (или их еще называют гнезда). Некоторые слова могут включаться в различные ряды. Все их можно найти в современных словарях синонимов (первый из них, кстати, был опубликован ровно 200 лет назад).
Сейчас, наверное, удобнее использовать онлайн-словари, но рекомендовать какой-то из них я затрудняюсь, ибо не было случая их полноценно протестировать. Можете просто ввести этот запрос в Яндексе или Гугле, чтобы получить список наиболее авторитетных из них
.
Виды синонимов (на примерах)
Знаменитый лингвист Дитмар Розенталь, по учебникам русского языка которого учились все советские дети, делил синонимы на три большие группы:
- полные или абсолютные;
- семантические;
- экспрессивно-стилистические или стилевые.

Полные синонимы
Абсолютными синонимами он называл слова, значение которых полностью совпадают. А значит, при их перестановке смысл всего текста не меняется.
Например:
битва – сражение, огромный – громадный, кидать – бросать
Также подобными синонимами можно легко заменять научные термины, и они становятся более понятными:
лингвистика – языкознание, орфография – правописание
Семантические синонимы
В данном случае речь идет уже о словах, которые не просто заменяют друг друга, но и придают речи большую глубину, делают ее богаче, насыщают ее нюансами.
Например:
красный – алый — пунцовый
В данном случае «красный» — это просто цвет, алый уже более светлый его оттенок, а пунцовый – наоборот, более темный.
Другой пример:
ломать – громить – разрушать — крушить
Весь этот ряд синонимов означает, в принципе, одно и то же действие. Вот только интенсивность его различается (или, если проводить аналогию с цветом, можно сказать, что меняются оттенки). Так, «ломают» игрушки, «разрушают» здания, а «крушат» врагов.
Так, «ломают» игрушки, «разрушают» здания, а «крушат» врагов.
Примеры стилевых синонимов
Такие синонимы мы чаще всего употребляем в разговорной речи, когда литературные слова заменяются на жаргонные.
Например:
выговор – нагоняй, взбучка, головомойка
ходить – бродить, мотаться, шляться, слоняться
жадный – жмот, скупердяй, скряга, жадина
родители – предки, родаки, старики
Но речь, конечно, не только о жаргоне. К стилевым синонимам относятся все похожие слова, но которые принадлежат к разным стилям речи. Например, если сравнивать общеупотребляемые термины и официальные, то можно вспомнить:
жена/муж – супруга/супруг
болезнь – инфекция
Контекстные и фразеологические синонимы
Есть еще два вида, которые не были рассмотрены выше. Они довольно специфичные, но при этом и очень интересные.
Контекстные синонимы
Этим термином называются слова, которые не являются изначально синонимами, но могут в них превратиться в контексте конкретного предложения. Чтобы проще было объяснить, приведет пример:
Чтобы проще было объяснить, приведет пример:
«Ваня играл с Шариком во дворе. Он кидал мячик, а пес приносил его обратно мальчику».
В данном случае есть несколько наборов синонимов. Так, по отдельности слова «Ваня», «Он» и «мальчик» не имеют ничего общего друг с другом. Но в данном тексте они взаимозаменяемы, а потому их можно считать синонимами.
То же самое и с парами слов «Шарик — пес» и «мячик – его». И таким образом, можно сделать простой вывод – для чего нужны контекстные синонимы. Они помогают избавиться от тавтологии, делая любой текст более грамотным.
Фразеологические синонимы
Это отдельный вид синонимов, в котором одно слово заменяется сразу целой фразой (отсюда и название). Также и целая фраза будет являться синонимом для другой фразы. Причем это достаточно устойчивые выражения, которые мы используем постоянно.
Например, рассмотрим слово «МНОГО» и его фразеологические синонимы:
- хоть отбавляй;
- куры не клюют;
- полон рот;
- хоть пруд пруди;
- тьма-тьмущая.

Конечно, каждая из этих фраз применяется под конкретный подтекст. Так, «полон рот» обычно говорят о заботах, а «куры не клюют» — о деньгах.
Вот еще немного примеров:
Синонимами можно заменить и словосочетания. Например, фраза «БЕЖАТЬ БЫСТРО»:
- со всех ног;
- сломя голову;
- высунув язык;
- в мгновенье ока.
Более того, подобные фразы могут заменять не только отдельные слова, но и друг друга:
- спрятать концы в воду – замести следы;
- бить баклуши – сидеть сложа руки;
- мало каши ел – кожа да кости;
- овчинка выделки не стоит – игра не стоит свеч;
- водить за нос – втирать очки;
- молчит как партизан – воды в рот набрал;
- молоть чепуху – нести ахинею;
- тянуть канитель – черепашьим шагом.
Любые фразеологические синонимы служат для того, чтобы украсить речь или текст, сделать их более яркими и эмоциональными.
Примеры использование синонимов в речи и письме
Вспомним еще раз знаменитого Дитмара Розенталя. Он описывал это следующим образом:
Он описывал это следующим образом:
«Синонимы выполняют в русском языке важнейшую функцию – выразительности речи. Благодаря им появляются неограниченные возможности более точного употребления слов. Работая над текстами, подбору синонимов нужно уделять особое внимание, чтобы избегать тавтологии. И употреблять то единственное слово, которое лучше подходит под конкретный момент».
На самом деле современные лингвисты выделяют несколько функций синонимов.
Функция уточнения. Синонимы служат, чтобы более точно описать понятия.
Это был простой человек – обычный и ничем не примечательный.
Функция сопоставления. Синонимы употребляются вместе, но один из них усиливает другой.
Я верю в добро. И даже верую в него.
Функция противопоставления. Также синонимы используются вместе, но один одновременно и опровергает предыдущий, и уточняет его.
Он не смеялся, а громко хохотал.
Функция замещения. Это те самые контекстные синонимы, которые позволяют избежать тавтологии.
Это те самые контекстные синонимы, которые позволяют избежать тавтологии.
Мама подарила дочке шкатулку. Этот ларчик был такого же цвета, как и глаза девочки.
Функция усиления. Синонимы как бы «нанизываются» один на другой, усиливая первоначальное слово.
В бою солдаты были храбрые, отважные и необыкновенно стойкие.
В конце хочется отметить, что даже у синонимов бывают исключения. То есть не всегда похожие слова можно заменять друг на друга.
Для примера возьмем пару «жадный – скупой»:
- Он помогал бедным, а потому не считался жадным (здесь можно заменить на «скупой»).
- Он жадный, все время хочет захватить побольше (здесь «скупой» неприменимо).
Так что синонимами при всем их многообразии еще надо уметь пользоваться.
Синонимы Онлайн
Большой онлайн-словарь синонимов русского языка, база которого состоит более чем из 400 тыс.слов.
Словарь синонимов снабжен многофункциональным поисковиком, который позволяет осуществлять поиск по запросу, алфавиту, первому слогу и словам составного выражения.
*при клике по картинке она откроется в полный размер в новом окне
Результаты поиска подходящих слов отображаются в виде списка, в котором пользователь может проголосовать за тот или иной синоним. А также добавить собственный вариант.
*при клике по картинке она откроется в полный размер в новом окне
Для удобства внизу списка синонимическая выдача представлена в форме строкового перечисления.
Полученным перечнем слов можно поделиться в социальных сетях, распечатать или скачать в формате Word-документа.
*при клике по картинке она откроется в полный размер в новом окне
Кроме этого сервис предоставляет большую коллекцию профессиональных словарей, которые можно скачать на свое устройство.
*при клике по картинке она откроется в полный размер в новом окне
Перечисленные выше характеристики ресурса говорят о том, что «Синонимы Онлайн» — это профессиональный инструмент для всех, кто работает с текстом, и который следует добавить в закладки своего браузера.
Удачи вам! До скорых встреч на страницах блога KtoNaNovenkogo.ru
Эта статья относится к рубрикам:
Что такое синонимы? Примеры и определения
В нашем родном языке есть множество средств, позволяющих передать одно и тоже. Синонимия занимает в этом списке центральное место и указывает на богатство языковой культуры. Синонимы, что же это такое и какую роль они играют в предложениях?
Понятие
Синонимы — это слова близкие по значению, но разные по написанию и звучанию. Обычно относятся к одной и той же части речи. Термин пришел к нам из греческого языка и дословно переводится как «одноименный».
Справка! Причины возникновения данных лексических единиц в различных языковых группах во многих случаях идентичны. С развитием языка люди стараются глубже и четче описывать происходящее вокруг, делиться мыслями и высказывать собственные идеи.
Русский язык не живет обособленно от других языков. Возникновение синонимичных понятий на основе, схожих по семантике иностранных слов, расширяет выразительные возможности (земельный-аграрный; ввоз-импорт).
Иногда возникновение синонимичных рядов становится результатом появления новых языковых единиц. К неизменяемому корню прибавляются новые суффиксы и приставки (пилотаж-пилотирование; невиновный-безвинный).
Бывает, что лексическое толкование расщепляется: слово становится элементом разных синонимических рядов (сливки общества и сливки из молока).
Самый распространенный путь возникновения синонимов — приход слов из сленга, диалектных слов и жаргонизмов (руль-баранка; вор-жулик).
Классификация синонимичных рядов
В основе деления синонимов на группы лежит характер различий между ними.
- Семантические. Слова весьма близкие по значению, но не тождественные. Подчеркивают разнообразные стороны обозначаемого или могут указывать на разную степень проявления признака. Тишина-молчание; злиться-сердиться; страх-ужас.
- Стилистические.
 В этом случае смысловые и стилистические оттенки синонимов смешиваются между собой. Такие слова-повторы позволяют дать различную эмоциональную и оценочную характеристику описанному. Еда-хавчик-яство; спать-почивать-дрыхнуть.
В этом случае смысловые и стилистические оттенки синонимов смешиваются между собой. Такие слова-повторы позволяют дать различную эмоциональную и оценочную характеристику описанному. Еда-хавчик-яство; спать-почивать-дрыхнуть. - Синонимы одной части речи. Слова, принадлежащие к разным частям речи, чаще всего не могут быть синонимами. В основе каждой из частей речи заложено свое значение, которое служит для него ядром и опорой. У существительных это предметность, у глаголов — действие, у прилагательного — признак.
Значение синонимов
Разобрались, что такое синонимы, посмотрим как их можно употреблять в предложениях. Такие слова способны к решению нескольких задач в текстовом пространстве.
Заменив конструкцию на близкую ей по значению, мы навсегда забываем о повторах. Функция замещения берется за основу при создании какого-либо высказывания. Она используется в том случае, когда синонимы в тексте употреблены для обозначения одного и того же явления или предмета. Находятся в сменяющих друг друга частях текста.
Находятся в сменяющих друг друга частях текста.
- Лингвист работает над статьей: языковед описывает особенности употребления знаменательных частей речи.
- Правописание количественных числительных дается моим ученикам с трудом. Но мы работаем над совершенствованием орфографии каждый день.
- С приятелем Димой мы провели вместе все детство: с таким другом всегда было интересно.
Схожие по лексическому толкованию слова могут выражать различные смысловые оттенки, что позволяет яснее передать мысль. Уточняющая функция характерна для полных синонимов и чаще всего реализуется в рамках одного предложения. При помощи синонимов обычно уточняется степень проявления.
- Михаил нерешительно подошел к учительнице и робко спросил о понравившейся книге.

- Это прекрасный и даже великолепный способ самоконтроля.
- Мальчишки бесстрашно двинулись вперед и решительно бросились на помощь другу.
Синонимы в тексте могут выполнять стилистическую функцию. Слова-заменители помогают выдерживать окраску текста. Стилистические синонимы обычно тождественны по семантике, но различаются употреблением. Выбор синонима зависит от отношения говорящего к тому, о чем он ведет рассказ.
- Я стоял сзади одной толстой (пышной) дамы.
- Его запачканные грязные перчатки казались нарочно сшитыми.
- Маша уже идет в школу, плетется по узкой дорожке.
Синонимичные слова для связи предложений используются тогда, когда в тексте необходима образность и красочность. Этот способ используют в публицистике и художественной литературе.
- В лесу мы видели лося. Сохатый шел вдоль опушки и никого не боялся.
- Особое место в моем сердце занимает творчество А.С. Пушкина. Великий поэт умело соединил в своих произведениях различные языковые пласты.
Фразеологизмы-синонимы — это устойчивые единицы, состоящие из различных компонентов, но имеющие схожее значение. Их особенность заключается в том, что они могут появляться в разное время.
- Мы усердно трудились над проектом всем классом, засучив рукава.
- Очень бледный Петя вернулся домой: на его лице не было и кровинки.
- Помощь прибыла мгновенно: не успел дед и глазом моргнуть.
Полезное видео
Уроки русского языка на тему: «Что это такое синонимы».
Извлечение набора синонимов из биомедицинской литературы путем обнаружения лексических паттернов | BMC Bioinformatics
Мы решили, что лучшим решением будет сначала сгенерировать большое количество шаблонов, используя обучающий набор. Для каждой возможной пары терминов мы генерируем вектор признаков, который представляет частоту совпадения этой пары терминов с использованием каждого из сгенерированных шаблонов. Затем этот вектор признаков классифицируется, а апостериорная вероятность используется в нашем алгоритме формирования синсета, описанном ниже.
Для каждой возможной пары терминов мы генерируем вектор признаков, который представляет частоту совпадения этой пары терминов с использованием каждого из сгенерированных шаблонов. Затем этот вектор признаков классифицируется, а апостериорная вероятность используется в нашем алгоритме формирования синсета, описанном ниже.
Следует отметить, что мы использовали количество пар терминов для расчета этих оценок, что дает более низкое значение, чем можно было бы ожидать. Например, если 4 термина были правильно идентифицированы из синсета из 8 терминов, то были идентифицированы только 6 из 28 пар синонимов, поэтому оценка составляет всего 21,4%, хотя 50% терминологии было распознано.
Генерация шаблона
Наш метод генерации шаблона заключается в следующем: мы начинаем с базовых шаблонов, которые состоят из трех основных операторов *, # и (пробел) , где * представляет собой последовательность символов слова, (пробел) представляет любые пробелы/знаки препинания между словами, а # представляет термин (сопоставленный без учета регистра). Мы генерируем новые шаблоны, расширяя текущий шаблон следующими способами: * может быть заменен любой последовательностью буквенно-цифровых символов, а (пробел) может быть заменен любой последовательностью символов, не являющихся словами. Начав с набора начальных шаблонов, состоящих только из #s, *s и (пробел )s, эти шаблоны можно расширить, чтобы дать нам поиск, как на рисунке 1. Чтобы расширить шаблон, мы ищем в корпусе, взяв каждый синоним. пары и заменив # с терминами. Рассматривая каждое возможное разложение * или (пробел) , наша задача может рассматриваться как поиск по дереву.Очевидно, что это пространство поиска огромно, и поэтому мы ищем его эвристическим методом поиска с поиском по первому наилучшему. Алгоритм следующий:
Мы генерируем новые шаблоны, расширяя текущий шаблон следующими способами: * может быть заменен любой последовательностью буквенно-цифровых символов, а (пробел) может быть заменен любой последовательностью символов, не являющихся словами. Начав с набора начальных шаблонов, состоящих только из #s, *s и (пробел )s, эти шаблоны можно расширить, чтобы дать нам поиск, как на рисунке 1. Чтобы расширить шаблон, мы ищем в корпусе, взяв каждый синоним. пары и заменив # с терминами. Рассматривая каждое возможное разложение * или (пробел) , наша задача может рассматриваться как поиск по дереву.Очевидно, что это пространство поиска огромно, и поэтому мы ищем его эвристическим методом поиска с поиском по первому наилучшему. Алгоритм следующий:
Пример поиска по шаблону . Дерево, иллюстрирующее примерное пространство поиска для алгоритма генерации шаблона. Вершина дерева представляет собой начальный образец, и поиск продолжается путем замены одного из подстановочных знаков термином и пунктуацией для создания набора образцов.
Алгоритм генерации шаблонов
Ввод: Набор базовых шаблонов P , набор пар обучающих терминов S={(t1,t2),… (т, T’n)} MathType @ СПР @ 5 @ 5 + = feaafiart1ev1aaatCvAUfKttLearuWrP9MDH5MBPbIqV92AaeXatLxBI9gBaebbnrfifHhDYfgasaacPC6xNi = xH8viVGI8Gi = hEeeu0xXdbba9frFj0xb9qqpG0dXdb9aspeI8k8fiI + FSY = rqGqVepae9pg0db9vqaiVgFr0xfr = XFR = xc9adbaqaaeGaciGaaiaabeqaaeqabiWaaaGcbaGaem4uamLaeyypa0Jaei4EaSNaeiikaGIaemiDaq3aaSbaaSqaaiabigdaXaqabaGccqGGSaalcqWG0baDdaWgaaWcbaGaeGOmaidabeaakiabcMcaPiabcYcaSiabc6caUiabc6caUiabc6caUiabcIcaOiabdsha0naaBaaaleaacqWGUbGBaeqaaOGaeiilaWIafmiDaqNbauaadaWgaaWcbaGaemOBa4gabeaakiabcMcaPiabc2ha9baa @ 450E @, A корпус С.
Вывод: Набор шаблонов P , отсортированных по метрике оценки
-
1.
Добавить все базовые шаблоны с эвристической оценкой в кучу H .
-
2.

Для фиксированного числа итераций
-
(а)
Выберите шаблон, p , с максимальной оценкой в H .
-
(б)
Найти все совпадения этого шаблона, используя все пары терминов в S в корпусе C
-
(с)
Для каждого * или (пробел) в p найти все совпадающие строки в корпусе
-
(г)
Для каждого совпадения с каждым * или (пробел) добавить новый шаблон к H
-
3.

Шаблоны вывода H , отсортированные по количеству баллов
Мы экспериментировали с рядом эвристических показателей оценки, включая количество совпадений с образцом, однако мы обнаружили, что это дает слишком сильное смещение для терминов, которые встречаются очень часто, в частности, мы отметили, что многие из шаблонов содержат термины из нашего обучения набор, что весьма нежелательно.
h2 = # sentencesmatchingpattern # sentencesincorpusMathType @ СПР @ 5 @ 5 @ + = feaafiart1ev1aaatCvAUfKttLearuWrP9MDH5MBPbIqV92AaeXatLxBI9gBaebbnrfifHhDYfgasaacPC6xNi = xI8qiVKYPFjYdHaVhbbf9v8qqaqFr0xc9vqFj0dXdbba91qpepeI8k8fiI + FSY = rqGqVepae9pg0db9vqaiVgFr0xfr = XFR = xc9adbaqaaeGaciGaaiaabeqaaeqabiWaaaGcbaGaemiAaG2aaSbaaSqaaiabigdaXaqabaGccqGH9aqpjuaGdaWcaaqaaiabcocaJiabdohaZjabdwgaLjabd6gaUjabdsha0jabdwgaLjabd6gaUjabdogaJjabdwgaLjabdohaZjabbccaGiabd2gaTjabdggaHjabdsha0jabdogaJjabdIgaOjabdMgaPjabd6gaUjabdEgaNjabbccaGiabdchaWjabdggaHjabdsha0jabdsha0jabdwgaLjabdkhaYjabd6gaUbqaaiabcocaJiabdohaZjabdwgaLjabd6gaUjabdsha0jabdwgaLjabd6gaUjabdogaJjabdwgaLHqaciab = nhaZjabbccaGiab = LgaPjab = 5gaUjabbccaGiabdogaJjabd + gaVjabdkhaYjabdchaWjabdwha1jabdohaZbaaaaa @ 6D86 @ = # Synonympairsfound # synonympairsMathType @ СПР @ 5 @ 5 @ + = feaafiart1ev1aaatCvAUfKttLearuWrP9MDH5MBPbIqV92AaeXatLxBI9gBaebbnrfifHhDYfgasaacPC6xNi = xI8qiVKYPFjYdHaVhbbf9v8qqaqFr0xc9vqFj0dXdbba91qpepeI8k8fiI + FSY = rqGqVepae9pg0db9vqaiVgFr0xfr = XFR = xc9adbaqaaeGaciGaaiaabeqaaeqabiWaaaGcbaqbaeqabmqaaaqaaiabdIgaOnaaBaaaleaacqaIYaGmaeqaaOGaeyypa0ZaaSaaaeaacqGGOaakcqaIXaqmcqGHRaWkcqaHXoqycqGGPaqkcuWGWbaCgaqcaiqbdkhaYzaajaaabaGaeqySdeMafmiCaaNbaKaacqGHRaWkcuWGYbGCgaqcaaaaaeaacuWGWbaCgaqcaiabg2da9KqbaoaalaaabaGaei4iamIaem4yamMaem4Ba8MaemOCaiNaemOCaiNaemyzauMaem4yamMaemiDaqNaeeiiaaIaemiCaaNaemyyaeMaemiDaqNaemiDaqNaemyzauMaemOCaiNaemOBa4MaeeiiaaIaemyBa0MaemyyaeMaemiDaqNaem4yamMaemiAaGMaemyzauMaem4CamhabaGaei4iamIaemyyaeMaemiBaWMaemiBaWMaeeiiaaIaemiCaaNaemyyaeMaemiDaqNaemiDaqNaemyzauMaemOCaiNaemOBa4MaeeiiaaIaemyBa0MaemyyaeMaemiDaqNaem4yamMaemiAaGMaemyzauMaem4CamhaaaGcbaGafmOCaiNbaKaacqGH9aqpjuaGdaWcaaqaaiabcocaJiabdohaZjabdMha5jabd6gaUjabd + gaVjabd6gaUjabdMha5jabd2gaTjabbccaGiabdchaWjabdggaHjabdMgaPjabdkhaYjab dohazjabbccagiabdagamjabd + gavjabdwha1jabd6gaujabdsgakbqaaiabcoaujabdohazjabdmha5jabd6gaujazjabdmha5jabd6gaujabd + gavjabd6gaujabdmha5jabd2gatjabcaujabdkhabdchawdgagagjabdmgaibdkhawdhabdghaaaaaaaaaa @ A92F @
= # Synonympairsfound # synonympairsMathType @ СПР @ 5 @ 5 @ + = feaafiart1ev1aaatCvAUfKttLearuWrP9MDH5MBPbIqV92AaeXatLxBI9gBaebbnrfifHhDYfgasaacPC6xNi = xI8qiVKYPFjYdHaVhbbf9v8qqaqFr0xc9vqFj0dXdbba91qpepeI8k8fiI + FSY = rqGqVepae9pg0db9vqaiVgFr0xfr = XFR = xc9adbaqaaeGaciGaaiaabeqaaeqabiWaaaGcbaqbaeqabmqaaaqaaiabdIgaOnaaBaaaleaacqaIYaGmaeqaaOGaeyypa0ZaaSaaaeaacqGGOaakcqaIXaqmcqGHRaWkcqaHXoqycqGGPaqkcuWGWbaCgaqcaiqbdkhaYzaajaaabaGaeqySdeMafmiCaaNbaKaacqGHRaWkcuWGYbGCgaqcaaaaaeaacuWGWbaCgaqcaiabg2da9KqbaoaalaaabaGaei4iamIaem4yamMaem4Ba8MaemOCaiNaemOCaiNaemyzauMaem4yamMaemiDaqNaeeiiaaIaemiCaaNaemyyaeMaemiDaqNaemiDaqNaemyzauMaemOCaiNaemOBa4MaeeiiaaIaemyBa0MaemyyaeMaemiDaqNaem4yamMaemiAaGMaemyzauMaem4CamhabaGaei4iamIaemyyaeMaemiBaWMaemiBaWMaeeiiaaIaemiCaaNaemyyaeMaemiDaqNaemiDaqNaemyzauMaemOCaiNaemOBa4MaeeiiaaIaemyBa0MaemyyaeMaemiDaqNaem4yamMaemiAaGMaemyzauMaem4CamhaaaGcbaGafmOCaiNbaKaacqGH9aqpjuaGdaWcaaqaaiabcocaJiabdohaZjabdMha5jabd6gaUjabd + gaVjabd6gaUjabdMha5jabd2gaTjabbccaGiabdchaWjabdggaHjabdMgaPjabdkhaYjab dohazjabbccagiabdagamjabd + gavjabdwha1jabd6gaujabdsgakbqaaiabcoaujabdohazjabdmha5jabd6gaujazjabdmha5jabd6gaujabd + gavjabd6gaujabdmha5jabd2gatjabcaujabdkhabdchawdgagagjabdmgaibdkhawdhabdghaaaaaaaaaa @ A92F @
 В конце концов мы решили, что лучшим ответом будет использование количества найденных пар синонимов, так как это легко подсчитывается и не приводит к смещению в сторону более общей терминологии. Во многих методах генерации паттернов, включая систему WHISK, прилагаются значительные усилия для разработки надежного набора паттернов, мы разработали этот алгоритм только для получения множества приемлемых результатов. Причина этого заключалась в том, что мы хотели дать классификатору синонимов как можно больше информации, и что слишком большая сложность в создании шаблонов дублировала усилия статистического классификатора.Используемая нами эвристика выглядит следующим образом.
h4 = # synonympairsfound # synonympairsMathType @ СПР @ 5 @ 5 @ + = feaafiart1ev1aaatCvAUfKttLearuWrP9MDH5MBPbIqV92AaeXatLxBI9gBaebbnrfifHhDYfgasaacPC6xNi = xI8qiVKYPFjYdHaVhbbf9v8qqaqFr0xc9vqFj0dXdbba91qpepeI8k8fiI + FSY = rqGqVepae9pg0db9vqaiVgFr0xfr = XFR = xc9adbaqaaeGaciGaaiaabeqaaeqabiWaaaGcbaGaemiAaG2aaSbaaSqaaiabiodaZaqabaGccqGH9aqpjuaGdaWcaaqaaiabcocaJiabdohaZjabdMha5jabd6gaUjabd + gaVjabd6gaUjabdMha5jabd2gaTjabbccaGiabdchaWjabdggaHjabdMgaPjabdkhaYjabdohaZjabbccaGiabdAgaMjabd + gaVjabdwha1jabd6gaUjabdsgaKbqaaiabcocaJiabdohaZjabdMha5jabd6gaUjabd + gaVjabd6gaUjabdMha5jabd2gaTjabbccaGiabdchaWjabdggaHjabdMgaPjabdkhaYjabdohaZbaaaaa @ 5CE8 @
В конце концов мы решили, что лучшим ответом будет использование количества найденных пар синонимов, так как это легко подсчитывается и не приводит к смещению в сторону более общей терминологии. Во многих методах генерации паттернов, включая систему WHISK, прилагаются значительные усилия для разработки надежного набора паттернов, мы разработали этот алгоритм только для получения множества приемлемых результатов. Причина этого заключалась в том, что мы хотели дать классификатору синонимов как можно больше информации, и что слишком большая сложность в создании шаблонов дублировала усилия статистического классификатора.Используемая нами эвристика выглядит следующим образом.
h4 = # synonympairsfound # synonympairsMathType @ СПР @ 5 @ 5 @ + = feaafiart1ev1aaatCvAUfKttLearuWrP9MDH5MBPbIqV92AaeXatLxBI9gBaebbnrfifHhDYfgasaacPC6xNi = xI8qiVKYPFjYdHaVhbbf9v8qqaqFr0xc9vqFj0dXdbba91qpepeI8k8fiI + FSY = rqGqVepae9pg0db9vqaiVgFr0xfr = XFR = xc9adbaqaaeGaciGaaiaabeqaaeqabiWaaaGcbaGaemiAaG2aaSbaaSqaaiabiodaZaqabaGccqGH9aqpjuaGdaWcaaqaaiabcocaJiabdohaZjabdMha5jabd6gaUjabd + gaVjabd6gaUjabdMha5jabd2gaTjabbccaGiabdchaWjabdggaHjabdMgaPjabdkhaYjabdohaZjabbccaGiabdAgaMjabd + gaVjabdwha1jabd6gaUjabdsgaKbqaaiabcocaJiabdohaZjabdMha5jabd6gaUjabd + gaVjabd6gaUjabdMha5jabd2gaTjabbccaGiabdchaWjabdggaHjabdMgaPjabdkhaYjabdohaZbaaaaa @ 5CE8 @ Мы даем алгоритм прогон для фиксированного числа итераций, мы выбрал это число, чтобы найти примерно в 10 раз больше шаблонов, которые мы планируем использовать в нашей классификации.
Классификация синонимов
Чтобы сгенерировать векторы признаков, мы обнаружили, что многие из шаблонов были негибкими и совпадали очень редко, для борьбы с этим мы просто позволили * и (пробел) соответствовать ε , пустой строке, по которой мы имеем в виду, что разрешить совпадение с любым из *s или (пробел) опущены. Это позволяло шаблонам, таким как # (* #), соответствовать не только « термин (или аббревиатура )», но и « термин ( аббревиатура ).Мы обнаружили, что это значительно улучшило полноту и точность результата.
Мы ожидали, что некоторые из сгенерированных паттернов будут давать достаточно хорошую точность, а некоторые — относительно хорошую полноту, однако, объединив все это вместе, мы сможем получить намного больше. лучший общий результат По этой причине мы рассматриваем проблему как проблему статистической классификации. шаблона с номерами, соответствующими терминам в паре синонимов-кандидатов. Хотя в теории потребует n2MathType @ СПР @ 5 @ 5 @ + = feaafiart1ev1aaatCvAUfKttLearuWrP9MDH5MBPbIqV92AaeXatLxBI9gBaebbnrfifHhDYfgasaacPC6xNi = xH8viVGI8Gi = hEeeu0xXdbba9frFj0xb9qqpG0dXdb9aspeI8k8fiI + FSY = rqGqVepae9pg0db9vqaiVgFr0xfr = XFR = xc9adbaqaaeGaciGaaiaabeqaaeqabiWaaaGcbaqcfa4aaSaaaeaacqWGUbGBaeaacqaIYaGmaaaaaa @ 2ECA @ ( п — 1) векторы признаков для п терминов, на самом деле большинство пары терминов вообще не встречаются близко друг к другу в корпусе, поэтому их можно отбросить (и их вероятности получаются за счет классификации нулевого вектора).Для нашего эксперимента мы использовали 6000 лучших паттернов из алгоритма генерации паттернов. Затем это становится стандартной задачей статистической классификации, к которой можно применить любой алгоритм статистической классификации. Мы экспериментировали с наивным байесовским методом, логистической регрессией, C4.5 и методами опорных векторов с несколькими вариантами ядра. Мы обнаружили, что только логистическая регрессия дает полезный разброс вероятностей, которые можно использовать для формирования синсетов, поэтому мы сначала построили синсеты с этими вероятностями, а затем использовали логистическую регрессию на выходе самого сильного классификатора (SVM).
