
36 баллов по биологии. Перевод баллов егэ по русскому языку. Минимальные баллы на ЕГЭ
Каждый выпускник отлично понимает, что для успешного поступления на интересующую специальность необходимо качественно подготовится к ЕГЭ 2018 и набрать максимально возможные баллы. Что же значит «хорошо сдать экзамен» и сколько баллов будет достаточно для того, что бы побороться за бюджетное место в том или ином ВУЗе? Об этом пойдет речь в данной статье.
Мы затронем такие важные вопросы:
Прежде всего, важно понимать, что существует:
- минимальный балл, дающий право на получение аттестата;
- минимальный балл, позволяющий подать документы в ВУЗ;
- минимальный балл, достаточный для реального поступления на бюджет по конкретной специальности в определенном университете России.
Естественно, что эти цифры существенно отличаются.
Минимальный аттестационный балл
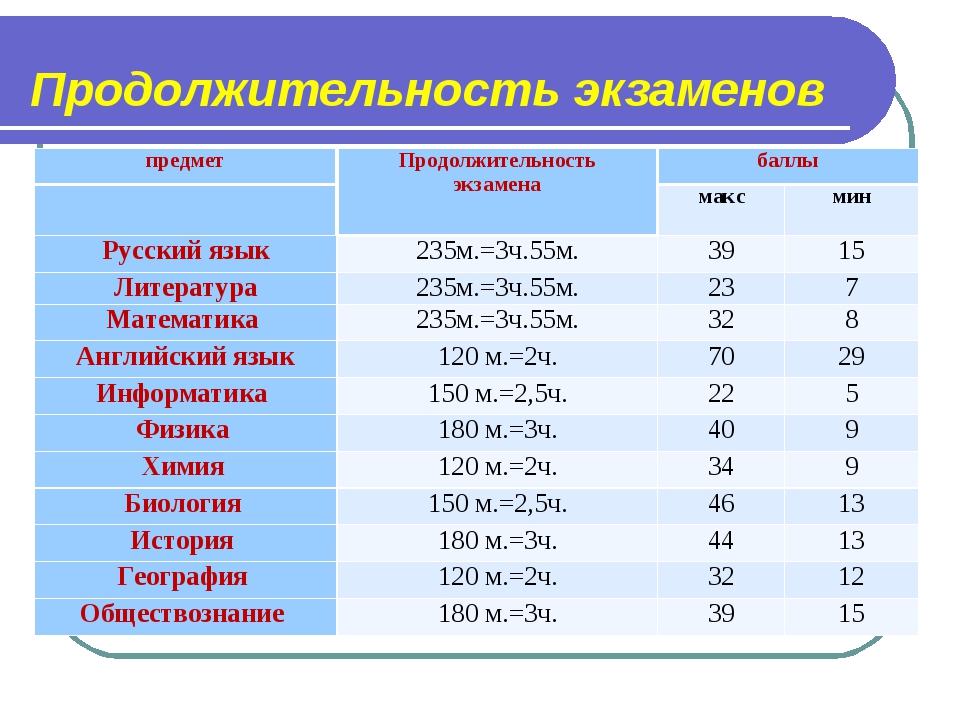
Минимальные аттестационные баллы ЕГЭ установлены для обязательных предметов – русского языка и математики базового уровня и в 2018составляют:
Преодолев данный порог, но, не дотянув до минимального тестового балла, экзаменуемый получит аттестат, но не сможет подать документы в университет.
Минимальный тестовый балл
Тестовый минимум – это пороговое значение, дающее право на вступление в ВУЗ. Иными словами, лица, преодолевшие тестовый порог теоретически имеют право вступить в борьбу за бюджетные места. Хотя, на практике, вступить с минимальными показателями в высоко котируемые университеты практически нереально.
В 2018 году по всем предметам, кроме русского языка и базовой математики тестовые минимальные баллы ЕГЭ совпадают с аттестационными и составляют:
Предмет | Минимальный тестовый балл |
|
Русский язык | |
Математика (базовый уровень) | |
Математика (профильный уровень) | |
Обществознание | |
Литература | |
Иностранный язык | |
Биология | |
Информатика | |
География |
Принцип расчета успешности сдачи единого государственного экзамена предполагает, что испытуемый должен продемонстрировать высокий, средний либо достаточный уровень знаний, соответствующий в школьной шкале оценкам «5», «4» и «3».
В случае неудовлетворительного результата, а также при сдаче на балл, который сам экзаменуемый считает для себя недостаточным, выпускникам предоставляется право пересдачи ЕГЭ.
Минимальный балл для поступления на бюджет
Большинство ВУЗов оглашают пороговый балл, необходимый для претендующих на бюджетное место. Это позволяет каждому абитуриенту реально оценивать перспективы поступления и выбирать университеты и специальности с учетом набранных на ЕГЭ баллов.
В 2018 году можно ориентироваться на тот факт, что в прошлом сезоне средние проходные баллы по всем предметам ЕГЭ среди абитуриентов, поступивших в МГИМО и другие высоко котируемые университеты столицы, колебались между пороговым значением 80-90. Но, для большинства региональных ВУЗов РФ конкурентным результатом можно считать уже 65-75 баллов.
