Урок 6. единицы измерения информации — Информатика — 7 класс
Информатика
7 класс
Урок № 6
Единицы измерения информации
Перечень вопросов, рассматриваемых в теме:
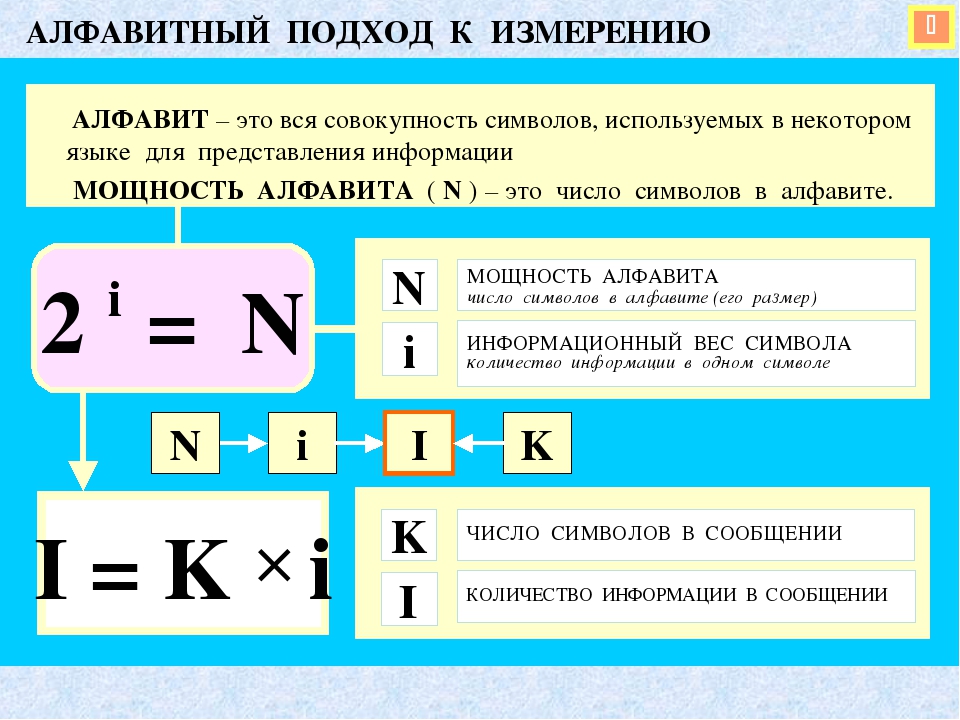
- Алфавитный подход к измерению информации.
- Наименьшая единица измерения информации.
- Информационный вес одного символа алфавита и информационный объём всего сообщения.
- Единицы измерения информации.
- Задачи по теме урока.
Тезаурус:
Каждый символ информационного сообщения несёт фиксированное количество информации.
Единицей измерения количества информации является бит – это наименьшаяединица.
1 байт = 8 бит
1 Кб (килобайт) = 1024 байта= 210байтов
1 Мб (мегабайт) = 1024 Кб = 210Кб
1 Гб (гигабайт) = 1024 Мб = 210 Мб
1 Тб (терабайт) =1024 Гб = 210 Гб
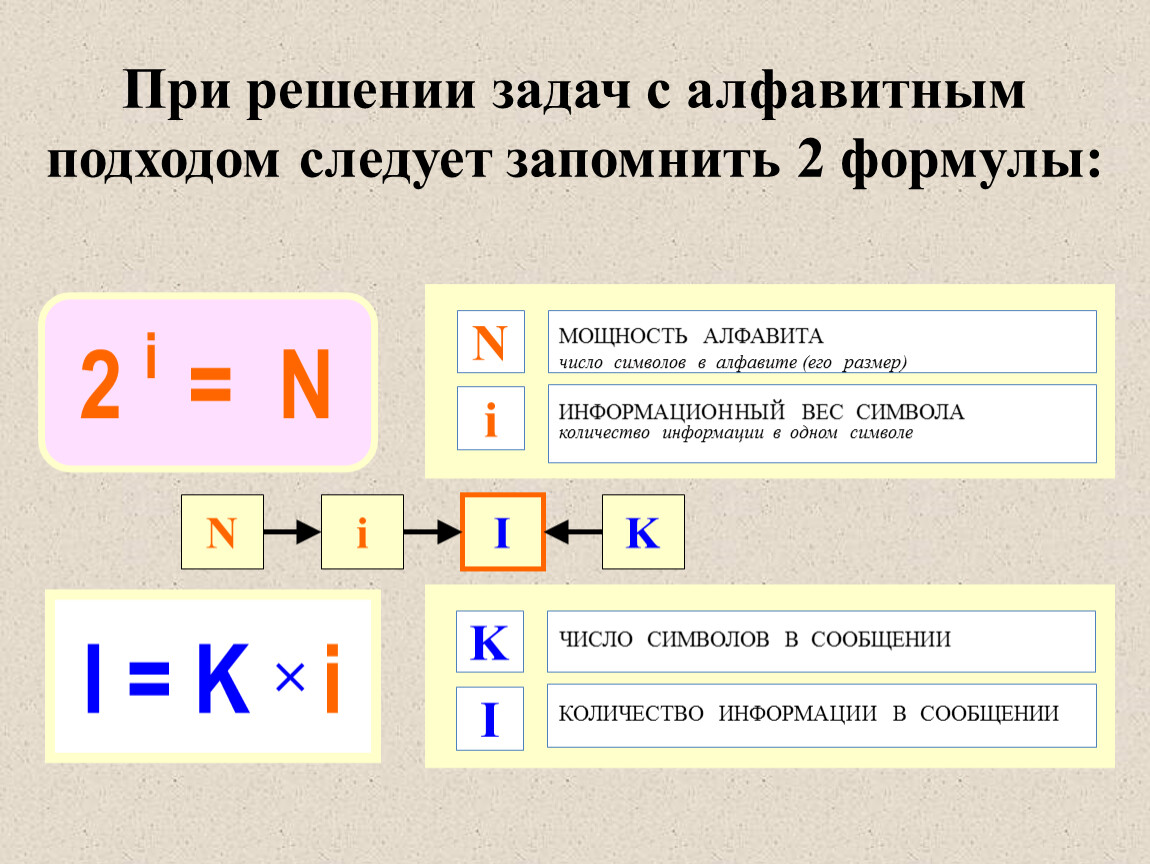
Формулы, которые используются при решении типовых задач:
Информационный вес символа алфавита и мощность алфавита связаны между собой соотношением:

Информационный объём сообщения определяется по формуле:
I = К · i,
I – объём информации в сообщении;
К – количество символов в сообщении;
i – информационный вес одного символа.
Основная литература:
- Босова Л. Л. Информатика: 7 класс. // Босова Л. Л., Босова А. Ю. – М.: БИНОМ, 2017. – 226 с.
Дополнительная литература:
- Босова Л. Л. Информатика: 7–9 классы. Методическое пособие. // Босова Л. Л., Босова А. Ю., Анатольев А. В., Аквилянов Н.А. – М.: БИНОМ, 2019. – 512 с.
- Босова Л. Л. Информатика. Рабочая тетрадь для 7 класса. Ч 1. // Босова Л. Л., Босова А. Ю. – М.: БИНОМ, 2019. – 160 с.
- Босова Л. Л. Информатика. Рабочая тетрадь для 7 класса. Ч 2. // Босова Л. Л., Босова А. Ю. – М.: БИНОМ, 2019. – 160 с.
- Гейн А. Г. Информатика: 7 класс. // Гейн А. Г., Юнерман Н. А., Гейн А.А. – М.: Просвещение, 2012. – 198 с.
Теоретический материал для самостоятельного изучения.
Любое сообщение несёт некоторое количество информации. Как же его измерить?
Одним из способов измерения информации является алфавитный подход, который говорит о том, что каждый символ любого сообщения имеет определённый информационный вес, то есть несёт фиксированное количество информации.
Сегодня на уроке мы узнаем, чему равен информационный вес одного символа и научимся определять информационный объём сообщения.
Что же такое символ в компьютере? Символом в компьютере является любая буква, цифра, знак препинания, специальный символ и прочее, что можно ввести с помощью клавиатуры. Но компьютер не понимает человеческий язык, он каждый символ кодирует. Вся информация в компьютере представляется в виде нулей и единичек. И вот эти нули и единички называются битом.
Информационный вес символа двоичного алфавита принят за минимальную единицу измерения информации и называется один бит.
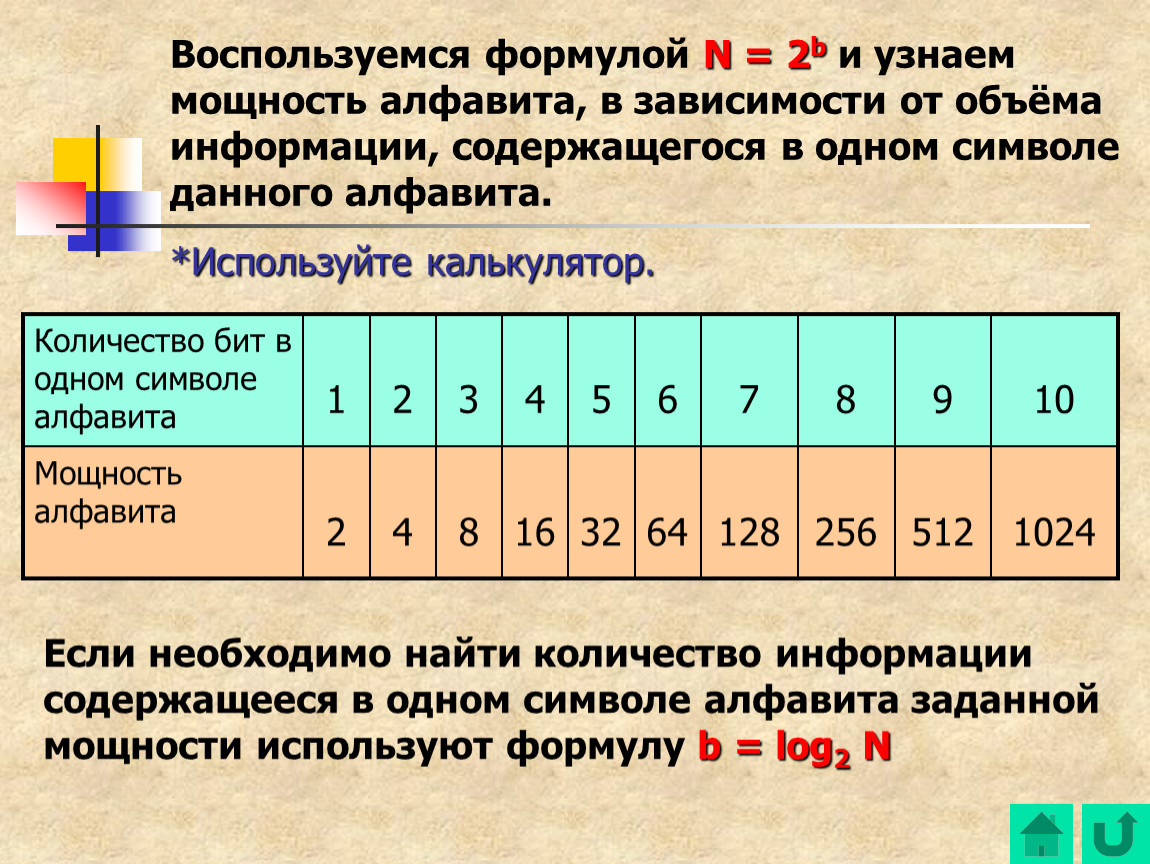
Алфавит любого понятного нам языка можно заменить двоичным алфавитом. При этом мощность исходного алфавита связана с разрядностью двоичного кода соотношением: N = 2i.
При этом мощность исходного алфавита связана с разрядностью двоичного кода соотношением: N = 2i.
Эту формулу можно применять для вычисления информационного веса одного символа любого произвольного алфавита.
Рассмотрим пример:
Алфавит древнего племени содержит 16 символов. Определите информационный вес одного символа этого алфавита.
Составим краткую запись условия задачи и решим её:
Дано:
N=16, i = ?
Решение:
N = 2i
16 = 2i, 24 = 2i, т. е. i = 4
Ответ: i = 4 бита.
Информационный вес одного символа этого алфавита составляет 4 бита.
Сообщение состоит из множества символов, каждый из которых имеет свой информационный вес. Поэтому, чтобы вычислить объём информации всего сообщения, нужно количество символов, имеющихся в сообщении, умножить на информационный вес одного символа.
Математически это произведение записывается так: I = К · i.
Например: сообщение, записанное буквами 32-символьного алфавита, содержит 180 символов. Какое количество информации оно несёт?
Какое количество информации оно несёт?
Дано:
N = 32,
K = 180,
I= ?
Решение:
I = К · i,
N = 2i
32 = 2i, 25 = 2 i, т.о. i = 5,
I = 180 · 5 = 900 бит.
Ответ: I = 900 бит.
Итак, информационный вес всего сообщения равен 900 бит.
В алфавитном подходе не учитывается содержание самого сообщения. Чтобы вычислить объём содержания в сообщении, нужно знать количество символов в сообщении, информационный вес одного символа и мощность алфавита. То есть, чтобы определить информационный вес сообщения: «
I = 23 · 8 = 184 бита.
Значит, сообщение весит 184 бита.
Как и в математике, в информатике тоже есть кратные единицы измерения информации. Так, величина равная восьми битам, называется байтом.
Бит и байт – это мелкие единицы измерения. На практике для измерения информационных объёмов используют более крупные единицы: килобайт, мегабайт, гигабайт и другие.
1 байт = 8 бит
1 Кб (килобайт) = 1024 байта= 210байтов
1 Мб (мегабайт) = 1024 Кб = 210Кб
1 Гб (гигабайт) = 1024 Мб = 210 Мб
1 Тб (терабайт) =1024 Гб = 210 Гб
Итак, сегодня мы узнали, что собой представляет алфавитный подход к измерению информации, выяснили, в каких единицах измеряется информация и научились определять информационный вес одного символа и информационный объём сообщения.
Материал для углубленного изучения темы.
Как текстовая информация выглядит в памяти компьютера.
Набирая текст на клавиатуре, мы видим привычные для нас знаки (цифры, буквы и т.д.). В оперативную память компьютера они попадают только в виде двоичного кода. Двоичный код каждого символа, выглядит восьмизначным числом, например 00111111. Теперь возникает вопрос, какой именно восьмизначный двоичный код поставить в соответствие каждому символу?
Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот код ‑ просто порядковый номер символа в двоичной системе счисления.
Каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот код ‑ просто порядковый номер символа в двоичной системе счисления.
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки.Таблица для кодировки – это «шпаргалка», в которой указаны символы алфавита в соответствии порядковому номеру. Для разных типов компьютеров используются различные таблицы кодировки.
Таблица ASCII (или Аски), стала международным стандартом для персональных компьютеров. Она имеет две части.