Хотя в теории потребует n2MathType @ СПР @ 5 @ 5 @ + = feaafiart1ev1aaatCvAUfKttLearuWrP9MDH5MBPbIqV92AaeXatLxBI9gBaebbnrfifHhDYfgasaacPC6xNi = xH8viVGI8Gi = hEeeu0xXdbba9frFj0xb9qqpG0dXdb9aspeI8k8fiI + FSY = rqGqVepae9pg0db9vqaiVgFr0xfr = XFR = xc9adbaqaaeGaciGaaiaabeqaaeqabiWaaaGcbaqcfa4aaSaaaeaacqWGUbGBaeaacqaIYaGmaaaaaa @ 2ECA @ ( п — 1) векторы признаков для п терминов, на самом деле большинство пары терминов вообще не встречаются близко друг к другу в корпусе, поэтому их можно отбросить (и их вероятности получаются за счет классификации нулевого вектора).Для нашего эксперимента мы использовали 6000 лучших паттернов из алгоритма генерации паттернов. Затем это становится стандартной задачей статистической классификации, к которой можно применить любой алгоритм статистической классификации. Мы экспериментировали с наивным байесовским методом, логистической регрессией, C4.5 и методами опорных векторов с несколькими вариантами ядра. Мы обнаружили, что только логистическая регрессия дает полезный разброс вероятностей, которые можно использовать для формирования синсетов, поэтому мы сначала построили синсеты с этими вероятностями, а затем использовали логистическую регрессию на выходе самого сильного классификатора (SVM).
Формирование синсета
Результаты, полученные нами в результате процедуры статистической классификации, дали только вероятность того, что конкретная пара терминов является синонимом. Однако мы ожидаем, что каждая пара терминов в синсете будет синонимичной, и эти результаты бинарной классификации не гарантируют, что такое отношение транзитивности существует. Таким образом, мы будем предполагать, что каждая пара терминов в синсете синонимична, и никакие пары терминов в разных синсетах не являются синонимами (хотя это технически неверно, поскольку некоторые слова могут быть многозначными).Это явно приводит к тому, что синсеты являются полными графами, поэтому мы можем рассматривать нашу цель как поиск ближайшего набора полных подграфов к нашему случайному графу. В качестве примера рассмотрим рисунок 2, на котором показано графическое представление выходных данных сверху, где узлы представляют термины, и они связаны, если классификатор предсказывает, что термины являются синонимами.
Случайный график для синтеза .Иллюстрация преобразования случайного графа в набор синсетов. Верхний график иллюстрирует случайные выходные данные классификатора, которые включают ложную связь между «денди-лихорадкой» и «желтой лихорадкой». Этот граф корректируется путем формирования синсетов с удалением ложной ссылки и добавлением двух ссылок, которые не были найдены классификатором.
Пусть {1 .. n } Соответствует нашим условиям, то наша цель — найти набор I * = {i1 *, … в *} Mathtype @ mtef @ 5 @ @ + = feaafiart1ev1aatcvaufktttlearuwrp9mdh5mbpbiqv92aaexhtlxbi9gbebbbnrfifhhdyfgasaacpc6xni = xh8vivgi8gi = hEeeu0xXdbba9frFj0xb9qqpG0dXdb9aspeI8k8fiI + FSY = rqGqVepae9pg0db9vqaiVgFr0xfr = XFR = xc9adbaqaaeGaciGaaiaabeqaaeqabiWaaaGcbaGaemysaK0aaWbaaSqabeaacqGHxiIkaaGccqGH9aqpcqGG7bWEcqWGjbqsdaqhaaWcbaGaeGymaedabaGaey4fIOcaaOGaeiilaWIaeiOla4IaeiOla4IaeiOla4IaemysaK0aa0baaSqaaiabd6gaUbqaaiabgEHiQaaakiabc2ha9baa @ 3C7F @ где
 . N } и I * максимизирует c ( I *), заданное выражением c({I1,…,IK})=∑k=1..Kc(IK)c(Ik)= Σi∈IkΣj∈Ik (журнал (Pij) + Σj∉Iklog (1-Pij)) MathType @ СПР @ 5 @ 5 + = feaafiart1ev1aaatCvAUfKttLearuWrP9MDH5MBPbIqV92AaeXatLxBI9gBaebbnrfifHhDYfgasaacPC6xNi = xI8qiVKYPFjYdHaVhbbf9v8qqaqFr0xc9vqFj0dXdbba91qpepeI8k8fiI + FSY = rqGqVepae9pg0db9vqaiVgFr0xfr = XFR = + gaVjabcEg aNjabcIcaOiabigdaXiabgkHiTiabdcfaqnaaBaaaleaacqWGPbqAcqWGQbGAaeqaaOGaeiykaKIaeiykaKcaleaacqWGQbGAcqGHjiYZcqWGjbqsdaWgaaadbaGaem4AaSgabeaaaSqab0GaeyyeIuoaaSqaaiabdMgaPjabgIGiolabdMeajnaaBaaameaacqWGRbWAaeqaaaWcbeqdcqGHris5aaaaaaa @ 8050 @
, где P И.Я.
— это вероятность того, что термины, соответствующие i и j, являются синонимами, как определено некоторым методом статистической классификации (и P ii
= 1).Обратите внимание, что эта логарифмическая форма используется, поскольку она упрощает дальнейшие вычисления, и многие выходные вероятности нашего классификатора были близки к 0 или 1.
. N } и I * максимизирует c ( I *), заданное выражением c({I1,…,IK})=∑k=1..Kc(IK)c(Ik)= Σi∈IkΣj∈Ik (журнал (Pij) + Σj∉Iklog (1-Pij)) MathType @ СПР @ 5 @ 5 + = feaafiart1ev1aaatCvAUfKttLearuWrP9MDH5MBPbIqV92AaeXatLxBI9gBaebbnrfifHhDYfgasaacPC6xNi = xI8qiVKYPFjYdHaVhbbf9v8qqaqFr0xc9vqFj0dXdbba91qpepeI8k8fiI + FSY = rqGqVepae9pg0db9vqaiVgFr0xfr = XFR = + gaVjabcEg aNjabcIcaOiabigdaXiabgkHiTiabdcfaqnaaBaaaleaacqWGPbqAcqWGQbGAaeqaaOGaeiykaKIaeiykaKcaleaacqWGQbGAcqGHjiYZcqWGjbqsdaWgaaadbaGaem4AaSgabeaaaSqab0GaeyyeIuoaaSqaaiabdMgaPjabgIGiolabdMeajnaaBaaameaacqWGRbWAaeqaaaWcbeqdcqGHris5aaaaaaa @ 8050 @
, где P И.Я.
— это вероятность того, что термины, соответствующие i и j, являются синонимами, как определено некоторым методом статистической классификации (и P ii
= 1).Обратите внимание, что эта логарифмическая форма используется, поскольку она упрощает дальнейшие вычисления, и многие выходные вероятности нашего классификатора были близки к 0 или 1. Мы также определяем межузловую стоимость , c ij
как c ij
= log ( P ij
) + лог ( Р джи
) — лог (1 — Р ij
) —
Мы также определяем межузловую стоимость , c ij
как c ij
= log ( P ij
) + лог ( Р джи
) — лог (1 — Р ij
) — Так как количество потенциальных синсетов равно 2 N , мы можем значительно уменьшить эту проблему, найдя небольшой набор потенциальных синсетов I такой, что I * ⊂ I ⊂ 90 {1.. N }). К счастью, большинство выходных вероятностей P ij
очень малы, поэтому мы можем надеяться на значительный успех, сгенерировав набор I с помощью алгоритма ветвей и границ. Мы находим условие, когда набор и все его надмножества не являются оптимальными, замечая, что Дж ∉ I * если ) + c ({ k }) для некоторых k ∈ I .
Лемма 1 : Пусть j ⊂ {1 .. n } и k ∉ j и v ⊂ {1 .. n } Такое, что j ∩ v = ∅ и к ∉ В . Тогда нет набора K такой, что j ∪ { k } { k } ⊂ k ⊂ k ∪ { k ∪ { k } ∪ k , k ∉ I * Если
-
1.
∑ i ∈ J c ik < 0
-
2.
-∑ i ∈ J c ik > max В’ ⊂ В ∑ i ∈ В’ c
ik
Доказательство : непосредственно из неравенства C ( K ) < k ( k \ { k \ { k }) + C ({ k })
Это очень полезен, так как набор V’ — это просто набор, для которого c ik
положительный.
Заметим также, что задачу можно разделить, используя следующую лемму: ( j ∩ K = ∅) такие, что ∀ J ∈ J ∀ K ∈ K C JK < 0, то не существует ∅ ⊂ J’ ⊆ J и ∅ ⊂ K’ ⊆ K таких, что J’ ∪ 9 I 9 K’
Доказательство : следует из C ( j ‘ ∪ k’ ) < C ( j ‘) + C ( K’ )
Это означает, что только подключены компоненты оптимальны, поэтому мы рассматриваем связные множества только при создании I (где мы определяем i и j как связные, если c ij
≥ 0). Также, когда термин был удален из области поиска (т.е. больше не находится в J ∪ V ), это может привести к отсоединению ранее подключенных компонентов. По этой причине мы также ищем связанные компоненты каждый раз, когда удаляем элемент из области поиска.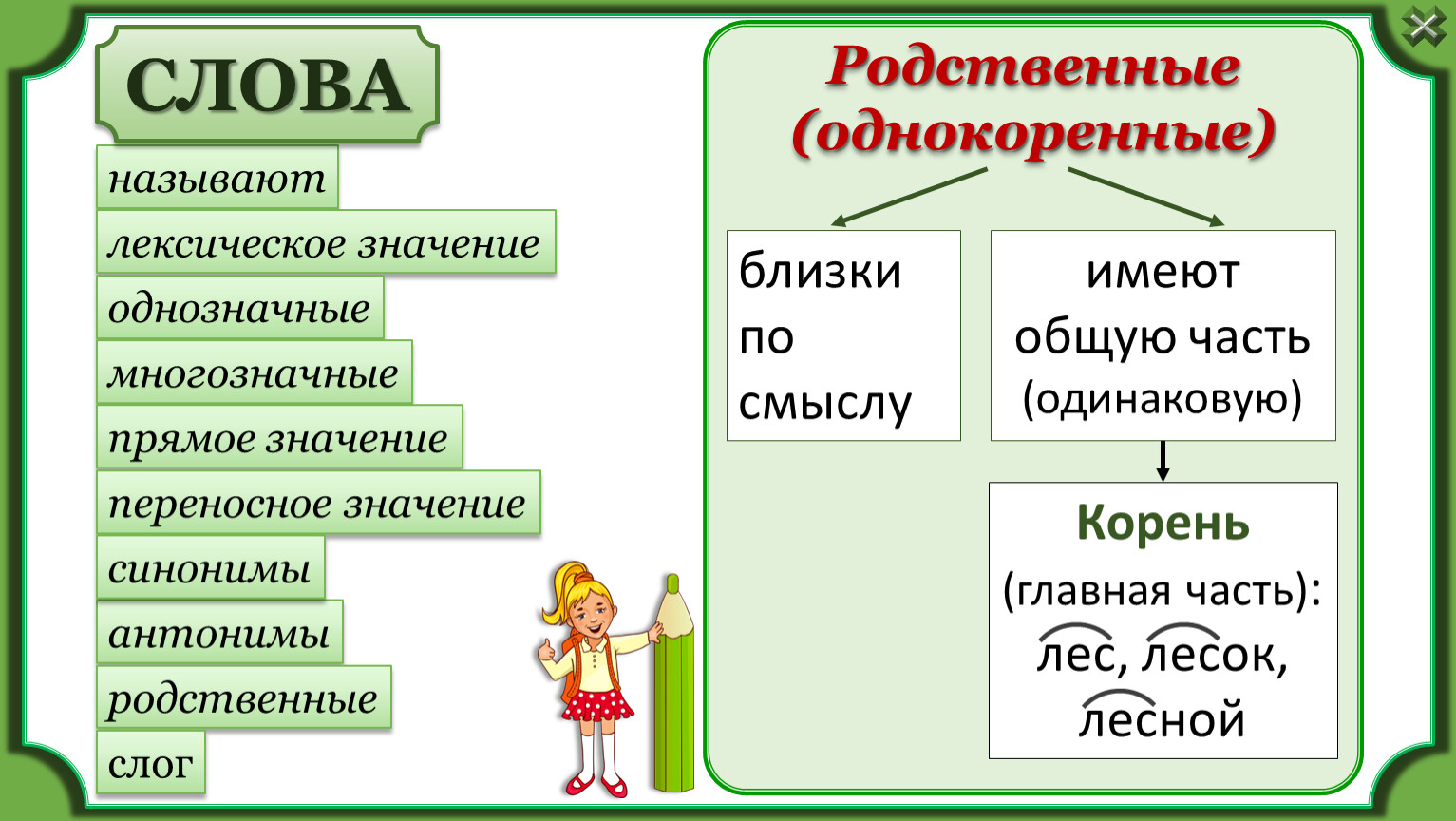 В таблице 1 показано количество синсетов, сгенерированных с помощью эвристики ветвей и границ (лемма 1), эвристики связных компонентов (лемма 2), нахождения связных компонентов с использованием ветвей и границ и окончательного алгоритма следующим образом (shift( X ) возвращает и удаляет первый элемент X ):
В таблице 1 показано количество синсетов, сгенерированных с помощью эвристики ветвей и границ (лемма 1), эвристики связных компонентов (лемма 2), нахождения связных компонентов с использованием ветвей и границ и окончательного алгоритма следующим образом (shift( X ) возвращает и удаляет первый элемент X ):
Алгоритм генерации матрицы
-
1.
Дж = ∅
-
2.
Для каждого подключенного компонента В в {1… N }
-
(а)
Сортировать V по ∑ k = 1… Н с ик
-
(б)
generate_matrix( Дж , В )
функция generate_matrix ( J , V )
-
1.

Пока длина( В ) > 0
-
(а)
к = сдвиг( В )
-
(б)
if(|J| = 0 или ∑ i ∈ J c ik > 0 или -∑ i ∈ J c ik < max В’ ⊂ В ∑ i ∈ В’ , c
9 10ik 9 ) -
я.
добавить J ∪ { k } к I
-
II.

generate_matrix( J ∪ { k }, V )
-
(с)
if( J ∪ V имеет более одного подключенного компонента)
-
я.
для каждого подключенного компонента, C , с | C ∩ J | > 0 и | С ∩ В | > 0: generate_matrix( Дж , С ∩ В )
-
II.
конец
Решение проблемы синсета
Эта задача на самом деле является задачей покрытия множеств, которая является NP-полной, однако мы обнаружили, что для нашей задачи достаточно точных методов. Чтобы решить эту проблему, после того, как мы сгенерировали I = { I 1 ,… I n
} мы сформировали матрицу A = ( a ij
), задается
Чтобы решить эту проблему, после того, как мы сгенерировали I = { I 1 ,… I n
} мы сформировали матрицу A = ( a ij
), задается
Мы также образуют вектор с где к к = с ( I к ), и теперь нахождение точного покрытия эквивалентно нахождению целочисленного вектора x , который максимизирует c T x при условии Ax = 1
, и это хорошо изученная задача. нахождение этого вектора x можно рассматривать как задачу ветвей и границ и атаковать с помощью алгоритма Dancing Links [18].Этот алгоритм использует формирование разреженной матрицы для эффективного удаления невозможных вариантов выбора строки, а в сочетании с алгоритмом ветвей и границ может очень эффективно находить оптимальные решения. Ветвь и граница просто отбрасывают любое частичное решение, когда максимальная стоимость гарантированно меньше, чем лучшее решение, найденное до сих пор. Эту максимальную стоимость можно найти, просто сведя в таблицу лучшую клику, доступную для каждого неудовлетворенного столбца в матрице. Более продвинутый алгоритм использует либо линейную релаксацию (что позволяет x принимать нецелые значения и решать с помощью симплексного алгоритма), либо лагранжеву релаксацию с субградиентной оптимизацией [19] для оценки этой верхней границы, однако мы это сделали. не находим это необходимым для наших наборов данных.
нахождение этого вектора x можно рассматривать как задачу ветвей и границ и атаковать с помощью алгоритма Dancing Links [18].Этот алгоритм использует формирование разреженной матрицы для эффективного удаления невозможных вариантов выбора строки, а в сочетании с алгоритмом ветвей и границ может очень эффективно находить оптимальные решения. Ветвь и граница просто отбрасывают любое частичное решение, когда максимальная стоимость гарантированно меньше, чем лучшее решение, найденное до сих пор. Эту максимальную стоимость можно найти, просто сведя в таблицу лучшую клику, доступную для каждого неудовлетворенного столбца в матрице. Более продвинутый алгоритм использует либо линейную релаксацию (что позволяет x принимать нецелые значения и решать с помощью симплексного алгоритма), либо лагранжеву релаксацию с субградиентной оптимизацией [19] для оценки этой верхней границы, однако мы это сделали. не находим это необходимым для наших наборов данных.
Независимо от реализации решателя, одно улучшение общего назначения состоит в том, чтобы атаковать каждую из подзадач (т. е. каждый из связанных компонентов) по отдельности, а затем объединять результаты. Число способов разбиения множества задается числом Белла
е. каждый из связанных компонентов) по отдельности, а затем объединять результаты. Число способов разбиения множества задается числом Белла
Число Белла дает наихудший размер пространства поиска для алгоритма танцующих ссылок.Если мы можем разделить задачу на связанные компоненты, заданные как S = { S 1 ,… S n }, то размер пространства поиска является
ΠSi∈SB | Si | MathType @ СПР @ 5 @ 5 + = feaafiart1ev1aaatCvAUfKttLearuWrP9MDH5MBPbIqV92AaeXatLxBI9gBaebbnrfifHhDYfgasaacPC6xNi = xI8qiVKYPFjYdHaVhbbf9v8qqaqFr0xc9vqFj0dXdbba91qpepeI8k8fiI + FSY = rqGqVepae9pg0db9vqaiVgFr0xfr = XFR = xc9adbaqaaeGaciGaaiaabeqaaeqabiWaaaGcbaWaaebeaeaacqWGcbGqdaWgaaWcbaWaaqWaaeaacqWGtbWudaWgaaadbaGaemyAaKgabeaaaSGaay5bSlaawIa7aaqabaaabaGaem4uam1aaSbaaWqaaiabdMgaPbqabaWccqGHiiIZcqWGtbWuaeqaniabg + Givdaaaa @ 3A7C @Однако путем атаковать каждого из проблемы отдельно мы получаем размер пространства поиска в
ΣSi∈SB | Si | MathType @ СПР @ 5 @ 5 @ + = feaafiart1ev1aaatCvAUfKttLearuWrP9MDH5MBPbIqV92AaeXatLxBI9gBaebbnrfifHhDYfgasaacPC6xNi = xI8qiVKYPFjYdHaVhbbf9v8qqaqFr0xc9vqFj0dXdbba91qpepeI8k8fiI + FSY = rqGqVepae9pg0db9vqaiVgFr0xfr = XFR = xc9adbaqaaeGaciGaaiaabeqaaeqabiWaaaGcbaWaaabeaeaacqWGcbGqdaWgaaWcbaWaaqWaaeaacqWGtbWudaWgaaadbaGaemyAaKgabeaaaSGaay5bSlaawIa7aaqabaaabaGaem4uam1aaSbaaWqaaiabdMgaPbqabaWccqGHiiIZcqWGtbWuaeqaniabggHiLdaaaa @ 3A8D @ Таким образом, теперь следует, что сложность этой задачи в первую очередь зависит от размера наибольшего компонента связности. В стандартном случайном графе Эрдёша-Реньи это число растет логарифмически, если вероятность существования ребра между парой узлов меньше n -1 , как в нашей задаче. Хотя наша проблема на самом деле не эквивалентна случайному графу Эрдёша-Реньи, ложноположительные связи между различными синсетами могут быть разумно смоделированы с помощью графа Эрдёша-Реньи. Тем не менее, сложность наибольшего связанного компонента B c log( n ) не является полиномиальной, поэтому все еще возможно, что мы не сможем найти оптимальное решение для больших наборов тестов, однако это будет только влияют на самые большие связанные компоненты, которые по мере увеличения набора тестов будут представлять меньше терминов и, следовательно, меньше ссылок.В этом случае мы можем решить большую часть задачи точно, а часть — приблизительно, чтобы получить хорошее общее решение.
В стандартном случайном графе Эрдёша-Реньи это число растет логарифмически, если вероятность существования ребра между парой узлов меньше n -1 , как в нашей задаче. Хотя наша проблема на самом деле не эквивалентна случайному графу Эрдёша-Реньи, ложноположительные связи между различными синсетами могут быть разумно смоделированы с помощью графа Эрдёша-Реньи. Тем не менее, сложность наибольшего связанного компонента B c log( n ) не является полиномиальной, поэтому все еще возможно, что мы не сможем найти оптимальное решение для больших наборов тестов, однако это будет только влияют на самые большие связанные компоненты, которые по мере увеличения набора тестов будут представлять меньше терминов и, следовательно, меньше ссылок.В этом случае мы можем решить большую часть задачи точно, а часть — приблизительно, чтобы получить хорошее общее решение.
Поиск синонимов из NLTK WordNet в Python
Что такое Wordnet?
Wordnet — это программа для чтения корпусов NLTK, лексическая база данных для английского языка.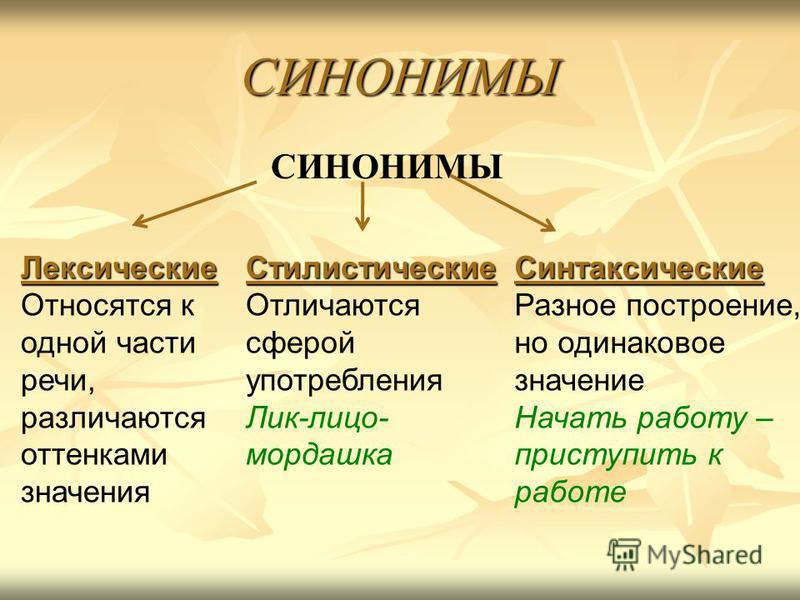 Его можно использовать для поиска значения слов, синонимов или антонимов. Его можно определить как семантически ориентированный словарь английского языка. Он импортируется с помощью следующей команды:
Его можно использовать для поиска значения слов, синонимов или антонимов. Его можно определить как семантически ориентированный словарь английского языка. Он импортируется с помощью следующей команды:
из nltk.corpus импортировать wordnet как гуру
Поиск синонимов из NLTK WordNet в Python
Статистика показывает, что существует 155287 слов и 117659 наборов синонимов , включенных в English WordNet.
Различные методы, доступные в WordNet, можно найти, набрав dir(guru)
. ‘__ge__’, ‘__getattr__’, ‘__getattribute__’, ‘__gt__’, ‘__hash__’, ‘__init__’, ‘__le__’, ‘__lt__’, ‘__module__’, ‘__name__’, ‘__ne__’, ‘__new__’, ‘__reduce__ ‘, ‘__reduce_ex__’, ‘__repr__’, ‘__setattr__’, ‘__sizeof__’, ‘__str__’, ‘__subclasshook__’, ‘__unicode__’, ‘__weakref__’, ‘_unload’, ‘subdir’, ‘unicode_repr’]
Давайте разберемся с некоторыми функциями, доступными в wordnet:
Synset : Его также называют набором синонимов или набором слов-синонимов. Давайте проверим пример
Давайте проверим пример
из nltk.corpus импортировать wordnet
syns = wordnet.synsets("собака")
печать (син.)
Вывод:
[Synset('dog.n.01'), Synset('frump.n.01'), Synset('dog.n.03'), Synset('cad.n.01'), Synset('frank .n.02'), Synset('pawl.n.01'), Synset('andiron.n.01'), Synset('chase.v.01')]
Лексические отношения : Это семантические отношения, которые взаимны. Если существует связь между {x1,x2,…xn} и {y1,y2,…yn}, то существует также связь между {y1,y2,…yn} и {x1,x2,…xn}.Например, синоним является противоположностью антонима или гиперонима, а гипоним является типом лексического понятия.
Давайте напишем программу, используя Python, для поиска синонима и антонима слова «активный» с помощью Wordnet.
из nltk.corpus импортировать wordnet
синонимы = []
антонимы = []
для син в wordnet.synsets("активный"):
для l в syn.lemmas():
synonyms.append(l.name())
если л.антонимы():
antonyms.append(l. antonyms()[0].name())
печать (набор (синонимы))
печать (набор (антонимы))
antonyms()[0].name())
печать (набор (синонимы))
печать (набор (антонимы))
Вывод кода:
{‘динамический’, ‘боевой’, ‘боевой’, ‘active_voice’, ‘active_agent’, ‘участвующий’, ‘живой’, ‘активный’} — Синоним
{‘стативный’, ‘пассивный’, ‘тихий’, ‘пассивный_голос’, ‘вымерший’, ‘спящий’, ‘неактивный’} — Антоним
Расшифровка кода
- Wordnet — это корпус, поэтому он импортируется из ntlk.корпус
- Список синонимов и антонимов считается пустым, который будет использоваться для добавления
- Синонимы слова active ищутся в синсетах модуля и добавляются в список синонимов. Тот же процесс повторяется для второго.
- Вывод распечатывается
Заключение:
WordNet — это лексическая база данных, которая использовалась крупной поисковой системой. Из WordNet можно рассчитать информацию о данном слове или фразе, например,
.- синоним (слова, имеющие одинаковое значение)
- гипернима (общий термин, используемый для обозначения класса особенностей (т.
 е., еда – это завтрак), гипонимы (рис – это еда)
е., еда – это завтрак), гипонимы (рис – это еда) - холонимы (белки, углеводы входят в состав пищи)
- меронимы (прием пищи является частью суточного рациона питания)
WordNet также предоставляет информацию о терминах координат, производных, смыслах и многом другом. Он используется для поиска сходства между любыми двумя словами. Он также содержит информацию о результатах связанного слова. Короче говоря, его можно рассматривать как словарь или тезаурус. Углубляясь в сеть слов, она разделена на четыре подсети, например
.- Существительное
- Глагол
- Прилагательное
- Наречие
Может использоваться в области искусственного интеллекта для анализа текста.С помощью Wordnet вы можете создать свой корпус для проверки орфографии, языкового перевода, обнаружения спама и многого другого.
Точно так же вы можете использовать этот корпус и настроить его для работы некоторых динамических функций. Это так же, как готовый корпус для вас. Вы можете использовать его по-своему.
Вы можете использовать его по-своему.
семантических факторов предсказывают скорость лексической замены слов содержания
Abstract
Скорость лексической замены оценивает диахроническую стабильность словоформ на основе того, как часто слово праязыка заменяется или сохраняется в своих дочерних языках.Было показано, что скорость лексической замены тесно связана с классом слов и частотой слов. В этой статье мы утверждаем, что содержательные слова и служебные слова ведут себя по-разному в отношении скорости лексической замены, и мы показываем, что семантические факторы предсказывают скорость лексической замены содержательных слов. Для 167 элементов контента в списке Сводеша были собраны данные о характеристиках скорости лексической замены, класса слов, частотности, возраста усвоения, синонимов, возбуждения, образности и средней взаимной информации либо из опубликованных баз данных, либо из корпусов и лексик. .Модель линейной регрессии показывает, что, помимо частоты, синонимы, смыслы и образность в значительной степени связаны с коэффициентом лексической замены содержательных слов, в частности, с количеством синонимов, которые есть у слова. Модель не показывает различий в скорости лексической замены между классами слов и превосходит модель только с предикторами класса слов и частоты слов.
Модель не показывает различий в скорости лексической замены между классами слов и превосходит модель только с предикторами класса слов и частоты слов.
Образец цитирования: Вейдемо С., Хёрберг Т. (2016) Семантические факторы прогнозируют скорость лексической замены содержательных слов.ПЛОС ОДИН 11(1): e0147924. https://doi.org/10.1371/journal.pone.0147924
Редактор: Наталья Л. Комарова, Калифорнийский университет, Ирвайн, США
Поступила в редакцию: 16 апреля 2015 г.; Принято: 11 января 2016 г.; Опубликовано: 28 января 2016 г.
Copyright: © 2016 Vejdemo, Hörberg. Это статья с открытым доступом, распространяемая в соответствии с условиями лицензии Creative Commons Attribution License, которая разрешает неограниченное использование, распространение и воспроизведение на любом носителе при условии указания автора и источника.
Доступность данных: Все соответствующие данные находятся в документе и в его файле вспомогательной информации.
Финансирование: Авторы не получали специального финансирования для этой работы.
Конкурирующие интересы: Авторы заявили об отсутствии конкурирующих интересов.
Введение
Слова в языках мира постоянно заменяются. Но не все слова заменяются в одном темпе или по одним и тем же причинам.Например, Даль [1] отметил, что со времен латыни слова «девушка» были заменены гораздо чаще в нескольких романских языках, чем слова «дерево». Каковы причины того, будет ли заменено слово или нет? Насколько быстрее заменяются одни слова, чем другие? Недавние исследования показали, что на эти вопросы можно частично ответить с помощью корреляционных статистических исследований языковых данных (см. [2], [3], [4], [5], [6]). В том же ключе цель этой статьи — показать, что, помимо частоты, семантические факторы (а именно синонимы, смыслы и образность) предсказывают скорость лексической замены содержательных слов.
Относительную скорость лексической замены понятия можно оценить, подсчитав количество раз, когда исходное праязыковое слово заменяется или сохраняется в своих дочерних языках (например, [1]; [2]). (Сохранение или отсутствие слова операционализируется как наличие или отсутствие родственного слова в списке первичных словоформ Сводеша. Естественно, отсутствие родственного слова в таком списке не означает, что родственного слова нет в языке с В остальной части этого текста родственное следует понимать как синонимичное родственное (также называемое s-родственным ) — слова, которые не только имеют общего предка, но и означают примерно одно и то же в настоящее время.) Пейджел и др. [2] рассчитали относительную скорость лексической замены первичных слов (ср. первичные обозначающие выражения в [7]) из 200 понятий списка Сводеша, основываясь на данных Дайена, Джеймса и Коула [8] о частоте изменение этих понятий в индоевропейских языковых разновидностях. В качестве иллюстрации в таблице 1 приведены переводные эквиваленты понятий «грязный» и «язык» в нескольких славянских и германских языках. В то время как в этой конкретной выборке языков есть восемь различных родственных классов для слова «грязный», во всех языках есть современное слово, родственное индоевропейскому исходному слову, обозначающему язык.(Точная категоризация родственных классов, конечно, может обсуждаться во всех случаях — для ЯЗЫКА Дарлинг Бак (1949: 230) отмечает, что другой корень, * sighwa , также может быть задействован, смешанный с * dnghwa .)