Перевод первичного балла в результирующий
Выполняя задания, предложенные в билете ЕГЭ, экзаменуемый набирает так называемые первичные баллы, максимальное значение которых варьируется в зависимости от предмета.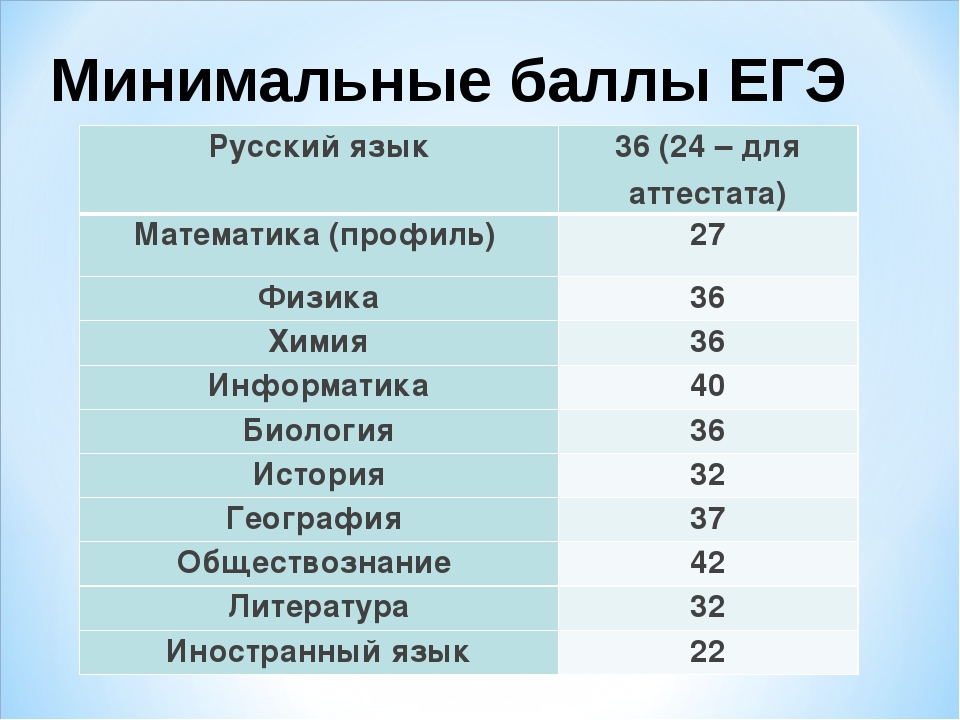 При оценивании уровня знаний, такие первичные баллы переводятся в результирующие, которые заносятся в сертификат и являются базовыми при поступлении.
При оценивании уровня знаний, такие первичные баллы переводятся в результирующие, которые заносятся в сертификат и являются базовыми при поступлении.
С помощью онлайн калькулятора, вы сможете сопоставить первичные и тестовые баллы по интересующим предметам.
Также как в прошлом году, в 2018 набранные при прохождении ЕГЭ баллы влияют на балл аттестата и, хотя официально таблица сопоставления тестового балла и традиционных оценок, не принята, можно приблизительно сопоставить свои баллы прямо сейчас, используя универсальный калькулятор.
Проходные баллы топ 10 ВУЗов России
суммарный |
||
| Московский государственный университет им. М.В. Ломоносова | ||
| Московский физико-технический институт | ||
| Национальный исследовательский ядерный университет «МИФИ» | ||
| Санкт-Петербургский государственный университет | ||
| Московский государственный институт международных отношений | ||
| Национальный исследовательский университет «Высшая школа экономики» | ||
Московский государственный технический университет имени Н. Э. Баумана
Э. Баумана
| ||
| Национальный исследовательский Томский политехнический университет | ||
| Новосибирский национальный исследовательский государственный университет | ||
| Санкт-Петербургский политехнический университет Петра Великого |
Обратите внимание, что средние проходные баллы по разным специальностям в одном ВУЗе могут существенно отличаться. Эта цифра отображает минимальный балл абитуриентов, поступивших на бюджет, и имеет тенденцию изменяться каждый год. Результаты 2017 года могут служить лишь неким ориентиром для абитуриентов 2018, мотивируя к достижению максимально высоких результатов.
На минимальный проходной балл влияет множество факторов, в числе которых:
- общее количество выпускников, подавших заявления и баллы, указанные в их сертификатах;
- число абитуриентов, предоставивших оригиналы документов;
- количество льготников.
Так, увидев свою фамилию на 20 месте в списке специальности, предусматривающей 40 бюджетных мест, можно с уверенностью считать себя студентом. Но, даже если вы окажитесь в этом списке 45, нет повода расстраиваться, если среди стоящих перед вами числится, 5-10 человек, предоставивших копии документов, ведь скорее всего эти люди настроены на другой ВУЗ и подали документы на эту специальность как на запасной вариант.
После проверки заданий ЕГЭ по математике выставляется первичный балл за их выполнение:
- Для базового уровня по математике – от 0 до 20;
- Для профильного уровня по математике – от 0 до 30.
Каждое задание оценивается определенным количеством баллов: чем сложнее задание, тем больше баллов за него можно получить. За верное выполнение каждого задания в ЕГЭ по математике базового уровня дается 1 балл. За верное выполнение заданий в ЕГЭ по математике профильного уровня дается от 1 до 4 баллов в зависимости от сложности задания.
После этого первичный балл переводится в тестовый балл, который указывается в сертификате ЕГЭ. Именно этот балл используется при поступлении в высшие учебные заведения. Перевод баллов ЕГЭ осуществляется с помощью специальной шкалы баллов. Балл за ЕГЭ по математике базового уровня для поступления не нужен, поэтому он не переводится в тестовый балл и не указывается в сертификате ЕГЭ.
Также по баллу за ЕГЭ можно определить приблизительную оценку по пятибалльной шкале, которую бы получил школьник за выполнение заданий на экзамене.
Ниже приведена шкала перевода баллов ЕГЭ по математике для базового и профильного уровней: первичные баллы, тестовые баллы и приблизительная оценка.