В этой таблице латинские буквы (прописные и строчные) располагаются в алфавитном порядке. Расположение цифр также упорядочено по возрастанию значений. Это правило соблюдается и в других таблицах кодировки и называется принципом последовательного кодирования алфавитов. Благодаря этому понятие «алфавитный порядок» сохраняется и в машинном представлении символьной информации. Для русского алфавита принцип последовательного кодирования соблюдается не всегда.
Запишем, например, внутреннее представление слова «file». В памяти компьютера оно займет 4 байта со следующим содержанием:
01100110 01101001 01101100 01100101.
А теперь попробуем решить обратную задачу. Какое слово записано следующим двоичным кодом:
01100100 01101001 01110011 01101011?
В таблице 2 приведен один из вариантов второй половины кодовой таблицы АSСII, который называется альтернативной кодировкой. Видно, что в ней для букв русского алфавита соблюдается принцип последовательного кодирования.
Вывод: все тексты вводятся в память компьютера с помощью клавиатуры. На клавишах написаны привычные для нас буквы, цифры, знаки препинания и другие символы. В оперативную память они попадают в форме двоичного кода.
Из памяти же компьютера текст может быть выведен на экран или на печать в символьной форме.
Сейчас используют целых
пять систем кодировок русского алфавита (КОИ8-Р, Windows, MS-DOS, Macintosh и ISO). Из-за количества систем кодировок и отсутствия одного стандарта, очень часто возникают недоразумения с переносом русского текста в компьютерный его вид. Поэтому, всегда нужно уточнять, какая система кодирования установлена на компьютере.
Поэтому, всегда нужно уточнять, какая система кодирования установлена на компьютере. Разбор решения заданий тренировочного модуля
№1. Определите информационный вес символа в сообщении, если мощность алфавита равна 32?
Варианты ответов:
3
5
9
Решение:
Информационный вес символа алфавита и мощность алфавита связаны между собой соотношением: N = 2i.
32 = 2i, 32 – это 25, следовательно, i =5 битов.
Ответ: 5 битов.
№2. Выразите в килобайтах 216 байтов.
Решение:
216 можно представить как 26 · 210.
26 = 64, а 210 байт – это 1 Кб. Значит, 64 · 1 = 64 Кб.
Ответ: 64 Кб.
№3. Тип задания: выделение цветом
8х = 32 Кб, найдите х.
Варианты ответов:
3
4
5
6
Решение:
8 можно представить как 23. А 32 Кб переведём в биты.
А 32 Кб переведём в биты.
Получаем 23х=32 · 1024 ·8.
Или 23х = 25 · 210 · 23
.23х = 218.
3х = 18, значит, х=6.
Ответ: 6.
Вычисление количества информации. Решение задач
Решение задачна вычисление количества информации
Для решения различных задач на определение количества информации вы должны
помнить следующее:
отношение количества вариантов (или чисел) N к количеству информации которую
несет в себе один из вариантов I: N=2I
полный информационный объем сообщения V равен количество символов в
сообщении K умноженное на количество информации на каждый символ I: V=K*I.
Формула Шеннона для равновероятных событий: I=log2N.
если алфавит имеет мощность ( количество символов в этом алфавите) М, то количество всех
возможных «слов» (символьных цепочек) длиной N (без учета смысла) равно K=MN; для
двоичного кодирования (мощность алфавита M –2 символа) получаем известную формулу: K=2N
1 байт = 8 бит
1 Кбайт = 210байт = 1024 байт
1 Мбайт = 210Кбайт = 1024 Кбайт
1 Гбайт = 210Мбайт = 1024 Мбайт
Световое табло состоит из лампочек. Каждая лампочка может находиться в
одном из трех состояний («включено», «выключено» или «мигает»).
Какое наименьшее количество лампочек должно находиться на табло,
чтобы с его помощью можно было передать 18 различных сигналов?
1) 6
2) 5
3) 3
4)4
Решение задачи №1.
K=MN
В данной задаче мощность алфавита равна 3 («включено»,
«выключено» или «мигает»), следовательно: M=3.
Количество необходимых сигналов R=18.
Найти надо К.
Следовательно:
18=3N,
N=3.
Ответ: 3.
Задача №2.
Метеорологическая станция ведет наблюдение за влажностью воздуха. Результатом одного
измерения является целое число от 0 до 100 процентов, которое записывается при помощи минимально
возможного количества бит. Станция сделала 80 измерений.
Определите информационный объем результатов наблюдений.
1) 80 бит
2) 70 байт
3) 80 байт
4) 560 байт
Решение задачи №2.

Определим информационный объем одного измерения: количество возможных вариантов
равно 100 (т.к. результатом одного измерения является целое число от 0 до100 процентов).
Следовательно, информационный объем одного варианта измерения находится по формуле:
N=2I
100=2I, I = 7 бит.
Так как станция сделала 80 измерений, следовательно, информационный объем результатов
наблюдений равен:
7*80=560 бит
Такого ответа нет, переведем биты в байты:
560 : 8=70 байт.
Ответ: 2.
Задача №3.
Сколько существует различных последовательностей из символов «плюс» и
«минус», длиной ровно в пять символов?
1) 64
2) 50
3) 32
4)20
Решение задачи №3.
K=MN
Мощность алфавита М — равна 2. Длина слова N — равна 5.
Количество различных последовательностей:
К=25,
К=32.
Ответ: 3.
Задача №4.
В корзине лежат 8 черных шаров и 24 белых шара.
Сколько бит информации несет сообщение о том, что достали черный шар?
1) 2 бита
2) 4 бита
3) 8 бит
4) 24бита
Решение задачи №4.
Черные шарики составляют 8/4 — 1/4 из всех шаров, следовательно информация о том что
достали черный шарик соответствует одному из 4 вариантов.
N=2I
1 из 4 вариантов несет в себе количество информации I — равное 2:
4=22.
Также можно решить данную задачу по формуле Шеннона: количество вариантов получения
черного шарика равна 4, следовательно, I=log24 = 2 бита.
Ответ: 2 бита.
Задача №5.
В коробке лежат 64 цветных карандаша. Сообщение о том, что достали белый карандаш,
несет 4 бита информации.
Сколько белых карандашей было в коробке?
1) 4
2) 8
3) 16
4)32
Решение задачи №5.
Данная задача похожа на задачу № 4, только нам надо определить количество карандашей по
известному количеству информации который несет один карандаш.
Определим количество возможных событий (вариантов получения белого карандаша) по формуле
Шеннона:
log2N=4,
следовательно,
N=16.
Количество возможных событий получения белого карандаша равно 16, следовательно, количество
белых карандашей составляет 1/16 всех карандашей.

Всего карандашей 64, следовательно белых карандашей
64/16=4.
Ответ: 4 белых карандаша.
Задача № 6.
В некоторой стране автомобильный номер длиной 5 символов составляется из заглавных
букв (всего используется 30 букв) и десятичных цифр в любом порядке. Каждый символ кодируется
одинаковым и минимально возможным количеством бит, а каждый номер – одинаковым и
минимально возможным количеством байт.
Определите объем памяти, необходимый для хранения 50 автомобильных номеров.
1) 100 байт
2) 150 байт
3) 200 байт
4)250 байт
Решение задачи № 6.
Количество символов используемых для кодирования номера составляет: 30 букв + 10 цифр = 40
символов. Количество информации несущий один символ равен 6 бит (2I=40, но количество информации
не может быть дробным числом, поэтому берем ближайшую степень двойки большую количества
символов 26=64).
Мы нашли количество информации заложенное в каждом символе, количество символов в
номере равно 5, следовательно 5*6=30 бит.
 Каждый номер равен 30 битам информации, но по условию
Каждый номер равен 30 битам информации, но по условиюзадачи каждый номер кодируется одинаковым и минимально возможным количеством байт,
следовательно нам необходимо узнать сколько байт в 30 битах. Если разделить 30 на 8 получится дробное
число, а нам необходимо найти целое количество байт на каждый номер, поэтому находим ближайший
множитель 8-ки который превысит количество бит, это 4 (8*4=32). Каждый номер кодируется 4 байтами.
Для хранения 50 автомобильных номеров потребуется: 4*50=200 байт.
Ответ: 200 байт.
Задача № 7.
Для регистрации на сайте некоторой страны пользователю необходимо придумать пароль
длиной ровно 11 символов. В пароле можно использовать десятичные цифры и 12 различных
символов местного алфавита, причем все буквы используются в двух начертаниях – строчные и
прописные. Каждый символ кодируется одинаковым и минимально возможным количеством бит, а
каждый пароль – одинаковым и минимально возможным количеством байт.
Определите объем памяти, необходимый для хранения 60 паролей.
1) 720 байт
2) 660 байт
3) 540 байт
4)600 байт
Решение задачи № 7.
Количество символов используемых для кодирования пароля составляет: 10 цифр + 12
строчных букв + 12 прописных букв = 34 символа. Количество информации несущий один символ равен
6 бит (2I=34, но количество информации не может быть дробным числом, поэтому берем ближайшую
степень двойки большую количества символов 26=64).
Мы нашли количество информации заложенное в каждом символе, количество символов в
пароле равно 11, следовательно 11*6=66 бит. Каждый пароль равен 66 битам информации, но по условию
задачи каждый пароль кодируется одинаковым и минимально возможным количеством байт,
следовательно нам необходимо узнать сколько байт в 66 битах. Если разделить 66 на 8 получится
дробное число, а нам необходимо найти целое количество байт на каждый пароль, поэтому находим
ближайший множитель 8-ки который превысит количество бит, это 9 (8*9=72).
 Каждый номер
Каждый номеркодируется 9 байтами.
Для хранения 60 паролей потребуется: 9*60=540 байт.
Ответ: 540 байт.
Нахождение информационного объема
Практическое занятие № 2
Нахождение информационного объема
Количество часов на выполнение: 2часа
Цель работы: изучение алфавитного подхода к измерению информации;
закрепление навыков перевода одних единиц количества информации в другие.
Задание: решить задачи
Методика выполнения задания:
1. Ознакомится с теоритическим материалом
2. Ознакомится с задачами
3. Решить задачи по разобранному примеру
4. Ответить на вопросы
Теоретический материал:
При
алфавитном подходе к определению количества информации отвлекаются от содержания
информации и рассматривают информационное сообщение как последовательность
знаков определенной знаковой системы. При алфавитном подходе к измерению
информации количество информации зависит не от содержания, а от размера текста
и мощности алфавита.
Единицы измерения информации.
В 1 бит можно записать один двоичный символ.
1 байт = 8 бит.
В кодировке ASCII в один байт можно записать один 256 символьный код.
В кодировке UNICODE один 256 символьный код занимает в памяти два байта.
1 килобайт = 1024 байт
1 мегабайт = 1024 килобайт
1 гигабайт = 1024 мегабайт
1 терабайт = 1024 гигабайт
Важно помнить следующее правило: при переводе меньших единиц в большие единицы, необходимо делить, а при переводе больших единиц в меньшие необходимо умножать.
Формула Хартли 2 i = N где i– количество информации в битах, N – неопределенность
Таблица степеней двойки, которая показывает сколько информации можно закодировать с помощью i – бит
i 0 1 2 3 4 5 6 7 8 9 10
N=2 i 1 2 4 8 16 32 64 128 256 512 1024
Чтобы вычислить информационный объем сообщения надо количество символов умножить на число бит, которое требуется для хранения одного символа
Мощность
алфавита – это количество символов в алфавите или неопределенность из
формулы Хартли.
Информационный вес одного символа – это значение i из формулы Хартли.
Информационный объем сообщения – это количество символов (равно количеству байтов).
Методика выполнения задания:
1. Прочтите теоретические основы по данной теме
2. Посмотреть примеры решения задач
3. По аналогии выполнить задачи
Задача 1. Какое количество информации содержится в неинформационном сообщении?
Решение: N=0 => 2i=0 => i=«пустое множество»
Задача 2. Найти количество информации в однозначном сообщении.
Решение: N=1 => 2i=1 => i=0 бит
Задача 3. Измерить количество информации при ответе на вопрос: «Какие завтра намечаются осадки?»
Решение: N=4 => 2i=4 => i=2 бит
Задача 4. Какое количество информации потребуется для кодирования одного шахматного поля?
Решение: N=8*8=64 => 2i=64 => i=6 бит
Задача 5. Получено сообщение,
объемом 10 бит. Какое количество сообщений возможно составить из полученных
данных?
Получено сообщение,
объемом 10 бит. Какое количество сообщений возможно составить из полученных
данных?
Решение: i=10 => 210=1024 => N=1024 сообщения
Задача 6. Какое количество слов получится из фразы в 8 бит?
Решение: i=8 => 28=256 => N=256 слов
Задача 7. В корзине лежит 16 шаров разного цвета. Сколько информации несет сообщение, что достали белый шар?
Решение: N=16 => 2i=16 => i=4
Задача 8. Сообщение о том, что ваш друг живет на 6 этаже несет 4 бита информации. Сколько этажей в доме.
Решение: i=4 => 24=16 => N=16 этажей
Задача 9. За четверть ученик получил 100 оценок. Сообщение о том, что он получил четверку, несет 2 бита информации. Сколько четверок ученик получил за четверть?
Решение: i =2 =>
22=4 => N=4 отметки. Это очевидно. Отметки «2», «3»,
«4», «5». Всего получено 100 отметок, а вот сколько из них четверок, не понятно
даже ёжику.
Это очевидно. Отметки «2», «3»,
«4», «5». Всего получено 100 отметок, а вот сколько из них четверок, не понятно
даже ёжику.
Примеры решения задач на тему «Алфавитный подход к измерению информации»
Задача 1. Для записи текста использовался 256-символьный алфавит. Каждая страница содержит 32 строки по 64 символа в строке. Какой объем информации содержат 5 страниц этого текста?
Решение: N=256, => 2i = 256, => i=8 bit
k=32*64*5 символов
I=i*k=8*32*64*5 bit = 8*32*64*5/8 b = 32*64*5/1024 kb = 10 kb
Задача 2. Можно ли уместить на одну дискету книгу, имеющую 432 страницы, причем на каждой странице этой книги 46 строк, а в каждой строке 62 символа?
Решение: Т.к. речь идет о книге, напечатанной в электронном виде, то мы имеем дело с компьютерным языком. Тогда N=256, => 2i = 256, => i=8 bit
k = 46*62*432 символов
I = i*k = 8*46*62*432 bit = 8*46*62*432/8 b = 46*62*432/1024 kb = 1203,1875 kb = 1,17 Mb
Т. к. объем дискеты 1,44 Mb, а объем книги
1,17 Mb, то она на
дискету уместится.
к. объем дискеты 1,44 Mb, а объем книги
1,17 Mb, то она на
дискету уместится.
Задача 3. Скорость информационного потока – 20 бит/с. Сколько минут потребуется для передачи информации объемом в 10 килобайт.
Решение: t = I/v = 10 kb/ 20 бит/c = 10*1024 бит/ 20 бит/c = 512 c = 8,5 мин
Задача 4. Лазерный принтер печатает со скоростью в среднем 7 Кбит в секунду. Сколько времени понадобится для распечатки 12-ти страничного документа, если известно, что на одной странице в среднем по 45 строк, в строке 60 символов.