В то время как в этой конкретной выборке языков есть восемь различных родственных классов для слова «грязный», во всех языках есть современное слово, родственное индоевропейскому исходному слову, обозначающему язык.(Точная категоризация родственных классов, конечно, может обсуждаться во всех случаях — для ЯЗЫКА Дарлинг Бак (1949: 230) отмечает, что другой корень, * sighwa , также может быть задействован, смешанный с * dnghwa .)
Таблица 1. Переводные эквиваленты понятий грязный и язык в некоторых славянских и германских языках.
В то время как слова, обозначающие ГРЯЗЬ, происходят из восьми разных родственных классов, все слова, обозначающие ЯЗЫК, родственны индоевропейскому первоначальному слову *dnghwa и, следовательно, происходят из одного родственного класса.
https://doi.org/10.1371/journal.pone.0147924.t001
Если размер выборки увеличить, чтобы включить все индоевропейские языки в Dyen, James & Cole [8], всего будет 46 родственные классы для грязного и только 4 родственных класса для языка, что указывает на то, что первая концепция была заменена намного быстрее, чем вторая. Пейджел и др. [2] измерили уровень лексической замены, основанный на таких данных, но также взвешенный по отношениям языковой семьи между языками.Таким образом, показатель измеряет относительное разнообразие выборочных языков в списке Сводеша и может использоваться для оценки среднего относительного уровня лексической замены.
Пейджел и др. [2] измерили уровень лексической замены, основанный на таких данных, но также взвешенный по отношениям языковой семьи между языками.Таким образом, показатель измеряет относительное разнообразие выборочных языков в списке Сводеша и может использоваться для оценки среднего относительного уровня лексической замены.
Пейджел и др. [2] обнаружили, что как частота современных слов, так и класс слов предсказывают, сохранит ли понятие или изменит свой лексический инвентарь. Используя регрессионное моделирование, они обнаружили, что лемматизированная частота корпусов и классы слов объясняют большую часть дисперсии коэффициента лексической замены, независимо от того, из какого языка получена информация о частоте (английский, R = 0.69; испанский, R = 0,69; русский, R = 0,71; и греческий, R = 0,69: все p :s < 0,0001.) Понятия, которые чаще используются в современных корпусах, как правило, не заменяются так часто, как менее часто используемые понятия. При контроле частоты скорость замены самая высокая для понятий, обычно выражаемых предлогами и союзами, за которыми следуют прилагательные, глаголы, существительные, специальные наречия, местоимения и, наконец, числа.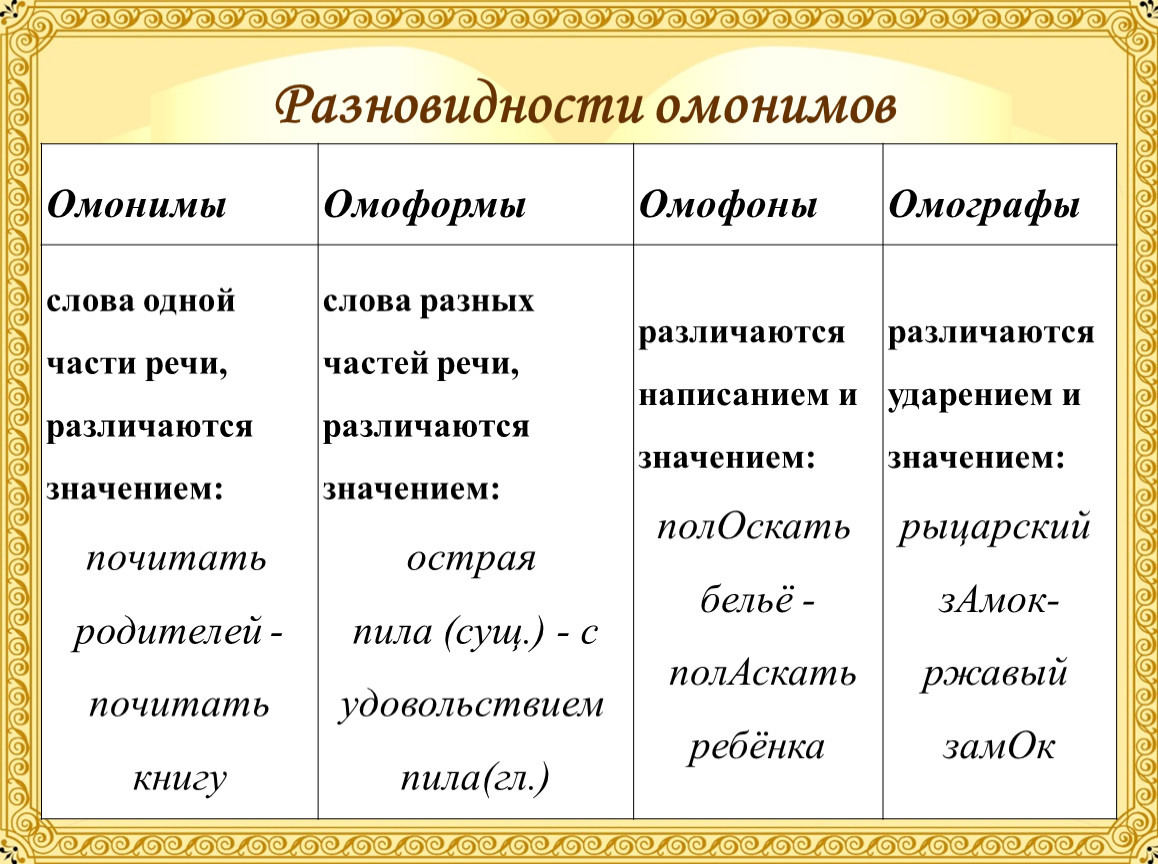 (Деление классов слов было сделано для метаязыка английского, а затем предполагалось, что оно будет одинаковым для всех родственных слов во всех других языках.Хотя это, скорее всего, выполнимо для индоевропейского языка, следует отметить, что этот метод может не подойти для других языковых семей, где классы слов могут быть совершенно другими.)
(Деление классов слов было сделано для метаязыка английского, а затем предполагалось, что оно будет одинаковым для всех родственных слов во всех других языках.Хотя это, скорее всего, выполнимо для индоевропейского языка, следует отметить, что этот метод может не подойти для других языковых семей, где классы слов могут быть совершенно другими.)
Опираясь на Pagel et al., Монаган [5] обнаружил, что возраст усвоения и коррелированные особенности конкретности и фонологической длины (слова, которые дети учат первыми, обычно относятся к конкретным объектам и являются короткими), влияют на скорость лексической замены.
В этой статье мы утверждаем, что целесообразно рассматривать служебные слова (такие как предлоги, союзы, наречия, местоимения и числа) и содержательные слова (существительные, глаголы и прилагательные) по-разному, когда мы пытаемся понять скорость лексической замены.Мы оценим прогностическую силу нескольких потенциальных семантических факторов, определяющих скорость лексической замены содержательных слов, с помощью корреляционных и множественных регрессионных тестов. Сначала мы сосредоточимся на различии между содержательными и служебными словами, и, как только мы убедимся, что стоит продолжать и рассматривать только содержательные слова, мы обратимся к степени их замещения.
Сначала мы сосредоточимся на различии между содержательными и служебными словами, и, как только мы убедимся, что стоит продолжать и рассматривать только содержательные слова, мы обратимся к степени их замещения.
Содержание и функциональные слова
При изучении факторов, влияющих на скорость лексической замены, есть веские причины рассматривать открытые и закрытые классы слов отдельно.Классы открытых слов содержат содержательные слова, такие как язык, камень, женщина, а классы закрытых слов содержат грамматические (функциональные) слова, такие как и, но, три. Классы открытых слов, особенно существительные, пополняются новыми членами (например, когда необходимо назвать новые объекты), в то время как новые грамматические функции появляются в языке реже. Существует также когнитивный разрыв в обработке мозгом содержательных и служебных слов. В то время как клинические пациенты, страдающие экспрессивной афазией, как правило, имеют проблемы с произношением служебных слов и морфосинтаксической структурой, пациенты с рецептивной афазией часто неспособны понимать и выбирать слова правильного содержания во время речеобразования [9]. Имеются также четкие различия в нейрофизиологической активности при обработке служебных слов по сравнению с обработкой содержательных слов [10–12].
Имеются также четкие различия в нейрофизиологической активности при обработке служебных слов по сравнению с обработкой содержательных слов [10–12].
Данные исследования Pagel et al. [2] также свидетельствуют о том, что концепты из открытых и закрытых классов слов ведут себя по-разному в отношении скорости их лексической замены. Классы слов, представленные в данных Pagel et al., принадлежат к двум различным группам: открытые (173 элемента: 40 прилагательных, 58 глаголов и 75 существительных) и закрытые (27 элементов: 3 союза (и, потому что, если), 3 предлогов (в, с, у), 5 числительных (один, два, три, четыре, пять), 7 наречий (здесь, там, как, где, когда, что, не) и 7 местоимений (я, ты, он, мы, вы, они, кто).) классы слов. Регрессионный анализ, проведенный отдельно для каждого языка в исследовании Pagel, показывает, что для слов закрытого класса вариация лексической замены в значительной степени зависит от различий классов слов (56,1% в английском, 51,6% в испанском, 56,1% в русском и 54,4%). % на греческом языке; все p :s < 0,001) и гораздо меньшая степень частотных различий (4% на английском, 0,8% на испанском, 5,6% на русском, 1,8% на греческом; все p :s < 0,001). Концепты из открытых классов слов, с другой стороны, составляют гораздо более однородную группу, для которой существенно большая часть вариации коэффициента лексического замещения остается необъяснимой: регрессионный анализ для слов открытого класса показывает, что даже когда частота и класс слов вместе взятые, они объясняют гораздо меньшую часть вариации (14.6% на английском, 15,2% на испанском, 16,2% на русском и 14,3% на греческом; все p :s < 0,0001). Различия в коэффициентах лексической замены между открытыми и закрытыми классами слов показаны на рис. 1. Все рисунки в этой статье были созданы с использованием пакета ggplot2 в статистическом программном обеспечении R [13,14].
% на греческом языке; все p :s < 0,001) и гораздо меньшая степень частотных различий (4% на английском, 0,8% на испанском, 5,6% на русском, 1,8% на греческом; все p :s < 0,001). Концепты из открытых классов слов, с другой стороны, составляют гораздо более однородную группу, для которой существенно большая часть вариации коэффициента лексического замещения остается необъяснимой: регрессионный анализ для слов открытого класса показывает, что даже когда частота и класс слов вместе взятые, они объясняют гораздо меньшую часть вариации (14.6% на английском, 15,2% на испанском, 16,2% на русском и 14,3% на греческом; все p :s < 0,0001). Различия в коэффициентах лексической замены между открытыми и закрытыми классами слов показаны на рис. 1. Все рисунки в этой статье были созданы с использованием пакета ggplot2 в статистическом программном обеспечении R [13,14].
Рис. 1. Коэффициент лексической замены в зависимости от нормализованной частоты в английском, греческом, русском и испанском языках для понятий открытых (красный: прилагательные, зеленый: существительные, синий: глаголы) и закрытых (желтый: наречия, серый: союзы, фиолетовый) : числа, бирюзовый: предлоги, оранжевый: местоимения) классы слов соответственно.
https://doi.org/10.1371/journal.pone.0147924.g001
Таким образом, мы предполагаем, что скорость изменения элементов закрытого класса больше связана с идиосинкразическими свойствами отдельного слова. Элементы закрытого класса всегда находятся дальше по континууму грамматизации и, следовательно, более абстрактны и универсальны по смыслу, более широко применимы и чаще используются [15]. В совокупности это говорит о том, что коэффициент лексической замены элементов закрытого класса в большей степени зависит от диахронических процессов конструкций, в которых эти элементы часто встречаются.С другой стороны, коэффициент лексической замены элементов открытого класса может быть менее чувствителен к диахроническим изменениям конкретных конструкций и больше зависеть от лексико-семантических и прагматических факторов этих элементов. Далее мы попытаемся установить, какими могут быть некоторые из этих факторов, используя корреляционный и линейный регрессионный анализ.
Материалы и методы
Прежде всего необходимо признать, что факторов, которые вызывают лексическую замену, вероятно, действительно очень много, и что их взаимодействие, без сомнения, сложное (см. грамм. Лэдд и др. [6] для обзора исследований взаимодействия таких факторов, как, например, скорость лексической замены, частота и конкретность). Также очень вероятно, что культурные соображения очень важны для замены слов, и что эти культурные соображения различаются между говорящими сообществами и с течением времени. Кроме того, определенные семантические домены (такие как части тела, термины родства, цвета и т. д.), вероятно, имеют специфичные для домена тенденции, когда речь идет о вероятности лексической замены.Наше исследование лексической замены ничего из этого не принимает во внимание, а вместо этого пытается исследовать, возможно ли найти доказательства того, что обобщения, переопределяющие предметную область, какие факторы могут влиять на скорость лексической замены.
грамм. Лэдд и др. [6] для обзора исследований взаимодействия таких факторов, как, например, скорость лексической замены, частота и конкретность). Также очень вероятно, что культурные соображения очень важны для замены слов, и что эти культурные соображения различаются между говорящими сообществами и с течением времени. Кроме того, определенные семантические домены (такие как части тела, термины родства, цвета и т. д.), вероятно, имеют специфичные для домена тенденции, когда речь идет о вероятности лексической замены.Наше исследование лексической замены ничего из этого не принимает во внимание, а вместо этого пытается исследовать, возможно ли найти доказательства того, что обобщения, переопределяющие предметную область, какие факторы могут влиять на скорость лексической замены.
Сначала мы представим мотивы включения каждого фактора и то, как эти факторы были введены в действие. Далее мы рассмотрим результаты корреляционных и множественных регрессионных тестов.
В этом исследовании исследуется взаимосвязь между семантическими факторами и скоростью лексической замены содержательных слов сверх частотности, класса слов и возраста усвоения — трех факторов, которые, по другим данным, влияют на скорость лексической замены (см. [2,5]). ).Этими факторами являются: совпадение с другими лексическими единицами, измеренное средней взаимной информацией ; визуализируемость ; вероятность эвфемизмов, измеренная с точки зрения возбуждения ; полисемия по количеству смыслов; и, наконец, число синонимов . Далее мы представляем мотивы для включения этих факторов и то, как они используются для статистического тестирования. За исключением данных о частоте и синонимах, все данные взяты из английского языка, возможная оговорка, к которой мы вернемся в ходе обсуждения.
[2,5]). ).Этими факторами являются: совпадение с другими лексическими единицами, измеренное средней взаимной информацией ; визуализируемость ; вероятность эвфемизмов, измеренная с точки зрения возбуждения ; полисемия по количеству смыслов; и, наконец, число синонимов . Далее мы представляем мотивы для включения этих факторов и то, как они используются для статистического тестирования. За исключением данных о частоте и синонимах, все данные взяты из английского языка, возможная оговорка, к которой мы вернемся в ходе обсуждения.
Частота слов и класс слов
Результаты Pagel et al. [2] ясно показывают, что частота слов и класс слов предсказывают скорость лексической замены. Мы также включаем частоту и класс слов в наше исследование. Данные о частоте взяты из среднего значения частот, указанных в Pagel et al. 2007 г. для английского, испанского, русского и греческого языков. Для повышения сопоставимости Pagel et al. данные использовались везде, где это было возможно. Частота слов часто выступает в качестве надежного предиктора в моделях, предсказывающих лексическое закрепление в памяти, но далеко не ясно, что именно измеряет частота использования слов в текстах, когда речь идет о человеческом познании.Баайен (2010) показал, что простое предположение о том, что частота, понимаемая как количество повторений слова, к которому привык говорящий/слушающий («счетчик в голове»), представляет уровни активации или уровень закрепления, может быть слишком верным. упрощенный. Баайен показывает, что в его модели лексического решения 90% дисперсии частоты слов можно предсказать по другим лексическим свойствам. Он указывает, что, хотя подсчет частоты часто является статистически сильным предиктором, например, Для экспериментов с лексическими решениями подсчет частоты на самом деле следует понимать как представляющий широкий спектр свойств лексического распределения, таких как контекстуальное разнообразие, дисперсия по разным типам текстов, соотношение того, как часто слово пишется или произносится и т.
Частота слов часто выступает в качестве надежного предиктора в моделях, предсказывающих лексическое закрепление в памяти, но далеко не ясно, что именно измеряет частота использования слов в текстах, когда речь идет о человеческом познании.Баайен (2010) показал, что простое предположение о том, что частота, понимаемая как количество повторений слова, к которому привык говорящий/слушающий («счетчик в голове»), представляет уровни активации или уровень закрепления, может быть слишком верным. упрощенный. Баайен показывает, что в его модели лексического решения 90% дисперсии частоты слов можно предсказать по другим лексическим свойствам. Он указывает, что, хотя подсчет частоты часто является статистически сильным предиктором, например, Для экспериментов с лексическими решениями подсчет частоты на самом деле следует понимать как представляющий широкий спектр свойств лексического распределения, таких как контекстуальное разнообразие, дисперсия по разным типам текстов, соотношение того, как часто слово пишется или произносится и т. д.Имея это в виду, что частота представляет собой не просто повторение, мы будем продолжать использовать частоту, чтобы не смешивать нашу модель с десятью или более дополнительными переменными, большинство из которых может быть трудно получить для элементов нашего списка Сводеша. данные класса также взяты из Pagel et al. [2].
д.Имея это в виду, что частота представляет собой не просто повторение, мы будем продолжать использовать частоту, чтобы не смешивать нашу модель с десятью или более дополнительными переменными, большинство из которых может быть трудно получить для элементов нашего списка Сводеша. данные класса также взяты из Pagel et al. [2].
Возраст приобретения
Монаган [5] обнаружил, что возраст приобретения коррелирует со скоростью замещения. Как и этот автор, мы используем данные Купермана и др. [16].
Взаимная информация
В качестве показателя частоты Pagel et al. [2] рассмотрели только количество слов, но мы полагаем, что может быть веская причина также включать другой вид измерения частоты, а именно вероятность совпадения с другими словами. Заменить слово, которое часто встречается вместе с другими словами в конструкциях, может быть труднее, чем заменить слово, которое не имеет таких общих сочетаний (например, брат может часто встречаться с сестрой, в то время как to go может не иметь такого сочетания). устойчивый лексический партнер, чтобы закрепить его).Таким образом, ожидается, что любая мера силы одновременности будет отрицательно связана со скоростью замещения.
устойчивый лексический партнер, чтобы закрепить его).Таким образом, ожидается, что любая мера силы одновременности будет отрицательно связана со скоростью замещения.
Вероятность совпадения определялась путем усреднения 20 самых высоких соседей взаимной информации каждого элемента в английском BNC. Взаимная информация — это измерение совместного появления, которое дает высокие значения двум элементам, которые часто встречаются одновременно ( соль будет иметь высокое значение MI с перцем ) и низкие значения элементам, которые редко встречаются одновременно ( соль будет иметь низкое значение MI с динозавром ).При расчете МИ для двух слов учитывается частота обоих слов независимо друг от друга и сопоставляется с вероятностью того, что эти слова встречаются вместе. Оценка взаимной информации элементов X и Y определяется как
где n(xy) — частота совпадений x и y, n(x) — частота x, n(y) — частота y, а ngramsize — размер исследуемого окна n-граммы. Данные взаимной информации для Британского национального корпуса объемом 100 миллионов слов были извлечены из http://corpus.интерфейс byu.edu/bnc/.
Данные взаимной информации для Британского национального корпуса объемом 100 миллионов слов были извлечены из http://corpus.интерфейс byu.edu/bnc/.
Возбуждение
Другим потенциальным фактором лексической замены является количество эвфемизмов понятия. Существует значительный объем исследований о влиянии табу и эвфемизмов на лексические изменения. Языковые табу, безусловно, могут быть очень локальными, но могут быть и если не универсальными, то, по крайней мере, весьма распространенными [17,18]. Как только существует лингвистическое табу, у говорящих есть различные стратегии, чтобы избежать оскорбительного слова [19,20]. Таким образом, эвфемизмы могут привести к большому множеству синонимов и ускоренной лексической замене.Берридж [21] пишет, что «очень немногие эвфемизмы, деградировавшие [путем ассоциации с табуированными темами] до табуированных терминов, возвращаются из бездны, даже после того, как они утратили свой табуированный смысл. Это способствует постоянно меняющейся лексике слов, обозначающих табуированные понятия». Гжега [22] также отмечает, что уничижение является важным фактором лексической замены, а Пинкер [23] назвал этот эффект «беговой дорожкой эвфемизма». Лингвистическое табу не бинарно: понятия могут быть более или менее табуированными и, таким образом, приводить к более или менее лексической замене [21].Хотя зачастую нетрудно указать явные случаи лингвистического табу (например, постоянно меняющийся словарный запас для табуированных понятий спермы, мочи или рвоты), существует также много случаев семантической деториации, когда табу, возможно, является слишком строгим. сильное слово. Гжега [22] приводит пример того, как слова для понятия «девушка» кажутся культурно окрашенными и должны часто меняться, чтобы избежать непреднамеренных ассоциаций, которые они постоянно вызывают, даже несмотря на то, что мало кто скажет, что девушки являются табу в e.грамм. англоязычных обществ. Если можно найти измерение для этого «эмоционального заряда», связанного с понятиями, порождающими эвфемизм, можно было бы ожидать, что он будет положительно связан со скоростью лексической замены: те понятия, которые имеют более высокий эмоциональный заряд (возможно, умереть, женщина) и т.
Гжега [22] также отмечает, что уничижение является важным фактором лексической замены, а Пинкер [23] назвал этот эффект «беговой дорожкой эвфемизма». Лингвистическое табу не бинарно: понятия могут быть более или менее табуированными и, таким образом, приводить к более или менее лексической замене [21].Хотя зачастую нетрудно указать явные случаи лингвистического табу (например, постоянно меняющийся словарный запас для табуированных понятий спермы, мочи или рвоты), существует также много случаев семантической деториации, когда табу, возможно, является слишком строгим. сильное слово. Гжега [22] приводит пример того, как слова для понятия «девушка» кажутся культурно окрашенными и должны часто меняться, чтобы избежать непреднамеренных ассоциаций, которые они постоянно вызывают, даже несмотря на то, что мало кто скажет, что девушки являются табу в e.грамм. англоязычных обществ. Если можно найти измерение для этого «эмоционального заряда», связанного с понятиями, порождающими эвфемизм, можно было бы ожидать, что он будет положительно связан со скоростью лексической замены: те понятия, которые имеют более высокий эмоциональный заряд (возможно, умереть, женщина) и т. д. .. и те, которые приводят к большему количеству эвфемизмов, будут подвергаться словесной замене быстрее, чем те, которые имеют меньший эмоциональный заряд (камень, идти).
д. .. и те, которые приводят к большему количеству эвфемизмов, будут подвергаться словесной замене быстрее, чем те, которые имеют меньший эмоциональный заряд (камень, идти).
Вероятность того, что понятие порождает множество эвфемизмов, операционализируется другим общепринятым в психологии показателем: возбуждение .Возбуждение (вместе с валентностью и силой) измеряется методом семантического дифференциала (впервые разработанным Осгудом [24]) с помощью опросников, в которых говорящие оценивают слово по нескольким разным осям. Высокое возбуждение означает, что слово вызывает у участника больше эмоций, чем низкое. В этом исследовании используются данные Warriner et al. [25].
Образность
Существует заметная разница между понятиями с высокой степенью образности (т. е. легко изображаемыми в уме) и менее образными понятиями.Во многих психолингвистических исследованиях изучалась разница в обработке мозгом этих двух категорий понятий: Пайвио [26] основывает теорию двойного кодирования когнитивной организации частично на различии между обработкой легко визуализируемых и трудно визуализируемых слов. Кратч и Уоррингтон [27] также пишут о принципиальных различиях между категориями. Мартенссон и др. [28] показывают, что существительные, связанные с сенсорными семантическими (зрительными и иными) характеристиками, обрабатываются в разных частях мозга, чем те, которые этого не делают.Была проделана работа над различиями между легко и не так легко изображаемыми существительными [29], а также в глаголах [30]. Связь между способностью к воображению и лексической заменой, в частности, между низкой способностью к воображению и медленной лексической заменой, также была выявлена в пилотном исследовании [3], в котором изучалась лексическая замена в словарном запасе для понятий как в индоевропейском, так и в австронезийском языках. Ожидается, что те понятия, которые легче представить и изобразить в сознании говорящих (камень, в отличие от старых), будут подвергаться меньшему количеству словесных замен.Таким образом, любая мера изобразительности будет иметь отрицательную связь со скоростью замещения.
Кратч и Уоррингтон [27] также пишут о принципиальных различиях между категориями. Мартенссон и др. [28] показывают, что существительные, связанные с сенсорными семантическими (зрительными и иными) характеристиками, обрабатываются в разных частях мозга, чем те, которые этого не делают.Была проделана работа над различиями между легко и не так легко изображаемыми существительными [29], а также в глаголах [30]. Связь между способностью к воображению и лексической заменой, в частности, между низкой способностью к воображению и медленной лексической заменой, также была выявлена в пилотном исследовании [3], в котором изучалась лексическая замена в словарном запасе для понятий как в индоевропейском, так и в австронезийском языках. Ожидается, что те понятия, которые легче представить и изобразить в сознании говорящих (камень, в отличие от старых), будут подвергаться меньшему количеству словесных замен.Таким образом, любая мера изобразительности будет иметь отрицательную связь со скоростью замещения.
При измерении способности к воображению участников спрашивали, насколько легко сформировать мысленный образ при предъявлении определенного слова. Тесно связанной с образностью семантической характеристикой является конкретность: в этом случае участников спрашивают, насколько конкретно слово (см. Hills and Adelman [31] для обсуждения того, как конкретность взаимодействует с обучаемостью и использованием слова). Монаган [5] показывает, что конкретность коррелирует со скоростью лексической замены, используя данные Brysbaert et al [32].В этом исследовании используются данные об имидже от Cortese & Fugett [33], которые опубликовали рейтинги имиджа от носителей английского языка для многих английских слов. Данные по визуализируемости Cortese & Fugett и Brysbaert et al. данные о конкретности элементов Сводеша сильно коррелируют (r = 0,88 p < 0,0001).
Чувства
Степень многозначности основного слова понятия и, следовательно, многозначности может также влиять на скорость его лексической замены. Многозначные слова могут использоваться в более различных жанрах, чем малозначительные слова, и это может привести к большему укоренению, которое, таким образом, может в некоторой степени изолировать слово от замещения (см. обсуждение укоренения в [34]). Следовательно, измерение количества семантических смыслов должно иметь отрицательную связь со скоростью замены.
Многозначные слова могут использоваться в более различных жанрах, чем малозначительные слова, и это может привести к большему укоренению, которое, таким образом, может в некоторой степени изолировать слово от замещения (см. обсуждение укоренения в [34]). Следовательно, измерение количества семантических смыслов должно иметь отрицательную связь со скоростью замены.
В исследовании количество смыслов было определено на основе лексической базы данных Wordnet English [35], где все лексические единицы помечены тем, сколько у них значений.
Синонимы
Наконец, есть веские основания подозревать, что количество синонимов, которое имеет понятие, связано с коэффициентом его лексической замены. Имеются убедительные доказательства из психологии и нейробиологии, что слова и значения в уме хранятся в некой сетевой структуре ([36], глава 10). В задачах на ассоциации, где участников просят свободно ассоциировать от данного слова-стимула, целевое слово, как правило, семантически связано со словом-стимулом с точки зрения координации (слова, которые семантически группируются вместе, например, бабочка и мотылек, и часто имеют общий гипероним). ), словосочетание (слова, которые часто встречаются вместе со стимулом, например, соль и вода, яркое и красное), суперординация (насекомое вызывается бабочкой) и синонимия (голодный и голодный) [37].В задачах на лексическое решение, в которых испытуемые определяют, является ли слово-стимул правильным словом или бессмысленным словом, время ответа ниже [38], а нейрофизиологический ответ на лексико-семантический процесс снижается [39], когда целевому слову предшествует целевое слово. семантически родственное слово. Таким образом, семантически связанные слова предшествуют друг другу, указывая на то, что они совместно активируются во время лексического доступа и, таким образом, психологически связаны. Трауготт и Дашер [34] пишут, что основной движущей силой регулярных семантических изменений является прагматизм, и что если слово приобретается или заменяется для определенного понятия, это происходит постепенно.Прагматический когнитивный инструмент логического вывода является важной частью лексической замены и изменения: если значения M1 и M2 каким-то образом семантически связаны, W2, обозначающее M2, может посредством логического вывода обозначать M1.
), словосочетание (слова, которые часто встречаются вместе со стимулом, например, соль и вода, яркое и красное), суперординация (насекомое вызывается бабочкой) и синонимия (голодный и голодный) [37].В задачах на лексическое решение, в которых испытуемые определяют, является ли слово-стимул правильным словом или бессмысленным словом, время ответа ниже [38], а нейрофизиологический ответ на лексико-семантический процесс снижается [39], когда целевому слову предшествует целевое слово. семантически родственное слово. Таким образом, семантически связанные слова предшествуют друг другу, указывая на то, что они совместно активируются во время лексического доступа и, таким образом, психологически связаны. Трауготт и Дашер [34] пишут, что основной движущей силой регулярных семантических изменений является прагматизм, и что если слово приобретается или заменяется для определенного понятия, это происходит постепенно.Прагматический когнитивный инструмент логического вывода является важной частью лексической замены и изменения: если значения M1 и M2 каким-то образом семантически связаны, W2, обозначающее M2, может посредством логического вывода обозначать M1. Таким образом, можно ожидать, что концепции, которые в большей степени вовлечены в большее количество выводов, будут заменяться чаще.
Таким образом, можно ожидать, что концепции, которые в большей степени вовлечены в большее количество выводов, будут заменяться чаще.
Элементы с более семантическими связями с другими элементами могут иметь более высокую вероятность замены, поскольку это означает, что заменить элемент ближайшим синонимом будет проще.Следовательно, количество синонимов понятия должно быть положительно связано с коэффициентом лексической замены.
В исследовании количество синонимов , которое есть у слова, измеряется путем подсчета количества предлагаемых синонимов в словарях синонимов. Для английских данных синонимы взяты из Оксфордского карманного американского тезауруса [40], так как из него оказалось легко автоматически извлекать данные. Однако словари синонимов содержат не только синонимы, но и распространенные гипонимы и гиперонимы, а также метафорические синонимы.Некоторые слова имеют больше метафорических синонимов, чем другие. В любом случае все эти семантические отношения являются свидетельством семантических связей, и для краткости в этой статье для их обозначения будут использоваться «синонимы». Чтобы получить более сбалансированное среднее количество синонимов для основного понятия, мы также собрали данные из словарей синонимов на четырех других германских языках: шведском [41], датском [42], немецком (http://www.woerterbuch.info/ ) и нидерландском (http://synoniemen.net), и усреднили количество синонимов, сначала взвесив его по многословности конкретного словаря синонимов (если бы среднее количество заданных синонимов было 18, количество синонимов для конкретного слова было бы разделить на 18), а затем усреднить результат по всем пяти языкам.