Шкала перевода баллов ЕГЭ: математика базовый уровень
Шкала перевода баллов ЕГЭ: математика профильный уровень
Минимальный тестовый балл для поступления в высшие учебные заведения равен 27.
| Первичный балл | Тестовый балл | Оценка |
|---|---|---|
| 0 | 0 | 2 |
| 1 | 5 | |
| 2 | 9 | |
| 3 | 14 | |
| 4 | 18 | |
| 5 | 23 | |
| 6 | 27 | 3 |
| 7 | 33 | |
| 8 | 39 | |
| 9 | 45 | |
| 10 | 50 | 4 |
| 11 | 56 | |
| 12 | 62 | |
| 13 | 68 | 5 |
| 14 | 70 | |
| 15 | 72 | |
| 16 | 74 | |
| 17 | 76 | |
| 18 | 78 | |
| 19 | 80 | |
| 20 | 82 | |
| 21 | 84 | |
| 22 | 86 | |
| 23 | 88 | |
| 24 | 90 | |
| 25 | 92 | |
| 26 | 94 | |
| 27 | 96 | |
| 28 | 98 | |
| 29 | 99 | |
| 30 | 100 |
Общее число участников основного дня основного периода ЕГЭ в 2018 г. превысило 327 тыс. человек, что, как и в предыдущие годы, составило более половины от общего числа участников ЕГЭ. Обществознание — наиболее массовый экзамен, сдаваемый по выбору выпускников, что обусловило крайнюю неоднородность уровня подготовки контингента участников экзамена. Востребованность результатов экзамена для поступления на обучение по широкому спектру специальностей связана с тем, что экзамен включает в себя проверку основ социально-философских, экономических, социологических и правовых знаний и предусматривает высокие требования к уровню подготовки выпускников (даже к достижению минимального балла предъявляется высокий уровень требований).
превысило 327 тыс. человек, что, как и в предыдущие годы, составило более половины от общего числа участников ЕГЭ. Обществознание — наиболее массовый экзамен, сдаваемый по выбору выпускников, что обусловило крайнюю неоднородность уровня подготовки контингента участников экзамена. Востребованность результатов экзамена для поступления на обучение по широкому спектру специальностей связана с тем, что экзамен включает в себя проверку основ социально-философских, экономических, социологических и правовых знаний и предусматривает высокие требования к уровню подготовки выпускников (даже к достижению минимального балла предъявляется высокий уровень требований).
В целом доля участников, не преодолевших минимального балла, в 2018 г. увеличилась в сравнении с 2017 г. и составила 17,4% (в 2017 г. — 13,8%; в 2016 г. — 17,6%).
Число стобалльников в 2018 г. повысилось в сравнении с 2017 г.: 198 против 142. Рост в 2018 г. доли стобалльников до 0,06% (в 2017 г. — 0,04%) и высокобалльников до 7,4% (в 2017 г. — 4,5%) может быть обусловлен дальнейшим распространением практики дифференцированной подготовки выпускников с учетом их индивидуального уровня сформированности системы знаний и умений, а также отмеченным выше усовершенствованием системы оценивания ряда заданий и реализацией системы мер по повышению качества работы предметных комиссий субъектов РФ.
— 4,5%) может быть обусловлен дальнейшим распространением практики дифференцированной подготовки выпускников с учетом их индивидуального уровня сформированности системы знаний и умений, а также отмеченным выше усовершенствованием системы оценивания ряда заданий и реализацией системы мер по повышению качества работы предметных комиссий субъектов РФ.
Более подробные аналитические и методические материалы ЕГЭ 2018 года доступны по ссылке .
На нашем сайте представлены больше 3800 заданий для подготовки к ЕГЭ по обществознанию в 2018 году. Общий план экзаменационной работы представлен ниже.
ПЛАН ЭКЗАМЕНАЦИОННОЙ РАБОТЫ ЕГЭ ПО ОБЩЕСТВОЗНАНИЮ 2019 ГОДА
Обозначение уровня сложности задания: Б — базовый, П — повышенный, В — высокий.
Проверяемые элементы содержания и виды деятельности |
Уровень сложности задания |
Максимальный балл за выполнение задания |
Примерное время выполнения задания (мин. |
| Задание 1. Знать и понимать: биосоциальную сущность человека; основные этапы и факторы социализации личности; место и роль человека в системе общественных отношений; закономерности развития общества как сложной самоорганизующейся системы; тенденции развития общества в целом как сложной динамичной системы, а также важнейших социальных институтов; основные социальные институты и процессы; необходимость регулирования общественных отношений, сущность социальных норм, механизмы правового регулирования; особенности социально-гуманитарного познания (выявление структурных элементов с помощью схем и таблиц) | |||
| Задание 2. Знать и понимать: биосоциальную сущность человека; основные этапы и факторы социализации личности; место и роль человека в системе общественных отношений; закономерности развития общества как сложной самоорганизующейся системы; тенденции развития общества в целом как сложной динамичной системы, а также важнейших социальных институтов; основные социальные институты и процессы; необходимость регулирования общественных отношений, сущность социальных норм, механизмы правового регулирования; особенности социально-гуманитарного познания (выбор обобщающего понятия для всех остальных понятий, представленных в перечне) | |||
Задание 3. Знать и понимать: биосоциальную сущность человека; основные этапы и факторы социализации личности; место и роль человека в системе общественных отношений; закономерности развития общества как сложной самоорганизующейся системы; тенденции развития общества в целом как сложной динамичной системы, а также важнейших социальных институтов; основные социальные институты и процессы; необходимость регулирования общественных отношений, сущность социальных норм, механизмы правового регулирования; особенности социально-гуманитарного познания (соотнесение видовых понятий с родовыми)