Решение: Т.к. речь идет о документе в электронном виде, готовым к печати на принтере, то мы имеем дело с компьютерным языком. Тогда N=256, => 2i = 256, => i=8 bit
K = 45*60*12 символов
I = i*k = 8*45*60*12 bit = 8*45*60*12/8 b = 45*60*12/1024 kb = 31,6 kb
t = I/v = 31,6 kb/ 7 Кбит/c = 31,6*8 kбит/ 7 Кбит/c = 36 c
Задача 5. Автоматическое
устройство осуществило перекодировку информационного сообщения на русском
языке, из кодировки Unicode, в кодировку КОИ-8. При этом информационное
сообщение уменьшилось на 480 бит. Какова длина сообщения?
При этом информационное
сообщение уменьшилось на 480 бит. Какова длина сообщения?
Решение: Объем 1 символа в кодировке КОИ-8 равен 1 байту, а в кодировке Unicode – 2 байтам.
Пусть x – длина сообщения, тогда IКОИ-8 = 1*x b, а IUnicode = 2*x b.
Получаем 2*x8 bит – 1*x*8 бит = 480 бит, 8x = 480, х = 60 символов в сообщении.
Задача 6. Найдите х, если 4х бит=32 Кбайт.
Решение: 4х бит = 32 Кбайт
4х бит = 32 * 1024 байт
4х бит = 32 * 1024 * 8 бит
22х бит = 25 * 210 * 23 бит
22х бит = 218 бит
2х = 18
Х = 9
Задачи для самостоятельного решения
Задача 1. Имеется 2 текста
на разных языках. Первый текст использует 32-символьный алфавит и содержит 200
символов, второй – 16-символьный алфавит и содержит 250 символов. Какой из
текстов содержит большее количество информации и на сколько бит?
Какой из
текстов содержит большее количество информации и на сколько бит?
Задача 2. За 45 секунд был распечатан текст. Подсчитать количество страниц в тексте, если известно, что в среднем на странице 5о строк по 75 символов в каждой, скорость печати лазерного принтера 8 Кбит/сек., 1 символ — 1 байт. Ответ округлить до целой части.
Задача 3. Найдите х, если 16х бит=128 Кбайт.?
Задача 4. Для записи сообщения использовался 64-х символьный алфавит. Каждая страница содержит 30 строк. Все сообщение содержит 8775 байтов информации и занимает 6 страниц. Сколько символов в строке?
Задача 5. ДНК человека (генетический код) можно представить себе как некоторое слово в четырехбуквенном алфавите, где каждой буквой помечается звено цепи ДНК (нуклеотид). Сколько информации в битах содержит цепочка ДНК человека, содержащая примерно 1,5×1023 нуклеотидов?
Задача 6. Сообщение,
записанное буквами 64-символьного алфавита, содержит 20 символов. Какой объем
информации оно несет?
Какой объем
информации оно несет?
Задача 7. Жители планеты Принтер используют алфавит из 256 знаков, а жители планеты Плоттер — из 128 знаков. Для жителей какой планеты сообщение из 10 знаков несет больше информации и на сколько?
Задача 8. Для кодирования нотной записи используется 7 значков-нот. Каждая нота кодируется одним и тем же минимально возможным количеством бит. Чему равен информационный объем сообщения, состоящего из 180 нот?
Задача 9. За четверть ученик получил 100 оценок. Сообщение о том, что он получил четверку, несет 2 бита информации. Сколько четверок ученик получил за четверть?
Задача 10 (ЕГЭ). В велокроссе участвуют 119 спортсменов. Специальное устройство регистрирует прохождение каждым из участников промежуточного финиша, записывая его номер с использованием минимально возможного количества бит, одинакового для каждого спортсмена. Каков информационный объем сообщения, записанного устройством, после того как промежуточный финиш прошли 70 велосипедистов?
Задача 11. Словарный запас
некоторого языка составляет 256 слов, каждое из которых состоит точно из 4
букв. Сколько букв в алфавите языка?
Словарный запас
некоторого языка составляет 256 слов, каждое из которых состоит точно из 4
букв. Сколько букв в алфавите языка?
Задача 12 (ЕГЭ). Сколько информации несет сообщение о том, что было угадано число в диапазоне целых чисел от 684 до 811?
Задача 13. В некоторой стране автомобильный номер длиной 7 символов составляется из заглавных букв (всего используется 26 букв) и десятичных цифр в любом порядке. Каждый символ кодируется одинаковым и минимально возможным количеством бит, а каждый номер – одинаковым и минимально возможным количеством байт. Определите объем памяти, необходимый для хранения 20 автомобильных номеров.
Задача 14. Каждая клетка
поля 8×8 кодируется минимально возможным и одинаковым количеством бит.
Решение задачи о прохождении ‘конем’ поля записывается последовательностью
кодов посещенных клеток . Каков объем информации после 11 сделанных ходов?
(Запись решения начинается с начальной позиции коня).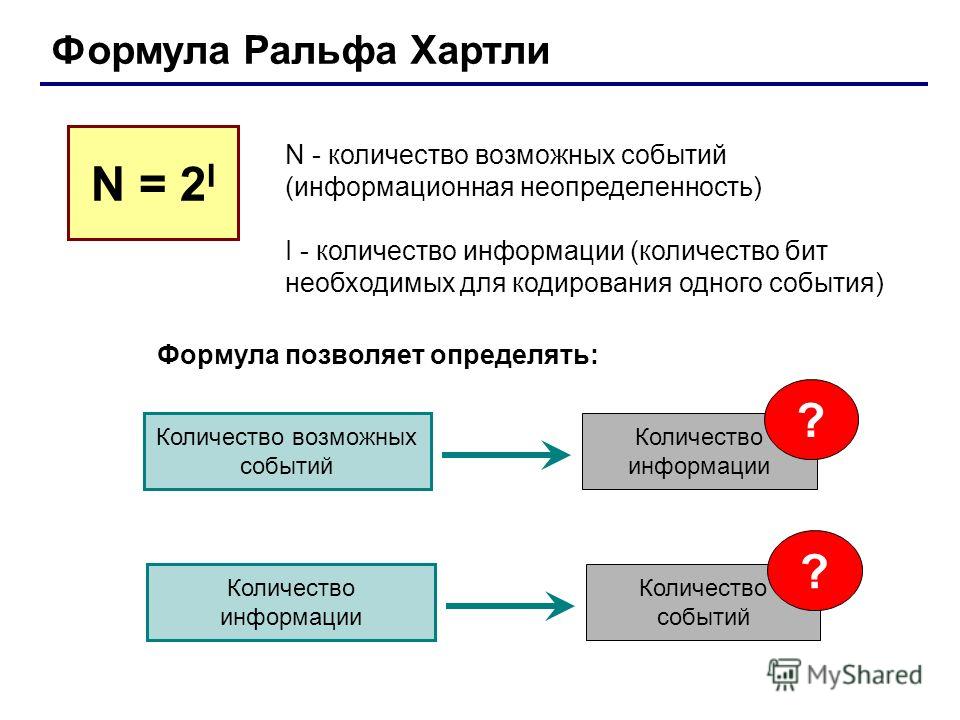
Задача 15. Информационное сообщение объемом 1,5 килобайта содержит 3072 символа. Сколько символов содержит алфавит, с помощью которого было записано это сообщение?
Задача 16. Мощность алфавита равна 64. Сколько Кбайт памяти потребуется, чтобы сохранить 128 страниц текста, содержащего в среднем 256 символов на каждой странице?
Задача 17. Конфеты находятся в одной из 10 коробок. Определить информационную неопределенность.
Задача 18. Тетрадь лежит на одной из двух полок — верхней или нижней. Сколько бит несет в себе сообщение, что она лежит на нижней полке?
Задача 19. Шарик находится в одной из трех урн: А, В или С. Определить информационную неопределенность.
Задача 20. Шарик находится в одной из 32 урн. Сколько единиц информации будет содержать сообщение о том, где он находится?
Оформление результатов работы:
1.
Напишите отчет в папке для выполнения практических работ, в котором
укажите номер, название и цель работы, порядок работы.
2. Ответьте на предложенные вопросы по данной теме в конце практической работы.
3. Напишите вывод.
Вопросы к защите практической работы:
1. В чем заключается алфавитный подход к измерению количества информации?
2. Сколько символов в компьютерном алфавите?
3. По какой формуле можно найти количество информации?
Количество информации. Формулы Хартли и Шеннона
В 1928 г. американский инженер Р. Хартли предложил научный подход к оценке сообщений. Предложенная им формула имела следующий вид:
I
= log2 K ,
Где К — количество равновероятных событий; I —
количество бит в сообщении, такое, что любое из К событий произошло.
Тогда K=2I.
Иногда формулу Хартли записывают так:
I
= log2 K = log2 (1 / р) = — log2 р,
т. к. каждое из К событий имеет равновероятный исход р = 1 / К, то К = 1 / р.
к. каждое из К событий имеет равновероятный исход р = 1 / К, то К = 1 / р.
Задача.
Шарик находится в одной из трех урн: А, В или С. Определить сколько бит информации содержит сообщение о том, что он находится в урне В.
Решение.
Такое сообщение содержит I = log2 3 = 1,585 бита информации.
Но не все ситуации имеют одинаковые вероятности реализации. Существует много таких ситуаций, у которых вероятности реализации различаются. Например, если бросают несимметричную монету или «правило бутерброда».
«Однажды в детстве я уронил бутерброд. Глядя, как я виновато вытираю масляное пятно, оставшееся на полу, старший брат успокоил меня:
— не горюй, это сработал закон бутерброда.
— Что еще за закон такой? — спросил я.
— Закон, который гласит: «Бутерброд
всегда падает маслом вниз». Впрочем, это шутка, — продолжал брат.-
Никакого закона нет. Прсто бутерброд действительно ведет себя довольно
странно: большей частью масло оказывается внизу.
Впрочем, это шутка, — продолжал брат.-
Никакого закона нет. Прсто бутерброд действительно ведет себя довольно
странно: большей частью масло оказывается внизу.
— Давай-ка еще пару раз уроним бутерброд, проверим, — предложил я. — Все равно ведь его придется выкидывать.
Проверили. Из десяти раз восемь бутерброд упал маслом вниз.
И тут я задумался: а можно ли заранее узнать, как сейчас упадет бутерброд маслом вниз или вверх?
Наши опыты прервала мать…»
(
Отрывок из книги «Секрет великих полководцев», В.Абчук).
В 1948 г. американский инженер и математик К Шеннон
предложил формулу для вычисления количества информации для событий с
различными вероятностями.
Если I — количество
информации,
К —
количество возможных
событий,
рi —
вероятности отдельных событий,
то количество информации для событий с
различными вероятностями можно определить по формуле:
I
= — Sum рi log2 рi,
где i принимает
значения от 1 до К.
Формулу Хартли теперь можно рассматривать как частный случай формулы Шеннона:
I = — Sum 1 / К log2 (1 / К) = I = log2 К.
При равновероятных событиях получаемое количество информации максимально.
Задачи.
1. Определить количество
информации, получаемое при реализации одного из событий, если
бросают
а) несимметричную четырехгранную пирамидку;
б) симметричную
и однородную четырехгранную пирамидку.
Решение.
а) Будем
бросать несимметричную четырехгранную пирамидку.
Вероятность отдельных
событий будет такова:
р1 = 1 / 2,
р2 = 1 / 4,
р3 = 1 / 8,
р4 =
1 / 8,
тогда количество информации, получаемой после реализации одного
из этих событий, рассчитывается по формуле:
I = -(1 / 2 log2
1/2 + 1 / 4 log2 1/4 + 1 / 8 log2 1/8 + 1 / 8
log2 1/8) = 1 / 2 + 2 / 4 + + 3 / 8 + 3 / 8 = 14/8 = 1,75
(бит).
б) Теперь рассчитаем количество информации, которое получится
при бросании симметричной и однородной четырехгранной пирамидки:
I =
log2 4 = 2 (бит).
2. Вероятность перового события составляет
0,5, а второго и третьего 0,25. Какое количество информации мы получим
после реализации одного из них?
3. Какое количество информации будет
получено при игре в рулетку с 32-мя секторами?
4. Сколько различных чисел можно закодировать с помощью 8 бит?
Решение: I=8 бит, K=2I=28=256 различных чисел.
Физиологи и психологи научились определять количество
информации, которое человек может воспринимать при помощи органов чувств,
удерживать в памяти и подвергать обработке. Информацию можно представлять
в различных формах: звуковой, знаковой и др. рассмотренный выше способ
определения количества информации, получаемое в сообщениях, которые
уменьшают неопределенность наших знаний, рассматривает информацию с
позиции ее содержания, новизны и понятности для человека. С этой точки
зрения в опыте по бросанию кубика одинаковое количество информации
содержится в сообщениях «два», «вверх выпала грань, на которой две точки»
и в зрительном образе упавшего кубика.
С этой точки
зрения в опыте по бросанию кубика одинаковое количество информации
содержится в сообщениях «два», «вверх выпала грань, на которой две точки»
и в зрительном образе упавшего кубика.
При передаче и хранении информации с помощью различных технических устройств информацию следует рассматривать как последовательность знаков (цифр, букв, кодов цветов точек изображения), не рассматривая ее содержание.
Считая, что алфавит (набор символов знаковой
системы) — это событие, то появление одного из символов в сообщении можно
рассматривать как одно из состояний события. Если появление символов
равновероятно, то можно рассчитать, сколько бит информации несет каждый
символ. Информационная емкость знаков определяется их количеством в
алфавите. Чем из большего количества символов состоит алфавит, тем большее
количество информации несет один знак. Полное число символов алфавита
принято называть мощностью алфавита.
Молекулы ДНК (дезоксирибонуклеиновой кислоты) состоят из четырех различных составляющих (нуклеотидов), которые образуют генетический алфавит. Информационная емкость знака этого алфавита составляет:
4 = 2I, т.е. I = 2 бит.
Каждая буква русского алфавита (если считать, что е=е) несет информацию 5 бит (32 = 2I).
При таком подходе в результате сообщения о результате бросания кубика , получим различное количество информации, Чтобы его подсчитать, нужно умножить количество символов на количество информации, которое несет один символ.
Количество информации, которое содержит сообщение, закодированное с помощью знаковой системы, равно количеству информации, которое несет один знак, умноженному на число знаков в сообщении.
Использованы материалы учителя информатики школы № 3Ильиной Ольги Владимировны, г.
 Тутаев Ярославской обл..
Тутаев Ярославской обл..
Занятие 1. Вычисление информационного объема сообщения
Тема: Вычисление информационного объема сообщения.
Что надо знать?
- Единицы измерения информации
В 1 бит можно записать один двоичный символ.