Чтобы получить более сбалансированное среднее количество синонимов для основного понятия, мы также собрали данные из словарей синонимов на четырех других германских языках: шведском [41], датском [42], немецком (http://www.woerterbuch.info/ ) и нидерландском (http://synoniemen.net), и усреднили количество синонимов, сначала взвесив его по многословности конкретного словаря синонимов (если бы среднее количество заданных синонимов было 18, количество синонимов для конкретного слова было бы разделить на 18), а затем усреднить результат по всем пяти языкам.
Важно иметь в виду, что некоторые из этих переменных не могут быть независимыми друг от друга: некоторые из них могут быть взаимосвязаны. Особое внимание следует уделить тому, как класс слов взаимодействует с различными переменными.
Результаты и обсуждение
Источники данных для независимых переменных в модели обсуждались в предыдущем разделе. Зависимая переменная, скорость лексической замены, взята из [2]. Данные касаются 167 из 173 элементов, перечисленных в [2] как слова открытого класса: отсутствующие шесть элементов перечислены как слова открытого класса, но оцениваются нами как семантически близкие к элементам закрытого класса (это: все, немногие, многие, близкие, другие, некоторые, тот, этот), и так были исключены.
Данные касаются 167 из 173 элементов, перечисленных в [2] как слова открытого класса: отсутствующие шесть элементов перечислены как слова открытого класса, но оцениваются нами как семантически близкие к элементам закрытого класса (это: все, немногие, многие, близкие, другие, некоторые, тот, этот), и так были исключены.
Все статистические анализы были проведены с помощью статистического программного обеспечения R, в основном с интегрированным статистическим пакетом [13]. Предикторы частоты, ощущений и возраста приобретения были логарифмически преобразованы, чтобы иметь приблизительно нормальное распределение. В качестве начального анализа были исследованы корреляции между всеми непрерывными переменными. Матрица корреляции с корреляциями Пирсона между всеми переменными показана в таблице 2. Как видно из таблицы, коэффициент лексической замены значительно коррелирует с частотой, возрастом приобретения, синонимами, взаимной информацией и образностью.
Также существует высокая корреляция между многими самими зависимыми переменными (например, синонимы и смыслы, взаимная информация и образность).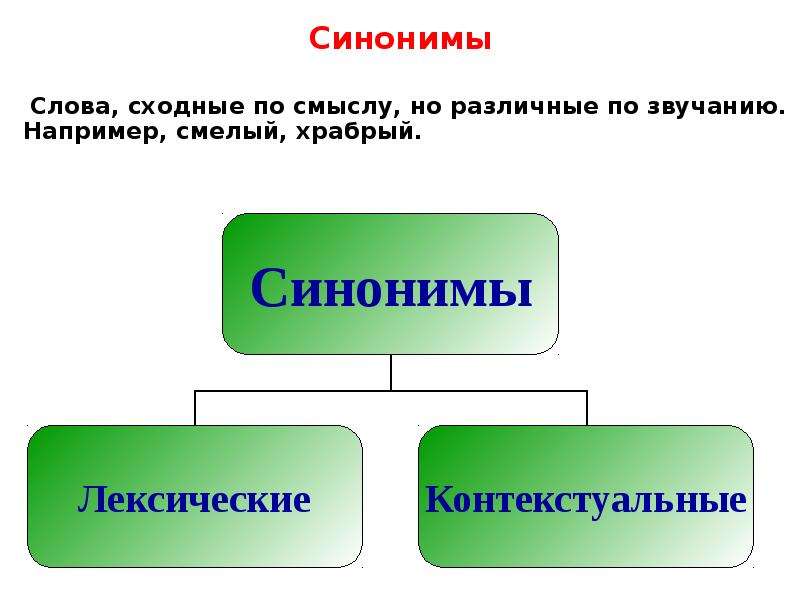 Поэтому неясно, действительно ли коэффициент лексического замещения индивидуально связан с имеющимися переменными, или же эти отношения опосредованы взаимозависимостью между самими зависимыми переменными.
Поэтому неясно, действительно ли коэффициент лексического замещения индивидуально связан с имеющимися переменными, или же эти отношения опосредованы взаимозависимостью между самими зависимыми переменными.
Чтобы решить эту проблему, данные были проанализированы с использованием множественного регрессионного моделирования. Этот метод моделирует нормально распределенную непрерывную переменную, переменную результата, как линейную комбинацию набора независимых переменных или предикторов.Важно отметить, что модель оценивает индивидуальные взаимосвязи между каждым предиктором и переменной результата, контролируя влияние всех других переменных-предикторов в модели путем их частичного исключения. Модель содержит непрерывные предикторы, показанные в таблице 2, вместе с предиктором класса слов (т. е. класс слова, частота (в логарифмической форме, далее LogFrequency), возраст приобретения (далее LogAgeofAcq), образность, взаимная информация, синонимы, чувства ( далее LogSense) и Arousal).
Проблема линейной регрессии заключается в том, что переобучает регрессионной модели. Если модель содержит слишком много предикторов по отношению к размеру выборки, коэффициенты модели могут быть чрезмерно оптимистичными, и предсказания модели не будут распространяться за пределы данных выборки (см., например, [43]). Переобучение оценивали с помощью бутстрап-валидации. Суммарное переоснащение оценивалось путем расчета коэффициентов усадки γ 0 и γ 1 на основе 10000 бутстраповых образцов с использованием пакета boot [44].Модель обновляется для каждой выборки начальной загрузки, и наблюдаемые значения исходного набора данных регрессируют по сравнению с прогнозируемыми значениями каждой модели начальной загрузки. Затем γ 0 и γ 1 оцениваются как среднее отрезков и наклонов бутстрэпных моделей. Коэффициенты существенно не отличались от пересечения и наклона наблюдаемых значений, регрессировавших по сравнению с предсказанными значениями исходной модели (т. е. 0 и 1 соответственно), как видно из тестов Z (γ 0 = 0.41, Z = -0,92, р = 0,36; γ 1 = 0,87, Z = 0,95, p = 0,34) (ср. [45,46,47]).
е. 0 и 1 соответственно), как видно из тестов Z (γ 0 = 0.41, Z = -0,92, р = 0,36; γ 1 = 0,87, Z = 0,95, p = 0,34) (ср. [45,46,47]).
Последней проблемой линейной регрессии является (мульти)коллинеарность, то есть корреляция между двумя или несколькими предикторами в модели. Коллинеарные предикторы могут по отдельности не учитывать дисперсию переменной результата. Это, в свою очередь, увеличивает стандартные ошибки оценок коэффициентов и, следовательно, снижает достоверность этих оценок. Как показано в таблице 2, высокая корреляция между отдельными предикторами вместе с показателями фактора инфляции дисперсии (макс. VIF: 5.9), который оценивает корреляции между отдельным предиктором и всеми другими предикторами модели (см., например, Harrell, 2010: 65), указывает на то, что мультиколлинеарность может быть проблемой. Поэтому бутстрэппинг также использовался для проверки значимости отдельных предикторов независимо от их стандартных ошибок. Оценки предикторов были рассчитаны на основе 10 000 бутстрап-выборок, показанных в таблице 3. Статистика предикторов бутстрап-модели подтверждает эффекты предикторов в исходной модели с точки зрения направления эффекта и значимости (см. табл. 3) и, следовательно, свидетельствует о том, что стабильность предикторов.
Оценки предикторов были рассчитаны на основе 10 000 бутстрап-выборок, показанных в таблице 3. Статистика предикторов бутстрап-модели подтверждает эффекты предикторов в исходной модели с точки зрения направления эффекта и значимости (см. табл. 3) и, следовательно, свидетельствует о том, что стабильность предикторов.
Таблица 3. Коэффициенты β и статистика вывода исходной и бутстрепной модели.
Таблица также включает 95% точечные доверительные интервалы для коэффициентов, основанные на квантилях 0,025 и 0,975 оценок коэффициентов 10000 выборок начальной загрузки. Таблица также включает ΔR 2 для каждого предиктора, то есть долю дисперсии коэффициента лексической замены, объясненную каждым предиктором, по сравнению со всеми другими предикторами в модели.По техническим причинам переменная класса слов, которая имеет три значения (глагол, существительное или прилагательное), представлена в виде трех разных двоичных переменных: класс слов: существительное, класс слов: глагол, класс слов: прилагательное, и последняя из них не введен в модель, так как его информация уже есть: если что-то не является глаголом или существительным, это прилагательное.
https://doi.org/10.1371/journal.pone.0147924.t003
Модель показывает достойную посадку (N = 117, R 2 = 0.34, F (9, 99) = 5,62, p < 0,0001), что объясняет около 34% дисперсии коэффициента лексической замены. Важно отметить, что соответствие значительно лучше, чем у модели, включающей только логарифмическую частоту и класс слов в качестве предикторов (χ 2 (6) = 247,42, p < 0,0001). Статистика предиктора показана в таблице 3, которая включает статистику как исходной, так и бутстрепной модели. В последнем столбце сообщается ΔR 2 каждого предиктора, который является мерой доли дисперсии коэффициента лексической замены, объясненной каждым отдельным предиктором, по сравнению со всеми другими предикторами в модели.ΔR 2 рассчитано с помощью пакета lmSupport [48].
Результаты регрессионного моделирования повторяют результаты Pagel et al. [2], показав, что частота слов является сильным предиктором скорости лексической замены. Частота объясняет примерно 16,3% его дисперсии после учета влияния всех других предикторов: чем чаще встречается понятие, тем меньше вероятность замены его первичной лексической формы, о чем свидетельствует отрицательный знак бета-коэффициента. .
Частота объясняет примерно 16,3% его дисперсии после учета влияния всех других предикторов: чем чаще встречается понятие, тем меньше вероятность замены его первичной лексической формы, о чем свидетельствует отрицательный знак бета-коэффициента. .
Таблица 3 также показывает, что образность концепта также связана с уменьшением скорости его лексической замены. Предиктор Imageability объясняет около 6,1% дисперсии коэффициента замещения. Хотя мы не обнаружили существенной корреляции между коэффициентом лексической замены и LogSenses (см. Таблицу 2), существует значительный эффект LogSenses, объясняющий около 3,4% дисперсии коэффициента лексического замещения, когда все другие факторы контролируются для: понятий, чьи первичные формы с большим числом смыслов демонстрируют слабое, хотя и значительное, снижение коэффициента лексической замены.Этот негативный эффект возникает при контроле синонимов и показан на рис. 2: когда концепты группируются по среднему количеству синонимов, обнаруживается сильная отрицательная связь между LexicalReplacementRate и LogSenses.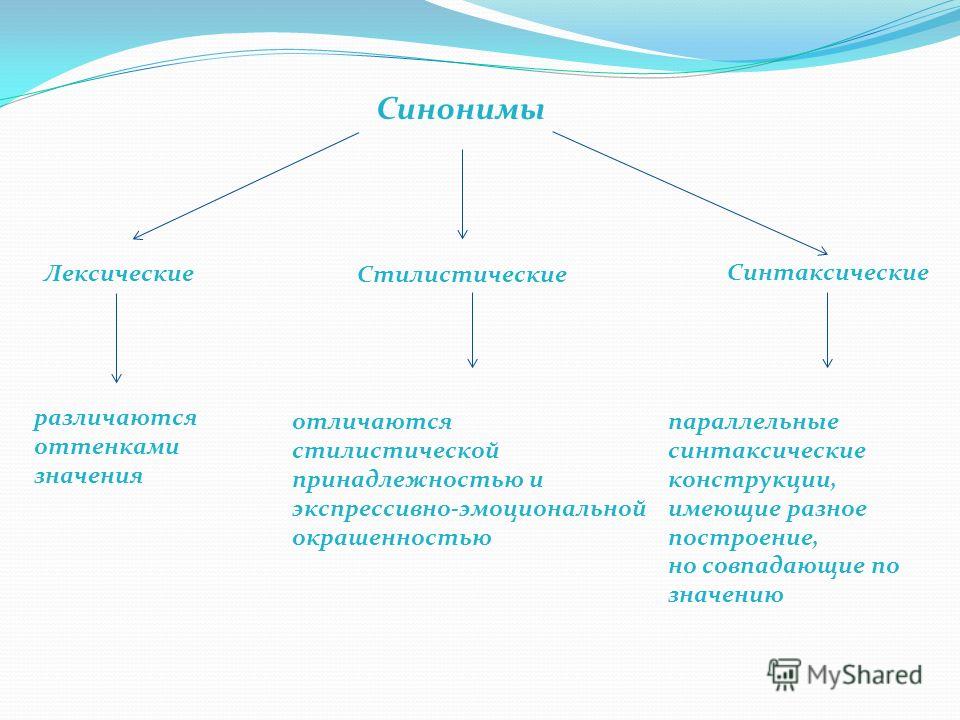
Рис. 2. Диаграммы рассеяния зависимости между скоростью лексической замены и logSenses.
На левой панели показана взаимосвязь между коэффициентом лексической замены и LogSenses для трех различных уровней синонимов (Низкий: 0–0.65 означают синонимы; Средний: 0,65–1,1 означает синонимы; и Высокий: 1,1–2,65 означают синонимы). На правой панели показана взаимосвязь между коэффициентом лексической замены и LogSenses, когда среднее количество синонимов не контролируется. Заштрихованные области представляют 95% доверительные интервалы наклонов линий регрессии.
https://doi.org/10.1371/journal.pone.0147924.g002
Важно отметить, что модель также показывает, что среднее количество синонимов, перечисленных в словарях синонимов для понятия, почти так же сильно связано с коэффициентом лексической замены. как частота.Предиктор Synonyms объясняет около 12,5% дисперсии коэффициента замещения. Чем больше среднее количество синонимов, используемых для понятия, тем больше вероятность того, что его первичная форма будет заменена. Наконец, регрессионная модель показывает, что индивидуальные отношения между коэффициентом лексического замещения и взаимной информацией (см. Таблицу 2) на самом деле опосредованы другими переменными в модели: как только их влияние учтено, связь исчезает.
Наконец, регрессионная модель показывает, что индивидуальные отношения между коэффициентом лексического замещения и взаимной информацией (см. Таблицу 2) на самом деле опосредованы другими переменными в модели: как только их влияние учтено, связь исчезает.
Аналогичным образом, в отличие от Монагана [5], мы не обнаружили связи между скоростью лексической замены и возрастом овладения, когда по крайней мере контролируется частота.Дополнительный регрессионный анализ, в котором скорость лексической замены была регрессирована по отношению к возрасту приобретения и частоте, также не обнаружил значительного влияния возраста приобретения на скорость лексической замены. Мы успешно воспроизвели исследование Монагана для всего набора данных этого исследования из 200 элементов, а затем добавили к этому набору данных бинарную переменную открытый класс (все существительные, глаголы, прилагательные; 173 элемента) / закрытый класс (оставшиеся 27 элементов). Влияние возраста усвоения на скорость лексического замещения на самом деле обусловлено разницей между словами открытого и закрытого классов. Мы провели отдельный анализ данных Моханагана по словам открытого и закрытого классов, соответственно, и не обнаружили значительного влияния возраста приобретения ни в одном из них. Однако, что более важно, когда предиктор класса слов заменяется предиктором, различающим только слова открытого и закрытого классов, тем самым контролируя их различие, анализ полного набора данных не обнаруживает значительного влияния возраста приобретения.
Мы провели отдельный анализ данных Моханагана по словам открытого и закрытого классов, соответственно, и не обнаружили значительного влияния возраста приобретения ни в одном из них. Однако, что более важно, когда предиктор класса слов заменяется предиктором, различающим только слова открытого и закрытого классов, тем самым контролируя их различие, анализ полного набора данных не обнаруживает значительного влияния возраста приобретения.
Влияние возбуждения и класса слов также не было статистически значимым.
Существенные отношения между LogFrequency, Synonyms, Imageability и LogSenses, с одной стороны, и коэффициентом лексической замены, с другой, показаны на рис. влияние всех остальных предикторов постоянно. Это делается путем построения коэффициента лексической замены по остаткам каждой переменной-предиктора, регрессировавшей по отношению ко всем другим предикторам.
Рис. 3. Диаграммы рассеяния взаимосвязей между скоростью лексической замены и (A) остаточной логарифмической частотой, (B) остаточной синонимами, (C) остаточной образностью и (D) остаточной смысловой нагрузкой.
Заштрихованные области представляют 95% доверительные интервалы наклонов линий регрессии.
https://doi.org/10.1371/journal.pone.0147924.g003
Выводы
В этой статье мы утверждали, что служебные и содержательные слова ведут себя по-разному в отношении скорости их лексической замены.Предыдущие исследования факторов, влияющих на скорость лексической замены, рассматривали служебные и содержательные слова вместе — при разделении этих двух групп становится ясно, что они ведут себя совершенно по-разному.
Мы также показали, что, в дополнение к частоте, количество синонимов, образность и количество смыслов, связанных с содержательными словесными понятиями, предсказывают скорость лексической замены этих понятий. Чем больше синонимов используется для понятия, тем выше коэффициент лексической замены этого понятия.Мы связываем это с тем, что наличие других семантически близких слов облегчает вывод и замену. Мы также обнаружили отрицательную связь между образностью (т. е. легкостью, с которой понятие изображается в сознании) понятий и коэффициентом их лексической замены. Таким образом, понятия, которые легче представить и представить в сознании говорящих, менее подвержены словесной замене. Хиллс и Адельман [31] отмечают, что конкретность (и, можно предположить, также подобная мера образности) в языке может увеличиваться по мере того, как в нем появляется больше носителей второго языка, что английский делал в течение последних нескольких столетий, и это может способствовать тому, что более конкретные слова более устойчивы с течением времени.Наконец, мы обнаружили небольшую отрицательную связь между числом значений понятия и коэффициентом его лексической замены. Мы предполагаем, что очень часто встречающиеся и многозначные слова (т. е. используемые во многих разных жанрах) прочно укоренились и, следовательно, их труднее заменить.
е. легкостью, с которой понятие изображается в сознании) понятий и коэффициентом их лексической замены. Таким образом, понятия, которые легче представить и представить в сознании говорящих, менее подвержены словесной замене. Хиллс и Адельман [31] отмечают, что конкретность (и, можно предположить, также подобная мера образности) в языке может увеличиваться по мере того, как в нем появляется больше носителей второго языка, что английский делал в течение последних нескольких столетий, и это может способствовать тому, что более конкретные слова более устойчивы с течением времени.Наконец, мы обнаружили небольшую отрицательную связь между числом значений понятия и коэффициентом его лексической замены. Мы предполагаем, что очень часто встречающиеся и многозначные слова (т. е. используемые во многих разных жанрах) прочно укоренились и, следовательно, их труднее заменить.
В отличие от Monaghan (2014), мы не обнаружили связи между скоростью лексической замены и возрастом приобретения, когда хотя бы частота контролировалась. Мы также не смогли показать какого-либо существенного вклада фактора взаимной информации в регрессионной модели, даже несмотря на то, что он значительно коррелирует со скоростью лексической замены сам по себе.Кроме того, хотя некоторый эффект возбуждения на степень замещения некоторых табуированных понятий кажется бесспорным, мы не смогли показать, что это, когда оно измеряется значениями возбуждения, полученными в экспериментах с семантическим дифференциалом, применимо в целом.
Мы также не смогли показать какого-либо существенного вклада фактора взаимной информации в регрессионной модели, даже несмотря на то, что он значительно коррелирует со скоростью лексической замены сам по себе.Кроме того, хотя некоторый эффект возбуждения на степень замещения некоторых табуированных понятий кажется бесспорным, мы не смогли показать, что это, когда оно измеряется значениями возбуждения, полученными в экспериментах с семантическим дифференциалом, применимо в целом.
Недостатком этого исследования является то, что, хотя скорость лексической замены рассчитывается на основе данных из многих различных индоевропейских языков, все независимые переменные основаны на данных либо из нескольких германских языков, либо только из английского.Причина использования в основном данных на английском языке была практической, поскольку в настоящее время нет других языков, на которых были бы завершены существенные усилия по сбору данных, необходимые для сбора данных для зависимых переменных. Дополнительные данные и дальнейшие исследования сделают результаты более надежными для распространения на другие индоевропейские языки. Однако мы считаем, что недостатки независимых переменных должны работать против гипотез, а не в их пользу: уже в этом ограниченном исследовании видны сильные корреляции между переменными, даже если идиосинкразии с e.грамм. отдельные языковые омонимы должны приводить к большему шуму. Если бы независимые переменные были основаны на данных репрезентативной выборки индоевропейских языков, мы ожидаем, что отношения между ними и скоростью лексической замены будут более сильными, а не более слабыми.
Дополнительные данные и дальнейшие исследования сделают результаты более надежными для распространения на другие индоевропейские языки. Однако мы считаем, что недостатки независимых переменных должны работать против гипотез, а не в их пользу: уже в этом ограниченном исследовании видны сильные корреляции между переменными, даже если идиосинкразии с e.грамм. отдельные языковые омонимы должны приводить к большему шуму. Если бы независимые переменные были основаны на данных репрезентативной выборки индоевропейских языков, мы ожидаем, что отношения между ними и скоростью лексической замены будут более сильными, а не более слабыми.
В заключение мы пришли к выводу, что есть основания оценивать служебные слова и содержательные слова отдельно по степени их лексической замены и что, помимо частоты, семантические факторы синонимов, смыслов и образов предсказывают скорость лексической замены. содержательных слов.
Благодарности
Авторы выражают благодарность Bernhard Wälchli и Michael Dunn за ценные комментарии к ранним черновикам, а также Thomas Hills и команду PlosOne за очень хорошие отзывы и предложения перед публикацией.
Авторские взносы
Инициатива и разработка экспериментов: С.В.Т.Х. Выполняли опыты: SV TH. Проанализированы данные: SV TH. Предоставленные реагенты/материалы/инструменты для анализа: SV TH. Написал статью: SV TH.
Каталожные номера
- 1.Даль О. Рост и поддержание лингвистической сложности [Интернет]. Амстердам; Филадельфия: Джон Бенджаминс; 2004 [цитировано 30 января 2013 г.]. Доступно: http://search.ebscohost.com/login.aspx?direct=true&scope=site&db=nlebk&db=nlabk&AN=148664
- 2. Пейджел М., Аткинсон К., Мид А. Частота употребления слов предсказывает скорость лексической эволюции на протяжении всей индоевропейской истории. Природа. 2007;449(7163):717–20. пмид:17928860
- 3. Вейдемо С.Межъязыковое лексическое изменение: почему, как и как быстро? Материалы WIGL 2010 [Интернет]. Висконсин; 2010. Доступно: http://vanhise.lss.wisc.edu/ling/?q=node/164
- 4.
Калуд А.С., Пейджел М. Как мы используем язык? Общие закономерности в частоте использования слов в 17 языках мира.
 Philos Trans R Soc B Biol Sci. 2011 г., 4 декабря; 366 (1567): 1101–1107.
Philos Trans R Soc B Biol Sci. 2011 г., 4 декабря; 366 (1567): 1101–1107. - 5. Монаган П. Возраст приобретения предсказывает скорость лексической эволюции. Познание. 9 сентября 2014 г .; 133 (3): 530–4.пмид:25215929
- 6. Лэдд Д.Р., Робертс С.Г., Дедиу Д. Корреляционные исследования в типологической и исторической лингвистике. Лингвист Анну Рев. 2015 Февраль;1(1):140804162027000.
- 7. Клепарски Г. Теория и практика исторической семантики: случай среднеанглийских и раннесовременных английских синонимов девушки/молодой женщины. Люблин: Университетское издательство Люблинского католического университета; 1997.
- 8. Дайен И., Крускал Дж. Б., Блэк П. Индоевропейская классификация: лексикостатистический эксперимент.Филадельфия: Американское философское общество; 1992.
- 9.
Инграм JCL. Нейролингвистика: введение в обработку разговорной речи и ее расстройства. Кембридж: Издательство Кембриджского университета; 2007.
 420 с.
420 с. - 10. Мюнте Т.Ф., Виринга Б.М., Вейертс Х., Сенткути А., Мацке М., Йоханнес С. Различия потенциалов мозга для слов открытого и закрытого классов: классовые и частотные эффекты. Нейропсихология. 2001 г., январь; 39 (1): 91–102. пмид:11115658
- 11. Кинг Дж., Кутас М.Кто что делал и когда? Использование ERP на уровне слов и статей для мониторинга использования рабочей памяти при чтении. J Cogn Neurosci. 1995 г., июль; 7 (3): 376–95. пмид:23961867
- 12. Диас М.Т., Маккарти Г. Сравнение мозговой активности, вызванной отдельными содержательными и функциональными словами: исследование неявной обработки текста с помощью МРТ. Мозг Res. 2009 г., 28 июля; 1282: 38–49. пмид:19465009
- 13. Основная команда разработчиков R. R: Язык и среда для статистических вычислений [Интернет].Вена, Австрия: R Foundation for Statistical Computing, Вена, Австрия; 2013. Доступно: http://www.R-project.org
- 14.
Уикхем Х.
 ggplot2: элегантная графика для анализа данных. 1-е изд. 2009. Корр. 3-е издание 2010 года. Нью-Йорк: Спрингер; 2009. 213 с.
ggplot2: элегантная графика для анализа данных. 1-е изд. 2009. Корр. 3-е издание 2010 года. Нью-Йорк: Спрингер; 2009. 213 с. - 15. Байби Дж.Л. Частота использования и организация языка [Интернет]. Оксфорд; Нью-Йорк: Издательство Оксфордского университета; 2007 [цитировано 13 марта 2013 г.]. Доступно: http://site.ebrary.com/id/10194230
- 16.Куперман В., Стадтаген-Гонсалес Х., Брисберт М. Рейтинги возраста усвоения 30 000 английских слов. Методы поведения Res. 2012 г., 12 мая; 44 (4): 978–90. пмид:22581493
- 17. Аллан К., Берридж К. Запрещенные слова: табу и языковая цензура. Кембридж, Великобритания; Нью-Йорк: издательство Кембриджского университета; 2006.
- 18. Зализняк А., Булах М., Ганенков Д., Грунтов И., Майсак Т., Руссо М. Каталог семантических сдвигов как база данных для лексико-семантической типологии.Лингвистика. 2012; (50–3): 633–69.
- 19.
Берридж К. Табу, эвфемизм и политическая корректность.
 В: Браун К., редактор. Энциклопедия языка и лингвистики (второе издание) [Интернет]. Оксфорд: Эльзевир; 2006 [цитировано 12 декабря 2013 г.]. п. 455–62. Доступно: http://www.sciencedirect.com/science/article/pii/B0080448542010920
В: Браун К., редактор. Энциклопедия языка и лингвистики (второе издание) [Интернет]. Оксфорд: Эльзевир; 2006 [цитировано 12 декабря 2013 г.]. п. 455–62. Доступно: http://www.sciencedirect.com/science/article/pii/B0080448542010920 - 20. Хольцкнехт К.А. Табу на слова и его последствия для лингвистических изменений в семье языков Маркхэма. Ланг Лингвист Меланес.1988; (18): 43–69.
- 21. Берридж К. Табуированные слова. В: Браун К., редактор. Энциклопедия языка и лингвистики (второе издание) [Интернет]. Оксфорд: Эльзевир; 2006 [цитировано 12 декабря 2013 г.]. п. 452–5. Доступно: http://www.sciencedirect.com/science/article/pii/B0080448542007781
- 22. Grzega J. Качественное и количественное представление сил лексических изменений в истории английского языка. Ономасиол онлайн. 2004; 5:15–55.
- 23. Пинкер С.Игра имени. Нью-Йорк Таймс. 1994 г., 3 апреля;
- 24.
Осгуд К.Э., Сучи Г.Дж., Танненбаум П.
 Х. Измерение смысла. Урбана: Университет Иллинойса Press; 1957.
Х. Измерение смысла. Урбана: Университет Иллинойса Press; 1957. - 25. Уорринер А.Б., Куперман В., Брисберт М. Нормы валентности, возбуждения и доминирования для 13 915 английских лемм. Методы поведения Res. 2013 г., 13 февраля;
- 26. Пайвио А. Образы и словесные процессы. Холт, Райнхарт и Уинстон; 1971. 620 с.
- 27. Костыль С.Дж., Уоррингтон Е.К.Абстрактные и конкретные понятия имеют структурно разные репрезентативные рамки. Мозг. 2005 г., 3 января; 128 (3): 615–27.
- 28. Мортенссон Ф., Ролл М., Апт П., Хорн М. Моделирование значения слов: нейронные корреляты обработки абстрактных и конкретных существительных. Acta Neurobiol Exp (Warsz). 2011;71(4):455–78.
- 29. Кролл Дж. Ф., Мервес Дж. С. Лексический доступ к конкретным и абстрактным словам. J Exp Psychol Learn Mem Cogn. 1986; 12(1):92–107.
- 30.
Перани Д., Каппа С.Ф., Шнур Т., Теттаманти М., Коллина С., Роза М.
 М. и др.Нейронные корреляты обработки глагола и существительного Исследование ПЭТ. Мозг. 1999 г., 12 января; 122 (12): 2337–44.
М. и др.Нейронные корреляты обработки глагола и существительного Исследование ПЭТ. Мозг. 1999 г., 12 января; 122 (12): 2337–44. - 31. Хиллз Т.Т., Адельман Дж.С. Недавняя эволюция обучаемости в американском английском с 1800 по 2000 год. Познание. 2015 окт.; 143:87–92. пмид:26117487
- 32. Брисберт М., Уорринер А.Б., Куперман В. Оценки конкретности 40 тысяч общеизвестных английских словесных лемм. Методы поведения Res. 2014 г., сен; 46 (3): 904–11. пмид:24142837
- 33. Кортезе М.Дж., Фьюгетт А.Рейтинги изобразительности для 3000 односложных слов. Behav Res Methods Instrum Comput. 2004 г., 1 августа; 36 (3): 384–7. пмид:15641427
- 34. Трауготт Э., Дашер РБ. Закономерность смысловых изменений. Кембридж; Нью-Йорк: издательство Кембриджского университета; 2002.
- 35. Fellbaum C. WordNet электронная лексическая база данных. 2-я печать. Кембриджская Массачусетс: MIT Press; 1999.
- 36.
 Спитцер М. Разум в сети: модели обучения, мышления и действия. Лондон: Книга Брэдфорда; 1999.
Спитцер М. Разум в сети: модели обучения, мышления и действия. Лондон: Книга Брэдфорда; 1999. - 37. Эйчисон Дж. Слова в уме: введение в ментальный лексикон. Блэквелл; 1994. 314 с.
- 38. Виглиокко Г., Винсон Д.П. Семантическое представление. В: Gaskell MG, Altmann GTM, редакторы. Оксфордский справочник по психолингвистике. Оксфорд; Нью-Йорк: Издательство Оксфордского университета; 2007. с. 195–215.