Знать и понимать: биосоциальную сущность человека; основные этапы и факторы социализации личности; место и роль человека в системе общественных отношений; закономерности развития общества как сложной самоорганизующейся системы; тенденции развития общества в целом как сложной динамичной системы, а также важнейших социальных институтов; основные социальные институты и процессы; необходимость регулирования общественных отношений, сущность социальных норм, механизмы правового регулирования; особенности социально-гуманитарного познания (соотнесение видовых понятий с родовыми)
|
|||
| Задание 4. | |||
| Задание 5. | |||
| Задание 6. | |||
| Задание 7. Характеризовать с научных позиций основные социальные объекты (факты, явления, процессы, институты), их место и значение в жизни общества как целостной системы | |||
Задание 8. Анализировать актуальную информацию о социальных объектах, выявляя их общие черты и различия; устанавливать соответствия между существенными чертами и признаками изученных социальных явлений и обществоведческими терминами и понятиями
Анализировать актуальную информацию о социальных объектах, выявляя их общие черты и различия; устанавливать соответствия между существенными чертами и признаками изученных социальных явлений и обществоведческими терминами и понятиями
|
|||
| Задание 9. Применять социально-экономические и гуманитарные знания в процессе решения познавательных задач по актуальным социальным проблемам | |||
| Задание 10. Осуществлять поиск социальной информации, представленной в различных знаковых системах (рисунок) | |||
| Задание 11. Характеризовать с научных позиций основные социальные объекты (факты, явления, процессы, институты), их место и значение в жизни общества как целостной системы | |||
| Задание 12. Осуществлять поиск социальной информации, представленной в различных знаковых системах (таблица, диаграмма) | |||
Задание 13.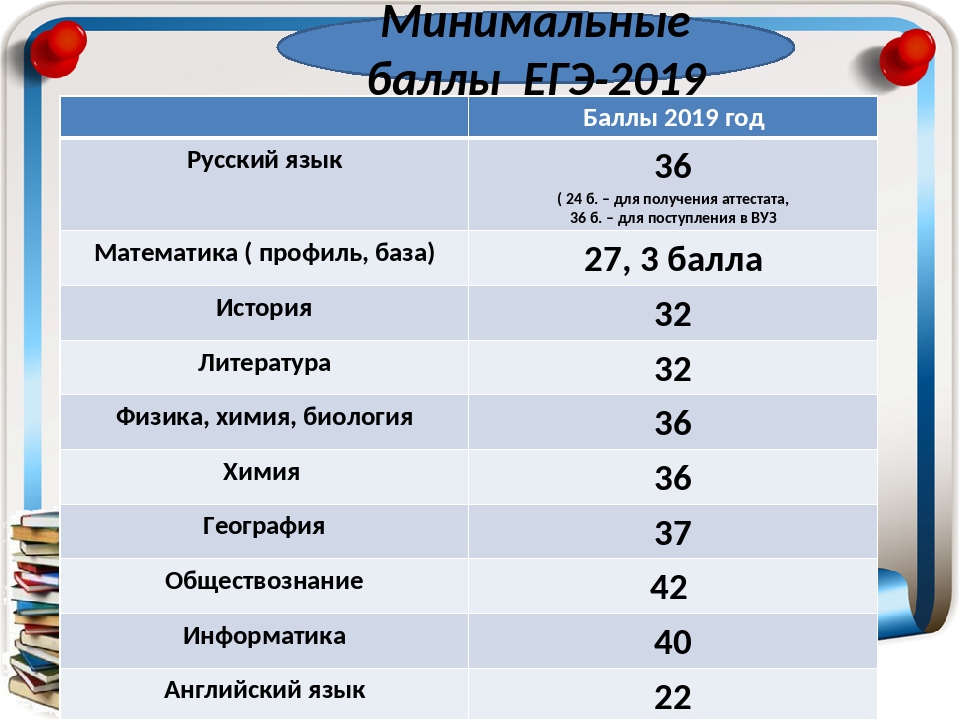 Характеризовать с научных позиций основные социальные объекты (факты, явления, процессы, институты), их место и значение в жизни общества как целостной системы
Характеризовать с научных позиций основные социальные объекты (факты, явления, процессы, институты), их место и значение в жизни общества как целостной системы
|
|||
| Задание 14. Анализировать актуальную информацию о социальных объектах, выявляя их общие черты и различия; устанавливать соответствия между существенными чертами и признаками изученных социальных явлений и обществоведческими терминами и понятиями | |||
| Задание 15. Применять социально-экономические и гуманитарные знания в процессе решения познавательных задач по актуальным социальным проблемам | |||
| Задание 16. Характеризовать с научных позиций основы конституционного строя, права и свободы человека и гражданина, конституционные обязанности гражданина РФ | |||
| Задание 17. Характеризовать с научных позиций основные социальные объекты (факты, явления, процессы, институты), их место и значение в жизни общества как целостной системы | |||
Задание 18. Анализировать актуальную информацию о социальных объектах, выявляя их общие черты и различия; устанавливать соответствия между существенными чертами и признаками изученных социальных явлений и обществоведческими терминами и понятиями
Анализировать актуальную информацию о социальных объектах, выявляя их общие черты и различия; устанавливать соответствия между существенными чертами и признаками изученных социальных явлений и обществоведческими терминами и понятиями
|
|||
| Задание 19. Применять социально-экономические и гуманитарные знания в процессе решения познавательных задач по актуальным социальным проблемам | |||
| Задание 20. Систематизировать, анализировать и обобщать неупорядоченную социальную информацию (определение терминов и понятий, соответствующих предлагаемому контексту) | Задание 21. Осуществлять поиск социальной информации; извлекать из неадаптированных оригинальных текстов (правовых, научно-популярных, публицистических и др.) знания по заданным темам; систематизировать, анализировать и обобщать неупорядоченную социальную информацию | ||
Задание 22. Осуществлять поиск социальной информации; извлекать из неадаптированных оригинальных текстов (правовых, научно-популярных, публицистических и др.) знания по заданным темам; систематизировать, анализировать и обобщать неупорядоченную социальную информацию. Объяснять внутренние и внешние связи (причинно-следственные и функциональные) изученных социальных объектов
Осуществлять поиск социальной информации; извлекать из неадаптированных оригинальных текстов (правовых, научно-популярных, публицистических и др.) знания по заданным темам; систематизировать, анализировать и обобщать неупорядоченную социальную информацию. Объяснять внутренние и внешние связи (причинно-следственные и функциональные) изученных социальных объектов
|
|||
| Задание 23. Объяснять внутренние и внешние связи (причинно-следственные и функциональные) изученных социальных объектов. Раскрывать на примерах изученные теоретические положения и понятия социально-экономических и гуманитарных наук | |||
| Задание 24.