1 байт = 8 бит
В кодировке ASCII в один байт можно записать один 256 символьный код
В кодировке UNICODE один 256 символьный код занимает в памяти два байта
1 килобайт = 1024 байт
1 мегабайт = 1024 килобайт
1 гигабайт = 1024 мегабайт
1 терабайт = 1024 гигабайт - Формула Хартли 2 i = N где i- количество информации в битах, N — неопределенность
- Таблица степеней двойки, которая показывает сколько информации можно закодировать с помощью i — бит
|
i |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
N=2 i |
1 |
2 |
4 |
8 |
16 |
32 |
64 |
128 |
256 |
512 |
1024 |
- Чтобы вычислить информационный объем сообщения надо количество символов умножить на число бит, которое требуется для хранения одного символа
Например: двоичный текст 01010111 занимает в памяти 8 бит
Этот же текст в кодировке ASCII занимает 8 байт или 64 бита
Этот же текст в кодировке UNICODE занимает 16 байт или 128 бит.
Не забывайте, что пробелы надо тоже считать за символы поскольку они также набираются на клавиатуре и хранятся в памяти.
Мощность алфавита — это количество символов в алфавите или неопределенность из формулы Хартли.
Информационный вес одного символа — это значение i из формулы Хартли.
Отсюда можно сделать вывод, что не существует алфавита, состоящего из одного символа, поскольку тогда информационный вес этого символа был бы равен 0.
- Чтобы перевести биты в байты надо число бит поделить на 8.
Например: 32 бита — это 4 байта.Чтобы перевести байты в килобайты надо число байтов поделить на 1024.
Например: в 2048 байтах будет 2 килобайта. И так далее по следующим единицам измерения.Чтобы перевести байты в биты надо число байт умножить на 8.
Например: в 3 байтах будет 24 бита.Чтобы перевести килобайты в байты надо число килобайт умножить на 1024.
Например: в 3 килобайтах будет 3072 байта и соответственно 24576 бит. И так далее.
И так далее. Если 128 символьным алфавитом записано сообщение из 5 символов, то объем сообщения — 35 бит.
Мощность алфавита — 128. Это неопределенность. Значит один символ занимает в памяти 7 бит, тогда 5 символов занимают в памяти 35 бит.Чтобы определить час прибытия поезда, надо задать 5 вопросов, иначе говоря, получить 5 бит информации, поскольку неопределенность равна 24.
Чтобы найти фальшивую монету из 64 монет необходимо сделать 6 взвешиваний.
- Задача. Определить, сколько времени будет передавать информацию страницы текста из 40 строк по 80 символов в строке модем, работающий со скоростью 1200 бит/сек.
Решение. Вычислим общее количество символов на странице. Это 40 х 80= 3200 символов.
Поскольку в кодировке ASCII один символ занимает в памяти 1 байт, общее количество информации на странице — 3200 байт, но скорость дана в бит/сек. Переведем 3200 байт в биты. Получим 25600 бит.
Разделим 25600 бит на 1200 бит/сек и получим 21,3 сек. Обратите внимание, что здесь нельзя округлить до 21 сек поскольку в этом случае вы не отправите всю заданную информацию.
Обратите внимание, что здесь нельзя округлить до 21 сек поскольку в этом случае вы не отправите всю заданную информацию.
Однако в случае передачи нескольких страниц текста для приближенного вычисления можно использовать результат 21,3 сек для дальнейших расчетов. Таким образом 10 страниц текста будут переданы за 213,3 сек. - Задача. Документ содержит точечную черно-белую фотографию 10 х 15 см. Каждый квадратный сантиметр содержит 600 точек, каждая точка описывается 4 битами. Каков общий информационный объем документа в килобайтах?
Решение. Вычислим общее количество точек, содержащихся в фотографии. Обратите внимание, что 600 точек содержит не линейный сантиметр, а квадратный. Таким образом общее число точек будет 10 х 15 х 600 = 9000 точек. Поскольку точка описывается 4 битами, то общее число бит 9000 х 4 = 36000 бит.
Переведем биты в байты и получим 36000 : 8 = 4500 байт
Переведем байты в килобайты 4500 : 1024 = 4,39 килобайт. - Задача. Метеорологическая станция ведет наблюдение за атмосферным давлением.
 Результатом одного измерения является целое число, принимающее значение от 720 до 780 мм ртутного столба, которое записывается при помощи минимально возможного количества бит. Станция сделала 80 измерений, Определите информационный объем результатов наблюдений.
Результатом одного измерения является целое число, принимающее значение от 720 до 780 мм ртутного столба, которое записывается при помощи минимально возможного количества бит. Станция сделала 80 измерений, Определите информационный объем результатов наблюдений.
Решение. Определим количество значений, которое надо закодировать. Это 61 значение.
780 — 720 + 1 = 61 (проверьте формулу на интервале по номерам очереди с 3 до 5).
Полученное число — это неопределенность. Значит для кодирования одного значения по формуле Хартли требуется 6 бит информации.
Сделано 80 измерений, получено 6 х 80 = 480 бит или 480 : 8 = 60 байт информации. - Количество символов в тексте = Информационный вес всего текста : Информационный вес одного символа
Задача. Информационный объем текста, набранного на компьютере с использованием кодировки UNICODE (каждый символ кодируется 16 битами), — 2 Кб. Определить количество символов в тексте.
Решение. Чтобы определить количество символов в тексте, надо знать информационный объем всего текста и информационный вес одного символа.
Однако прежде, чем выполнять деление, необходимо привести величины к одинаковым единицам измерения.
2 кб= 2 х 1024 = 2048 байт весь объем информации.
каждый символ кодируется 16 битами или 2 байтами. Отсюда 2048 : 2 = 1024 символа в тексте.
Тренировочные задачи.
1. Задача на использование первой основной формулы.
Каждый символ алфавита записывается с помощью 4 цифр двоичного кода. Сколько символов в этом алфавите?
Каждый символ алфавита записывается с помощью 6 цифр двоичного кода. Сколько символов в этом алфавите?
Каждый символ алфавита записывается с помощью 3 цифр двоичного кода. Сколько символов в этом алфавите?
Каждый символ алфавита записывается с помощью 5 цифр двоичного кода. Сколько символов в_этом алфавите?
2. Обратная задача на использование первой основной формулы.
Алфавит для записи сообщений состоит из 32 символов. Каков информационный вес одного символа? Не забудьте указать единицу измерения.
Алфавит для записи сообщений состоит из 64 символов. Каков информационный вес одного символа? Не забудьте указатьединицу измерения.
Каков информационный вес одного символа? Не забудьте указатьединицу измерения.
Алфавит для записи сообщений состоит из 16 символов. Каков информационный вес одного символа? Не забудьте указать единицу измерения.
Алфавит для записи сообщений состоит из 128 символов. Каков информационный вес одного символа? Не забудьте указать единицу измерения.
3. Задача НА использование второй формулы.
Информационный объем текста, набранного на компьютере с использованием кодировки UNICODE (каждый символ кодируется 16 битами), — 4 Кб. Определить количество символов в тексте.
Информационное сообщение объемом 1,5 Кб содержит 3072 символа. Определить информационный вес одного символа использованного алфавита в битах.
Информационный объем текста, набранного на компьютере с использованием кодировки UNICODE (каждый символ кодируется 16 битами), — 0,5 Кб. Определить количество символов в тексте.
Информационное сообщение объемом 3 Кб содержит 3072 символа. Определить информационный вес одного символа использованного алфавита в битах.
4. Задача на соотношение единиц измерения информации без использования степеней.
Объем информационного сообщения составляет 8192 бита. Выразить его в килобайтах.
Информационный объем сообщения равен 12 288 битам. Чему равен объем того же сообщения в килобайтах?
Объем информационного сообщения составляет 1 6 384 бита. Выразить его в килобайтах.
Информационный объем сообщения равен 4096 битам. Чему равен объем того же сообщения в килобайтах?
5. Задача на соотношение единиц измерения информации с использованием степеней.
Сколько бит информации содержит сообщение объемом 4 Мб? Ответ дать в степенях 2.
Сколько бит информации содержит сообщение объемом 16 Мб? Ответ дать в степенях 2.
Сколько бит информации содержит сообщение объемом 2 Мб? Ответ дать в степенях 2.
Сколько бит информации содержит сообщение объемом 8 Мб? Ответ дать в степенях 2.
6. Задача на использование двух формул.
Сообщение, записанное буквами из 25б-символьного алфавита, содержит 256 символов. Какой объем информации оно несет в килобайтах?
Какой объем информации оно несет в килобайтах?
Сообщение, записанное буквами из 16-символьного алфавита, содержит 512 символов. Какой объем информации оно несет в килобайтах?
Сколько символов содержит сообщение, записанное с помощью 16-символьного алфавита, если объем ею составил 1/16 часть килобайта?
Объем сообщения, содержащего 16 символов, составил 1/512 часть килобайта Каков размер алфавита.
7. «Текстовая» задача на использование основной формулы.
Сколько существует различных звуковых сигналов, состоящих из последовательностей коротких и длинных звонков? Длина каждого сигнала — 6 звонков.
Световое табло состоит из лампочек, каждая из которых может находиться в двух состояниях («включено» или «выключено»). Какое наименьшее количество лампочек должно находиться на табло, чтобы с его помощью можно было передать 150 различных сигналов?
Зрительный зал представляет собой прямоугольную область зрительских кресел: 12 рядов по 10 кресел. Какое минимальное количество бит потребуется для кодирования каждого места в автоматизированной системе?
Каждый пиксель цветного изображения кодируется 1 байтом. Сколько цветов в таком изображении?
Сколько цветов в таком изображении?
8. «Текстовая» задача на использование двух формул.
Метеорологическая станция ведет наблюдение за влажностью воздуха. Результатом одного измерения является целое число от 20 до 100%, которое записывается при помощи минимально возможного количества бит. Станция сделала 80 измерений. Определите информационный объем результатов наблюдений,
Метеорологическая станция ведет наблюдение за атмосферным давлением. Результатом одного измерения является целое число, принимающее значение от 700 до 780 мм ртутного столба, которое записывается при помощи минимально возможного количества бит. Станция сделала 80 измерений, Определите информационный объем результатов наблюдений.
Метеорологическая станция ведет наблюдение за влажностью воздуха. Результатом одного измерения является целое число от 40 до 100%, которое записывается при помощи минимально возможного количества бит. Станция сделала 50 измерений, Определите информационный объем результатов наблюдений.
Метеорологическая станция ведет наблюдение за атмосферным давлением. Результатом одного измерения является целое число, принимающее значение от 740 до 760 мм ртутного столба, которое записывается при помощи минимально возможного количества бит. Станция сделала 70 измерений. Определите информационный объем результатов наблюдений.
9. Задача о передаче информации с помощью модема.
Скорость передачи данных через АDSL-соединение равна 512000 бит/с. Через данное соединение передают файл размером 1500 Кб. Определите время передачи файла в секундах.
Скорость передачи данных через АDSL-соединение равна 1024000 бит/с. Через данное соединение передают файл размером 2500 Кб. Определите время передачи файла в секундах.
Скорость передачи данных через АDSL-соединение равна 1024000 бит/с. Передача файла через данное соединение заняла 5 секунд. Определите размер файла в килобайтах.
Скорость передачи данных через АDSL-соединение равна 512000 бит/с. Передача файла через данное соединение заняла 8 секунд. Определите размер файла в килобайтах.
Определите размер файла в килобайтах.
10. Задача о передаче графической информации.
Определите скорость работы модема, если за 256 с он может передать растровое изображение размером 640 х 480 пикселей. На каждый пиксель приходится 3 байта.
Сколько секунд потребуется модему, передающему информацию со скоростью 56 000 бит/с, чтобы передать цветное растровое изображение размером 640 х 480 пикселей, при условии, что цвет каждого пикселя кодируется тремя байтами?
Определите скорость работы модема, если за 132 с он может передать растровое изображение размером 640 х 480 пикселей. На каждый пиксель приходится 3 байта.
Сколько секунд потребуется модему, передающему информацию со скоростью 28800 бит/с, чтобы передать цветное растровое изображение размером 640 х 480 пикселей, при условии, что цвет каждого пикселя кодируется тремя байтами?
Вопрос на засыпку
Как двумя взвешиваниями найти фальшивую монету из 8 монет
Редактировалось Дата:Измерение информации: Задания с решениями
Задача 1. Сколько бит информации несёт сообщение о том, что из
колоды в 32 карты достали «даму пик»?
Сколько бит информации несёт сообщение о том, что из
колоды в 32 карты достали «даму пик»?
2i = 32;
Задача 2. Сколько бит информации получено из сообщения «Вася живет на пятом этаже», если в доме 16 этажей? N = 16,i — ?
Решение:
N = 2i, 16 = 2i, i = 4 бита
Ответ: сообщение содержит 4 бита. Задача 3. Какое количество информации в сообщении из 10 символов, записанном буквами из 32-символьного алфавита? N = 32,
I — ?
Решение:
I = K*i, N = 2i, 32 = 2i, i = 5 бит, значит I = 10*5 = 50 бит.
Ответ: 50 бит. Задача 4. Первое письмо состоит из 50 символов 32-символьного алфавита, а второе – из 40 символов 64 – символьного алфавита. Сравните объемы информации, содержащиеся в двух письмах. Решение:
I = K*i, N = 2i, Определим информационную емкость одного символа в каждом из писем: 2i = 32, i = 5 бит – для первого письма,
2i = 64, i = 6 бит – для второго письма.

Определим количество информации в каждом из писем:
50*5 = 250 бит – для первого письма, 40*6 = 240 бит – для второго письма.
Найдем разность между информационными объемами двух писем.
250 — 240 = 10 бит. Ответ: Объем информации, содержащейся в первом письме на 10 бит больше, чем объем информации, содержащейся во втором письме. Задача 5. Статья, созданная с помощью ПК, содержит 30 страниц, на каждой странице — 40 строк, в каждой строке 50 символов. Какой объём информации содержит статья? 1) На каждой странице 50 • 40 = 2000 символов; 2) во всей статье 2000 • 30 = 60000 символов; 3) т.к. вес каждого символа компьютерного алфавита равен 8 бит, следовательно, информационный объём всей статьи I = 60000*8 = 480000 бит = 60000 байт. Ответ: 60000 байт. Задача 6. Сколько информации содержит сообщение о выпадении грани с числом 3 на шестигранном игральном кубике? Ответ: i = 2,5 бит. Задача 7. Для хранения текста требуется 84000 бит.
 Сколько страниц займёт этот текст, если на странице размещается 30
строк по 70 символов в строке?
Сколько страниц займёт этот текст, если на странице размещается 30
строк по 70 символов в строке?Решение:
1 байт=8 бит. 84000/8=10500 символов в тексте. На странице помещается 30×70=2100 символов. 10500/2100=5 страниц.
Ответ: текст займёт 5 страниц. Задача 8. В корзине лежат шары. Все разного цвета. Сообщение о том, что достали синий шар, несёт 5 бит информации. Сколько всего шаров было в корзине?
Решение:
Если все шары разного цвета, значит, ни один шар не совпадает по цвету с другими. Следовательно, шары можно доставать с равной долей вероятности. В этом случае применяется формула Хартли. iсиний = 5 бит; 5 = log232; 2i = N; 25 = 32.
Ответ: в корзине 32 шара.
Задача 9. Сколько символов содержит сообщение, записанное с помощью 16-символьного алфавита, если его объём составил 1/16 часть мегабайта?
Решение:
1 Мб=1024 Кб.
 Значит, объём сообщения 1024/16=64 Кб.