- 39. Кутас М., Федермайер К.Д. Тридцать лет и подсчет: поиск смысла в компоненте N400 потенциала мозга, связанного с событием (ERP).Анну Рев Психол. 2011;62:621–47. пмид:20809790
- 40. Линдберг, Калифорния, издательство Оксфордского университета. Карманный оксфордский американский тезаурус [Интернет]. Нью-Йорк: Издательство Оксфордского университета; 2012 [цитировано 3 февраля 2013 г.]. Доступно: http://www.oxfordreference.com/view/10.1093/acref/9780195301694.001.0001/acref-9780195301694
- 41.
 Уолтер Г. Бонньерс синонимордбок. Стокгольм: Боннье; 2000.
Уолтер Г. Бонньерс синонимордбок. Стокгольм: Боннье; 2000. - 42. Ингеманн Т. Синонимордбог. См.: Гилдендаль; 2011.
- 43.Бабяк М.А. То, что вы видите, может не совпадать с тем, что вы получаете: краткое нетехническое введение в переоснащение в моделях регрессионного типа. Психозом Мед. 2004 г., июнь; 66 (3): 411–21. пмид:15184705
- 44. Canty A, Ripley B. boot: Bootstrap R (S-Plus) Функции. Пакет R версии 1.3–15. 2013.
- 45. Бааен РХ. Анализ лингвистических данных: практическое введение в статистику с использованием Р. Кембридж, Великобритания; Нью-Йорк: издательство Кембриджского университета; 2008. 353 с.
- 46.Gude JA, Mitchell MS, Ausband DE, Sime CA, Bangs EE. Внутренняя проверка прогнозирующих моделей логистической регрессии для принятия решений в управлении дикой природой. Дикий биол. 1 декабря 2009 г .; 15 (4): 352–69.
- 47.
Харрелл Ф.Э. Стратегии регрессионного моделирования с приложениями к линейным моделям, логистической регрессии и анализу выживания [Интернет].
 Нью-Йорк, штат Нью-Йорк: Springer New York; 2001 [цитировано 16 февраля 2015 г.]. Доступно: http://dx.doi.org/10.1007/978-1-4757-3462-1
Нью-Йорк, штат Нью-Йорк: Springer New York; 2001 [цитировано 16 февраля 2015 г.]. Доступно: http://dx.doi.org/10.1007/978-1-4757-3462-1 - 48.Curtin J. lmSupport: Поддержка линейных моделей [Интернет]. 2014. Доступно: http://CRAN.R-project.org/package=lmSupport
NLTK и Python WordNet: поиск синонимов и антонимов с помощью Python
NLTK Wordnet можно использовать для поиска синонимов и антонимов слов . Пакет NLTK Corpus используется для чтения корпуса, чтобы понять лексическую семантику слов в документе. WordNet включает семантические отношения слов и их значений в лексической базе данных.Смысловыми отношениями внутри WordNet являются гиперонимы, синонимы, холонимы, гипонимы, меронимы. NLTK WordNet включает использование синсетов для поиска слов в WordNet с их использованием, определениями и примерами. NLTK WordNet предназначен для поиска представлений между чувствами. Определение типа отношения связано с WordNet с лексической семантикой. Собака может быть млекопитающим, и это можно выразить с помощью предложения типа отношения «IS-A». Таким образом, NLTK Wordnet используется для поиска отношений между словами из документа, обнаружения спама, обнаружения дублирования или характеристик слов в письменном тексте с их POS-тегами.
Собака может быть млекопитающим, и это можно выразить с помощью предложения типа отношения «IS-A». Таким образом, NLTK Wordnet используется для поиска отношений между словами из документа, обнаружения спама, обнаружения дублирования или характеристик слов в письменном тексте с их POS-тегами.
Лемматизация NLTK, выделение корня, токенизация и тегирование POS связаны с NLTK WordNet для обработки естественного языка. Чтобы использовать набор средств естественного языка WordNet с большей эффективностью, для обработки и очистки текста следует использовать синонимов и антонимов , холонимов, гиперонимов и гипонимов, а также всех лексических отношений. В этом учебном пособии NLTK WordNet Python поиск синонимов и антонимов, а также расчет схожести слов будут использоваться с NLTK Corpus Reader для английского языка.
Быстрый пример поиска синонимов и антонимов с помощью NLTK Python можно найти ниже.
определение synonym_antonym_extractor(фраза):
из nltk. corpus импортировать wordnet
синонимы = []
антонимы = []
для син в wordnet.synsets(фраза):
для l в syn.lemmas():
synonyms.append(l.name())
если л.антонимы():
antonyms.append(l.antonyms()[0].name())
печать (набор (синонимы))
печать (набор (антонимы))
synonym_antonym_extractor (фраза = "слово")
ВЫВОД >>>
{'новости', 'пароль', 'Святое_Писание', 'Хорошая_Книга', 'Библия', 'обсуждение', 'новости', 'пароль', 'дать_голос', 'членораздельно', 'Сын', 'слово', ' Священное_Писание», «Книга», «взаимные уступки», «Христианская_Библия», «разум», «Логос», «фраза», «слово_чести», «формулировать», «Писание», «Слово», «девиз» , 'контрзнак', 'Слово_о_Боге'}
установить()
corpus импортировать wordnet
синонимы = []
антонимы = []
для син в wordnet.synsets(фраза):
для l в syn.lemmas():
synonyms.append(l.name())
если л.антонимы():
antonyms.append(l.antonyms()[0].name())
печать (набор (синонимы))
печать (набор (антонимы))
synonym_antonym_extractor (фраза = "слово")
ВЫВОД >>>
{'новости', 'пароль', 'Святое_Писание', 'Хорошая_Книга', 'Библия', 'обсуждение', 'новости', 'пароль', 'дать_голос', 'членораздельно', 'Сын', 'слово', ' Священное_Писание», «Книга», «взаимные уступки», «Христианская_Библия», «разум», «Логос», «фраза», «слово_чести», «формулировать», «Писание», «Слово», «девиз» , 'контрзнак', 'Слово_о_Боге'}
установить()
Пример блока кода поиска синонимов и антонимов с помощью Python NLTK включает создание пользовательской функции «nltk.corpus» и «wordnet» с «syn.lemmas», «syn.antonyms» вместе с циклом for. Фраза «слово» использовалась в качестве примера для поиска синонимов и антонимов NLTK. Согласно WordNet в NLTK.corpus, нет антонима для фразы «слово», но есть синонимы «пароль», «Священное писание», «Хорошая книга», «Библия», «Обсуждение», «Новости», «Условно-досрочное освобождение». Синонимы и антонимы NLTK включают лексические синонимы и контекстуальные синонимы из WordNet.
Согласно WordNet в NLTK.corpus, нет антонима для фразы «слово», но есть синонимы «пароль», «Священное писание», «Хорошая книга», «Библия», «Обсуждение», «Новости», «Условно-досрочное освобождение». Синонимы и антонимы NLTK включают лексические синонимы и контекстуальные синонимы из WordNet.
В этом руководстве по поиску синонимов и антонимов Python и NLTK будет рассмотрено использование NLTK WordNet для лексической семантики, сходства слов и синонимов, антонимов, гиперонимов, гипонимов, глагольных рамок и т. д.
Как найти синонимы слова с помощью NLTK WordNet и Python?
Чтобы найти синонимы слова с помощью NLTK WordNet, необходимо следовать приведенным ниже инструкциям.
- Импорт NLTK.corpus
- Импорт WordNet из NLTK.Corpus
- Создайте список для присвоения значений синонима слова.
- Используйте метод «синсетов».
- используйте свойство «syn.lemmas» для назначения синонимов в список с помощью цикла for.
- Назовите синонимы слова с NLTK WordNet в пределах набора.

Ниже приведен пример нахождения синонима слова через NLTK и Python.
из nltk.corpus импорт WordNet
синонимы = []
для син в wordnet.synsets("любовь"):
для i в syn.lemmas():
synonyms.append(l.name())
печать (набор (синонимы))
ВЫВОД >>>
{'самая дорогая', 'love_life', 'get_it_on', 'roll_in_the_hay', 'lie_with', 'блядь', 'bonk', 'страсть', 'дорогая', 'sleep_together', 'занятия любовью', 'making_love', ' make_love', 'have_sex', 'jazz', 'кровать', 'erotic_love', 'дорогой', 'do_it', 'have_it_away', 'be_intimate', 'fuck', 'have_a_go_at_it', 'sleep_with', 'горб' , 'наслаждайтесь', 'eff', 'have_it_off', 'знайте', 'have_intercourse', 'make_out', 'трах', 'любимый', 'любовь', 'get_laid', 'sexual_love'}
В приведенном выше примере слово «любовь» используется для поиска его синонимов для различных контекстов с NLTK и Python.Синонимы, которые встречаются для слова «любовь», включают «дорогая», «ложь с», «винт», «бонк», «страсть», «милая» и некоторые подтипы, такие как «сексуальная любовь», «эротическая любовь». Слово может быть синонимом другого слова, а косвенно связанные и связанные слова могут быть включены в список синонимов слова с помощью NLTK WordNet. Таким образом, для поиска различных контекстуальных синонимов и родственных фраз для слова можно использовать NLTK. Композиционные соединения и некомпозиционные соединения или синонимы используются поисковыми системами.Для проекта поисковой оптимизации или создания поисковой системы NLTK WordNet и синонимы важны для понимания контекста текстовых данных. Таким образом, из патентов Google можно найти NLTK и WordNet в качестве упомянутой методологии поиска синонимов.
Слово может быть синонимом другого слова, а косвенно связанные и связанные слова могут быть включены в список синонимов слова с помощью NLTK WordNet. Таким образом, для поиска различных контекстуальных синонимов и родственных фраз для слова можно использовать NLTK. Композиционные соединения и некомпозиционные соединения или синонимы используются поисковыми системами.Для проекта поисковой оптимизации или создания поисковой системы NLTK WordNet и синонимы важны для понимания контекста текстовых данных. Таким образом, из патентов Google можно найти NLTK и WordNet в качестве упомянутой методологии поиска синонимов.
Как найти антонимы слова с помощью NLTK WordNet и Python?
Чтобы найти антонимы слова с помощью NLTK WordNet и Python, необходимо выполнить следующие инструкции.
- Импорт НЛТК.corpus
- Импорт WordNet из NLTK.Corpus
- Создайте список для присвоения синонимических значений слову.
- Используйте метод «синсетов».
- используйте свойство «syn.
 lemmas» для назначения синонимов в список с помощью цикла for.
lemmas» для назначения синонимов в список с помощью цикла for. - Используйте метод «antonyms()» со свойством «name» для вызова антонима фразы.
- Назовите антонимы слова с помощью NLTK WordNet в наборе.
из nltk.corpus import wordnet
антонимы = []
для син в wordnet.синсеты ("любовь"):
для i в syn.lemmas():
если i.antonyms():
antonyms.append(i.antonyms()[0].name())
печать (набор (антонимы))
ВЫВОД >>>
{'ненависть'}
Антоним слова «любовь» был найден как «ненависть» с помощью примера кода поиска антонима NLTK. Поиск синонимов и антонимов в предложениях путем токенизации слов в предложении полезен, чтобы увидеть возможные контекстуальные связи для понимания содержания с помощью НЛП. Таким образом, создание пользовательской функции для поиска синонимов в тексте с помощью Python полезно.Следующий раздел учебника NLTK по поиску синонимов и антонимов Python с WordNet будет посвящен созданию пользовательских функций.
Как использовать пользовательскую функцию Python для поиска синонимов и антонимов с помощью NLTK WordNet?
Чтобы использовать пользовательскую функцию Python для поиска синонимов и антонимов с помощью NLTK, следуйте приведенным ниже инструкциям.
- Создайте пользовательскую функцию с помощью встроенной в Python команды «def».
- Используйте текст для поиска синонимов и антонимов в качестве аргумента пользовательской функции поиска синонимов и антонимов Python.
- Импортируйте «word_tokenize» из «nltk.tokenize».
- Импортировать «wordnet» из «nltk.corpus».
- Импортировать «дефолтдикт» из «коллекций».
- Импорт «pprint» для красивой печати антонимов и синонимов.
- Маркировать слова в предложении для поиска синонимов и антонимов с помощью NLTK.
- Создайте списки антонимов и синонимов с помощью «defaultdict(list)».
- Используйте цикл for с токенами токенизированного предложения с NLTK для поиска синонимов и антонимов.

- Используйте цикл for с «синсетами» для поиска синонимов и антонимов.
- Используйте оператор «если», чтобы проверить, существует ли антоним слова.
- Используйте «pprint.pformat» и «dict», чтобы сделать список синонимов и антонимов доступным для записи в файл txt.
- Добавить все синонимы и антонимы для каждого слова в предложении с созданными списками синонимов и антонимов defaultdict.
- Открыть новый файл как txt.
- Распечатать все синонимы и антонимы в текстовый файл.
- Закройте открытый и созданный текстовый файл.
Пример использования WordNet NLTK для поиска синонимов и антонимов в примерном предложении можно найти ниже.
определение text_parser_synonym_antonym_finder (текст: строка):
из nltk.tokenize импортировать word_tokenize
из nltk.corpus импортировать wordnet
из коллекций импортировать defaultdict
импорт pprint
токены = word_tokenize (текст)
синонимы = defaultdict (список)
антонимы = defaultdict (список)
для токена в токенах:
для син в wordnet. синсеты (токен):
для i в syn.lemmas():
#synonyms.append(i.name())
#print(f'{token} синонимы: {i.name()}')
синонимы[токен].append(i.name())
если i.antonyms():
#antonyms.append(i.antonyms()[0].name())
#print(f'{token} антонимы: {i.antonyms()[0].name()}')
антонимы[токен].append(i.antonyms()[0].name())
pprint.pprint (dict (синонимы))
ппринт.pprint (дикт (синонимы))
synonym_output = pprint.pformat((dict(синонимы)))
antonyms_output = pprint.pformat((dict(антонимы)))
с open(str(text[:5]) + ".txt", "a") как f:
f.write("Начало синонимов слов из предложений: " + synonym_output + "\n")
f.write("Начало антонимов слов из предложений: " + antonyms_output + "\n")
е.закрыть()
text_parser_synonym_antonym_finder(text="WordNet — это лексическая база данных, используемая крупной поисковой системой.
синсеты (токен):
для i в syn.lemmas():
#synonyms.append(i.name())
#print(f'{token} синонимы: {i.name()}')
синонимы[токен].append(i.name())
если i.antonyms():
#antonyms.append(i.antonyms()[0].name())
#print(f'{token} антонимы: {i.antonyms()[0].name()}')
антонимы[токен].append(i.antonyms()[0].name())
pprint.pprint (dict (синонимы))
ппринт.pprint (дикт (синонимы))
synonym_output = pprint.pformat((dict(синонимы)))
antonyms_output = pprint.pformat((dict(антонимы)))
с open(str(text[:5]) + ".txt", "a") как f:
f.write("Начало синонимов слов из предложений: " + synonym_output + "\n")
f.write("Начало антонимов слов из предложений: " + antonyms_output + "\n")
е.закрыть()
text_parser_synonym_antonym_finder(text="WordNet — это лексическая база данных, используемая крупной поисковой системой. Из WordNet можно рассчитать информацию о данном слове или фразе, например")
ВЫВОД >>>
Начало синонимов слов из предложений: {'WordNet': ['wordnet',
'Ворднет',
'Принстон_WordNet',
'воркнет',
'Ворднет',
«Принстон_WordNet»],
'a': ['ангстрем',
'ангстрем_единица',
«А»,
'витамин_А',
'антиофтальмический_фактор',
аксерофтол,
«А»,
'дезоксиаденозин_монофосфат',
«А»,
аденин,
«А»,
'ампер',
'усилитель',
«А»,
«А»,
а,
«А»,
'введите',
'группа_А',
'ангстрем',
'ангстрем_единица',
«А»,
'витамин_А',
'антиофтальмический_фактор',
аксерофтол,
«А»,
'дезоксиаденозин_монофосфат',
«А»,
аденин,
«А»,
'ампер',
'усилитель',
«А»,
«А»,
а,
«А»,
'введите',
'группа_А',
'ангстрем',
'ангстрем_единица',
«А»,
'витамин_А',
'антиофтальмический_фактор',
аксерофтол,
«А»,
'дезоксиаденозин_монофосфат',
«А»,
аденин,
«А»,
'ампер',
'усилитель',
«А»,
«А»,
а,
«А»,
'введите',
'группа_А'],
'о': ['о',
'в движении',
'примерно',
'о',
'рядом с',
'just_about',
'немного',
'грубо',
'более менее',
'около',
'или так',
'о',
'около',
'о',
'около',
'о',
'около',
'о',
'около',
'о',
'о',
'почти',
'наиболее',
'Около',
'около',
'близко',
'практически',
'почти'],
'как': ['мышьяк',
'Так как',
'атомный_номер_33',
'Американское Самоа',
'Восточное_Самоа',
'ТАК КАК',
'ангстрем',
'ангстрем_единица',
«А»,
'витамин_А',
'антиофтальмический_фактор',
аксерофтол,
«А»,
'дезоксиаденозин_монофосфат',
«А»,
аденин,
«А»,
'ампер',
'усилитель',
«А»,
«А»,
а,
«А»,
'введите',
'группа_А',
'в равной степени',
'так как',
'каждый кусочек'],
'быть': ['бериллий',
'Быть',
'глюциний',
'атомный_номер_4',
'быть',
'быть',
'быть',
'существует',
'быть',
'быть',
'равный',
'быть',
'составлять',
'представлять',
'макияж, мириться',
'включать',
'быть',
'быть',
'следить',
'воплощать',
'быть',
'олицетворять',
'быть',
'быть',
'жить',
'быть',
'Стоимость',
'быть'],
'был': ['быть',
'быть',
'быть',
'существует',
'быть',
'быть',
'равный',
'быть',
'составлять',
'представлять',
'макияж, мириться',
'включать',
'быть',
'быть',
'следить',
'воплощать',
'быть',
'олицетворять',
'быть',
'быть',
'жить',
'быть',
'Стоимость',
'быть'],
'by': ['by', 'мимо', 'в стороне', 'мимо', 'прочь'],
'рассчитано': ['рассчитано',
'шифр',
'шифр',
'вычислить',
'тренировка',
'считать',
'фигура',
'рассчитать',
'оценивать',
'считать',
'рассчитывать на',
'фигура',
'прогноз',
'учетная запись',
'рассчитать',
'прогноз',
'рассчитать',
'рассчитать',
'цель',
'непосредственный',
'считать',
'держать пари',
'зависеть',
'Смотреть',
'рассчитать',
'считать',
'преднамеренный',
'расчетный',
«измерено»],
'может может',
'банка',
'консервная банка',
'могу',
'канфул',
'могу',
'can_buoy',
'ягодицы',
'нейтс',
'жопа',
'задница',
'зад',
'задница',
'булочки',
'могу',
«фундамент»,
'задняя часть',
'зад_конец',
'кейстер',
'задний',
'прат',
'задний',
'задняя часть',
'огузок',
'суровый',
'сиденье',
'хвостик',
'хвост_конец',
'туши',
'туш',
'Нижний',
'позади',
'зад',
'Фанни',
'жопа',
'туалет',
'могу',
'комод',
'дерьмо',
'горшок',
'горшок',
'табурет',
'трон',
'туалет',
'туалет',
'лав',
'могу',
'Джон',
'тайный',
'ванная',
'могу',
'банка',
'смириться',
'сместить',
'Пожар',
'Обращать внимание',
'могу',
'увольнять',
'дай_топор',
'посылать',
'мешок',
'вытеснять',
'дай_мешок',
'завершить'],
'база данных': ['база данных'],
'двигатель': ['двигатель',
'двигатель',
'локомотив',
'двигатель',
'локомотив_двигатель',
'железнодорожный_локомотив',
'двигатель'],
'данный': ['данный',
'презумпция',
«предварительное условие»,
'дать',
'урожай',
'дать',
'предоставлять',
'дать',
'дать',
'дать',
'платить',
'держать',
'бросать',
'имеют',
'сделать',
'дать',
'дать',
'бросать',
'дать',
'подарок',
'настоящее время',
'дать',
'урожай',
'дать',
'платить',
'посвящать',
'оказывать',
'урожай',
'вернуть',
'дать',
'генерировать',
'передавать',
'покинуть',
'дать',
'передай',
'учреждать',
'дать',
'дать',
'дать',
'жертва',
'дать',
'проходить',
'рука',
'достигать',
'передай',
'оборот',
'дать',
'дать',
'посвятить',
'посвятить',
'совершить',
'посвящать',
'дать',
'дать',
'применять',
'дать',
'оказывать',
'грант',
'дать',
'переместить_овер',
'Уступи дорогу',
'дать',
'облегчить',
'урожай',
'подача',
'дать',
'способствовать',
'дать',
'вмешаться',
'ворваться',
'крах',
'падение',
'пещера_в',
'дать',
'Уступи дорогу',
'перерыв',
'основатель',
'дать',
'дать',
'дать',
'предоставлять',
'открытым',
'дать',
'дать',
'дать',
'дать',
'урожай',
'дать',
'дать',
'дать',
'дать',
'дать',
'дать',
'дать',
'дать',
'дать',
'дать',
'дать',
'дано',
'предоставляется',
'подходящий',
«распоряжение»,
'дано',
«мыслящий»,
'уход'],
'есть': ['час_угол',
'ХА',
'имеют',
'иметь',
'держать',
'имеют',
'характерная черта',
'опыт',
'получать',
'имеют',
'получать',
'собственный',
'имеют',
'владеть',
'получать',
'позволять',
'имеют',
'потреблять',
'глотать',
'принимать',
'брать',
'имеют',
'имеют',
'держать',
'бросать',
'имеют',
'сделать',
'дать',
'имеют',
'имеют',
'имеют',
'опыт',
'имеют',
'вызывать',
'стимулировать',
'причина',
'имеют',
'получать',
'сделать',
'принимать',
'брать',
'имеют',
'получать',
'имеют',
'страдать',
'поддерживать',
'имеют',
'получать',
'имеют',
'получать',
'сделать',
'рожать',
'доставлять',
'медведь',
'рождение',
'имеют',
'брать',
'имеют'],
'информация': ['информация',
'Информация',
'Информация',
'Информация',
'данные',
'Информация',
'Информация',
'выборочная_информация',
'энтропия'],
'есть': ['быть',
'быть',
'быть',
'существует',
'быть',
'быть',
'равный',
'быть',
'составлять',
'представлять',
'макияж, мириться',
'включать',
'быть',
'быть',
'следить',
'воплощать',
'быть',
'олицетворять',
'быть',
'быть',
'жить',
'быть',
'Стоимость',
'быть'],
'лексический': ['лексический', 'лексический'],
«основной»: [«основной»,
'Главный',
'Джон_Майор',
'Джон_Р.
Из WordNet можно рассчитать информацию о данном слове или фразе, например")
ВЫВОД >>>
Начало синонимов слов из предложений: {'WordNet': ['wordnet',
'Ворднет',
'Принстон_WordNet',
'воркнет',
'Ворднет',
«Принстон_WordNet»],
'a': ['ангстрем',
'ангстрем_единица',
«А»,
'витамин_А',
'антиофтальмический_фактор',
аксерофтол,
«А»,
'дезоксиаденозин_монофосфат',
«А»,
аденин,
«А»,
'ампер',
'усилитель',
«А»,
«А»,
а,
«А»,
'введите',
'группа_А',
'ангстрем',
'ангстрем_единица',
«А»,
'витамин_А',
'антиофтальмический_фактор',
аксерофтол,
«А»,
'дезоксиаденозин_монофосфат',
«А»,
аденин,
«А»,
'ампер',
'усилитель',
«А»,
«А»,
а,
«А»,
'введите',
'группа_А',
'ангстрем',
'ангстрем_единица',
«А»,
'витамин_А',
'антиофтальмический_фактор',
аксерофтол,
«А»,
'дезоксиаденозин_монофосфат',
«А»,
аденин,
«А»,
'ампер',
'усилитель',
«А»,
«А»,
а,
«А»,
'введите',
'группа_А'],
'о': ['о',
'в движении',
'примерно',
'о',
'рядом с',
'just_about',
'немного',
'грубо',
'более менее',
'около',
'или так',
'о',
'около',
'о',
'около',
'о',
'около',
'о',
'около',
'о',
'о',
'почти',
'наиболее',
'Около',
'около',
'близко',
'практически',
'почти'],
'как': ['мышьяк',
'Так как',
'атомный_номер_33',
'Американское Самоа',
'Восточное_Самоа',
'ТАК КАК',
'ангстрем',
'ангстрем_единица',
«А»,
'витамин_А',
'антиофтальмический_фактор',
аксерофтол,
«А»,
'дезоксиаденозин_монофосфат',
«А»,
аденин,
«А»,
'ампер',
'усилитель',
«А»,
«А»,
а,
«А»,
'введите',
'группа_А',
'в равной степени',
'так как',
'каждый кусочек'],
'быть': ['бериллий',
'Быть',
'глюциний',
'атомный_номер_4',
'быть',
'быть',
'быть',
'существует',
'быть',
'быть',
'равный',
'быть',
'составлять',
'представлять',
'макияж, мириться',
'включать',
'быть',
'быть',
'следить',
'воплощать',
'быть',
'олицетворять',
'быть',
'быть',
'жить',
'быть',
'Стоимость',
'быть'],
'был': ['быть',
'быть',
'быть',
'существует',
'быть',
'быть',
'равный',
'быть',
'составлять',
'представлять',
'макияж, мириться',
'включать',
'быть',
'быть',
'следить',
'воплощать',
'быть',
'олицетворять',
'быть',
'быть',
'жить',
'быть',
'Стоимость',
'быть'],
'by': ['by', 'мимо', 'в стороне', 'мимо', 'прочь'],
'рассчитано': ['рассчитано',
'шифр',
'шифр',
'вычислить',
'тренировка',
'считать',
'фигура',
'рассчитать',
'оценивать',
'считать',
'рассчитывать на',
'фигура',
'прогноз',
'учетная запись',
'рассчитать',
'прогноз',
'рассчитать',
'рассчитать',
'цель',
'непосредственный',
'считать',
'держать пари',
'зависеть',
'Смотреть',
'рассчитать',
'считать',
'преднамеренный',
'расчетный',
«измерено»],
'может может',
'банка',
'консервная банка',
'могу',
'канфул',
'могу',
'can_buoy',
'ягодицы',
'нейтс',
'жопа',
'задница',
'зад',
'задница',
'булочки',
'могу',
«фундамент»,
'задняя часть',
'зад_конец',
'кейстер',
'задний',
'прат',
'задний',
'задняя часть',
'огузок',
'суровый',
'сиденье',
'хвостик',
'хвост_конец',
'туши',
'туш',
'Нижний',
'позади',
'зад',
'Фанни',
'жопа',
'туалет',
'могу',
'комод',
'дерьмо',
'горшок',
'горшок',
'табурет',
'трон',
'туалет',
'туалет',
'лав',
'могу',
'Джон',
'тайный',
'ванная',
'могу',
'банка',
'смириться',
'сместить',
'Пожар',
'Обращать внимание',
'могу',
'увольнять',
'дай_топор',
'посылать',
'мешок',
'вытеснять',
'дай_мешок',
'завершить'],
'база данных': ['база данных'],
'двигатель': ['двигатель',
'двигатель',
'локомотив',
'двигатель',
'локомотив_двигатель',
'железнодорожный_локомотив',
'двигатель'],
'данный': ['данный',
'презумпция',
«предварительное условие»,
'дать',
'урожай',
'дать',
'предоставлять',
'дать',
'дать',
'дать',
'платить',
'держать',
'бросать',
'имеют',
'сделать',
'дать',
'дать',
'бросать',
'дать',
'подарок',
'настоящее время',
'дать',
'урожай',
'дать',
'платить',
'посвящать',
'оказывать',
'урожай',
'вернуть',
'дать',
'генерировать',
'передавать',
'покинуть',
'дать',
'передай',
'учреждать',
'дать',
'дать',
'дать',
'жертва',
'дать',
'проходить',
'рука',
'достигать',
'передай',
'оборот',
'дать',
'дать',
'посвятить',
'посвятить',
'совершить',
'посвящать',
'дать',
'дать',
'применять',
'дать',
'оказывать',
'грант',
'дать',
'переместить_овер',
'Уступи дорогу',
'дать',
'облегчить',
'урожай',
'подача',
'дать',
'способствовать',
'дать',
'вмешаться',
'ворваться',
'крах',
'падение',
'пещера_в',
'дать',
'Уступи дорогу',
'перерыв',
'основатель',
'дать',
'дать',
'дать',
'предоставлять',
'открытым',
'дать',
'дать',
'дать',
'дать',
'урожай',
'дать',
'дать',
'дать',
'дать',
'дать',
'дать',
'дать',
'дать',
'дать',
'дать',
'дать',
'дано',
'предоставляется',
'подходящий',
«распоряжение»,
'дано',
«мыслящий»,
'уход'],
'есть': ['час_угол',
'ХА',
'имеют',
'иметь',
'держать',
'имеют',
'характерная черта',
'опыт',
'получать',
'имеют',
'получать',
'собственный',
'имеют',
'владеть',
'получать',
'позволять',
'имеют',
'потреблять',
'глотать',
'принимать',
'брать',
'имеют',
'имеют',
'держать',
'бросать',
'имеют',
'сделать',
'дать',
'имеют',
'имеют',
'имеют',
'опыт',
'имеют',
'вызывать',
'стимулировать',
'причина',
'имеют',
'получать',
'сделать',
'принимать',
'брать',
'имеют',
'получать',
'имеют',
'страдать',
'поддерживать',
'имеют',
'получать',
'имеют',
'получать',
'сделать',
'рожать',
'доставлять',
'медведь',
'рождение',
'имеют',
'брать',
'имеют'],
'информация': ['информация',
'Информация',
'Информация',
'Информация',
'данные',
'Информация',
'Информация',
'выборочная_информация',
'энтропия'],
'есть': ['быть',
'быть',
'быть',
'существует',
'быть',
'быть',
'равный',
'быть',
'составлять',
'представлять',
'макияж, мириться',
'включать',
'быть',
'быть',
'следить',
'воплощать',
'быть',
'олицетворять',
'быть',
'быть',
'жить',
'быть',
'Стоимость',
'быть'],
'лексический': ['лексический', 'лексический'],
«основной»: [«основной»,
'Главный',
'Джон_Майор',
'Джон_Р. _Главный',
'Джон_Рой_Майор',
'главный',
'главный',
'главный',
'главный',
'главный',
'главный',
'главный',
'главный',
'главный',
'главный',
'главный'],
'или': ['Орегон',
'Бобер_Состояние',
'ИЛИ',
'операционная',
'ИЛИ',
'операционная',
'операционная',
'операция'],
'фраза': ['фраза',
'фраза',
'музыкальная_фраза',
'идиома',
'идиоматическое_выражение',
'фразовая_идиома',
'установить_фразу',
'фраза',
'фраза',
'дай_голос',
'формулировать',
'слово',
'фраза',
'членораздельный',
'фраза'],
'поиск': ['поиск',
'охота',
'охота',
'поиск',
'поиск',
'Погляди',
'поиск',
'поиск',
'поиск',
'стремиться',
'искать',
'поиск',
'Смотреть',
'исследование',
'поиск',
'проводить исследования',
'поиск'],
'такой': ['такой', 'такой'],
'используется': ['используется',
'использовать',
'использовать',
'применять',
'нанять',
'использовать',
'привыкнуть',
'использовать',
'расходовать',
'использовать',
'упражняться',
'применять',
'использовать',
'использовать',
'использовал',
«эксплуатировался»,
«неправильное использование»,
'наложенный',
'использовал',
«жертва»,
«жертва»,
'подержанный',
'использовал'],
'слово': ['слово',
'слово',
'Новости',
'интеллект',
'новости',
'слово',
'слово',
'обсуждение',
'давать и брать',
'слово',
'условно-досрочное освобождение',
'слово',
'слово_чести',
'слово',
'Сын',
'Слово',
'Логос',
'пароль',
'пароль',
'слово',
'условно-досрочное освобождение',
'контрподпись',
'Библия',
'Христианская_Библия',
'Книга',
'Хорошая книга',
'Священное_Писание',
'Священное_Писание',
'Писание',
'Слово Божие',
'Слово',
'дай_голос',
'формулировать',
'слово',
'фраза',
'членораздельный']}
Начало антонимов слов из предложений: {'быть': ['отличаться'],
'было': ['отличается'],
'может': ['нанять'],
'дано': ['взять', 'голодать'],
'имеет': ['отсутствует', 'воздерживаюсь', 'отказываюсь'],
'есть': ['отличаться'],
«основной»: [«незначительный», «незначительный», «незначительный», «незначительный», «незначительный», «незначительный», «незначительный»],
'используется': ['неправильно использовано']}
_Главный',
'Джон_Рой_Майор',
'главный',
'главный',
'главный',
'главный',
'главный',
'главный',
'главный',
'главный',
'главный',
'главный',
'главный'],
'или': ['Орегон',
'Бобер_Состояние',
'ИЛИ',
'операционная',
'ИЛИ',
'операционная',
'операционная',
'операция'],
'фраза': ['фраза',
'фраза',
'музыкальная_фраза',
'идиома',
'идиоматическое_выражение',
'фразовая_идиома',
'установить_фразу',
'фраза',
'фраза',
'дай_голос',
'формулировать',
'слово',
'фраза',
'членораздельный',
'фраза'],
'поиск': ['поиск',
'охота',
'охота',
'поиск',
'поиск',
'Погляди',
'поиск',
'поиск',
'поиск',
'стремиться',
'искать',
'поиск',
'Смотреть',
'исследование',
'поиск',
'проводить исследования',
'поиск'],
'такой': ['такой', 'такой'],
'используется': ['используется',
'использовать',
'использовать',
'применять',
'нанять',
'использовать',
'привыкнуть',
'использовать',
'расходовать',
'использовать',
'упражняться',
'применять',
'использовать',
'использовать',
'использовал',
«эксплуатировался»,
«неправильное использование»,
'наложенный',
'использовал',
«жертва»,
«жертва»,
'подержанный',
'использовал'],
'слово': ['слово',
'слово',
'Новости',
'интеллект',
'новости',
'слово',
'слово',
'обсуждение',
'давать и брать',
'слово',
'условно-досрочное освобождение',
'слово',
'слово_чести',
'слово',
'Сын',
'Слово',
'Логос',
'пароль',
'пароль',
'слово',
'условно-досрочное освобождение',
'контрподпись',
'Библия',
'Христианская_Библия',
'Книга',
'Хорошая книга',
'Священное_Писание',
'Священное_Писание',
'Писание',
'Слово Божие',
'Слово',
'дай_голос',
'формулировать',
'слово',
'фраза',
'членораздельный']}
Начало антонимов слов из предложений: {'быть': ['отличаться'],
'было': ['отличается'],
'может': ['нанять'],
'дано': ['взять', 'голодать'],
'имеет': ['отсутствует', 'воздерживаюсь', 'отказываюсь'],
'есть': ['отличаться'],
«основной»: [«незначительный», «незначительный», «незначительный», «незначительный», «незначительный», «незначительный», «незначительный»],
'используется': ['неправильно использовано']}
В приведенном выше примере предложение использовалось в качестве примера для поиска синонимов и антонимов с помощью пользовательской функции Python, которая называется «text_parser_synonym_antonym_finder». Ниже вы можете увидеть вывод «txt» экстрактора синонимов и антонимов из предложения.