Объяснять внутренние и внешние связи (причинно-следственные и функциональные) изученных социальных объектов. Оценивать действия субъектов социальной жизни, включая личность, группы, организации, с точки зрения социальных норм, экономической рациональности. 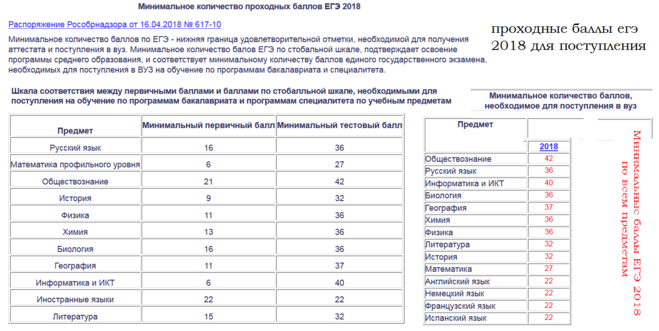 Формулировать на основе приобретенных обществоведческих знаний собственные суждения и аргументы по определенным проблемам |
|||
| Задание 25. Характеризовать с научных позиций основные социальные объекты (факты, явления, процессы, институты), их место и значение в жизни общества как целостной системы (задание на раскрытие смысла понятия, использование понятия в заданном контексте) | |||
| Задание 26. Раскрывать на примерах изученные теоретические положения и понятия социально-экономических и гуманитарных наук (задание, предполагающее раскрытие теоретических положений на примерах) | |||
| Задание 27. Применять социально-экономические и гуманитарные знания в процессе решения познавательных задач по актуальным социальным проблемам (задание-задача) | |||
| Задание 28. Подготавливать аннотацию, рецензию, реферат, творческую работу (задание на составление плана доклада по определенной теме) | |||
Задание 29. Характеризовать с научных позиций основные социальные объекты (факты, явления, процессы, институты), их место и значение в жизни общества как целостной системы. Анализировать актуальную информацию о социальных объектах, выявляя их общие черты и различия; устанавливать соответствия между существенными чертами и признаками изученных социальных явлений и обществоведческими терминами и понятиями. Объяснять внутренние и внешние связи (причинно-следственные и функциональные) изученных социальных объектов. Раскрывать на примерах изученные теоретические положения и понятия социально-экономических и гуманитарных наук. Оценивать действия субъектов социальной жизни, включая личность, группы, организации, с точки зрения социальных норм, экономической рациональности. Формулировать на основе приобретенных обществоведческих знаний собственные суждения и аргументы по определенным проблемам
Характеризовать с научных позиций основные социальные объекты (факты, явления, процессы, институты), их место и значение в жизни общества как целостной системы. Анализировать актуальную информацию о социальных объектах, выявляя их общие черты и различия; устанавливать соответствия между существенными чертами и признаками изученных социальных явлений и обществоведческими терминами и понятиями. Объяснять внутренние и внешние связи (причинно-следственные и функциональные) изученных социальных объектов. Раскрывать на примерах изученные теоретические положения и понятия социально-экономических и гуманитарных наук. Оценивать действия субъектов социальной жизни, включая личность, группы, организации, с точки зрения социальных норм, экономической рациональности. Формулировать на основе приобретенных обществоведческих знаний собственные суждения и аргументы по определенным проблемам
|
 )
)Соответствие между минимальными первичными баллами и минимальными тестовыми баллами 2019 года. Распоряжение о внесении изменений в приложение № 1 к распоряжению Федеральной службы по надзору в сфере образования и науки. .
Распоряжение о внесении изменений в приложение № 1 к распоряжению Федеральной службы по надзору в сфере образования и науки. .
ОФИЦИАЛЬНАЯ ШКАЛА 2019 ГОДА
ПОРОГОВЫЙ БАЛЛ
Распоряжением Рособрнадзора установлено минимальное количество баллов, подтверждающее освоение участниками экзаменов основных общеобразовательных программ среднего (полного) общего образования в соответствии с требованиями федерального государственного образовательного стандарта среднего (полного) общего образования.
ПОРОГ ПО ОБЩЕСТВОЗНАНИЮ: 22 первичных баллов (42 тестовых балла).
ЭКЗАМЕНАЦИОННЫЕ БЛАНКИ
Скачать бланки в высоком качестве можно по ссылке .
ЧТО МОЖНО ВЗЯТЬ С СОБОЙ НА ЭКЗАМЕН
На данном экзамене применение дополнительного оснащения и материалов не предусмотрено.
Авторы заданий для подготовки к ЕГЭ:
М. Ю. Брандт,
О. В. Кишенкова,
Г. Э. Королева,
Е. С. Королькова,
О. А. Котова,
А. Ю. Лазебникова,
Т. Е. Лискова,
Е. Л. Рутковская,
и др.; материалы сайта http://ege.yandex.ru.
Л. Рутковская,
и др.; материалы сайта http://ege.yandex.ru.
Шкалу перевода баллов ЕГЭ-2017 обязательно должны знать будущие абитуриенты и выпускники средней школы. Она им пригодится в процессе самоподготовки. В частности, шкала понадобится для оценки своих ответов при выполнении тренировочных тестов. В обзоре мы разберём, что такое первичные и тестовые баллы, а также их значения за обязательные и профильные предметы. А ещё вы узнаете, как эти баллы выглядят в знакомой пятибальной системе.
Первичные и тестовые очки
За каждый ответ в КИМе испытуемому начисляются баллы. После выполнения экзаменационной работы, все эти очки суммируются. Итоговое значение – и есть первичные баллы. Их ещё называют предварительными. Затем наступает черёд перевода баллов ЕГЭ в 100 бальную систему. Для этих целей существует очень сложная математическая формула. Она учитывает различные статистические данные. В результате шкалирования и появляется итоговый тестовый балл, который вносится в школьный аттестат или рассматривается членами приёмной комиссии ВУЗа.
«Где t – это тестовый балл ЕГЭ (по 100-балльной системе), θ – первичный балл, θ min – значение, которое равняется одному первичному очку, а θ max , – оценка, соответствующая первичному баллу, на единицу меньшему максимально возможного.