Информационный вес символа iсимв.=log216= 4
бит. Объём сообщения в битах — 64×1024×8=524 288 бит. Количество символов в
сообщении 524288/4=131 072.
Значит, объём сообщения 1024/16=64 Кб.
Информационный вес символа iсимв.=log216= 4
бит. Объём сообщения в битах — 64×1024×8=524 288 бит. Количество символов в
сообщении 524288/4=131 072.Ответ: в сообщении 131 072 символа.
Найдите сводку из пяти чисел в статистике: простые шаги
Как найти пятизначную сводку в статистике
Содержимое :
- Найти сводку из пяти чисел вручную
- Инструкции TI 89
- Инструкции SPSS
- 5 числовая сводка в Excel (новое окно)
Как найти пятизначную сводку в статистике: Обзор
Посмотрите видео с примером того, как найти сводку из 5 чисел для нечетного набора чисел:
Видео не видно? Кликните сюда.

Это второе короткое видео показывает, что делать, если у вас есть четный набор чисел:
Видео не видно? Кликните сюда.
Пятизначная сводка включает 5 пунктов:
- Минимум.
- Q1 (первый квартиль или отметка 25%).
- Медиана.
- Q3 (третий квартиль или отметка 75%).
- Максимум.
Сводка из пяти цифр дает приблизительное представление о том, как выглядит ваш набор данных.например, у вас будет самое низкое значение (минимум) и самое высокое значение (максимум). Хотя это полезно само по себе, основная причина, по которой вы захотите найти сводку из пяти чисел, заключается в том, чтобы найти более полезную статистику, такую как межквартильный диапазон, который иногда называют серединой пятидесяти.
Нужна помощь? Посетите нашу страницу обучения!
Как найти сводку из пяти чисел: шаги
- Шаг 1: Расположите числа в порядке возрастания (от меньшего к большему).Для этого конкретного набора данных порядок следующий:
Пример: 1, 2, 5, 6, 7, 9, 12, 15, 18, 19, 27. - Шаг 2: Найдите минимальное и максимальное значение для вашего набора данных. Теперь, когда ваши числа в порядке, это должно быть легко заметить.
В примере на шаге 1 минимальное (наименьшее число) равно 1, а максимальное (наибольшее число) равно 27. - Шаг 3: Найдите медиану . Медиана — это среднее число. Если вы не знаете, как найти медиану, см. раздел Как найти среднюю моду и медиану.
- Шаг 4: Заключите в скобки числа выше и ниже медианы .
(Это не технически , но это облегчает поиск Q1 и Q3).
(1, 2, 5, 6, 7), 9, (12, 15, 18, 19, 27). - Шаг 5: Найдите Q1 и Q3 . Q1 можно рассматривать как медиану нижней половины данных, а Q3 можно рассматривать как медиану верхней половины данных.
(1, 2, 5 , 6, 7) , 9 , (12, 15, 18 ,19,27). - Шаг 6: Запишите сводку, полученную на предыдущих шагах .
минимум = 1, Q1 = 5, медиана = 9, Q3 = 18 и максимум = 27.
Вот и все!
Если сводки не существует
Иногда невозможно найти сводку из пяти цифр. Чтобы пять чисел существовали, ваш набор данных должен соответствовать этим двум требованиям:
.- Ваши данные должны быть одномерными . Другими словами, данные должны быть одной переменной.Например, этот список весов представляет собой одну переменную: 120, 100, 130, 145. Если у вас есть список возрастов и вы хотите сравнить возрасты с весами, они становятся двумерными данными (две переменные).
 Например: 1 год (25 фунтов), 5 лет (60 фунтов), 15 лет (129 фунтов). Совпадающие пары не позволяют найти сводку из пяти чисел.
Например: 1 год (25 фунтов), 5 лет (60 фунтов), 15 лет (129 фунтов). Совпадающие пары не позволяют найти сводку из пяти чисел. - Данные должны быть порядковыми, интервальными или пропорциональными.
Нравится объяснение? Ознакомьтесь со Справочником по статистике практического мошенничества, в котором есть еще сотни пошаговых решений, таких как это!
Наверх
Коробчатая диаграмма с усами
Диаграмма с прямоугольниками и усами — это визуальное представление сводки.
Блок-схема / Найдите сводку из пяти чисел на TI 89
Коробчатая диаграмма с перекосом влево, показывающая длинный левый ус. Изображение: ШУ.ЭДУ
Когда вы создаете диаграмму «ящики и усы» на TI-89 , TI-89 автоматически рассчитает для вас сводку из пяти чисел.
Пример задачи: Создайте диаграмму с прямоугольниками и усами и найдите сводку из пяти чисел для следующих данных: 200, 350, 300, 350 и 400.
Шаг 1: Создайте новую папку под названием «Box.” На главном экране нажмите F4 и прокрутите вниз до NewFold (вариант B). Нажмите Ввод.
Шаг 2: Нажмите 2nd Alpha ( – x, чтобы написать B O X, и нажмите ENTER.
Шаг 3: Нажмите APPS, затем прокрутите вниз до Редактор статистики/списка . Дважды нажмите ВВОД.
Шаг 4: Нажмите клавишу со стрелкой вниз, чтобы перейти к первой строке списка. Введите свои данные в list1. После каждой записи ставьте запятую: 200, 350, 300, 350, 400.
Шаг 5: Нажмите F2, затем 1, чтобы ввести Настройка графика .
Шаг 6: Нажмите F1, стрелку вправо и 5, чтобы выбрать блочный график модуля .
Шаг 7: Стрелка вниз до Отметьте и выберите поле .
Шаг 8: Проведите стрелкой вниз и введите B O X (используя буквенно-цифровую клавиатуру) в поле x .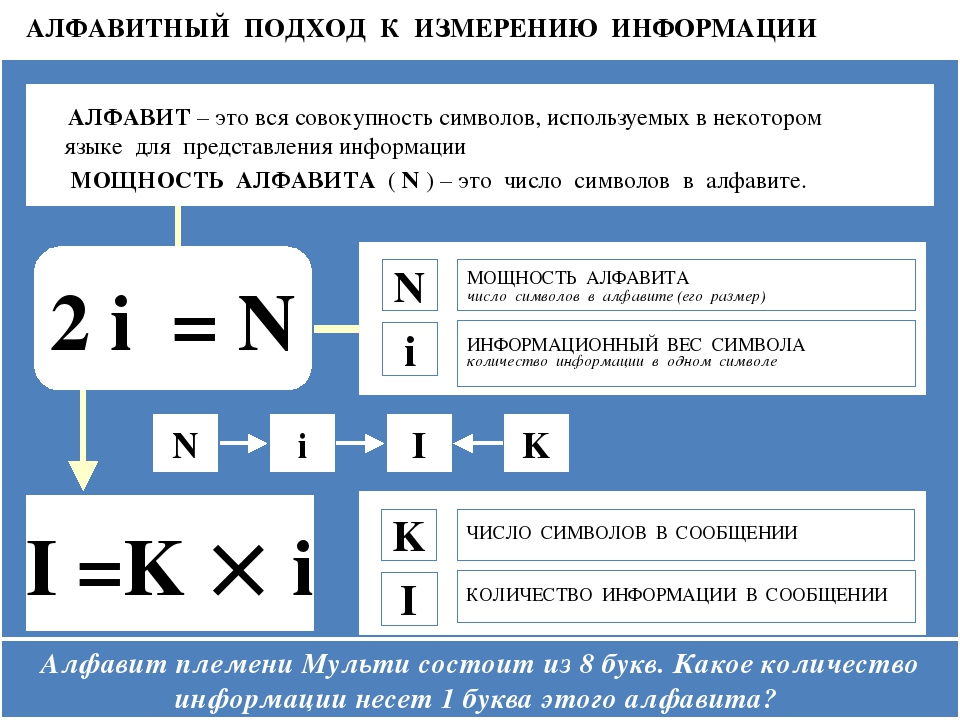 Нажмите Ввод.
Нажмите Ввод.
Шаг 9: Прочтите блок-диаграмму. Нажмите F3 и используйте курсоры влево и вправо, чтобы найти Min(200), Q1(250), Med(325), Q3(400) и Max(500).
Вот оно!
Совет : если вы хотите изменить папку обратно на ГЛАВНУЮ, нажмите MODES, прокрутите вниз до Текущая папка .Нажмите правую клавишу, затем нажмите 1 ENTER.
Совет Если вы получаете сообщение об ошибке неопределенная переменная , попытка решить проблему может оказаться утомительной. Очистка памяти *может* помочь, но более простой способ отобразить блочную диаграмму на графике — это ввести данные в «список 1» в редакторе списков, а затем ввести «список 1» в качестве «x» при определении блочной диаграммы. .
Потеряли путеводитель? Вы можете загрузить новую версию с веб-сайта TI здесь.
Наверх
Найдите сводку из пяти чисел в SPSS
Вычисление сводки из пяти чисел довольно просто, если у вас небольшой набор данных, но для больших наборов данных, с которыми вы обычно работаете в SPSS, задача может быть невероятно утомительной. Вот где программное обеспечение, такое как SPSS, пригодится — задачи, которые иногда требуют часов вручную, могут быть вычислены за долей секунды. Сводка пяти чисел SPSS рассчитывается с помощью инструмента «Частоты».
Вот где программное обеспечение, такое как SPSS, пригодится — задачи, которые иногда требуют часов вручную, могут быть вычислены за долей секунды. Сводка пяти чисел SPSS рассчитывается с помощью инструмента «Частоты».
Посмотрите видео по шагам:
Видео не видно? Кликните сюда.
Шаг 1: Откройте новый лист данных и введите свои данные в столбец (или несколько столбцов). Чтобы открыть новый лист данных, нажмите «Файл» на панели инструментов, затем нажмите «Создать», а затем нажмите «Данные».Убедитесь, что вы вводите данные без пробелов (другими словами, не оставляйте пустых строк).
Шаг 2: Нажмите «Анализ», , затем нажмите «Описательная статистика», а затем нажмите «Частоты», чтобы открыть диалоговое окно «Частоты».
Сводка из пяти чисел в SPSS рассчитывается через меню «Частота».
Шаг 3: Щелкните имя переменной (или несколько, если вы ввели данные в несколько столбцов), а затем щелкните центральную стрелку, чтобы переместить их в поле списка Переменные.Обратите внимание, что в SPSS используется термин «переменные», но на самом деле он означает только имя заголовка столбца. Вы можете изменить это имя, нажав кнопку просмотра «Переменные» в нижней части листа.
Шаг 4: Нажмите «Статистика» , чтобы открыть диалоговое окно «Статистика».
Шаг 5: Отметьте «Квартили», «медиану», «минимум» и «максимум», а затем нажмите «Продолжить».
Шаг 6: Нажмите «ОК». Вычисляется пятизначная сводка SPSS, и результаты возвращаются в новом окне.
Примечание : SPSS указывает первый квартиль (Q1) как 25-й процентиль в окне результатов, а третий квартиль (Q3) указывает как 75-й процентиль.
Наверх
Загляните на наш канал YouTube, чтобы получить дополнительную справку по статистике и советы.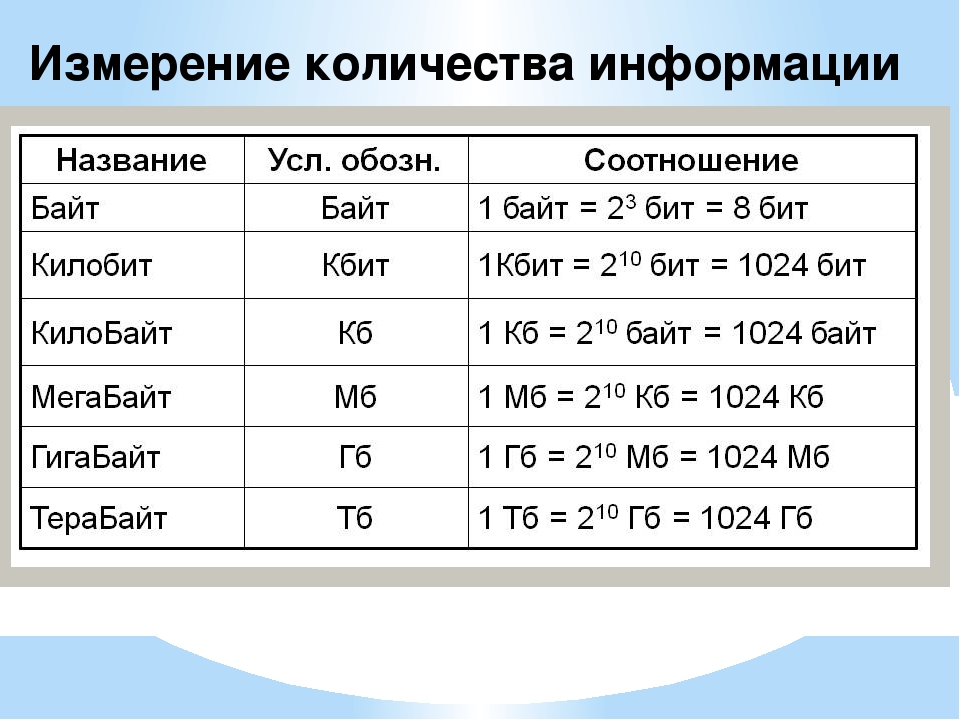
Ссылки
Ларри Гоник. The Cartoon Guide to Statistics, 1993
Дэвид С. Хоаглин, Фредерик Мостеллер и Джон В. Тьюки. «Понимание надежного и исследовательского анализа данных». Уайли, 1983.
Нужна помощь с домашним заданием или контрольным вопросом? С Chegg Study вы можете получить пошаговые ответы на ваши вопросы от эксперта в данной области.Ваши первые 30 минут с репетитором Chegg бесплатны!
Комментарии? Нужно опубликовать исправление? Оставьте комментарий на нашей странице в Facebook .
Распространение в наборах данных: определение и пример — видео и расшифровка урока
Диапазон
Самый простой способ найти разброс в наборе данных — определить диапазон , представляющий собой разницу между самым высоким и самым низким значениями в наборе данных. Расположим возраст последней продукции от меньшего к большему: 9, 11, 12, 12, 13, 29, 36, 38, 42, 43, 47, 57, 64.
Расположим возраст последней продукции от меньшего к большему: 9, 11, 12, 12, 13, 29, 36, 38, 42, 43, 47, 57, 64.
Теперь возьмите наименьшее число и наибольшее число и найдите разницу: 64 — 9 = 55. Для этого производства существует 55-летний разброс в возрастах. Диапазон, вероятно, является лучшей мерой разброса для этих данных. Табата может объявить, что ищет актеров в возрасте от 9 до 64 лет для этой постановки. Давайте посмотрим, как Табата может найти разброс в своих данных.
Межквартильный диапазон
Межквартильный диапазон — это значение, представляющее собой разницу между значением верхнего квартиля и значением нижнего квартиля.Для этого метода нам нужно будет найти каждый квартиль в наборе данных. Чтобы найти квартили, выполните следующие действия:
- Упорядочите данные от наименьшего к наибольшему.