Ниже вы можете увидеть вывод «txt» экстрактора синонимов и антонимов из предложения.
Для поиска и извлечения синонимов и антонимов из текста мы создали новый файл «.txt» с именем первого слова предложения. Важно отметить, что в NLTK WordNet и Python слово может иметь несколько синонимов с одним и тем же словом, потому что для каждого слова в списке антонимов и синонимов существуют разные теги POS.
Как использовать теги POS для поиска синонимов и антонимов с помощью NLTK WordNet?
Чтобы использовать теги POS для поиска синонимов и антонимов с помощью NLTK WordNet, атрибут «pos» должен использоваться с WordNet NLTK.Ниже приведен пример использования тегов POS для поиска антонима и синонима с NLTK WordNet.
print("ГЛАГОЛ любви: ", wordnet.synsets("love", pos = wordnet.VERB))
print("ПРИЛОЖЕНИЕ любви: ", wordnet.synsets("любовь", pos = wordnet.ADJ))
print("СУЩЕСТВИТЕЛЬНОЕ любви: ", wordnet.synsets("любовь", pos = wordnet.СУЩЕСТВЕННОЕ))
ВЫВОД >>>
ГЛАГОЛ любви: [Synset('love. v.01'), Synset('love.v.02'), Synset('love.v.03'), Synset('sleep_together.v.01')]
ПРИЛАГАТЕЛЬНОЕ любви: []
СУЩЕСТВИТЕЛЬНОЕ любви: [Synset('любовь.n.01'), Synset('love.n.02'), Synset('любимый.n.01'), Synset('love.n.04'), Synset('love.n.05'), Synset('sexual_love.n.02')]
v.01'), Synset('love.v.02'), Synset('love.v.03'), Synset('sleep_together.v.01')]
ПРИЛАГАТЕЛЬНОЕ любви: []
СУЩЕСТВИТЕЛЬНОЕ любви: [Synset('любовь.n.01'), Synset('love.n.02'), Synset('любимый.n.01'), Synset('love.n.04'), Synset('love.n.05'), Synset('sexual_love.n.02')]
Маркировка POS для синонимов и антонимов с помощью NLTK WordNet показывает разные синсеты (кольца синонимов) для разных синонимов и антонимов слова в зависимости от его контекста. Например, «love.v.01» и «love.v.02» не совпадают друг с другом с точки зрения контекста. Чтобы увидеть разницу слова с точки зрения его синонимического значения и контекста, можно использовать метод «определения» NLTK с тегами POS.Чтобы узнать больше о тегах NLTK POS, ознакомьтесь с соответствующим руководством и учебным пособием.
Как найти определение слова-синонима с помощью NLTK WordNet?
Чтобы найти определение синонима Word с помощью NLTK WordNet, поняв его контекст, следует использовать метод «wordnet. synset(«пример слова», pos = wordnet.POS TAG).definition()». Чтобы увидеть два разных значения одного и того же слова в качестве синонимов, слово «любовь» будет использоваться в качестве примера ниже.
synset(«пример слова», pos = wordnet.POS TAG).definition()». Чтобы увидеть два разных значения одного и того же слова в качестве синонимов, слово «любовь» будет использоваться в качестве примера ниже.
wordnet.synset("любовь.v.01").определение()
ВЫВОД >>>
'испытывать большую привязанность или симпатию к'
Приведенный выше пример определения синонима слова с помощью NLTK WordNet демонстрирует первый пример глагола «любить» как «иметь большую привязанность или симпатию к». В приведенном ниже примере показано второе определение глагола «любовь».
wordnet.synset("love.v.02").definition()
ВЫВОД >>>
'получить удовольствие'
Второй пример поиска значения слова с помощью NLTK WordNet можно найти выше.Второе значение слова «любовь» — «получать удовольствие от». Таким образом, даже если синоним слова имеет те же «строки», что и «фраза», все равно значение может быть другим. Таким образом, у слова может быть несколько синонимов с одинаковой формой, но разными значениями. NLTK WordNet можно найти, найдя различные контексты, значения синонимов с помощью тегов POS с помощью NLTK и поиска определения слова. Чтобы улучшить контекстуальное понимание предложения с NLTK, можно назвать примеры словоупотребления.Поиск определения слова с помощью Python имеет другие методы, такие как использование PyDictionary, но NLTK WordNet предоставляет другие преимущества, такие как поиск примеров предложений для слов или поиск различных контекстов слова с его антонимами и синонимами.
NLTK WordNet можно найти, найдя различные контексты, значения синонимов с помощью тегов POS с помощью NLTK и поиска определения слова. Чтобы улучшить контекстуальное понимание предложения с NLTK, можно назвать примеры словоупотребления.Поиск определения слова с помощью Python имеет другие методы, такие как использование PyDictionary, но NLTK WordNet предоставляет другие преимущества, такие как поиск примеров предложений для слов или поиск различных контекстов слова с его антонимами и синонимами.
Как найти примеры предложений для слов в NLTK WordNet?
Чтобы найти примеры предложений с помощью NLTK WordNet, используется метод «wordnet.synset.examples()». Пример извлечения примера предложения с помощью NLTK WordNet можно найти ниже.
для i в wordnet.synset("love.v.01").examples():
печать (я)
ВЫВОД >>>
я люблю французскую кухню
Она любит своего босса и много работает для него
В приведенном выше примере первое существительное, означающее слово «любовь», используется с методом «wordnet. synset().examples()». Предложения «Я люблю французскую еду» и «Она любит своего босса и усердно работает для него» являются примерами предложений, в которых слово «любовь» используется в определенном значении.
synset().examples()». Предложения «Я люблю французскую еду» и «Она любит своего босса и усердно работает для него» являются примерами предложений, в которых слово «любовь» используется в определенном значении.
для i в wordnet.synset("love.v.01").examples():
печать (я)
ВЫВОД >>>
Я люблю готовить
Первое значение «любви» как «глагола» используется для примера, как указано выше. Предложение «Я люблю готовить» возвращено NLTK WordNet в качестве примера первого значения глагола «любить». Метод «примеры ()» NLTK WordNet полезен для просмотра точного контекста определенного слова и его тега POS с его числовым значением версии.
Как одновременно извлечь синонимы и их определения с помощью NLTK WordNet?
Чтобы извлечь синонимы и их определения с помощью NLTK WordNet, файл «wordnet.synset» и метод «lemmas()» с методом «definition()». Приведенные ниже инструкции следует выполнять для одновременного извлечения синонимов и их определений с помощью NLTK WordNet.
- Используйте «wordnet.synset()» для таких слов, как «любовь» или «фраза».
- Возьмите леммы определенного кольца синонимов с помощью метода «lemmas()».
- Одновременно вывести методы «lemma.name()» и «definition()».
Ниже вы можете найти пример вывода.
для i в wordnet.synsets("любовь"):
для леммы в i.lemmas():
print("Синоним слова: " + lemma.name(), "| Определение синонима: " + i.definition())
ВЫВОД >>>
Синоним слова: любовь | Определение синонима: сильная положительная эмоция уважения и привязанности.
Синоним слова: любовь | Определение синонима: любой объект теплой привязанности или преданности.
Синоним слова: страсть | Определение синонима: любой объект теплой привязанности или преданности.
Синоним слова: любимый | Определение синонима: любимый человек; используется как выражение нежности
Синоним слова: дорогая | Определение синонима: любимый человек; используется как выражение нежности
Синоним слова: самый дорогой | Определение синонима: любимый человек; используется как выражение нежности
Синоним слова: мед | Определение синонима: любимый человек; используется как выражение нежности
Синоним слова: любовь | Определение синонима: любимый человек; используется как выражение нежности
Синоним слова: любовь | Определение синонима: глубокое чувство сексуального желания и влечения. Синоним слова: sexy_love | Определение синонима: глубокое чувство сексуального желания и влечения.
Синоним слова: erotic_love | Определение синонима: глубокое чувство сексуального желания и влечения.
Синоним слова: любовь | Определение синонима: нулевой счет в теннисе или сквоше.
Синоним слова: sexy_love | Определение синонима: сексуальные действия (часто включая половые сношения) между двумя людьми.
Синоним слова: занятие любовью | Определение синонима: сексуальные действия (часто включая половые сношения) между двумя людьми.
Синоним слова: Making_love | Определение синонима: сексуальные действия (часто включая половые сношения) между двумя людьми.
Синоним слова: любовь | Определение синонима: сексуальные действия (часто включая половые сношения) между двумя людьми.
Синоним слова: love_life | Определение синонима: сексуальные действия (часто включая половые сношения) между двумя людьми.
Синоним слова: любовь | Определение синонима: иметь большую привязанность или симпатию к
Синоним слова: любовь | Определение синонима: получать удовольствие от
Синоним слова: наслаждаться | Определение синонима: получать удовольствие от
Синоним слова: любовь | Определение синонима: быть влюбленным или влюбленным в
Синоним слова: спать_вместе | Определение синонима: вступать в половую связь с
Синоним слова: roll_in_the_hay | Определение синонима: вступать в половую связь с
Синоним слова: любовь | Определение синонима: вступать в половую связь с
Синоним слова: make_out | Определение синонима: вступать в половую связь с
Синоним слова: make_love | Определение синонима: вступать в половую связь с
Синоним слова: sleep_with | Определение синонима: вступать в половую связь с
Синоним слова: get_laid | Определение синонима: вступать в половую связь с
Синоним слова: have_sex | Определение синонима: вступать в половую связь с
Синоним слова: знать | Определение синонима: вступать в половую связь с
Синоним слова: do_it | Определение синонима: вступать в половую связь с
Синоним слова: be_intimate | Определение синонима: вступать в половую связь с
Синоним слова: have_intercourse | Определение синонима: вступать в половую связь с
Синоним слова: have_it_away | Определение синонима: вступать в половую связь с
Синоним слова: have_it_off | Определение синонима: вступать в половую связь с
Синоним слова: винт | Определение синонима: вступать в половую связь с
Синоним слова: ебать | Определение синонима: вступать в половую связь с
Синоним слова: джаз | Определение синонима: вступать в половую связь с
Синоним слова: эфф | Определение синонима: вступать в половую связь с
Синоним слова: горб | Определение синонима: вступать в половую связь с
Синоним слова: ложь_с | Определение синонима: вступать в половую связь с
Синоним слова: кровать | Определение синонима: вступать в половую связь с
Синоним слова: have_a_go_at_it | Определение синонима: вступать в половую связь с
Синоним слова: бах | Определение синонима: вступать в половую связь с
Синоним слова: get_it_on | Определение синонима: вступать в половую связь с
Синоним слова: бонк | Определение синонима: вступать в половую связь с
Синоним слова: sexy_love | Определение синонима: глубокое чувство сексуального желания и влечения.
Синоним слова: erotic_love | Определение синонима: глубокое чувство сексуального желания и влечения.
Синоним слова: любовь | Определение синонима: нулевой счет в теннисе или сквоше.
Синоним слова: sexy_love | Определение синонима: сексуальные действия (часто включая половые сношения) между двумя людьми.
Синоним слова: занятие любовью | Определение синонима: сексуальные действия (часто включая половые сношения) между двумя людьми.
Синоним слова: Making_love | Определение синонима: сексуальные действия (часто включая половые сношения) между двумя людьми.
Синоним слова: любовь | Определение синонима: сексуальные действия (часто включая половые сношения) между двумя людьми.
Синоним слова: love_life | Определение синонима: сексуальные действия (часто включая половые сношения) между двумя людьми.
Синоним слова: любовь | Определение синонима: иметь большую привязанность или симпатию к
Синоним слова: любовь | Определение синонима: получать удовольствие от
Синоним слова: наслаждаться | Определение синонима: получать удовольствие от
Синоним слова: любовь | Определение синонима: быть влюбленным или влюбленным в
Синоним слова: спать_вместе | Определение синонима: вступать в половую связь с
Синоним слова: roll_in_the_hay | Определение синонима: вступать в половую связь с
Синоним слова: любовь | Определение синонима: вступать в половую связь с
Синоним слова: make_out | Определение синонима: вступать в половую связь с
Синоним слова: make_love | Определение синонима: вступать в половую связь с
Синоним слова: sleep_with | Определение синонима: вступать в половую связь с
Синоним слова: get_laid | Определение синонима: вступать в половую связь с
Синоним слова: have_sex | Определение синонима: вступать в половую связь с
Синоним слова: знать | Определение синонима: вступать в половую связь с
Синоним слова: do_it | Определение синонима: вступать в половую связь с
Синоним слова: be_intimate | Определение синонима: вступать в половую связь с
Синоним слова: have_intercourse | Определение синонима: вступать в половую связь с
Синоним слова: have_it_away | Определение синонима: вступать в половую связь с
Синоним слова: have_it_off | Определение синонима: вступать в половую связь с
Синоним слова: винт | Определение синонима: вступать в половую связь с
Синоним слова: ебать | Определение синонима: вступать в половую связь с
Синоним слова: джаз | Определение синонима: вступать в половую связь с
Синоним слова: эфф | Определение синонима: вступать в половую связь с
Синоним слова: горб | Определение синонима: вступать в половую связь с
Синоним слова: ложь_с | Определение синонима: вступать в половую связь с
Синоним слова: кровать | Определение синонима: вступать в половую связь с
Синоним слова: have_a_go_at_it | Определение синонима: вступать в половую связь с
Синоним слова: бах | Определение синонима: вступать в половую связь с
Синоним слова: get_it_on | Определение синонима: вступать в половую связь с
Синоним слова: бонк | Определение синонима: вступать в половую связь с
Приведенный выше пример относится ко всем вариантам слова «любовь» с его возможными синонимами и их контекстами. Он показывает, как можно обогатить контент с помощью определенных типов словарей и как можно еще больше углубить контекст для повышения релевантности. Возможная система поиска информации может лучше понять цель контента с помощью этих синонимов и антонимов. Таким образом, важны NLTK WordNet и извлечение синонимов, антонимов, а также изучение определения слова и примеров предложений.
Он показывает, как можно обогатить контент с помощью определенных типов словарей и как можно еще больше углубить контекст для повышения релевантности. Возможная система поиска информации может лучше понять цель контента с помощью этих синонимов и антонимов. Таким образом, важны NLTK WordNet и извлечение синонимов, антонимов, а также изучение определения слова и примеров предложений.
Как извлечь синонимы и антонимы из других языков, кроме английского, через NLTK Wordnet?
Для извлечения синонимов и антонимов из других языков, помимо английского, через NLTK Wordnet, следует использовать метод «langs()».С NLTK WordNet и методом «lang» следует использовать языковые коды ISO-639. Коды языков ISO-639 содержат коды языков с сокращением. Коды языков, которые можно использовать с NLTK WordNet, можно увидеть ниже.
- ENG
- ALS
- ARB
- бул
- кошка
- стп
- дан
- Ell
- EUS
- фас
- плавник
- От
- ГЛГ
- хеб
- грн
- экз
- ита
- JPN
- NLD
- нно
- шишка
- Pol
- Por
- qcn
- SLV
- спа
- SWE
- тха
- ZSM
Для того, чтобы использовать ISO-639 коды языков с NLTK WordNet для поиска синонимов и антонимов с атрибутом «lang», вы можете изучить пример ниже.
wordnet.synset("love.v.01").lemma_names("fra")
ВЫВОД >>>
['aimer', 'amour', 'bien', "faire_l'amour", 'Mange']
Пример использования метода «lang» для поиска синонима «love» с первым значением глагола во французском языке можно увидеть выше. Синонимы «любви» как глагола во французском языке можно увидеть ниже.
Эти типы языковых переводов с разными синонимами из разных контекстов могут использоваться для поиска контекстуальной релевантности между разными документами на разных языках.Таким образом, NLTK является ценным инструментом для поисковых систем. Коды языка ISO-639 использовались для атрибута hreflang в контексте SEO, как в методе NLTK WordNet «lang».
Какая еще лексическая семантика может быть извлечена с помощью NLTK WordNet помимо антонимов и синонимов?
Другая лексическая семантика может быть извлечена с помощью NLTK WordNet, кроме антонимов и синонимов, перечисленных ниже.
- Гиперонимы: Гипероним является противоположностью (антонимом) Гипонима.
 Гипнерим — высшая вещь из класса вещей.NLTK WordNet можно использовать для извлечения гипернимов слова с атрибутом «hypnerym».
Гипнерим — высшая вещь из класса вещей.NLTK WordNet можно использовать для извлечения гипернимов слова с атрибутом «hypnerym». - Гипонимы: Гипоним является противоположностью (антонимом) гипернима. Гипоним — внутренняя вещь класса вещей. NLTK WordNet можно использовать для извлечения гипонима слова с атрибутом «hyponym».
- Холонимы: Холоним является противоположностью (антонимом) меронима. Холоним — это название целого, состоящего из нескольких частей. NLTK WordNet можно использовать для извлечения гиперонимов слова с атрибутом «member_holonym».
- Меронимы: Мероним является противоположностью (антонимом) холонима. Он представляет собой название части внутри вещи. NLTK WordNet можно использовать для извлечения гипернимов слова с атрибутом «hypnerym». NLTK WordNet имеет «member_meronyms» для извлечения меронима слова.
Лексическая семантика включает в себя гиперонимы, гипонимы, холонимы, меронимы, антонимы, синонимы и более семантические отношения слов. Маркировка семантических ролей и лексическая семантика напрямую связаны с семантическим SEO и обработкой естественного языка.В этом контексте NLTK WordNet и лексические отношения, такие как гипернимы, гипонимы, меронимы, важны для SEO и NLP.
Маркировка семантических ролей и лексическая семантика напрямую связаны с семантическим SEO и обработкой естественного языка.В этом контексте NLTK WordNet и лексические отношения, такие как гипернимы, гипонимы, меронимы, важны для SEO и NLP.
Как найти гиперним слова с помощью NLTK WordNet и Python?
Чтобы найти гипернимы слова и просмотреть имена его высших классов, следует использовать метод «гиперним()» в NLTK WordNet и Synset. Гипероним является частью лексических отношений в NLTK WordNet, которая объясняет верхние и высшие понятия слова. Гипероним может показать контекст слова.Пример нахождения гипернима слова можно увидеть ниже.
для син в wordnet.synsets("любовь"):
print(syn.hypernym_distances())
ВЫВОД >>>
{(Synset('чувство.n.01'), 2), (Synset('атрибут.n.02'), 4), (Synset('любовь.n.01'), 0), (Synset(' entity.n.01'), 6), (Synset('abstraction.n.06'), 5), (Synset('state.n.02'), 3), (Synset('эмоция.n.01 '), 1)}
{(Synset('love.n.02'), 0), (Synset('cognition. n.01'), 3), (Synset('content.n.05'), 2), (Synset(' психологическая_особенность.n.01'), 4), (Synset('сущность.n.01'), 6), (Synset('абстракция.n.06'), 5), (Synset('объект.n.04') , 1)}
{(Synset('целое.n.02'), 5), (Synset('физический_объект.n.01'), 7), (Synset('сущность.n.01'), 8), (Synset(' entity.n.01'), 5), (Synset('organism.n.01'), 3), (Synset('object.n.01'), 6), (Synset('любимый.n.01 '), 0), (Synset('living_thing.n.01'), 4), (Synset('физическая_сущность.n.01'), 4), (Synset('lover.n.01'), 1) , (Synset('person.n.01'), 2), (Synset('causal_agent.n.01'), 3)}
{(Synset('abstraction.n.06'), 6), (Synset('state.n.02'), 4), (Synset('sexual_desire.n.01'), 1), (Synset('attribute.n.02'), 5), (Synset('entity.n.01') , 7), (Синсет('любовь.n.04'), 0), (Синсет('чувство.n.01'), 3), (Синсет('желание.n.01'), 2)}
{(Synset('score.n.03'), 1), (Synset('measure.n.02'), 4), (Synset('number.n.02'), 2), (Synset(' entity.n.01'), 6), (Synset('abstraction.n.06'), 5), (Synset('love.n.05'), 0), (Synset('определенное_количество.
n.01'), 3), (Synset('content.n.05'), 2), (Synset(' психологическая_особенность.n.01'), 4), (Synset('сущность.n.01'), 6), (Synset('абстракция.n.06'), 5), (Synset('объект.n.04') , 1)}
{(Synset('целое.n.02'), 5), (Synset('физический_объект.n.01'), 7), (Synset('сущность.n.01'), 8), (Synset(' entity.n.01'), 5), (Synset('organism.n.01'), 3), (Synset('object.n.01'), 6), (Synset('любимый.n.01 '), 0), (Synset('living_thing.n.01'), 4), (Synset('физическая_сущность.n.01'), 4), (Synset('lover.n.01'), 1) , (Synset('person.n.01'), 2), (Synset('causal_agent.n.01'), 3)}
{(Synset('abstraction.n.06'), 6), (Synset('state.n.02'), 4), (Synset('sexual_desire.n.01'), 1), (Synset('attribute.n.02'), 5), (Synset('entity.n.01') , 7), (Синсет('любовь.n.04'), 0), (Синсет('чувство.n.01'), 3), (Синсет('желание.n.01'), 2)}
{(Synset('score.n.03'), 1), (Synset('measure.n.02'), 4), (Synset('number.n.02'), 2), (Synset(' entity.n.01'), 6), (Synset('abstraction.n.06'), 5), (Synset('love.n.05'), 0), (Synset('определенное_количество.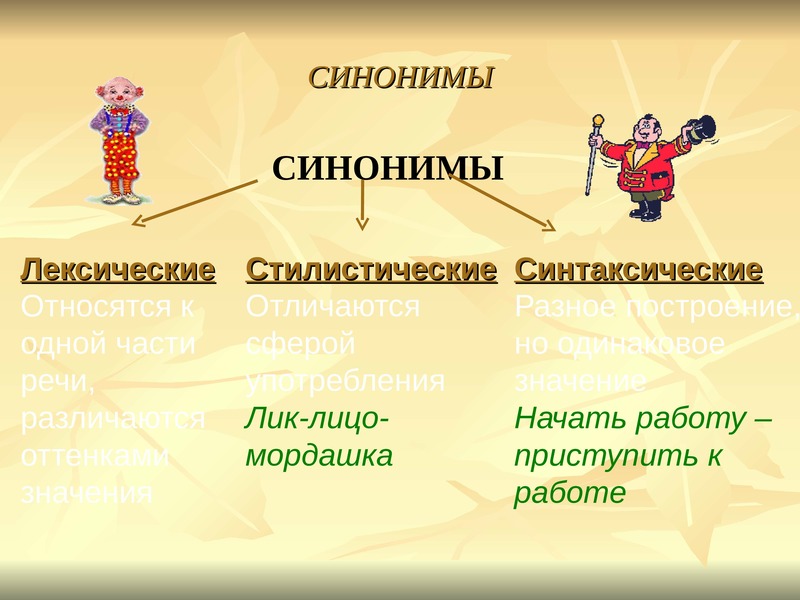 n.01 '), 3)}
{(Synset('sexual_activity.n.01'), 1), (Synset('organic_process.n.01'), 3), (Synset('process.n.06'), 4), (Synset(' сексуальная_любовь.n.02'), 0), (Synset('entity.n.01'), 6), (Synset('physical_entity.n.01'), 5), (Synset('body_process.n.01') , 2)}
{(Синсет('love.v.01'), 0)}
{(Synset('like.v.02'), 1), (Synset('love.v.02'), 0)}
{(Synset('love.v.03'), 0), (Synset('love.v.01'), 1)}
{(Synset('copulate.v.01'), 1), (Synset('sleep_together.v.01'), 0), (Synset('connect.v.01'), 3), (Synset(' присоединиться.v.04'), 2)}
n.01 '), 3)}
{(Synset('sexual_activity.n.01'), 1), (Synset('organic_process.n.01'), 3), (Synset('process.n.06'), 4), (Synset(' сексуальная_любовь.n.02'), 0), (Synset('entity.n.01'), 6), (Synset('physical_entity.n.01'), 5), (Synset('body_process.n.01') , 2)}
{(Синсет('love.v.01'), 0)}
{(Synset('like.v.02'), 1), (Synset('love.v.02'), 0)}
{(Synset('love.v.03'), 0), (Synset('love.v.01'), 1)}
{(Synset('copulate.v.01'), 1), (Synset('sleep_together.v.01'), 0), (Synset('connect.v.01'), 3), (Synset(' присоединиться.v.04'), 2)}
Объяснение «как найти гиперним слова с кодовым блоком NLTK» ниже.
- Импорт NLTK и WordNet
- Использовать «.synsets» метод wordnet.
- Используйте цикл for для всех контекстов фраз.
Пример обнаружения гиперонимов выделенной фразы представляет разные контексты «существительное» и «глагол». Таким образом, существует множество различных гиперонимических путей. Гиперонимическая дистанция представляет различные концептуальные связи со значимой лексической иерархией. Например, фраза «любовь» имеет «чувство» в качестве гипернима, чувство с первым контекстом «существительное», в то время как «атрибут» является вторым примером гипернима для второго контекста «существительного».Контекст слов можно увидеть с его определением, как показано ниже.
Например, фраза «любовь» имеет «чувство» в качестве гипернима, чувство с первым контекстом «существительное», в то время как «атрибут» является вторым примером гипернима для второго контекста «существительного».Контекст слов можно увидеть с его определением, как показано ниже.
wordnet.synset("love.n.01").definition()
ВЫВОД>>>
«сильная положительная эмоция уважения и привязанности»
WordNet говорит, что «love.n.01» означает сильную положительную эмоцию. Таким образом, гиперонимом слова «любовь» для первого контекста существительного является «чувство», которое является синонимом «эмоции». Для гипернима второго контекста, который является второй «существительной» версией слова «любовь», пример приведен ниже.
wordnet.synset("love.n.02").definition()
ВЫВОД >>>
'любой объект теплой привязанности или преданности'
Слово «атрибут» является гиперонимом слова «любовь» для второго существительного, означающего «любой объект теплой привязанности или преданности». Таким образом, в зависимости от контекста слова значение и гиперонимы будут меняться. Пути и расстояния гиперонимов WordNet могут влиять на показатель актуальности и семантическую релевантность части контента запросу или контексту.Еще один пример нахождения «гипернимов» можно найти ниже.
Таким образом, в зависимости от контекста слова значение и гиперонимы будут меняться. Пути и расстояния гиперонимов WordNet могут влиять на показатель актуальности и семантическую релевантность части контента запросу или контексту.Еще один пример нахождения «гипернимов» можно найти ниже.