Округление проводится до целого числа. Нулевому первичному очку соответствует 0 за ЕГЭ, а максимально возможному – 100. «
Перевод баллов ЕГЭ-2017 в оценки по пятибалльной шкале
Однако многие привыкли оценивать свои работы в «пятёрках», «двойках», «тройках» и «четвёртках». Поэтому все эти первичные и тестовые баллы им видятся просто нагромождением непонятных цифр. Чтобы облегчить оценивание своих результатов, можно перевести очки в пятибалльную систему.
Вот как выглядят баллы ЕГЭ по обязательным и профильным предметам. В перечне указаны первичные и тестовые (они в скобках) очки.
Шкала перевода баллов ЕГЭ по обществознанию
- 0 – 18 (0 – 41) – «2»;
- 19 – 30 (42 — 54) – «3»;
- 31 – 42 (55 — 66) – «4»;
- от 43 (от 67) – «5».
Шкала перевода очков по информатике
- 0 – 7 (0 – 41) – «2»;
- 8 – 15 (42 – 57) – «3»;
- 16 – 26 (58 – 78) – «4»;
- от 27 (от 79) – «5».
Шкала перевода баллов ЕГЭ-2017 по русскому языку
- 0 – 14 (0 – 34) – «2»;
- 15 – 32 (36 – 56) – «3»;
- 33 – 44 (57 – 70) – «4»;
- от 45 (от 71) – «5».
Шкала перевода очков по литературе
- 0 – 8 (0 – 31) – «2»;
- 9 – 23 (32 — 54) – «3»;
- 24 – 31 (55 — 66) – «4»;
- от 32 (от 67) – «5».
Шкала перевода баллов ЕГЭ по химии
- ниже 14 (0 – 35) – «2»;
- 14 – 31 (36 – 55) – «3»;
- 32 – 49 (56 – 72) – «4»;
- от 50 (73) – «5».
Шкала перевода очков по иностранному языку
- 0 – 21 (0 – 21) – «2»;
- 22 – 59 (22 – 59) – «3»;
- 60 – 84 (60 – 84) – «4»;
- от 85 (от 85) – «5».
Первичные очки соответствуют тестовым баллам.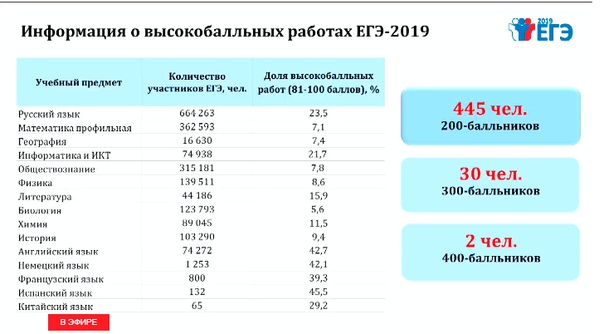
Шкала перевода баллов ЕГЭ по физике
- 0 – 10 (0 – 35) – «2»;
- 11 – 23 (36 – 52) – «3»;
- 24 – 34 (53 – 67) – «4»;
- от 35 (от 68) – «5».
Шкала перевода очков по географии
- 0 – 12 (0 – 35) – «2»;
- 13 – 22 (37 – 50) – «3»;
- 23 – 37 (51 – 66) – «4»;
- от 38 (от 67) – «5».
Шкала перевода баллов ЕГЭ-2017 по математике базового уровня
- 0 – 6 – «2»;
- 7 – 11 – «3»;
- 12 – 16 – «4»;
- от 17 – «5».
Первичные очки по математике базового уровня не переводятся в тестовые баллы.
Шкала перевода очков по истории
- 0 – 12 (0 – 35) – «2»;
- 13 – 27 (36 – 49) – «3»;
- 28 – 42 (50 – 67) – «4»;
- от 43 (от 68) – «5».
Шкала перевода баллов ЕГЭ по математике профильного уровня
- 0 – 5 (0 – 26) – «2»;
- 6 – 11 (26 – 46) – «3»;
- 12 – 17 (47 – 64) – «4»;
- от 18 (от 65) – «5».
Шкала перевода очков по биологии
- 0 – 12 (0 – 34) – «2»;
- 13 – 28 (36 – 53) – «3»;
- 29 – 43 (54 – 70) – «4»;
- от 44 (от 71) – «5».
Послесловие
Вот так выглядит таблица оценок баллов ЕГЭ-2017 в пятибалльной шкале. Значения сугубо примерные. Поэтому в таблице возможны серьёзные неточности. Но в качестве ориентира, который поможет оценить свои знания в ходе выполнения тренировочных тестов, она вполне может быть востребованной.
Окончание школы и поступление в ВУЗ сопровождается сдачей единого государственного экзамена. При его сдаче выпускники задаются вопросом, каким образом, первичный балл преобразуется в сто процентную шкалу.
Перевод баллов ЕГЭ в оценки направлен на то, чтобы определить, на какой показатель может рассчитывать будущий студент.
Калькулятор ЕГЭ по предметам
Шкала перевода баллов ЕГЭ в оценки
В процессе обучения в школе дети получают оценки по пятибалльной шкале, а по сути даже по четырехбалльной, так как единица ставится крайне редко.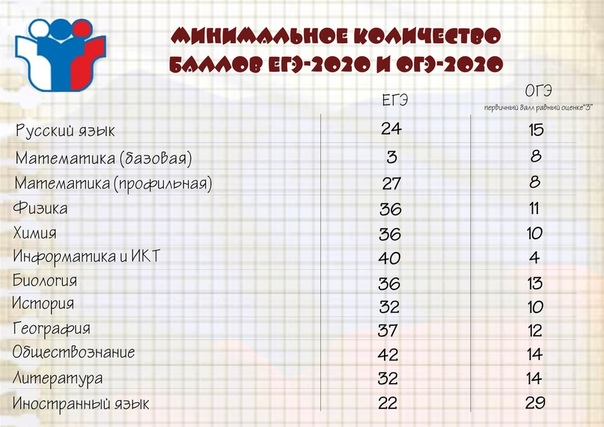
При сдаче экзаменов в девятом и одиннадцатом классах ученики сталкиваются с такими понятиями как первичные баллы за задания, а также стобалльная шкала.