- Найдите медиану набора данных и разделите набор данных на две половины.
- Найдите медиану двух половин.
Более подробно о квартили см. в нашем уроке «Квартили и межквартильный диапазон».
в нашем уроке «Квартили и межквартильный диапазон».
Наша медиана равна 36, что составляет вторую квартиль. Для каждой половины набора данных мы должны найти медиану, медиана для первого квартиля (нижняя половина набора данных) равна 12, а медиана для третьего квартиля (верхняя половина набора данных) равна 45.
Чтобы найти межквартильный диапазон, просто возьмите верхний квартиль и вычтите нижний квартиль: 45 — 12 = 33. Межквартильный диапазон равен 33. Это означает, что большинство возрастов в этом наборе данных находятся в пределах 33 лет друг от друга. . Хотя эта информация может не дать Табате конкретный возрастной диапазон, который она ищет, она может помочь ей понять разнообразие возрастов, которые она ищет в этой постановке.
Дисперсия
Теперь давайте посмотрим на дисперсию в этом наборе данных. Дисперсия — это то, насколько далеко разбросан набор чисел. Чтобы найти дисперсию, выполните следующие действия:
- Найдите среднее значение набора данных.

- Вычесть каждое число из среднего.
- Возведите результат в квадрат.
- Сложите числа вместе.
- Разделите результат на общее количество чисел в наборе данных.
Взгляните на диаграмму ниже, чтобы найти дисперсию в этом наборе данных:
Первый столбец содержит все числа в наборе данных, второй столбец показывает среднее значение набора данных.В следующих столбцах мы взяли результаты второго столбца и возвели каждое число в квадрат. В четвертом столбце мы взяли каждое число из третьего столбца и сложили их вместе, а в пятом и последнем столбце мы разделили число из четвертого столбца на общее количество значений из набора данных, то есть 13. Наше отклонение от этого набора данных составляет 329,72.
При анализе дисперсии набора данных чем больше дисперсия, тем больше разброс. Число 329.72 говорит нам о том, что данные имеют большой разброс и что числа сильно отличаются от среднего. Для получения дополнительной информации о дисперсии ознакомьтесь с нашим уроком «Население и выборочная дисперсия».
Для получения дополнительной информации о дисперсии ознакомьтесь с нашим уроком «Население и выборочная дисперсия».
Вы также можете использовать стандартное отклонение, чтобы найти разброс в наборе данных. Для простоты стандартное отклонение представляет собой квадратный корень из дисперсии. Таким образом, стандартное отклонение этого набора данных составляет приблизительно 18,15. Чтобы глубже понять эту концепцию, ознакомьтесь с нашим уроком «Стандартное отклонение и сдвиги в среднем».’
Резюме урока
разброс данных является мерой того, насколько числа в наборе данных далеки от среднего или медианы. Разброс данных может показать нам, насколько сильно различаются значения набора данных. Это полезно для определения того, являются ли значения в наборе данных относительно близкими или разбросанными. Есть три метода, которые вы можете использовать, чтобы найти разброс в наборе данных: диапазон, межквартильный диапазон и дисперсия.
Диапазон — это разница между самым высоким и самым низким значениями в наборе данных. Вы можете найти диапазон, взяв наименьшее число в наборе данных и наибольшее число в наборе данных и вычтя их. Так Табата нашла возрастной диапазон актеров, необходимых ей для ее пьесы.
Вы можете найти диапазон, взяв наименьшее число в наборе данных и наибольшее число в наборе данных и вычтя их. Так Табата нашла возрастной диапазон актеров, необходимых ей для ее пьесы.
Вы также можете найти разброс в наборе данных, используя межквартильный диапазон , который представляет собой разницу между значением верхнего квартиля и значением нижнего квартиля. Для этого метода вам нужно будет найти каждый квартиль в наборе данных. Чтобы найти квартили, выполните следующие действия:
- Упорядочите данные от наименьшего к наибольшему.
- Найдите медиану набора данных и разделите набор данных на две половины.
- Найдите медиану двух половин.
Вы также можете использовать дисперсию , то есть насколько далеко разбросан набор чисел. Чтобы найти дисперсию, выполните следующие действия:
- Найдите среднее значение набора данных.
- Вычесть каждое число из среднего.
- Возведите результат в квадрат.

- Сложите числа вместе.
- Разделите результат на общее количество чисел в наборе данных.
Каждый из этих методов что-то говорит нам о разбросе данных. Диапазон лучше всего подходит для наборов данных, где вы ищете данные, которые действительно далеки друг от друга и охватывают все. Межквартильный диапазон лучше всего подходит для случаев, когда вы смотрите на группу чисел и сравниваете их со средними значениями, такими как результаты тестов или данные о производительности, такие как результаты игр. Дисперсия лучше всего подходит для того, чтобы показать, насколько далеко числа разбросаны друг от друга, используя одно значение по сравнению со средним значением.Чем больше значение дисперсии, тем дальше числа разбросаны от среднего.
Результаты обучения
После этого занятия вы должны уметь:
- Объяснять, что такое разброс данных, и определить три метода его определения
- Перечислите шаги, необходимые для нахождения межквартильного размаха и дисперсии
- Опишите, когда лучше всего использовать диапазон, межквартильный диапазон или дисперсию
Основная сумма: определение и формула — видео и расшифровка урока
Что насчет процентов?
Основная сумма не включает проценты или ставку, уплачиваемую в качестве платы за заимствование денег. Чтобы вычислить сумму процентов, уплаченных Джоном в течение пяти лет, вы можете использовать формулу простых процентов , которая представляет собой формулу для расчета процентов, выплачиваемых только на основную сумму. Эта формула:
Чтобы вычислить сумму процентов, уплаченных Джоном в течение пяти лет, вы можете использовать формулу простых процентов , которая представляет собой формулу для расчета процентов, выплачиваемых только на основную сумму. Эта формула:
или проценты равны основной сумме, умноженной на процентную ставку, умноженной на количество времени. Используя эту формулу, вы обнаружите, что сумма процентов по ссуде Джона в размере 7500 долларов составила 3750 долларов. Таким образом, по истечении пяти лет он заплатит в общей сложности 11 250 долларов.Это не включает какие-либо дополнительные сборы, которые могут взиматься.
Формулы основной суммы
Для ссуды Джона нам была дана основная сумма, и мы использовали ее для определения суммы процентов. Что, если мы уже знаем процентную ставку, сумму процентов и количество времени, но нам нужно узнать основную сумму? Мы можем изменить формулу процентов, I = PRT , чтобы рассчитать основную сумму. Новая, измененная формула будет выглядеть так: P = I / (RT) , что означает, что основная сумма равна проценту, деленному на процентную ставку, умноженному на количество времени.
Новая, измененная формула будет выглядеть так: P = I / (RT) , что означает, что основная сумма равна проценту, деленному на процентную ставку, умноженному на количество времени.
Давайте попробуем это, найдя основную сумму кредита с общей суммой процентов 18 500 долларов и годовой процентной ставкой 6,5% на 12 лет.
Чтобы решить, мы вводим значения в уравнение, P = I / (RT) . Это дает нам:
P = 18 500 долларов США / (0,065 * 12) = 23 718 долларов США
Основная сумма кредита составляет 23 718 долларов США.
Формулы сложных процентов
Мы также можем использовать основную сумму и процентную ставку, чтобы найти сложные проценты , которые представляют собой общую сумму процентов как на основную сумму, так и на любые накопленные проценты, не выплаченные в течение периода погашения.Формула сложных процентов:
И если у нас уже есть сумма сложных процентов и нужно найти основную сумму, мы также можем изменить эту формулу в соответствии с нашими потребностями. Формула может показаться сложной, но на самом деле это всего лишь подстановка чисел. Давайте применим его к чему-то другому, кроме суммы кредита.
Формула может показаться сложной, но на самом деле это всего лишь подстановка чисел. Давайте применим его к чему-то другому, кроме суммы кредита.
Предположим, что у нашей подруги Марии есть инвестиционный счет, и по истечении 7 лет остаток на инвестиционном счете составляет 33 818 долларов США, что представляет собой первоначальные инвестиции плюс проценты.Если проценты начисляются ежегодно по ставке 2,5%, какова основная сумма?
Во-первых, нам нужно применить полученные значения к формуле. Мы заменяем на в нашей формуле на 33 818 долларов; это первоначальные инвестиции плюс проценты. Ставка 2,5% за 7 лет, поэтому заменяем 0,025 на r и 7 на t . Проценты начисляются ежегодно или один раз в год, поэтому мы заменяем 1 вместо на .
Когда мы решаем, мы находим, что основная сумма инвестиций составляет 28 450 долларов.
Резюме урока
Основная сумма кредита представляет собой первоначальную сумму займа, но она также относится к первоначальным суммам инвестиций и депозитов.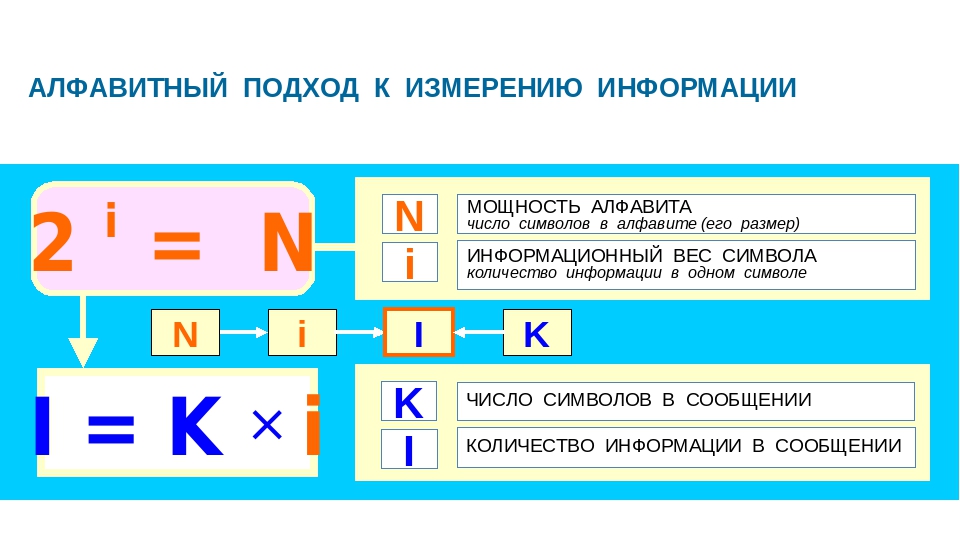 Он используется в различных формулах. Например, формула простых процентов выглядит так:
Он используется в различных формулах. Например, формула простых процентов выглядит так:
I = PRT
, где P — основная сумма, I — сумма процентов, R , — процентная ставка4. T — количество времени. nt ) , чтобы найти основную сумму.
Ключевые термины
- Основная сумма — сумма займа
- Проценты — ставка, уплачиваемая в качестве платы за ссуду денег
- Формула простых процентов — формула для расчета процентов, выплачиваемых только на основную сумму: I = PRT
- Формула основной суммы — формула для расчета основной суммы с использованием процентной ставки и текущей суммы: P = I / (RT)
- Сложные проценты – общая сумма процентов как на основную сумму, так и на любые накопленные проценты, не выплаченные в течение периода погашения
Результаты обучения
После просмотра этого урока проверьте, сможете ли вы:
- Определите правильную формулу для нахождения основной суммы, процентов или сложных процентов по кредиту.

- Рассчитайте основную сумму кредита, зная проценты, процентную ставку и временные рамки.
- Рассчитать проценты, зная основную сумму, процентную ставку и временные рамки.
Каков правильный объем информации? (или правильный размер ваших данных)
Первый вопрос, на который вам нужно ответить, когда вы думаете о том, какую информацию вы хотите получить от программной системы: «Что вы собираетесь с ней делать?» Следующий вопрос: «Насколько легко мы можем упростить процесс сбора данных?»
Знай, что тебе нужно
Наличие информации только ради информации не принесет вам никакой пользы.Вы должны быть в состоянии принять деловое решение с информацией. Например, если вы хотите посмотреть на выполнение строительных работ и тратите время на сортировку и сборку менеджером проекта. Это может быть полезная информация, а может и нет. Все они могут работать с разными клиентами или разными типами работ. Таким образом, тратить все свое время на сбор информации руководителем проекта может быть пустой тратой времени и не давать четкой картины производительности.
Определенные пользователем поля также могут использоваться не по назначению и теряют свою полезность.Если информация введена неверно и непоследовательно, то данные бесполезны. Вы можете идеально ввести все данные, но если вы не можете получить информацию, она бесполезна. Кто-то должен потратить время на ввод данных в программное обеспечение, чтобы вы могли извлечь их обратно из программного обеспечения. Если получить информацию обратно в отчете слишком сложно или невозможно сообщить информацию, то эта информация бесполезна.
Знайте, зачем вы собираете данные
«Мы всегда так делали» — неправильный ответ.Должна быть причина для работы. Это должно повысить ценность. Вы помните в Office Space, где парень составлял отчеты TPS? Никто не знал, почему отчеты были сделаны. Вы и ваши сотрудники должны знать, зачем вы собираете данные и как они будут использоваться.
Будьте проще
Если никто не знает, зачем вводится информация и почему она важна, действительно ли стоит тратить время на добавление этой информации в систему? Подумайте о том, чтобы вернуться к основам и собирать только необходимую и полезную информацию. Подождите, пока технология или процессы наверстают упущенное, а затем вы сможете добавлять дополнительную информацию по мере необходимости. Одним из самых ценных отчетов, которые мы видим, является отчет о прибыльности работы. Он показывает доход от работы, стоимость работы, валовую прибыль от работы и процент валовой прибыли. Удивительно, сколько информации можно получить из 4 простых столбцов данных. Вы можете принимать решения по этому поводу. Вы можете создать отчет такого типа в бухгалтерских системах MOST, и это не требует ввода большого количества дополнительных данных.
Подождите, пока технология или процессы наверстают упущенное, а затем вы сможете добавлять дополнительную информацию по мере необходимости. Одним из самых ценных отчетов, которые мы видим, является отчет о прибыльности работы. Он показывает доход от работы, стоимость работы, валовую прибыль от работы и процент валовой прибыли. Удивительно, сколько информации можно получить из 4 простых столбцов данных. Вы можете принимать решения по этому поводу. Вы можете создать отчет такого типа в бухгалтерских системах MOST, и это не требует ввода большого количества дополнительных данных.
Сводка
Больше данных не значит больше данных. Это просто больше данных. Точно так же, как большее количество одежды в вашем шкафу не равно лучшему гардеробу. Это просто означает больше одежды. Я предпочел бы действительно хороший, хорошо продуманный гардероб, который сделает мою жизнь проще, чем большой беспорядок, который только сделает мою жизнь более запутанной. Ваше программное обеспечение для бухгалтерского учета должно предоставлять информацию, необходимую для принятия правильных бизнес-решений.
Использовать встроенные функции Excel для поиска данных в таблице или диапазоне ячеек
Сводка
В этой пошаговой статье описывается, как найти данные в таблице (или диапазоне ячеек) с помощью различных встроенных функций в Microsoft Excel.Вы можете использовать разные формулы для получения одного и того же результата.