собака = wordnet.synset('собака.n.01')
печать (собака.гипернимы ())
ВЫВОД >>>
[Synset('basenji.n.01'), Synset('corgi.n.01'), Synset('cur.n.01'), Synset('dalmatian.n.02'), Synset('great_pyrenees. n.01'), Synset('грифон.n.02'), Synset('hunting_dog.n.01'), Synset('болонка.n.01'), Synset('leonberg.n.01'), Synset('mexican_less.n.01'), Synset('Ньюфаундленд.n.01'), Synset('дворняжка.n.01'), Synset('пудель.n.01'), Synset('мопс.n .01'), Synset('щенок.n.01'), Synset('шпиц.n.01'), Synset('toy_dog.n.01'), Synset('working_dog.n.01')]
Фраза «собака» со значением первого существительного имеет разные гипернимы от «далматинец» до «грифон» или «щенок» и «рабочая собака». Все эти гипернимы могут быть ближе к значению собаки в документе в соответствии с общим контекстом документа. Нахождение гиперонимов и гипонимов связаны друг с другом. Гипонимы могут дополнять значение гипернима для выбранной фразы в NLTK WordNet.
Нахождение гиперонимов и гипонимов связаны друг с другом. Гипонимы могут дополнять значение гипернима для выбранной фразы в NLTK WordNet.
Как найти гипоним слова с помощью NLTK WordNet и Python?
Чтобы найти гипонимы слова с помощью NLTK WordNet и Python, можно использовать метод «hyponyms()». Нахождение гипонима полезно для того, чтобы увидеть лексические отношения слова как гипернима. Гипонимы включают в себя низшие типы низших версий определенной фразы с различным контекстом. Чтобы найти гипонимы с NLTK и NLP, следуйте приведенным ниже инструкциям.
для син в wordnet.synsets("любовь"):
печать (син.гипонимы())
ВЫВОД >>>
[Synset('agape.n.01'), Synset('agape.n.02'), Synset('любовь.n.01'), Synset('страсть.n.02'), Synset('доброжелательность. n.01'), Synset('преданность.n.01'), Synset('filial_love.n.01'), Synset('heartstrings.n.01'), Synset('любовь.n.01'), Synset('лояльность.n.02'), Synset('puppy_love.n.01'), Synset('поклонение.n.02')]
[]
[]
[]
[]
[]
[Synset('adore. v.01'), Synset('care_for.v.02'), Synset('dote.v.02'), Synset('love.v.03')]
[Синсет('get_off.v.06')]
[Синсет('романтика.v.02')]
[Synset('прелюбодействовать.v.01'), Synset('take.v.35')]
v.01'), Synset('care_for.v.02'), Synset('dote.v.02'), Synset('love.v.03')]
[Синсет('get_off.v.06')]
[Синсет('романтика.v.02')]
[Synset('прелюбодействовать.v.01'), Synset('take.v.35')]
Объяснение поиска гипонима на примере кода NLTK приведено ниже.
- Импорт NLTK и WordNet
- Вызов «wordnet.sysnset» для выбранной фразы.
- Назовите каждый «гипоним» для каждого контекста слова.
Приведенный выше пример фразы «любовь» показывает, что существуют разные типы гипонимов для разных типов значений слова «любовь». Для первого контекста существительного гипоним любви — «агапе».«Агапе» — это гипоним второго значения «любви» как существительного одновременно. В WordNet слово может иметь разные гипернимы для разных версий существительных, но иметь один и тот же гипоним для обоих из них, например, любовь. В NLTK может быть несколько гипонимов для определенного слова, например «влюбчивость». Влюбленность — это гипоним слова «любовь» для значения первого существительного. Это означает, что когда мы проверяем гипероним гипонима, то же самое понятие будет появляться для завершения пути гиперонима. Ниже приведен пример двунаправленного контроля гипероним-гипоним для NLTK WordNet.
Это означает, что когда мы проверяем гипероним гипонима, то же самое понятие будет появляться для завершения пути гиперонима. Ниже приведен пример двунаправленного контроля гипероним-гипоним для NLTK WordNet.
для син в wordnet.synsets("влюбчивость"):
печать (син.гипернимы ())
ВЫВОД >>>
[Синсет('love.n.01')]
[Synset('sexual_desire.n.01')]
Гиперонимом «влюбчивости» является словосочетание «любовь». И второй гипероним «влюбленности» – «половое влечение», что является сигналом контекста связи между «любовью» и «влюбленностью». Тот же самый процесс можно проследить для значения первого гипонима любви — «агапе».
для син в wordnet.синсеты ("агапе"):
печать (син.гипернимы ())
ВЫВОД >>>
[Синсет('love.n.01')]
[Синсет('love.n.01')]
[Synset('religious_ceremony.n.01')]
[]
«Агапе» имеет гиперним «любовь», естественно. У него также есть гипероним «религиозная церемония», который показывает контекст связи с фразой «любовь». Если мы проверим синонимы и определение «агапе», эта связь станет более ясной.
Если мы проверим синонимы и определение «агапе», эта связь станет более ясной.
wordnet.synset("agape.n.01").definition()
ВЫВОД >>>
'(христианское богословие) любовь Бога или Христа к человечеству'
Определение «агапе» показывает связь слова «любовь» и его гипонима со словом «религиозная церемония».Синонимы «агапе» могут сделать контекст этой связи более ясным.
для син в wordnet.synsets("agape"):
для l в syn.lemmas():
печать (л.имя())
ВЫВОД >>>
агапе
агапе
agape_love
агапе
любовь_пир
агапе
зияющие
Синонимы «агапе» представляют контекст «христианской любви» как гипоним слова «любовь». Потому что «пир любви» — это один из синонимов слова «любовь». А «пир любви» на самом деле является термином христианской мифологии.
«Праздник любви» определяется словом «агапэ». Гиперонимы и гипонимы NLTK WordNet показывают контекст слова и возможную актуальность ассоциации понятия. Поиск гиперонимов с помощью NLTK и NLP может быть поддержан путем проверки гиперонимов и синонимов, а также определений слов. Тематическое моделирование является важной частью соединений гипернимов и гипонимов NLTK. В этом контексте в качестве примера можно привести тематическое моделирование с помощью Bertopic.
Тематическое моделирование является важной частью соединений гипернимов и гипонимов NLTK. В этом контексте в качестве примера можно привести тематическое моделирование с помощью Bertopic.
Как найти глагольные рамки глагола с помощью NLTK WordNet и Python?
Чтобы найти глагольные рамки глагола с помощью NLTK WordNet можно найти с помощью методов «frame_ids» и «frame_strings».Глагольная рамка включает в себя значение конкретного глагола с примерным предложением. Ниже вы можете увидеть пример использования «frame_ids» и «frame_strings» с NLTK WordNet для поиска кадров глаголов.
для леммы в wordnet.synset('run.v.02').lemmas():
печать (лемма, лемма.frame_ids())
print(" | ".join(lemma.frame_strings()))
ВЫВОД >>>
Лемма('scat.v.01.scat') [1, 2, 22]
Что-то копро | Кто-то скат | Кто-нибудь скат ПП
Лемма('scat.v.01.run') [1, 2, 22]
Что-то запустить | Кто-нибудь, бегите | Кто-нибудь, запустите ПП
Лемма('scat.v.01.scarper') [1, 2, 22]
Что-то скуднее | Кто-то убегает | Кто-то убирает ПП
Лемма('scat. v.01.turn_tail') [1, 2, 22]
Что-то поворот_хвост | Кто-нибудь поверните_хвост | Кто-нибудь, поверните_хвост, ПП
Лемма('scat.v.01.lam') [1, 2, 22]
Что-то лам | Кто-то лам | Кто-то лям ПП
Лемма('scat.v.01.run_away') [1, 2, 22]
Что-то run_away | Кто-то run_away | Кто-то убегает, ПП
Лемма('scat.v.01.hightail_it') [1, 2, 22]
Что-то hightail_it | Кто-то hightail_it | Кто-то hightail_it ПП
Лемма('scat.v.01.койка') [1, 2, 22]
Что-то двухъярусное | Кто-то двухъярусный | Кто-то двухъярусный ПП
Лемма('scat.v.01.head_for_the_hills') [1, 2, 22]
Что-то head_for_the_hills | Кто-то head_for_the_hills | Кто-то head_for_the_hills PP
Лемма('scat.v.01.take_to_the_woods') [1, 2, 22]
Что-нибудь возьми_в_ту_вудс | Кто-нибудь возьмет_в_лес | Кто-нибудь, возьми_в_вудс PP
Лемма('scat.v.01.escape') [1, 2, 22]
Что-то бежать | Кто-то бежать | Кто-нибудь, сбегите, ПП
Лемма('scat.v.01.fly_the_coop') [1, 2, 22]
Что-то fly_the_coop | Кто-нибудь fly_the_coop | Кто-нибудь, fly_the_coop, ПП
Лемма('scat.v.01.break_away') [1, 2, 22]
Что-то break_away | Кто-то break_away | Кто-то break_away PP
v.01.turn_tail') [1, 2, 22]
Что-то поворот_хвост | Кто-нибудь поверните_хвост | Кто-нибудь, поверните_хвост, ПП
Лемма('scat.v.01.lam') [1, 2, 22]
Что-то лам | Кто-то лам | Кто-то лям ПП
Лемма('scat.v.01.run_away') [1, 2, 22]
Что-то run_away | Кто-то run_away | Кто-то убегает, ПП
Лемма('scat.v.01.hightail_it') [1, 2, 22]
Что-то hightail_it | Кто-то hightail_it | Кто-то hightail_it ПП
Лемма('scat.v.01.койка') [1, 2, 22]
Что-то двухъярусное | Кто-то двухъярусный | Кто-то двухъярусный ПП
Лемма('scat.v.01.head_for_the_hills') [1, 2, 22]
Что-то head_for_the_hills | Кто-то head_for_the_hills | Кто-то head_for_the_hills PP
Лемма('scat.v.01.take_to_the_woods') [1, 2, 22]
Что-нибудь возьми_в_ту_вудс | Кто-нибудь возьмет_в_лес | Кто-нибудь, возьми_в_вудс PP
Лемма('scat.v.01.escape') [1, 2, 22]
Что-то бежать | Кто-то бежать | Кто-нибудь, сбегите, ПП
Лемма('scat.v.01.fly_the_coop') [1, 2, 22]
Что-то fly_the_coop | Кто-нибудь fly_the_coop | Кто-нибудь, fly_the_coop, ПП
Лемма('scat.v.01.break_away') [1, 2, 22]
Что-то break_away | Кто-то break_away | Кто-то break_away PP
В приведенном выше примере показано, как найти различные значения глагола с его вариациями.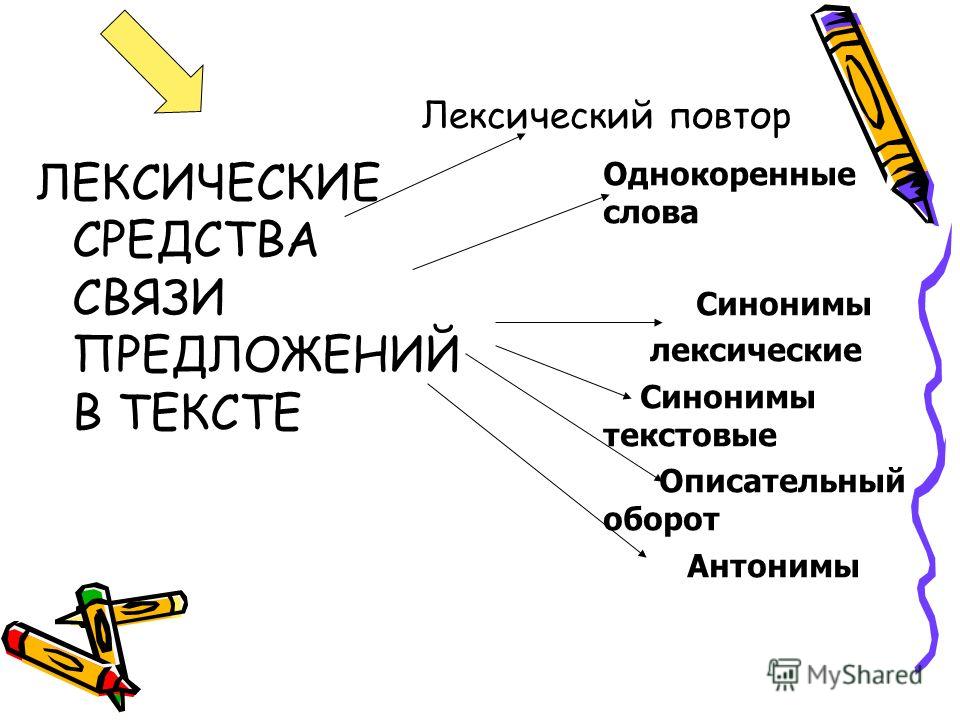 Второе значение глагола «бежать» имеет другие вариации и синонимы, такие как «повернуть_хвост», «скат», «отколоться», «убежать» и другие контекстуальные синонимы. Глагольные рамки помогают найти возможные замены слов и контекстуальные связи между предложениями. Если конкретный глагол заменяется одним из примеров в глагольной структуре без изменения значения предложения или контекста абзаца, это означает, что глагольные рамки используются правильно.
Второе значение глагола «бежать» имеет другие вариации и синонимы, такие как «повернуть_хвост», «скат», «отколоться», «убежать» и другие контекстуальные синонимы. Глагольные рамки помогают найти возможные замены слов и контекстуальные связи между предложениями. Если конкретный глагол заменяется одним из примеров в глагольной структуре без изменения значения предложения или контекста абзаца, это означает, что глагольные рамки используются правильно.
Как найти похожие слова для целевого слова с помощью NLTK WordNet и Python?
Чтобы найти похожие друг на друга слова с помощью NLTK Wordnet и Python, используются «lch_similarity» и «path_similarity». NLTK WordNet измеряет сходство слов на основе таксономии гиперонимов и гипонимов. Расстояние между словами в рамках путей гиперонимов и гипонимов представляет собой уровень сходства между ними. Типы сходства и методы, которые можно использовать в NLTK WordNet для измерения сходства слов, перечислены ниже.
- Resink Сходство с «synset1.
 res_similarity(synset2, ic)».
res_similarity(synset2, ic)». - Ву-Палмер Сходство с «synset1.wup_similarity(synset2)».
- Leacock-Chodorow Сходство с «synset1.lch_similarity(synset2)».
- Сходство пути с «synset1.path_similarity(synset2)».
Пример измерения сходства слов с NLTK WordNet можно найти ниже.
wordnet.synset("dog.n.01").path_similarity(wordnet.synset("cat.n.01"))
ВЫВОД >>>
0.2
Оценка сходства слов в NLTK WordNet представляет собой сходство между словами. Оценка сходства слов в NLTK WordNet находится в диапазоне от 0 до 1. 0 означает отсутствие сходства, а 1 представляет точное идентичное сходство. Таким образом, приведенный выше пример измерения сходства слов с Python показывает, что слово «кошка» и слово «собака» как «существительное» похожи друг на друга на 20%.
«Подобие Ликока-Чодороу» использует расстояние между гиперонимами и гипонимами для расчета подобия, принимая во внимание кратчайший путь.Кратчайший путь гиперонима и гипонима между двумя словами и общая глубина пути будут представлять сходство для измерения сходства Ликока-Чодороу. Ниже вы можете найти пример использования подобия Leacock-Chodorow с NLTK WordNet.
Ниже вы можете найти пример использования подобия Leacock-Chodorow с NLTK WordNet.
wordnet.synset("dog.n.01").lch_similarity(wordnet.synset("cat.n.01"))
ВЫВОД >>>
2,0281482472922856
В приведенном выше примере показана оценка сходства слов на основе сходства Ликока-Чодорова с NLTK WordNet.Поиск похожих слов с помощью Python и NLTK WordNet — это широкая тема, которую можно решить с помощью таких формул, как «-log(p/2d)» и других измерений сходства или атрибутов корневого узла. Полезно видеть прогнозы и замены слов с успехом. Алгоритм NLP может заменять слова на основе их сходства, чтобы проверить сдвиги контекста. Если контекст смещается слишком сильно, это означает, что контент имеет отношение к первому кандидату контекста. И сходство слов с NLTK можно использовать для расчета релевантности или информационно-поисковых систем.
Как найти тематические домены слова с помощью NLTK WordNet и Python?
NLTK WordNet имеет метрику «тематический домен» для определенного слова. Тематическая область показывает контекст слова и его значение для предметной области. NLTK WordNet можно использовать для понимания актуальности и актуальности контента для другого. Все документы с веб-сайта, книги или все предложения из контента с их словами могут быть взяты для расчета тематических доменов. Доминирующая предметная область может сигнализировать об основном контексте документа.Таким образом, для поисковой системы полезны NLTK WordNet или Semantic Networks с надлежащим набором данных.
Тематическая область показывает контекст слова и его значение для предметной области. NLTK WordNet можно использовать для понимания актуальности и актуальности контента для другого. Все документы с веб-сайта, книги или все предложения из контента с их словами могут быть взяты для расчета тематических доменов. Доминирующая предметная область может сигнализировать об основном контексте документа.Таким образом, для поисковой системы полезны NLTK WordNet или Semantic Networks с надлежащим набором данных.
Чтобы найти тематические домены слова с помощью NLTK WordNet и Python, выполните следующие действия.
- Импортируйте NLTK.corpus и wordnet, чтобы найти тематический домен.
- Выберите пример слова или фразы, чтобы взять тематический домен.
- Используйте метод «синхронизации» Wordnet для выбранного слова.
- Используйте метод «topic_domains()» объекта «synset».
- Прочитайте вывод примера «topic_domains()».
Пример использования NLTK WordNet для поиска предметной области слова можно найти ниже.
wordnet.synset('code.n.03').topic_domains()
ВЫВОД >>>
[Synset('computer_science.n.01')]
В приведенном выше примере показано, что предметной областью слова «код» как существительного с третьей версией является «информатика». Одна из проблем диагностики тематических доменов для слов из NLTK WordNet заключается в том, что моделирование и иерархия тем могут быть недостаточно подробными.Для этого можно использовать домены Wordnet. Чтобы использовать домены WordNet, необходимо подать заявку с адресом электронной почты и принять лицензию Creative Common. С доменами WordNet можно исследовать более 400 тематических доменов. Чтобы напечатать тематические домены в доменах WordNet, используйте приведенный ниже пример кода.
из коллекций импортировать defaultdict
из nltk.corpus импортировать wordnet как wn
domain2synsets = defaultdict(список)
synset2domains = defaultdict(список)
для i в open('wn-domains-3.2-20070223', 'р'):
ssid, doms = i. strip().split('\t')
дома = дома.split()
synset2domains[ssid] = домены
для d в домах:
domain2synsets[d].append(ssid)
для сс в wn.all_synsets():
ssid = str(ss.offset).zfill(8) + "-" + ss.pos()
если synset2domains[ssid]:
print(ss, ssid, synset2domains[ssid])
для домена в sorted(domain2synsets):
print(dom, domain2synsets[dom][:3])
ВЫВОД >>>
акустика ['02584104-н', '02584268-н', '02584812-н']
администрация ['00045146-n', '00556291-n', '00556427-n']
сельское хозяйство ['00429923-n', '00866914-n', '00996641-n']
анатомия ['00037703-n', '00133136-n', '00353921-n']
animal_husbandry ['00792299-n', '00860674-n', '00861073-n']
животные ['00012748-n', '00962111-n', '01153586-n']
антропология ['00210724-n', '00211160-n', '00211365-n']
прикладная_наука ['03985477-n', '04266345-n', '04352832-n']
археология ['00040040-n', '01328460-n', '018
strip().split('\t')
дома = дома.split()
synset2domains[ssid] = домены
для d в домах:
domain2synsets[d].append(ssid)
для сс в wn.all_synsets():
ssid = str(ss.offset).zfill(8) + "-" + ss.pos()
если synset2domains[ssid]:
print(ss, ssid, synset2domains[ssid])
для домена в sorted(domain2synsets):
print(dom, domain2synsets[dom][:3])
ВЫВОД >>>
акустика ['02584104-н', '02584268-н', '02584812-н']
администрация ['00045146-n', '00556291-n', '00556427-n']
сельское хозяйство ['00429923-n', '00866914-n', '00996641-n']
анатомия ['00037703-n', '00133136-n', '00353921-n']
animal_husbandry ['00792299-n', '00860674-n', '00861073-n']
животные ['00012748-n', '00962111-n', '01153586-n']
антропология ['00210724-n', '00211160-n', '00211365-n']
прикладная_наука ['03985477-n', '04266345-n', '04352832-n']
археология ['00040040-n', '01328460-n', '018-n']
стрельба из лука ['00423600-n', '070-n', '09608089-n']
архитектура ['00577011-n', '00871831-n', '02578017-n']
искусство ['00258392-n', '00573836-n', '00672395-n']
мастерство ['00869978-n', '00870256-n', '00870389-n']
астрология ['03407158-n', '04436236-n', '05444230-n']
космонавтика ['00280016-н', '02827728-н', '02966235-н']
астрономия ['00045801-n', '02655846-n', '02656041-n']
легкая атлетика ['00410707-n', '00410925-n', '00414898-n']
atomic_physic ['02657581-н', '02685588-н', '02736848-н']
авиация ['00047580-n', '00047871-n', '00159777-n']
бадминтон ['00455850-н', '00456227-н', '00458699-н']
Поиск тем в документах с тематическими доменами слов через NLTK WordNet можно сделать лучше, используя домены WordNet. Ниже вы можете увидеть вывод доменов WordNet с Python.
Ниже вы можете увидеть вывод доменов WordNet с Python.
Поисковая система Google имеет такую же актуальность и понимание предметной области, что и NLTK WordNet и домены WordNet. Google NLP API дает более 100 тем для определенного раздела. В этом контексте чтение с использованием Google Knowledge Graph API и учебника и руководства по Python полезно для просмотра тем, объектов и их классификации на основе текста.
Чтобы узнать больше, прочтите Руководство по доменам WordNet.
Как найти региональные домены слова с помощью NLTK WordNet и Python?
Региональные домены представляют регион конкретного используемого слова. Полезно видеть культурную близость слова. Домен региона может сигнализировать о домене темы. Но разница между доменом региона и доменом темы заключается в том, что он представляет географическую и культурную категорию больше, чем его основную тему. Чтобы найти домен региона с помощью NLTK WordNet, используется метод «region_domains()».Инструкции по поиску региональных доменов слова с помощью NLTK WordNet приведены ниже.
- Импортируйте корпус NLTK и WordNet, чтобы найти региональный домен слова.
- Выберите слово, чтобы найти домены региона.
- Используйте «WordNet.synset()» в качестве примера слова.
- Используйте метод «region_domains()».
Ниже приведен пример поиска доменов регионов с помощью NLTK WordNet и Python.
wordnet.synset('pukka.a.01').region_domains()
ВЫВОД >>>
[Синсет('Индия.п.01')]
Приведенный выше пример показывает, что слово «Пукка» в качестве прилагательного имеет Индию в качестве домена региона. Тот же процесс может быть реализован для всех слов из документа, чтобы найти общие сигналы региона документа с помощью NLTK WordNet.
Разница между доменом темы и доменом региона заключается в том, что домен темы фокусируется на значении слова, а домен региона фокусируется на географии и культуре слова. Точно так же «область использования» фокусируется на том, в каком языковом стиле используется конкретное слово. Например, слово может быть из темы медицины и Японии как региона при использовании в научном языке. Таким образом, NLTK WordNet должен предоставлять информацию для изучения тональности языка, региональных сигналов и понимания актуальности. В следующем разделе будет продемонстрирован пример для доменов использования NLTK WordNet.
Например, слово может быть из темы медицины и Японии как региона при использовании в научном языке. Таким образом, NLTK WordNet должен предоставлять информацию для изучения тональности языка, региональных сигналов и понимания актуальности. В следующем разделе будет продемонстрирован пример для доменов использования NLTK WordNet.
Как найти домены использования слова с помощью NLTK WordNet и Python?
Домен использования включает используемый языковой стиль слова. Слово может быть использовано учеными или может быть использовано в жаргонном языке.Чтобы узнать подлинность контента, целевую аудиторию или писательский характер автора, можно использовать домен использования. В этом контексте можно увидеть акцент текстового языка. Чтобы найти домен использования слова с помощью NLTK WordNet, следует использовать метод «usage_domains()». Ниже приведены инструкции по поиску доменов использования с помощью NLTK WordNet.
- Импорт корпуса NLTK и WordNet
- Выберите слово, чтобы найти домены использования.

- Используйте «WordNet.synset()» для слова.
- Используйте метод «usage_domains()».
Ниже приведен пример использования домена использования NLTK WordNet.
wn.synset('fuck.n.01').usage_domains()
ВЫВОД >>>
[Synset('непристойность.n.02'), Synset('сленг.n.02')]
В приведенном выше примере поиска области использования слова с помощью NLTK WordNet и Python показана область использования слова из «нецензурной лексики» и «сленга». Домены использования NLTK WordNet могут быть хорошим сигналом для того, чтобы увидеть общий характер содержимого веб-сайта или документа и книги.
Как использовать WordNet для других языков с Python NLTK?
Чтобы использовать WordNet NLTK на другом языке, используется метод «wordnet.lang» или «lemma_names». Коды языков ISO-639 используются для определения языка, который будет использоваться для WordNet NLTK. Ниже вы можете найти пример использования NLTK WordNet для других языков для поиска синонимов или антонимов вместе с другими лексическими связями с Python.
wordnet.synset("love.v.01").lemma_names("японский")
ВЫВОД >>>
['いとおしむ',
'いとおしがる',
'傾慕+する',
'好く',
'寵愛+する',
'愛しむ',
'愛おしむ',
'愛好+する',
'愛寵+する',
'愛慕+する',
'慕う',
'ほれ込む']
Пример поиска синонимов для слова «любовь» в Японии с помощью NLTK Wordnet и Python можно увидеть выше.NLTK WordNet можно использовать для поиска синонимов и лемм английских слов через слова из других языков. В приведенном ниже примере показано, как найти синонимы слова «macchina» на английском языке, который является итальянским.
wordnet.lemmas('macchina', lang='ita')
ВЫВОД >>>
[Лемма('car.n.01.macchina'),
Лемма('локомотив.n.01.macchina'),
Лемма('machine.n.01.macchina'),
Лемма('machine.n.02.macchina')]
Использование слов других языков для поиска синонимов в английском языке через NLTK WordNet полезно, чтобы увидеть возможные связи в английском языке с другими языками.Слово из итальянского языка может иметь разные типы лексических отношений в английском языке. Обнаружение межъязыкового синонима показывает понимание семантики языком-агностическим способом. Таким образом, использование NLTK WordNet для многоязычных приложений, таких как поисковые системы, полезно для просмотра темы с большим количеством слоев.
Обнаружение межъязыкового синонима показывает понимание семантики языком-агностическим способом. Таким образом, использование NLTK WordNet для многоязычных приложений, таких как поисковые системы, полезно для просмотра темы с большим количеством слоев.
Какие задачи НЛП связаны с WordNet с помощью NLTK?
Другие связанные с NLTK WordNet задачи NLTK для НЛП можно найти ниже.
- Токенизация NLTK связана с NLTK WordNet, поскольку каждое слово, токенизированное с помощью NLTK, может быть проверено с помощью его гиперонимов, гипонимов или синонимов в WordNet.
- NLTK Lemmatize связан с NLTK WordNet как задача NLP, поскольку она предоставляет различные варианты и версии одного и того же слова для понимания его контекста.
- NLTK Stemming связан с задачей NLTK WordNet для НЛП, так как она дает разные версии слов с основой.
- Тег NLTK Part of Speech относится к NLTK WordNet как к задаче NLP, поскольку он дает разные роли слову в предложении, защищая его контекст.
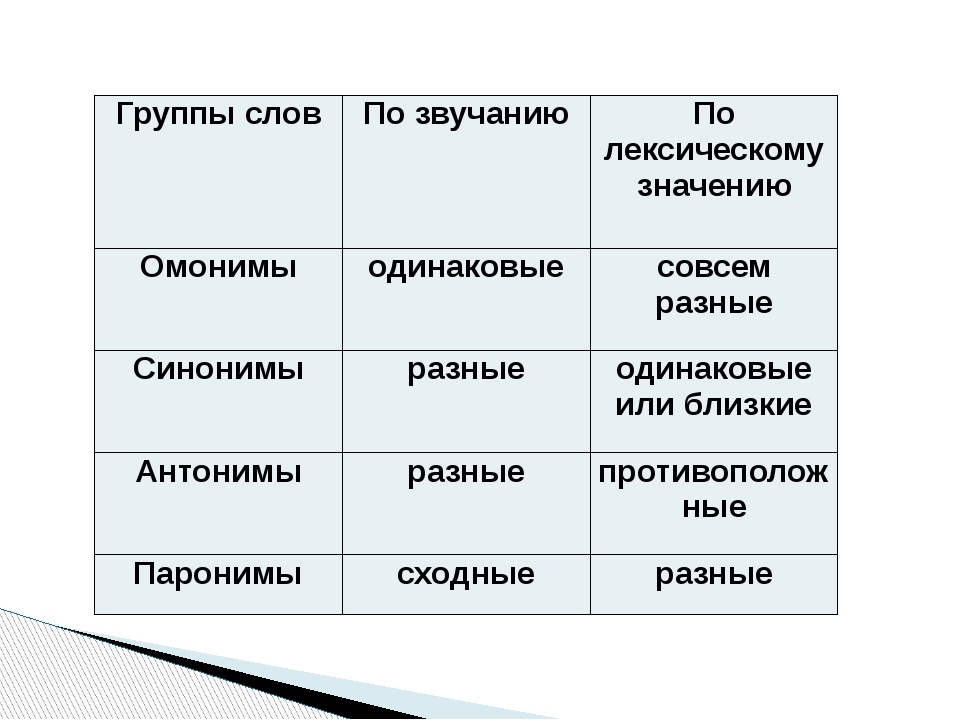
Какие термины связаны с WordNet от NLTK?
Термины, связанные с WordNet из NLTK, включают в себя лексические отношения и семантическую релевантность, а также сходство.Набор средств естественного языка для WordNet связан с приведенными ниже условиями.
- FrameNet: FrameNet подключен к NLTK WordNet, поскольку включает семантические ролевые метки, основанные на предикатах предложений и их значениях.
- Лексические отношения: Лексические отношения связаны с WordNet NLTK, поскольку они обеспечивают лексическое сходство и связи между различными терминами и понятиями.
- Семантическая релевантность: Семантическая релевантность связана с NLTK WordNet, поскольку она показывает, насколько одно слово релевантно другому, на основе семантических отношений.
- Семантическое сходство: семантическое сходство связано с NLTK, поскольку обеспечивает сходство между двумя словами на основе их контекста.
- Гипернимы: Гипернимы связаны с WordNet, потому что они включают верхнюю и старшую части слова.

- Гипонимы: Гипонимы связаны с WordNet, потому что они включают нижнюю и нижнюю части слова.
- Синонимы: Синонимы связаны с WordNet, потому что они включают в себя другие слова, имеющие такое же значение.
- Антонимы: Антонимы связаны с WordNet, потому что они включают слова с противоположным значением слова.