Базовая процедура проверки основана на компьютерном анализе и экспертном изучении. Тестовая часть подвергается автоматизированному подсчету, оспорить данные проблематично. А вот ту часть, которую проверяют специалисты, допустимо подвергнуть дополнительному анализу.
Все баллы также переводятся в оценки. Несмотря на то, что этот показатель не оказывает существенного влияния, многие ученики интересуются, какие оценки дают те или иные первичные пункты.
Математика
Последние несколько лет по математике проводится два вида экзамена:
- базовый, который нужен для получения аттестата;
- профильный уровень – требуется для поступления в ВУЗы технической направленности.
В первом случае максимально возможный первичный балл равен двадцати, для пятерки требуется семнадцать пунктов, для четверки – двенадцать, а для трех — всего семь очков.
Что касается профиля, то отличная оценка выставляется тем, кто набрал от тринадцати до тридцати очков. Четверка — тем, кто получил пункты в пределах от десяти до двенадцати очков, а тройка ставится от шести первичных баллов.
Русский язык
Максимальный первичный балл по русскому равен тридцати девяти, для получения пятерки допустимо недобрать пять очков. Четверка начинается от двадцати пяти пунктов, а тройка с пятнадцати. При наборе менее, чем четырнадцати – экзамен считается не сданным.
Иностранные языки
Самый большой первичный балл из всех экзаменов – за иностранные языки – семьдесят.
Для получения отличной оценки требуется набрать минимум пятьдесят девять очков.
Что касается четверки, то вполне хватит и сорока шести пунктов, а для тройки – двадцати девяти.
Если выпускник набрал менее двадцати восьми, то сдачу экзамена ему не засчитают.
География
Чтобы быть отличником по географии, следует решить задания на двадцать семь баллов, максимальная планка равна тридцати двум.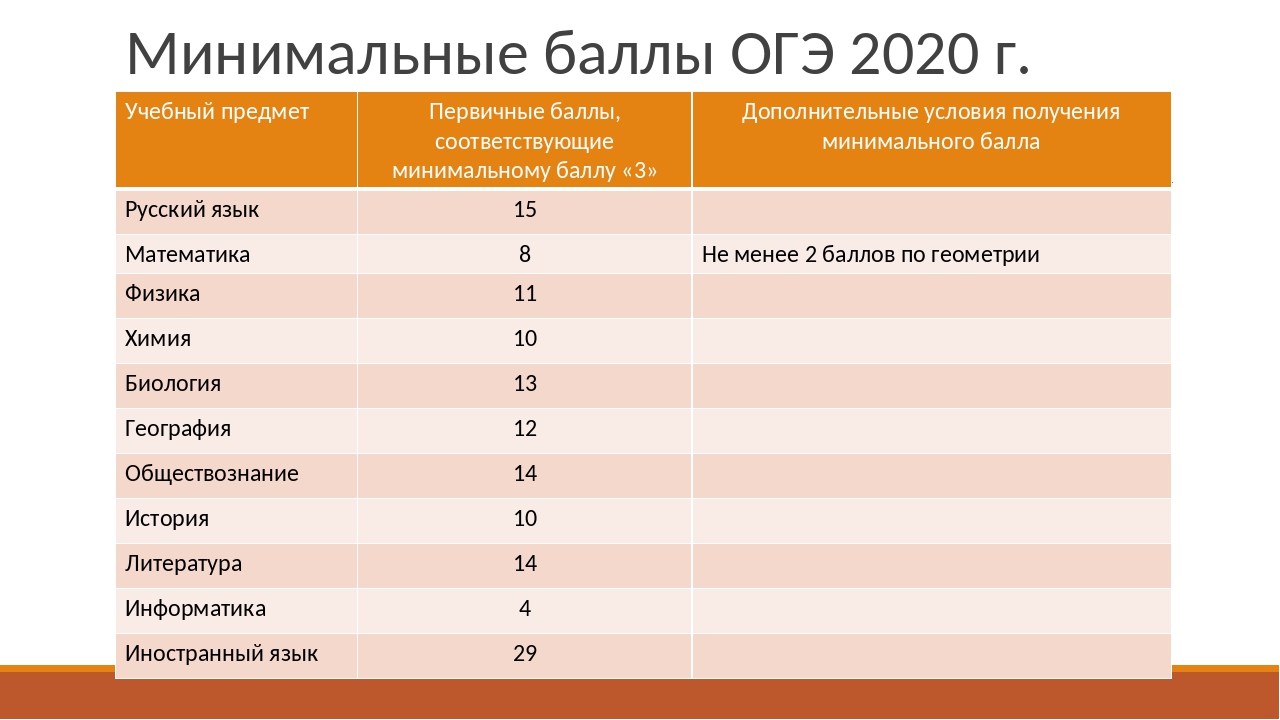 Четверка — с двадцати до двадцати шести, а для тройки достаточно всего двенадцати пунктов.
Четверка — с двадцати до двадцати шести, а для тройки достаточно всего двенадцати пунктов.
Биология
За экзамен по биологии можно накопить сорок шесть баллов, притом нижняя планка для пятерки равна тридцати семи очкам.
Тройка начинается с тринадцати, а четверка — с двадцати шести пунктов.
Несданным считается тест, по которому набрано менее двенадцати пунктов.
Литература
При благополучной сдаче литературы в рамках ЕГЭ можно получить до тридцати трех баллов, при этом отсчет пятерки идет с двадцати семи. Для четверки хватит двадцати пунктов, а для тройки – двенадцати.
Химия
Для химии допускается набрать тридцать четыре пункта, из них двадцати семи хватит для отличной оценки. Четверка стартует с девятнадцати, а для троечки хватит и девяти пунктов.
История
За экзамен по истории накапливается сорок четыре балла.