Создайте образец рабочего листа
В этой статье используется образец рабочего листа для иллюстрации встроенных функций Excel. Рассмотрим пример ссылки на имя из столбца A и возврата возраста этого человека из столбца C. Чтобы создать этот рабочий лист, введите следующие данные в пустой рабочий лист Excel.
Введите значение, которое хотите найти, в ячейку E2.Вы можете ввести формулу в любую пустую ячейку на том же листе.
|
А |
Б |
С |
Д |
Э |
||
|
1 |
Имя |
Отдел |
Возраст |
Найти значение |
||
|
2 |
Генри |
501 |
28 |
Мэри |
||
|
3 |
Стэн |
201 |
19 |
|||
|
4 |
Мэри |
101 |
22 |
|||
|
5 |
Ларри |
301 |
29 |
Определения терминов
В этой статье для описания встроенных функций Excel используются следующие термины:
|
Срок |
Определение |
Пример |
|
Массив таблиц |
Вся интерполяционная таблица |
А2:С5 |
|
Искомое_значение |
Значение, которое нужно найти в первом столбце Table_Array. |
Е2 |
|
Lookup_Array |
Диапазон ячеек, содержащий возможные значения поиска. |
А2:А5 |
|
Col_Index_Num |
Номер столбца в Table_Array, для которого должно быть возвращено соответствующее значение. |
3 (третий столбец в Table_Array) |
|
Массив_результатов |
Диапазон, содержащий только одну строку или столбец. |
С2:С5 |
|
Range_Lookup |
Логическое значение (ИСТИНА или ЛОЖЬ).Если TRUE или опущено, возвращается приблизительное совпадение. Если FALSE, он будет искать точное совпадение. |
ЛОЖЬ |
|
Top_cell |
Это ссылка, от которой вы хотите получить смещение. Top_Cell должен ссылаться на ячейку или диапазон соседних ячеек.В противном случае СМЕЩ возвращает #ЗНАЧ! значение ошибки. |
|
|
Offset_Col |
Это количество столбцов слева или справа, на которое должна ссылаться верхняя левая ячейка результата. |

 Он должен быть того же размера, что и Lookup_Array или Lookup_Vector.
Он должен быть того же размера, что и Lookup_Array или Lookup_Vector.  Например, «5» в качестве аргумента Offset_Col указывает, что верхняя левая ячейка в ссылке находится на пять столбцов справа от ссылки.Offset_Col может быть положительным (что означает справа от начальной ссылки) или отрицательным (что означает слева от начальной ссылки).
Например, «5» в качестве аргумента Offset_Col указывает, что верхняя левая ячейка в ссылке находится на пять столбцов справа от ссылки.Offset_Col может быть положительным (что означает справа от начальной ссылки) или отрицательным (что означает слева от начальной ссылки). Функции
ПРОСМОТР()
Функция ПРОСМОТР находит значение в одной строке или столбце и сопоставляет его со значением в той же позиции в другой строке или столбце.
Ниже приведен пример синтаксиса формулы ПРОСМОТР:
=ПРОСМОТР(Искомое_Значение,Искомый_Вектор,Результативный_Вектор)
Следующая формула определяет возраст Марии в образце рабочего листа:
=ПРОСМОТР(E2,A2:A5,C2:C5)
Формула использует значение «Мария» в ячейке E2 и находит «Мария» в векторе поиска (столбец A). Затем формула сопоставляется со значением в той же строке результирующего вектора (столбец C). Поскольку «Мария» находится в строке 4, функция ПРОСМОТР возвращает значение из строки 4 в столбце C (22).
Затем формула сопоставляется со значением в той же строке результирующего вектора (столбец C). Поскольку «Мария» находится в строке 4, функция ПРОСМОТР возвращает значение из строки 4 в столбце C (22).
ПРИМЕЧАНИЕ. Функция ПРОСМОТР требует, чтобы таблица была отсортирована.
Для получения дополнительных сведений о функции ПРОСМОТР щелкните следующий номер статьи базы знаний Майкрософт:
Как использовать функцию ПРОСМОТР в Excel
ВПР()
Функция VLOOKUP или вертикального поиска используется, когда данные перечислены в столбцах.Эта функция ищет значение в крайнем левом столбце и сопоставляет его с данными в указанном столбце в той же строке. Вы можете использовать VLOOKUP для поиска данных в отсортированной или несортированной таблице. В следующем примере используется таблица с несортированными данными.
Ниже приведен пример синтаксиса формулы VLOOKUP :
=ВПР(Искомое_Значение,Таблица_Массив,Количество_индекса_столбца,Диапазон_просмотра)
Следующая формула определяет возраст Марии в образце рабочего листа:
=ВПР(E2,A2:C5,3,ЛОЖЬ)
Формула использует значение «Мария» в ячейке E2 и находит «Мария» в крайнем левом столбце (столбец A).Затем формула сопоставляется со значением в той же строке в Column_Index. В этом примере используется «3» в качестве Column_Index (столбец C). Поскольку «Мария» находится в строке 4, ВПР возвращает значение из строки 4 в столбце C (22).
Для получения дополнительных сведений о функции VLOOKUP щелкните следующий номер статьи базы знаний Майкрософт:
Как использовать ВПР или ГПР, чтобы найти точное совпадение
ИНДЕКС() и ПОИСКПОЗ()
Вы можете использовать функции ИНДЕКС и ПОИСКПОЗ вместе, чтобы получить те же результаты, что и при использовании ПРОСМОТР или ВПР .
Ниже приведен пример синтаксиса, который объединяет ИНДЕКС и ПОИСКПОЗ для получения тех же результатов, что и ПРОСМОТР и ВПР в предыдущих примерах:
= ИНДЕКС(Таблица_Массив,ПОИСКПОЗ(Искомое_Значение,Искомый_Массив,0),Количество_Индекса_Столбца)
Следующая формула определяет возраст Марии в образце рабочего листа:
=ИНДЕКС(A2:C5,ПОИСКПОЗ(E2,A2:A5,0),3)
Формула использует значение «Мария» в ячейке E2 и находит «Мария» в столбце A.Затем оно соответствует значению в той же строке в столбце C. Поскольку «Мария» находится в строке 4, формула возвращает значение из строки 4 в столбце C (22).
ПРИМЕЧАНИЕ. Если ни одна из ячеек в Lookup_Array не соответствует Lookup_Value («Mary»), эта формула вернет #N/A.
Для получения дополнительных сведений о функции ИНДЕКС щелкните следующий номер статьи базы знаний Майкрософт:

Как использовать функцию ИНДЕКС для поиска данных в таблице
СМЕЩ() и ПОИСКПОЗ()
Вы можете использовать функции OFFSET и MATCH вместе, чтобы получить те же результаты, что и в предыдущем примере.
Ниже приведен пример синтаксиса, который объединяет OFFSET и MATCH для получения тех же результатов, что и LOOKUP и VLOOKUP :
= OFFSET(top_cell,MATCH(Lookup_Value, Lookup_Array,0),Offset_Col)
Эта формула определяет возраст Марии в образце рабочего листа:
=СМЕЩЕНИЕ(A1,ПОИСКПОЗ(E2,A2:A5,0),2)
Формула использует значение «Мария» в ячейке E2 и находит «Мария» в столбце A.Затем формула сопоставляется со значением в той же строке, но на два столбца правее (столбец C). Поскольку «Мария» находится в столбце A, формула возвращает значение в строке 4 столбца C (22).
Для получения дополнительных сведений о функции OFFSET щелкните следующий номер статьи базы знаний Майкрософт:
Как использовать функцию СМЕЩЕНИЕ
Как рассчитать среднее значение (с примерами)
- Руководство по карьере
- Развитие карьеры
- Как рассчитать среднее значение (с примерами)
30 июня 2021 г.
Определение значения данных может быть ценным инструментом для компаний, заинтересованных в анализе своих продаж и расходов.В этой статье мы объясним, что такое среднее значение и чем оно отличается от медианы и моды. Затем мы покажем вам, как вычислить среднее значение на нескольких примерах.
Связанный: Методы принятия решений на рабочем месте
Как рассчитать среднее значение?
Чтобы найти среднее значение, сложите все точки данных, а затем разделите эту сумму на общее количество точек данных.
Существует много причин для нахождения среднего значения набора данных. Например, компания может использовать среднее значение, чтобы найти среднюю сумму денег, потраченную на коммунальные услуги в течение года, и использовать эту информацию для составления реалистичного бюджета на следующий год.Среднее значение может быть аналогичным образом применено к количеству продаж, посещению клиентов или любому другому набору данных.
Среднее значение лучше всего работает с набором данных, имеющим относительно близкие по диапазону числа. Выбросы чисел могут исказить среднее значение. Например:
Один владелец франшизы управляет семью ресторанами быстрого питания. Они хотят найти среднее количество сотрудников в каждом магазине.
-
магазин 1 = 11 сотрудников
-
магазин 2 = 10 сотрудников
-
магазин 3 = 25 сотрудников
-
магазин 4 = 11 сотрудников
-
магазин 5 = 13 сотрудников
-
магазин 6 = 12 сотрудников
-
Магазин 7 = 14 сотрудников
В магазине 3 работает гораздо больше сотрудников, чем в любом другом магазине. Это число сдвинет среднее значение вверх и от центра набора данных. Существуют и другие измерения наборов данных, которые вы можете использовать в сочетании со средним значением, чтобы лучше понять ваши цифры.
Это число сдвинет среднее значение вверх и от центра набора данных. Существуют и другие измерения наборов данных, которые вы можете использовать в сочетании со средним значением, чтобы лучше понять ваши цифры.
Связано: Управление операциями: все, что вам нужно знать
Среднее, медиана и мода
Среднее, медиана и мода — все это метрики, которые предоставляют ценную информацию о наборах данных:
-
Среднее: среднее или типичное значение, набора данных
-
Медиана: Число в середине набора данных
-
Мода: Число, наиболее часто встречающееся в наборе данных
Каждый из этих показателей говорит что-то свое о наборе данных.Среднее дает среднее значение и лучше всего используется с наборами данных, близкими по диапазону. Медиана, напротив, отлично подходит для наборов данных с выбросами. Поскольку медиана определяет число в центре набора данных, она дает четкое представление о том, где находится середина, несмотря на широкий диапазон чисел. Этот режим полезен, если вы ищете тенденции в своих числах, поскольку он определяет наиболее распространенное число в наборе данных.
Этот режим полезен, если вы ищете тенденции в своих числах, поскольку он определяет наиболее распространенное число в наборе данных.
Например, посмотрите на числа из примера быстрого питания в порядке от меньшего к большему:
10, 11, 11, 12, 13, 14, 25 посередине, с тремя цифрами ниже и на три цифры выше.Режим этого набора данных равен 11, потому что он появляется чаще всего (дважды). Владелец франшизы теперь может использовать эти показатели для информирования будущих решений, таких как покупка продукта.
См. также: Как анализ данных может улучшить процесс принятия решений
Как рассчитать среднее значение
Выполните следующие действия, чтобы рассчитать среднее значение набора данных:
1. Соберите набор данных
Решите, какую информацию вы хотите получить использование, например доход, посещения вашего магазина или инвентарь. Перечислите все ваши точки данных.
Пример: Давайте воспользуемся приведенными выше числами от владельца франшизы быстрого питания: 10, 11, 11, 12, 13, 14, 25.
2. Подсчитайте точки данных
Посмотрите на свой список точек данных. Подсчитайте количество точек данных в вашем наборе данных. Напишите это число рядом со своим списком и обозначьте его буквой «n».
Пример. В нашем наборе данных семь чисел, поэтому n = 7.
3. Создайте уравнение
Чтобы найти среднее значение, сложите все точки данных вместе и разделите на n.
Пример: 10 + 11 + 11 + 12 + 13 + 14 + 25 / 7 = 13.7. Среднее значение для нашего набора данных равно 14, поскольку расчет средней численности сотрудников имеет смысл округлить до ближайшего целого числа. Среднее количество сотрудников, работающих в каждом отдельном магазине, равно 14.
Примеры
Нахождение среднего значения набора данных имеет множество применений в деловом мире. См. несколько примеров ниже:
Пример 1
F&G Heating имеет пять складов, все с инвентаризацией печей на месте. Они заинтересованы в определении среднего количества печей во всех своих магазинах.
-
-
Магазин 1 имеет 20 печей
-
Магазин 2 имеет 32 печи
-
Магазин 3 имеет 18 печей
-
Магазин 4 имеет 29 печей
-
Магазин 5 имеет 25 печей
формула для расчета среднего значения F&G Heating записывает следующее уравнение:
20 + 32 + 18 + 29 + 25 / 5 = 25
Среднее количество печей на складе в каждом магазине равно 25.
Пример 2
Katie’s Corner — магазин мороженого, заинтересованный в определении среднего количества клиентов в день.Они отслеживают посещения клиентов в течение недели и собирают следующие данные:
-
Понедельник: 138 человек получили мороженое
-
Вторник: 98 человек получили мороженое
-
Среда: 111 человек получили мороженое
3
- 0 Четверг: 145 человек получили мороженое
-
Пятница: 214 человек получили мороженое
-
Суббота: 301 человек получили мороженое
-
Воскресенье: 276 человек получили мороженое это уравнение:
138 + 98 + 111 + 145 + 214 + 301 + 276 / 7 = 183
Среднее количество клиентов, получающих мороженое в Katie’s Corner, составляет 183 человека в день.

Пример 3
Neighbourhood Hardware хочет знать свой средний доход от продаж в месяц. Они оглядываются на предыдущие 12 месяцев и составят список продаж:
-
январь: $ 12,527
-
февраля: $ 10,248
-
марта: $ 11 241
-
апрель: $ 13 111
-
Май: $ 14 135
-
-
июня: $ 14,895
-
Июль
-
августа: $ 14 573
-
-
-
-
Ноябрь
-
-
Декабрь: $ 15 102
-
Оборудование соседства рассчитывает в среднем с этим уравнением:
$ 12,527 + $ 10,248 + $ 11 241 + $ 13 111 + $ 14 135 + $ 14 895 + $ 15 249 + $ 14 573 + $ 13 581 + $ 12 249 + $ 14 249 + $ 15 102/12 = $ 13 430
среднемесячный доход соседства составляет 13 430 долларов .
Сколько данных будет создаваться каждый день в 2022 году? [Вы будете в шоке!]
Вы когда-нибудь задумывались, сколько данных создается каждый день? Или, может быть, вам интересно узнать, сколько данных средний человек использует дома? Благодаря изобретению мобильных технологий, таких как смартфоны и планшеты , наряду с инновациями в мобильных сетях и Wi-Fi , создание и потребление данных постоянно растет.
Итак, сколько данных производится каждый день в этом технически подкованном мире? Прежде чем мы углубимся в детали, вот краткий обзор.
Потрясающая статистика роста данных (выбор редакции)
Теперь можно увидеть, сколько данных создается каждый день, а также сколько данных мы потребляем регулярно. Вы можете быть удивлены, узнав, что:
- В 2020 году люди создавали 1,7 МБ данных каждую секунду.