- Holonyms: Holonyms подключен к WordNet, потому что включает в себя всю вещь.
- Меронимы: холонимы связаны с WordNet, потому что они включают части чего-либо.
- Партоним: Партоним связан с WordNet, потому что включает замену одного слова на другое с другими суффиксами или префиксами.
- Многозначность: Многозначность связана с WordNet, потому что она предоставляет одни и те же фразы с разными значениями.
- Обработка естественного языка связана с WordNet, потому что это процесс понимания человеческого языка машинами.
- Семантический поиск подключен к WordNet, потому что он обеспечивает значимые связи между разными словами на семантической карте.

- Semantic SEO подключен к WordNet, потому что WordNet можно использовать для улучшения практики написания контента.
- Semantic Web подключен к WordNet, потому что шаблоны поведения семантической сети имеют значимые словесные отношения.
- Распознавание именованных объектов подключено к WordNet, потому что оно обеспечивает распознавание именованных объектов.
Последние мысли о NLTK WordNet и целостном SEO
NLTK WordNet и комплексное SEO следует использовать вместе.Комплексное SEO содержит все вертикали и аспекты поисковой оптимизации. NLTK WordNet может предоставить SEO-специалисту различные контексты для определенного слова, чтобы проверить возможные контекстуальные связи между разными фразами. NLTK WordNet — это известный инструмент для понимания текста, а также для очистки и обработки текста. Google и другие семантические поисковые системы, такие как Microsoft Bing, могут использовать синонимы, антонимы и гиперонимы или гипонимы для перезаписи запроса. Поисковая система может обрабатывать запрос, размечая его и заменяя слова другими родственными словами с другим контекстом.NLTK WordNet может понять актуальность конкретной части контента для запроса или кластера запросов. Исходя из этого, NLTK WordNet и целостное SEO следует брать и обрабатывать вместе.
Поисковая система может обрабатывать запрос, размечая его и заменяя слова другими родственными словами с другим контекстом.NLTK WordNet может понять актуальность конкретной части контента для запроса или кластера запросов. Исходя из этого, NLTK WordNet и целостное SEO следует брать и обрабатывать вместе.
Руководство NLTK будет по-прежнему регулярно обновляться на основе новых обновлений NLP и NLTK.
Владелец и основатель Holistic SEO & Digital
Корай Тугберк ГУБЮР является основателем и владельцем Holistic SEO & Digital. Обладая более чем 6-летним опытом SEO, Корай Тугберк ГУБУР использует науку о данных, визуализацию, внешнее кодирование и Google. Патенты на SEO-проекты.Корай Тугберк ГУБУР является автором OnCrawl, JetOctopus, Authoritas, Serpstat, NewzDash. Корай Тугберк ГУБЮР выступает на вебинарах по SEO с RankSense и Authoritas. Koray Tuğberk GÜBÜR работал с более чем 200 компаниями над их SEO-проектами. Koray Tuğberk GÜBÜR использует стратегии технического SEO, контент-маркетинга и кодирования для улучшения органической видимости SEO-проектов.
Синонимия в переводе
В этой статье будет предпринята попытка исследовать сложную природу синонимии в попытке исследовать ее проблематичный характер в отношении перевода.Особое внимание будет уделено тому, является ли перевод формой синонимии. Будут проанализированы типы синонимии, а затем будут предоставлены примеры из английского и арабского языков для изучения совпадения между одной формой синонимии и другой. В конце анализа будут сделаны выводы, а последствия будут представлены для дальнейших исследований.
Хотя понятие синонимии рассматривалось в последние два десятилетия как одно из наиболее значимых языковых явлений, повлиявших на структуру лексики, этому понятию уделялось мало внимания в областях лексикографии, психологии или даже вычислительной техники. лингвистика (Эдмондс и Херст, 2002).Какова бы ни была причина, будь то философская, практическая или практическая, синонимия считалась непроблемной проблемой в лингвистике или переводе, потому что у нас либо есть синонимы с полностью идентичными значениями и, следовательно, с ними легко иметь дело, либо мы имеем дело с синонимами. не синонимы, и в этом случае их можно рассматривать как просто разные слова (там же: 106). Понятие почти синонимов, утверждают Эдмондс и Херст, показывает, что оно столь же сложно, как и понятие полисемии, и что оно по своей сути влияет на структуру лексического знания.
не синонимы, и в этом случае их можно рассматривать как просто разные слова (там же: 106). Понятие почти синонимов, утверждают Эдмондс и Херст, показывает, что оно столь же сложно, как и понятие полисемии, и что оно по своей сути влияет на структуру лексического знания.
| Синонимия не означает тождественность, поскольку эта форма синонимии не существует в одноязычных или многоязычных условиях. |

В статье, озаглавленной « Перевод культур: беззаботный взгляд на ловушки коммуникации посредством перевода», Шоу (2003) утверждает, что люди могут различать нюансы и/или тонкие различия значений одного объекта и другого. Шоу иллюстрирует это, говоря, что в нашем языке шоу может быть пьесой , драмой , мюзиклом или фильмом. Слово шоу может быть даже проявлением таланта , т.е.е. талант или варьете . Шоу утверждает, что позже в жизни мы узнаем реальные существенные различия между сердитым , расстроенным , обеспокоенным , отмеченным , яростным и баллистическим (например, «он пошел 9 баллистическим» ) когда критиковали его друзей»). Тот же самый процесс различения происходит, когда мы изучаем второй язык и в то же время узнаем, что слова имеют значения, а такие значения имеют уникальные и разные семантические единицы.
В том же духе Hjorland (2007) считает, что синонимия является своего рода семантическим отношением. То есть слова или фразы являются синонимами только в том случае, если они имеют одинаковое значение. Однако бывают случаи, когда слова или фразы могут иметь тонкое значение и поэтому могут вызывать различные словесные ассоциации. Например, база данных Word Net (2006 г.) различает разные значения слова «компьютер» (цитируется по Edmonds and Hirst 2002:107). Первое значение дается как «машина для автоматического выполнения вычислений».Вот список различных значений слова компьютер :
То есть слова или фразы являются синонимами только в том случае, если они имеют одинаковое значение. Однако бывают случаи, когда слова или фразы могут иметь тонкое значение и поэтому могут вызывать различные словесные ассоциации. Например, база данных Word Net (2006 г.) различает разные значения слова «компьютер» (цитируется по Edmonds and Hirst 2002:107). Первое значение дается как «машина для автоматического выполнения вычислений».Вот список различных значений слова компьютер :
Компьютер
Вычислительная машина
Вычислительное устройство
Процессор данных,
Электронный компьютер
Система обработки информации
С неконтекстной точки зрения Новый словарь синонимов Merriam-Webster ( 1984: 24 ) дает следующее точное определение синонимии:
Синоним в этом словаре всегда будет означать одно из двух или более слов в английском языке, которые имеют одинаковое или почти одинаковое существенное значение. Следовательно, синонимами являются только такие слова, которые могут быть полностью или почти полностью определены в одних и тех же терминах. Обычно они отличаются друг от друга дополнительным значением или коннотацией, или они могут отличаться своим идиоматическим использованием или применением.
Следовательно, синонимами являются только такие слова, которые могут быть полностью или почти полностью определены в одних и тех же терминах. Обычно они отличаются друг от друга дополнительным значением или коннотацией, или они могут отличаться своим идиоматическим использованием или применением.
Приведенное выше определение несколько расплывчато, поскольку в нем не проводится различие между полной или полной синонимией и почти или частичной синонимией. Синонимия определяется как полная и частичная синонимия, игнорирующая тонкие различия между одним словом и другим.Это неадекватное определение, или, скорее, то, как некоторые могут относиться к синонимии, немного сбивает с толку переводчиков, особенно тех, кто считает перевод формой синонимии.
Поскольку многие лингвисты считают, что истинная или полная синонимия не существует ни в одном языке (Quine 1951; Cruse 1986:270), были предприняты попытки классифицировать синонимию по типам. Согласно Куайну (1951), существует два вида синонимии: полная синонимия и частичная синонимия.Полной синонимией считаются слова, имеющие одинаковые смысловые компоненты. Говоря более конкретно, слова являются полными синонимами тогда и только тогда, когда они разделяют друг с другом все ингредиенты. По Куайну, такого рода синонимии не существует просто потому, что ее невозможно определить, а значения слов в одноязычных или многоязычных условиях постоянно меняются. Следовательно, слова могут иметь общее большинство составляющих друг с другом, но не все составляющие. Что касается частичной синонимии, то это когда слова разделяют большинство необходимых компонентов или составляющих.Например, слова , завершающие и , завершающие , могут иметь общие характеристики друг с другом, но в некоторых отношениях они все же различаются. Слово закончить предполагает заключительную стадию выполнения чего-либо, тогда как завершить предполагает достижение предела. Это может означать окончание предыдущей официальной встречи.
Согласно Куайну (1951), существует два вида синонимии: полная синонимия и частичная синонимия.Полной синонимией считаются слова, имеющие одинаковые смысловые компоненты. Говоря более конкретно, слова являются полными синонимами тогда и только тогда, когда они разделяют друг с другом все ингредиенты. По Куайну, такого рода синонимии не существует просто потому, что ее невозможно определить, а значения слов в одноязычных или многоязычных условиях постоянно меняются. Следовательно, слова могут иметь общее большинство составляющих друг с другом, но не все составляющие. Что касается частичной синонимии, то это когда слова разделяют большинство необходимых компонентов или составляющих.Например, слова , завершающие и , завершающие , могут иметь общие характеристики друг с другом, но в некоторых отношениях они все же различаются. Слово закончить предполагает заключительную стадию выполнения чего-либо, тогда как завершить предполагает достижение предела. Это может означать окончание предыдущей официальной встречи. Поскольку полной синонимии не существует в одноязычных условиях, не говоря уже о разных языках, упор делается на частичную синонимию. Эта дихотомия между полной и частичной синонимией подлила масла в огонь при рассмотрении понятия эквивалентности в переводе или того, является ли перевод формой синонимии.
Поскольку полной синонимии не существует в одноязычных условиях, не говоря уже о разных языках, упор делается на частичную синонимию. Эта дихотомия между полной и частичной синонимией подлила масла в огонь при рассмотрении понятия эквивалентности в переводе или того, является ли перевод формой синонимии.
Основываясь на приведенном выше обсуждении, я считаю, что существует явная путаница в отношении того, что представляет собой синонимия. То есть некоторые рассматривают синонимию как слова, имеющие несколько общих характеристик друг с другом (Нида 1969: 73). Другие предполагают, что это рассматривается как форма частичной синонимии (Edmonds and Hirst 2002:107). Я хотел бы предложить здесь, чтобы быть разумным и ясным, синонимию следует классифицировать следующим образом:
Рисунок (1)
Классификация синонимов
Приведенная выше диаграмма показывает, что для того, чтобы два слова были синонимами, они должны быть идентичными и иметь общие основные компоненты и, таким образом, могут использоваться для замены друг друга во всех контекстах без какой-либо заметной разницы в их значениях. Такого рода синонимии, несомненно, не существует между двумя текстовыми версиями одного и того же языка или исходными текстами, не говоря уже о текстах на разных языках.
Такого рода синонимии, несомненно, не существует между двумя текстовыми версиями одного и того же языка или исходными текстами, не говоря уже о текстах на разных языках.
Отправной точкой здесь является предположение, что перевод не является формой синонимии просто потому, что слова могут иметь семантические значения, непереводимые на другие языки. Например, хотя такие слова, как ложь, ложь , неправда , выдумка и искажение фактов , могут использоваться для замены друг друга в большинстве контекстов одного и того же языка, они не могут использоваться для замены друг друга во всех контекстах. контексты.Согласно Эдмондсу и Херсту (2002: 107), они считаются близкими или частичными синонимами. Объяснение дается Эдмондсом и Херстом следующим образом:
Действительно, почти синонимы широко распространены в языке; примеры легко найти. Ложь , ложь , неправда , выдумка и искажение фактов , например, являются почти синонимами друг друга. Все они обозначают утверждение, которое не соответствует истине, но они отличаются друг от друга тонкими аспектами своего значения.Ложь есть преднамеренная попытка ввести в заблуждение, которая является прямым противоречием истине, тогда как искажение может быть более косвенным, как из-за неправильной расстановки акцентов, неправда может быть сказана просто по незнанию, а выдумка является преднамеренным, но относительно тривиальным, возможно, ему говорят, чтобы спасти свое или чье-то лицо (Gove 1984). Слова также различаются стилистически; выдумка — неформальный, детский термин, тогда как ложь — вполне формальный, а неправда может использоваться эвфемистически, чтобы избежать некоторых уничижительных значений некоторых других терминов .
Все они обозначают утверждение, которое не соответствует истине, но они отличаются друг от друга тонкими аспектами своего значения.Ложь есть преднамеренная попытка ввести в заблуждение, которая является прямым противоречием истине, тогда как искажение может быть более косвенным, как из-за неправильной расстановки акцентов, неправда может быть сказана просто по незнанию, а выдумка является преднамеренным, но относительно тривиальным, возможно, ему говорят, чтобы спасти свое или чье-то лицо (Gove 1984). Слова также различаются стилистически; выдумка — неформальный, детский термин, тогда как ложь — вполне формальный, а неправда может использоваться эвфемистически, чтобы избежать некоторых уничижительных значений некоторых других терминов .
С другой стороны, арабские слова hisaan , faras , jawaad , agarr обозначают английское слово лошадь. Хотя эти слова взаимозаменяемы в большинстве контекстов (поскольку все они относятся к слову лошадь ), они не являются взаимозаменяемыми во всех контекстах . Если мы возьмем слова для лошадь , мы можем найти следующие значения, которые являются синонимами и используются в контексте, связанном с этим словом:
Если мы возьмем слова для лошадь , мы можем найти следующие значения, которые являются синонимами и используются в контексте, связанном с этим словом:
- Слово hisaan имеет компоненты лошадь и мужчина .
- Слово фарас состоит из компонентов лошадь и мужчина или женщина .
- Слово джавад состоит из компонентов конкретная лошадь , то есть быстрая , самец или самка .
- Слово agarr состоит из компонентов конкретной лошади , у которой белое пятно на лбу и кобель или самка .
Форма множественного числа любой из этих форм — khayl (лошади), хотя (1) и (2) могут иметь различные формы множественного числа как hisaan/ahsina и faras как furus / afraas , соответственно. Вышеуказанные слова-синонимы имеют более одного общего семантического компонента. Все они имеют компонент лошадь и самец и самка компоненты . Только (1) имеет только компонент «папа» , тогда как (2) и (4) имеют общий компонент «папа» или «мама». Мы также можем обнаружить, что (1) и (2) не имеют отличительных качеств, как лошадей , за исключением упомянутых компонентов. Однако (3) характеризуется проворным движением и резвостью и (4) особым белым пятном на лбу, которое естественно контрастирует с общей темной окраской лошади. Как переводчик может передать эти слова в переводе с их общим значением на другой язык без какой-либо потери или приобретения смысла? Это область, в которой необходимо провести дополнительные исследования.
Все они имеют компонент лошадь и самец и самка компоненты . Только (1) имеет только компонент «папа» , тогда как (2) и (4) имеют общий компонент «папа» или «мама». Мы также можем обнаружить, что (1) и (2) не имеют отличительных качеств, как лошадей , за исключением упомянутых компонентов. Однако (3) характеризуется проворным движением и резвостью и (4) особым белым пятном на лбу, которое естественно контрастирует с общей темной окраской лошади. Как переводчик может передать эти слова в переводе с их общим значением на другой язык без какой-либо потери или приобретения смысла? Это область, в которой необходимо провести дополнительные исследования.
В действительности, однако, (1) и (2) могут использоваться для замены друг друга, не создавая серьезных синтаксических или семантических трудностей. Я полагаю, что переводчики без труда переведут любую из этих двух форм на английский язык как horse , поскольку слова обозначают вид и пол. Хотя (3) обозначает скаковую лошадь , также может использоваться для обозначения лошади в общем смысле, с некоторой потерей смысла в его ассоциативном значении, то есть быстрая лошадь .Что касается слова в (4), переводчики должны пояснить, переводя значение этого слова на английский язык как лошадь , что оно обозначает лошадь определенного цвета . Если переводчики хотят быть более верными тексту (SL), они могут прибегнуть к парафразу, и в этом случае слово джавад может быть переведено как скаковая лошадь , а агарр как лошадь с белым пятном. на лбу. Если согласиться с Нидой в том, что, имея дело с синонимичными словами, мы должны смотреть на различные составные черты значений этих синонимов и «выбирать только те значения, которые конкурируют в одних и тех же семантических полях» (Нида 1969: 64), то мы можем быть уверены, что арабские слова, обозначающие лошадей и , упомянутые выше, являются близкими синонимами.
Хотя (3) обозначает скаковую лошадь , также может использоваться для обозначения лошади в общем смысле, с некоторой потерей смысла в его ассоциативном значении, то есть быстрая лошадь .Что касается слова в (4), переводчики должны пояснить, переводя значение этого слова на английский язык как лошадь , что оно обозначает лошадь определенного цвета . Если переводчики хотят быть более верными тексту (SL), они могут прибегнуть к парафразу, и в этом случае слово джавад может быть переведено как скаковая лошадь , а агарр как лошадь с белым пятном. на лбу. Если согласиться с Нидой в том, что, имея дело с синонимичными словами, мы должны смотреть на различные составные черты значений этих синонимов и «выбирать только те значения, которые конкурируют в одних и тех же семантических полях» (Нида 1969: 64), то мы можем быть уверены, что арабские слова, обозначающие лошадей и , упомянутые выше, являются близкими синонимами. Такие слова показывают определенные перекрывающиеся области значений, которые «конкурируют в одном и том же семантическом поле».
Такие слова показывают определенные перекрывающиеся области значений, которые «конкурируют в одном и том же семантическом поле».
Кроме того, арабские слова, такие как sayf, muhannad, husaam, среди других слов или выражений, обозначают английское слово меч . Слово сайф является нейтральным словом, обозначающим английское слово меч . Хотя слова муханнад и хусаам имеют все характеристики слова меч , они имеют дополнительные характеристики.Например, слово muhannad относится к мечу в ножнах или ножнах, футляре, указывающем на то, что меч еще не использовался. Слово husaam относится к остроконечному или острому мечу. Это также предполагает значения прямолинейности или прямоты. Нейтральное арабское слово сайф не имеет таких коннотаций. Теперь вопрос заключается в том, могут ли эти слова использоваться для замены друг друга во всех контекстах без какой-либо потери или приобретения смысла. Другими словами, все ли эти синонимы взаимозаменяемы во всех контекстах?
С лингвистической точки зрения Нида (1969: 73) определяет синонимию в языке как «слова, которые имеют несколько общих (но не все) существенных компонентов и, таким образом, могут использоваться для замены друг друга в некоторых (но не во всех) контекстах без какой-либо заметной разницы». значения в этих контекстах, e.грамм. нравится , а нравится . Питер Ньюмарк (1981: 101) занимает позицию, аналогичную позиции Ниды, очень четко заявляя: «Я не одобряю положение о том, что перевод является формой синонимии». Сьюзан Басснетт-Макгуайр более подробно объясняет синонимию и связанные с ней сложности. Она указывает, что даже кажущаяся синонимия не дает эквивалентности, «поэтому словарь так называемых синонимов может дать слово совершенное как синоним идеальное или транспортное средство как синоним транспортное средство , но ни в том, ни в другом случае можно ли говорить о полной эквивалентности, поскольку каждая единица содержит в себе набор непереводимых ассоциаций и коннотаций» (Bassnett-McGuire 1980: 15).Кроме того, Басснетт-Макгуайр (1980:29) утверждает, что «эквивалентность в переводе не следует рассматривать как поиск тождества, поскольку тождество не может существовать даже между двумя (ПЯ) версиями одного и того же текста, не говоря уже о (ПЯ) и ПЯ.
значения в этих контекстах, e.грамм. нравится , а нравится . Питер Ньюмарк (1981: 101) занимает позицию, аналогичную позиции Ниды, очень четко заявляя: «Я не одобряю положение о том, что перевод является формой синонимии». Сьюзан Басснетт-Макгуайр более подробно объясняет синонимию и связанные с ней сложности. Она указывает, что даже кажущаяся синонимия не дает эквивалентности, «поэтому словарь так называемых синонимов может дать слово совершенное как синоним идеальное или транспортное средство как синоним транспортное средство , но ни в том, ни в другом случае можно ли говорить о полной эквивалентности, поскольку каждая единица содержит в себе набор непереводимых ассоциаций и коннотаций» (Bassnett-McGuire 1980: 15).Кроме того, Басснетт-Макгуайр (1980:29) утверждает, что «эквивалентность в переводе не следует рассматривать как поиск тождества, поскольку тождество не может существовать даже между двумя (ПЯ) версиями одного и того же текста, не говоря уже о (ПЯ) и ПЯ. версии (TL)
версии (TL)
Анна Вежбицкая, с другой стороны, исследует проблему синонимии и переводимости, анализируя глубинные структуры языка с точки зрения того, что она называет семантическими примитивами . Обсуждая проблемы, связанные с переводом английских цветовых слов и терминологии родства на другие языки, она приходит к выводу, что высказывания на разных языках различаются не только по своей поверхностной, но и по глубинной структуре.Wierzbicka (1980: 67) утверждает, что «эти различные глубинные структуры всегда выразимы в языках, которые взаимно изоморфны; все они изоморфны универсальному языку, то есть языку семантических примитивов. предложений в разных языках (какими бы разными они ни были сами по себе) всегда взаимно переводимы».
Как указывалось ранее, синонимия не означает одинаковости, поскольку эта форма синонимии не существует в одноязычных или многоязычных условиях.Синонимия может быть описана с точки зрения точной замены и взаимозаменяемости. То есть слова могут быть описаны как синонимы тогда и только тогда, когда они заменяют друг друга во всех контекстах без каких-либо изменений ни в когнитивном, ни в эмоциональном значении.
То есть слова могут быть описаны как синонимы тогда и только тогда, когда они заменяют друг друга во всех контекстах без каких-либо изменений ни в когнитивном, ни в эмоциональном значении.
Кроме того, эквивалентность может рассматриваться как подходящий критерий, который оказывается адекватной формой перевода. Под эквивалентностью здесь понимается тот факт, что каждая языковая единица (ниже уровня предложения) имеет характерное распределение.Если две (или более) единицы встречаются в одном и том же диапазоне контекстов, они должны быть эквивалентны в распределении (или иметь одинаковое распределение). Однако чрезвычайно важно убедиться, что эти две эквивалентные лексические единицы являются синонимами тогда и только тогда, когда значение не меняется в пределах всего текста.
Басснетт-Макгуайр, С. (1980). Переводоведение . Нью-Йорк: Methuen & Co. Ltd.
Cruse, DA (1986). Лексическая семантика . Кембридж: Издательство Кембриджского университета.
Эдмондс, О.П. и Херст, Г. (2002). «Околосинонимия и лексический выбор». Компьютерная лингвистика , том 28, номер 2: 105-144.
Гоув, Филип Б., редактор. (1984). Новый словарь синонимов Вебстера . Мерриам-Вебстер, Спрингфилд, Массачусетс.
Лайонс, Дж. (1995). Лингвистическая семантика. Введение. Кембридж: Издательство Кембриджского университета.
Мерриам-Вебстер (1984). Новый словарь синонимов Вебстера; Словарь различаемых синонимов с антонимами и аналогичными и контрастными словами . Спрингфилд, Массачусетс, США: Merriam-Webster.
Нида, Э. и Табер, К. (1969). Теория и практика перевода. Нидерланды: Э.Дж. Брилл.
Ньюмарк, П. (1981). Подходы к переводу . Оксфорд: пергамон.
Куайн, Западная В.О. (1951). «Две догмы эмпиризма». Философское обозрение , 60: 20-43.
Вежбицкая, Анна (1980). Lingua Mentalis: семантика естественного языка . Сидней/Нью-Йорк: Academic Press.
Что является примером лексического определения?
Лексикография: определение и история
Лексикография — это практика создания словарей и других типов справочных текстов.Изучите историю этой практики и важных деятелей, участвовавших в составлении коллекций, которые у нас есть сегодня.
Использование справочных материалов для словарного запаса
Справочные материалы — это наборы списков слов, которые помогают описывать и объяснять мир. Узнайте, как словари, глоссарии и тезаурусы могут помочь расширить словарный запас, а также другие надежные примеры справочного материала.
Узнайте, как словари, глоссарии и тезаурусы могут помочь расширить словарный запас, а также другие надежные примеры справочного материала.
Как учить словарный запас
Студенты могут не понимать, что они читают, если у них нет богатого словарного запаса.Узнайте, как учить словарные слова с помощью таких методов, как построение словарного запаса, стены слов, карты слов, карточки для запоминания и бинго.
Прислушиваться к цели и функции
Выступая с речью, также важно слушать. Поймите, почему, узнав о том, как слушать для целей и функций, а затем просмотрите примеры вопросов, чтобы лучше понять.
Поймите, почему, узнав о том, как слушать для целей и функций, а затем просмотрите примеры вопросов, чтобы лучше понять.
Использование словарей и глоссариев: урок для детей
Словари и глоссарии можно использовать, чтобы найти значение неизвестных слов или терминов.Узнайте о различиях и сходствах между глоссариями и словарями, о том, как в них расположены слова, и о примерах того, как каждый из них представляет информацию.
Техника росписи по ткани
Вы когда-нибудь хотели украсить футболку или добавить красочный рисунок к джинсам? Знаете ли вы, что есть много способов рисовать на ткани? В этом уроке изучите основы техники росписи по ткани.
Психометрия: определения и примеры тестов
Психометрия — это область изучения психологии, которая использует объективное тестирование для измерения психологических качеств.Одной из самых известных форм психометрии является тест IQ. Изучите область психометрии, узнайте ее определение и узнайте, какое отношение валидность, надежность и нормирование имеют к разработке психометрических тестов.
Индивидуальная инструкция: определение и пример
Цель индивидуального обучения состоит в том, чтобы удовлетворить потребности каждого отдельного учащегося. Изучите определение и примеры этого метода, изучите тех, кто должен его получить, как разработать цели, хорошие стратегии использования и его связь с дифференцированным обучением.
Изучите определение и примеры этого метода, изучите тех, кто должен его получить, как разработать цели, хорошие стратегии использования и его связь с дифференцированным обучением.
Организация и классификация идей, концепций и информации
Написание статьи — сложная задача.На этом уроке вы узнаете, как определить тип статьи, которую нужно написать, а затем выполните шаги по организации и категоризации идей статьи, изучению концепций и передаче информации.
Расширение учебной программы: определение и ресурсы
Обогащение учебной программы дает продвинутым учащимся возможность расширить свои знания материала, который они уже изучили. Узнайте о различных возможностях обогащения учебного плана, которые предлагает продвинутым учащимся, и о ресурсах, которые современные классы могут использовать для их предоставления.
Узнайте о различных возможностях обогащения учебного плана, которые предлагает продвинутым учащимся, и о ресурсах, которые современные классы могут использовать для их предоставления.
Как использовать машинное обучение для поиска синонимов | by Nikhil Dandekar
Большинство методов генерации синонимов , которые я видел на веб-сайтах/приложениях для пользователей, решают эту задачу в два этапа:
1. Генерация кандидатов
вы создаете всех возможных кандидатов, которые могут быть синонимами слова.
Обратите внимание, что то, что вы подразумеваете под «синонимами», обычно сильно меняется в зависимости от домена. Если вы пишете текстовый процессор, вам, вероятно, нужно что-то более близкое к словарному определению синонима. Для поисковой системы ваше определение синонимов может быть намного шире и включать любые альтернативные слова, которые помогут вам получить лучшие результаты поиска по вашему запросу. Например. Расширения акронимов (CS -> «информатика»), синонимы имен собственных («большое яблоко» -> «Нью-Йорк») или даже замена целых фраз — хорошие «синонимы» для поисковой системы.
Например. Расширения акронимов (CS -> «информатика»), синонимы имен собственных («большое яблоко» -> «Нью-Йорк») или даже замена целых фраз — хорошие «синонимы» для поисковой системы.
В зависимости от вашего конкретного приложения, вот некоторые из источников, которые вы можете использовать для генерации синонимов:
- Вложения слов: Вы можете обучать векторы слов для своего корпуса, а затем находить синонимы для текущего слова, используя ближайших соседей или путем определения некоторого понятия «подобие». Подробнее об этом читайте здесь: Какие родственные слова выводит Word2Vec?
- Исторические данные о пользователях: Вы также можете просмотреть историю поведения пользователей и создать на их основе синонимы-кандидаты.Простой способ сделать это для поисковых систем — просмотреть замены слов и фраз по шаблону «запрос, запрос, щелчок». Таким образом, если вы видите, что пользователи ищут [купить сумочки], ничего не нажимая, а затем ищут [купить кошельки] и нажимают на результат, вы можете рассматривать «кошельки» в качестве кандидата на синоним «сумочки».
 Простая версия игнорирует контекст (в данном случае предыдущее слово — «купить»), но для получения более точных синонимов вы хотите использовать в качестве контекста предыдущее и следующее n слов.Для текстовых процессоров вы можете аналогичным образом посмотреть на замены слов и фраз, которые делают ваши пользователи.
Простая версия игнорирует контекст (в данном случае предыдущее слово — «купить»), но для получения более точных синонимов вы хотите использовать в качестве контекста предыдущее и следующее n слов.Для текстовых процессоров вы можете аналогичным образом посмотреть на замены слов и фраз, которые делают ваши пользователи. - Лексические синонимы: Это грамматические синонимы, определенные правилами языка. Wordnet является популярным источником для них среди других.
Если существуют другие источники синонимов помимо этих, которые лучше подходят для вашего приложения, вы также должны использовать их.
Вы можете использовать любой из этих методов по отдельности для решения вашей проблемы. Например.вам может быть достаточно алгоритма генерации синонимов с использованием только векторов word2vec. Но, используя только один источник, вы упустите сильные стороны, которые предлагают другие источники.
2. Обнаружение синонимов
Теперь, когда у вас есть набор синонимов-кандидатов для данного слова, вам нужно выяснить, какие из них на самом деле являются синонимами. Это может быть решено как классическая задача обучения с учителем .
Это может быть решено как классическая задача обучения с учителем .
Имея набор кандидатов, вы можете генерировать достоверные обучающие данные либо с помощью судей-людей, либо с привлечением пользователей в прошлом.Как я упоминал выше, определения синонимов различаются для разных приложений, поэтому, если вы используете судей-людей, вам нужно будет придумать четкие рекомендации о том, что делает синоним хорошим для них.
Когда у вас есть размеченный обучающий набор, вы можете создавать различные лексические и статистические функции для своих данных и обучать на нем контролируемую модель машинного обучения по вашему выбору. На практике я видел, что любые функции, связанные с прошлым поведением пользователя, такие как частота замены слов, лучше всего подходят для обнаружения синонимов в определенных доменах, таких как поисковые системы.
Генерация антонимов
Вы можете найти антонимы, используя ту же технику, что и синонимы.