- К 2022 году 70% мирового ВВП будет оцифровано.
- В 2021 году 68% пользователей Instagram просматривают фотографии брендов.
- К 2025 году более 200 зеттабайт данных будут храниться в облачных хранилищах по всему миру.
- В 2020 году пользователи отправляли около 500 000 твитов в день.
- К концу 2020 года 44 зеттабайта составят всю цифровую вселенную.
- Каждый день отправляется 306,4 миллиарда электронных писем и делается 500 миллионов твитов .
Сколько данных мы используем?
Много.
А теперь пора заканчивать… Шучу, шучу.
Учитывая, сколько данных находится в Интернете, фактический объем используемых данных трудно подсчитать.
Но если мы говорим о том, сколько данных создается каждый день, текущая оценка составляет 1,145 триллиона МБ в день .
Это еще не все.
1. В среднем каждый человек создавал не менее 1,7 МБ данных в секунду в 2020 году.
(Источник: Домо)
Почему 1,7 МБ ? Наша следующая статистика даст больше перспективы.
Пойдем со мной…
2. В 2020 году мы ежедневно создавали 2,5 квинтиллиона байтов данных.
(Источник: Домо)
Если вам интересно сколько данных средний человек использует в месяц , вы можете начать с изучения того, сколько данных люди создавали каждый день в среднем в 2020 году. Эта цифра составляла 2,5 квинтиллиона байтов в день .
В квинтиллионе 18 нулей. Просто к вашему сведению.
3. К 2025 году люди будут генерировать 463 эксабайта данных каждый день.
(Источник: Raconteur)
Основываясь на том, сколько данных уже генерируется людьми каждый день через социальные сети, обмен видео и общение , это число, несомненно, увеличится.
Теперь поговорим об Интернете.
Пока вы читаете это, на вашем устройстве хранится много бесполезных данных. Вы можете рассмотреть возможность использования инструмента для освобождения места и удаления ненужных файлов.
Статистика роста Интернета
Статистика роста использования Интернета говорит нам о том, что люди во всем мире все чаще получают доступ к Интернету . Логично, что число интернет-пользователей и поисковых запросов тоже увеличивается. Этот впечатляющий темп роста информации будет только продолжаться.
Сейчас.
Попробуйте угадать, сколько активных интернет-пользователей.
4. В январе 2021 года во всем мире насчитывалось 4,66 миллиарда активных интернет-пользователей.
(Источник: Statista)
Рост Интернета Статистические данные Statista показывают, что 4,66 миллиарда человек пользуются Интернетом по состоянию на январь 2021 года. Это почти 60% населения мира.
Это ошеломляющий рост, учитывая, что их было всего 2.6 миллиардов интернет-пользователей в 2013 году.
Похоже, мобильные телефоны были более популярны, чем другие устройства, с 4,28 миллиардами уникальных пользователей . Поскольку удобство для мобильных устройств сегодня является главной функцией большинства сайтов, это имеет большой смысл.
Кстати, ты хоть представляешь, сколько там сайтов? Вот ответ.
5. В 2020 году было 319 миллионов новых пользователей Интернета.
(Источник: Отчет о данных)
Согласно росту интернет-статистики, 300+ миллионов новых пользователей присоединились к Интернету в 2020 году. По состоянию на 2021 год темпы роста составляют 7% , что соответствует примерно 875 тысячам новых пользователей в день .
По состоянию на 2021 год темпы роста составляют 7% , что соответствует примерно 875 тысячам новых пользователей в день .
6. К концу 2021 года Google может выполнить два триллиона поисковых запросов.
(Источник: ILS)
Google является поисковой системой номер один с долей рынка 91% . Интересно, сколько людей используют Google?
Эксперты прогнозируют, что поиски движка составят около 2 трлн за весь 2021 год .Это соответствует 6 миллиардам поисковых запросов в день .
Статистика использования социальных сетей
Сколько именно данных создается каждый день в социальных сетях? Сами по себе статистические данные об использовании социальных сетей говорят о многом. Вот некоторые сведения о популярных платформах Facebook и Twitter .
7. 15% контента на Facebook — это видео.
(Источник: Social Insider)
Видео оставляют свой след в Facebook, крупнейшей социальной сети . В 2020 году на сайте было 10,5 млн видео . 71% из них пришли с аккаунтов с более чем 100000 подписчиков .
В 2020 году на сайте было 10,5 млн видео . 71% из них пришли с аккаунтов с более чем 100000 подписчиков .
8. В 2020 году ежедневно публиковалось пятьсот тысяч новых твитов.
(Источник: Дэвид Сайс)
Трудно представить, сколько твитов пользователей отправляют в день .
Полмиллиона твитов за день — это оооочень много!
Это означает почти два миллиарда в год .А теперь представьте, сколько потенциальных клиентов могут охватить бренды, используя этот режим.
9. В 2020 году Facebook ежедневно генерировал четыре петабайта данных.
(Источник: Кинста)
Как вы знаете, один петабайт равен одному миллиону гигабайт . Так как же Facebook использовал четыре петабайта в день?
Это связано с количеством времени, которое пользователи проводят в Facebook, о чем свидетельствует статистика роста данных за 2020 год. На самом деле, человек в Facebook больше, чем в любой другой социальной сети .
На самом деле, человек в Facebook больше, чем в любой другой социальной сети .
«Facebook мертв». Конечно, тиктокеры, конечно. Если бы вы только знали, сколько американцев используют Facebook.
10. 68% трафика Instagram просматривают фотографии брендов в 2021 году.
(Источник: Business of Apps)
Почти 70% посетителей в Instagram просматривают фотографии брендов в 2021 году. Видео брендов тоже не худые: 66% просмотров .
Итак, что еще люди проверяют в социальных сетях?
Вот разбивка по наиболее заметным показателям:
- Контент пользователя: 67%
- Фото инфлюенсеров: 63%
- Видео знаменитостей: 62%
Статистика роста видео
Статистика роста видео говорит нам, что YouTube, Twitch и Snapchat , как правило, являются самыми популярными социальными платформами для обмена видео. Что интересно, так это разница в данных, которые они используют индивидуально.
Что интересно, так это разница в данных, которые они используют индивидуально.
11. Видео 480p на YouTube использует 8,3 МБ в минуту и 500 МБ в час.
(Источник: WhistleOut)
«Сколько данных использует видео на YouTube?» — довольно распространенный вопрос.
Во многом зависит от качества воспроизводимого видео. 480p — это стандартное разрешение , однако более высокие настройки качества, такие как 1080p , неизбежно будут использовать больше данных.
12. Видео 480p на Twitch использует от 0,405 ГБ до 0,54 ГБ в час.
(Источник: Схема потока)
Хотя это может показаться немного (и на самом деле это не так), правда в том, что это больше, чем на других платформах, таких как YouTube и Snapchat .
13. Для отправки одного Snapchat требуется 1 МБ.
(Источник: Canstarblue)
Если вы хотите узнать сколько данных использует Snapchat , я боюсь общедоступных данных, касающихся . Тем не менее, это приблизительно , что один Snapchat стоит 1 МБ для отправки .
Тем не менее, это приблизительно , что один Snapchat стоит 1 МБ для отправки .
Помните, что вам потребуется больше для изображений высокой четкости, видео или Snapchat с фильтрами.
14. В 2020 году время просмотра видео в Twitter выросло на 72%.
(Источник: Hootsuite)
Твиттер славился небольшими сообщениями. Сейчас количество просмотров видео на сайте быстро растет. В 2020 году он вырос на 72%.Это было бы хорошее время для брендов, чтобы извлечь выгоду из размещения видео на платформе.
Статистика связи
То, как часто вы используете коммуникационные приложения или инструменты, оказывает огромное влияние на то, сколько данных создается каждый день.
15. Одно текстовое сообщение использует эквивалент 0,0001335 МБ данных.
(Источник: Side Hustle Nation)
Определить используемые данные на основе того, сколько текстов отправляется в день, довольно сложно. SMS-сообщения обычно включены в тарифный план телефона, поэтому мы не можем указать точную цифру. Что мы знаем, так это то, что 0.0001335MB количество данных, используемых для отправки одного текста, едва ли удивительно.
SMS-сообщения обычно включены в тарифный план телефона, поэтому мы не можем указать точную цифру. Что мы знаем, так это то, что 0.0001335MB количество данных, используемых для отправки одного текста, едва ли удивительно.
16. Для обмена сообщениями в WhatsApp обычно используются только килобайты данных.
(Источник: Quora)
Хотите узнать, сколько данных использует WhatsApp для одного сообщения? Правда в том, что обычно не так много. Однако, если вы поделитесь видео, это может использовать более 1 МБ данных.Фактически, это обычно использует между 500 МБ и 2 ГБ данных.
17. Ожидайте использование от 0,5 МБ до 1,3 МБ в минуту для вызова VoIP.
(Источник: GenVoice)
Опять переменная. Все сводится к технологии , используемой вашим VoIP-провайдером , а также к вашей личной привычке использования.
18. В 2024 году количество электронных писем будет составлять около 361 миллиарда каждый день.

(Источник: Statista)
Статистика роста данных показывает, что количество ежедневных электронных писем, летающих по сети, увеличится на 55.2 миллиарда в ближайшие несколько лет. Способ общения по-прежнему остается предпочтительным как для брендов, так и для отдельных лиц, несмотря на достижения в чатах и приложениях для обмена сообщениями.
Статистика роста больших данных
Статистика роста данных в 2021 году говорит нам о том, что большие данные растут беспрецедентными темпами. большая часть мировых данных появилась только за последних двух лет , как показывает статистика роста данных. Между тем, машинно-генерируемых данных будут составлять 40% интернет-данных в этом году.К счастью, у нас есть инструменты визуализации данных, чтобы сделать все эти данные понятными.
19. К 2022 году почти 70% ВВП будут оцифрованы.
(Источник: IORG)
Самый большой урок, который Covid-19 преподал экономике, заключается в том, что оцифровка имеет первостепенное значение . Наиболее существенным преимуществом является то, что работа по-прежнему может продолжаться без сообщения о физических рабочих местах.
Наиболее существенным преимуществом является то, что работа по-прежнему может продолжаться без сообщения о физических рабочих местах.
Статистика роста данных показывает, что к 2022 году более 70% ВВП во всем мире пройдут ту или иную форму цифровизации.Спрос на программное обеспечение для совместной работы , облачные решения и бесконтактные услуги будет расти по мере того, как правительства и организации стремятся отказаться от аналоговых систем.
Это еще не все.
К 2023 году инвестиции в Direct Digital Transformation (DXT) составят 6,8 трлн долларов . В течение этого времени организации будут продолжать работать над своими существующими системами, чтобы найти лучшие способы предоставления услуг, распределенной рабочей силы и сокращения затрат.
20. Объем облачных хранилищ данных по всему миру к 2025 году составит более 200 зеттабайт.

(Источник: Cybercrime Magazine)
Рост данных хранилища Статистика показывает, что общедоступная и частная облачная инфраструктура получат 200+ зеттабайт (ZB) данных к 2025 году . Это по сравнению с 4.4ZB 2019 года и 44ZB 2020 года.
Это палка о двух концах.
Положительным будет то, что предприятия выполнят большую часть своих планов цифровизации для производства этих данных . недостатком будет то, что киберпреступность будет процветать .
Но это произойдет только в том случае, если организации и правительства откажутся от кибербезопасности, что маловероятно.
21. В 2020 году более 40% интернет-данных приходилось на машинно-генерируемые данные.
(Источник: Справочник по исследованиям облачных инфраструктур для анализа больших данных )
Статистика роста машинного обучения данных и роста веб-данных показывает, что человек сгенерировали 60% данных в Интернете в прошлом году. Глобальная стоимость машинных языков составит 117,19 миллиардов долларов к концу 2027 года .
Глобальная стоимость машинных языков составит 117,19 миллиардов долларов к концу 2027 года .
Статистика роста IoT
IoT не показывает никаких признаков замедления. В самом деле, промышленность бум . По мере увеличения количества устройств IoT количество активных пользователей и подписок также увеличивается . Вот три ключевых статистических данных, которые вам необходимо знать о технологии IoT .
22. К 2023 году ожидается около 1.3 миллиарда подписок IoT.
(Источник: Statista)
Так почему же эта цифра такая высокая? Хотя многие бытовые IoT-устройства действительно существуют, многие из них используются вне дома в таких местах, как фабрики и больницы.
23. К 2030 году количество устройств IoT достигнет 25,44 миллиарда.
(Источник: Statista)
В 2019 году количество подключенных устройств составляло всего 7,74 миллиарда. Согласно статистике роста данных, к 2030 году это число увеличится более чем в три раза.
Согласно статистике роста данных, к 2030 году это число увеличится более чем в три раза.
В потребительском сегменте основными вариантами использования технологии будут мультимедийные устройства, такие как смартфоны. Другие примеры включают интеллектуальную сеть, отслеживание и мониторинг активов, автономные транспортные средства и ИТ-инфраструктуру.
24. В 2020 году в Китае было 3,17 миллиарда устройств IoT.
(Источник: Statista)
В 2020 году в Китае было более трех миллиардов гаджетов, подключенных к Интернету вещей. Что касается расходов на оборудование, Китай был на первом месте в Азиатско-Тихоокеанском регионе со 168 миллиардами долларов в 2019 году.Южная Корея заняла второе место с 26 миллиардами долларов.
Есть еще:
Прогнозы показывают, что к 2030 году регион Азиатско-Тихоокеанского региона станет крупнейшим потребителем Интернета вещей.
Насколько велик размер данных?
Теперь давайте посмотрим, как маленькие данные становятся большими данными.
Сколько стоит байт?
1 байт равен 0,001 килобайт.
Сколько стоит килобайт?
1 килобайт равен 1024 байтам.
Сколько стоит мегабайт?
1 мегабайт равен 1024 килобайтам.
Сколько стоит гигабайт?
1 гигабайт равен примерно 1024 мегабайтам.
Сколько стоит терабайт?
1 терабайт равен 1024 ГБ.
Сколько стоит петабайт?
1 петабайт равен 1024 терабайтам.
Сколько стоит эксабайт?
1 эксабайт примерно равен 1024 петабайтам.
Сколько стоит зеттабайт?
1 зеттабайт равен примерно одному триллиону гигабайт.
Сколько стоит йоттабайт?
1 йоттабайт равен 1204 зеттабайтам.
Теперь мы официально чувствуем себя графом фон графом.
Завершение
Статистика роста данных давала большие цифры. И они будут только увеличиваться.
Вот что она сказала.
В любом случае.
Поскольку все больше и больше людей получают доступ в Интернет ежедневно , люди используют социальные сети и другие формы цифрового общения, такие как VoIP-звонки и текстовые приложения , все больше и больше.Вот почему в последнее время так популярны программы для визуализации данных и инструменты для инфографики — они могут легко преобразовывать тонны данных в удобную для восприятия информацию.
Учитывая, что большая часть мировых данных была создана только за последних двух лет , будет интересно задать вопрос «сколько данных создается каждый день» через пять или десять лет.
Думаешь, граф фон Граф сможет это сосчитать?
.