Недобор даже девяти пунктов даст выпускнику отличную оценку.
Хорошистом по истории станет тот, кто решит тест на двадцать четыре пункта.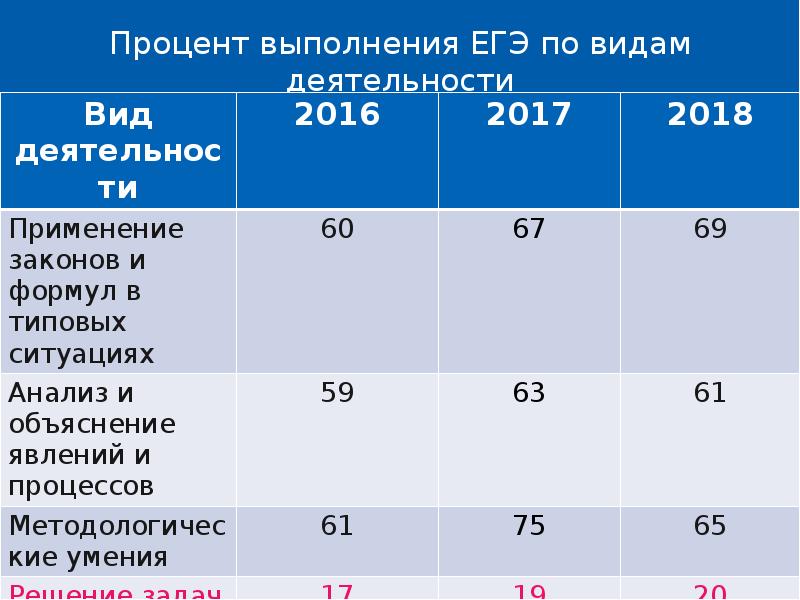 Удовлетворительная оценка начинается с тринадцати очков.
Удовлетворительная оценка начинается с тринадцати очков.
Информатика
Самый маленький первичный балл за экзамен по информатике — он равен двадцати двум. Однако, для того чтобы получить отметку в пять, допустим недобор всего четыре пункта. Тройка начинается с пяти очков, а тройка с двенадцати.
Обществознание
Для приобретения пятерки по обществознанию требуется набрать от тридцати четырех до тридцати пяти очков. Хорошистам хватит двадцати пяти, а тем, кого устроит удовлетворительная отметка – пятнадцати.
Подготовка к ЕГЭ
Онлайн-сервис ГДЗ, на котором представлены решебники от различных авторов, включая математику 6 класс Виленкина, имеют множество преимуществ по сравнению с использованием решебников в бумажном формате:
- сервис бесплатный;
- можно учебники скачать ;
- сервис доступен в любое время суток любого дня недели;
- воспользоваться сервисом можно из любой точки с выходом в Интернет;
- на сервисе представлены решебники, составленные специалистами высокой квалификации, что исключает вероятность получения недостоверной или некачественной информации.
Немаловажными преимуществами онлайн-сервиса ГДЗ являются возможность доступа с любого компьютерного устройства, независимо от установленной на устройстве операционной системы.
Широкий выбор решебников, представленных на сайте, позволяет найти ответ практически на любой интересующий школьника вопрос. Так что теперь учиться стало проще.
Что значит первичный балл в ЕГЭ
Основные понятия:
- Первичный – сумма очков, которые можно набрать при решенных заданиях; в зависимости от сложности задачам присваивается определенное количество пунктов.
- Тестовый – переведенные в систему из ста очков пункты за решенные задания.
Данная система придумана для простоты подсчета результатов, так как поступление в ВУЗ происходит на основании суммы баллов за несколько экзаменов, а максимальный первичный показатель у предметов разный.
Дело в том, что каждое задание в темах оценивается отдельно и существует специальный счетчик для распределения очков.
Как перевести первичные баллы во вторичные
Для того чтобы осуществить перевод первичных пунктов во вторичные, требуется воспользоваться специальной шкалой, которая представлена на официальных сайтах ФИПИ, а также ряде сторонних источников.
Самостоятельно произвести подсчет проблематично, для этого нужно точно знать принцип перечисления.
В статье представлен калькулятор по переводу информации. Критерии, которые считаются, основываются на результативности сданного экзамена.
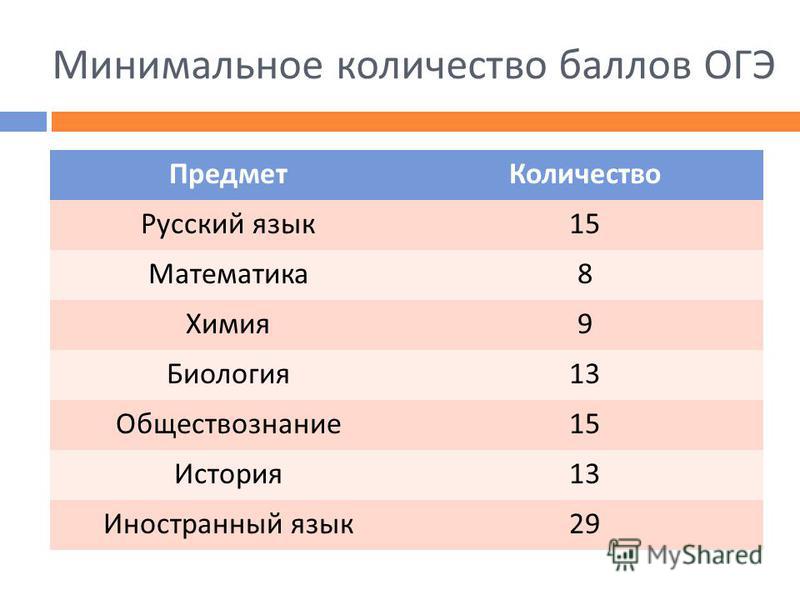
Минимальные баллы на ЕГЭ
Ежегодно утверждается размер минимальных пунктов как база, которая требуется для получения аттестата в школе и получения права на подачу заявления.
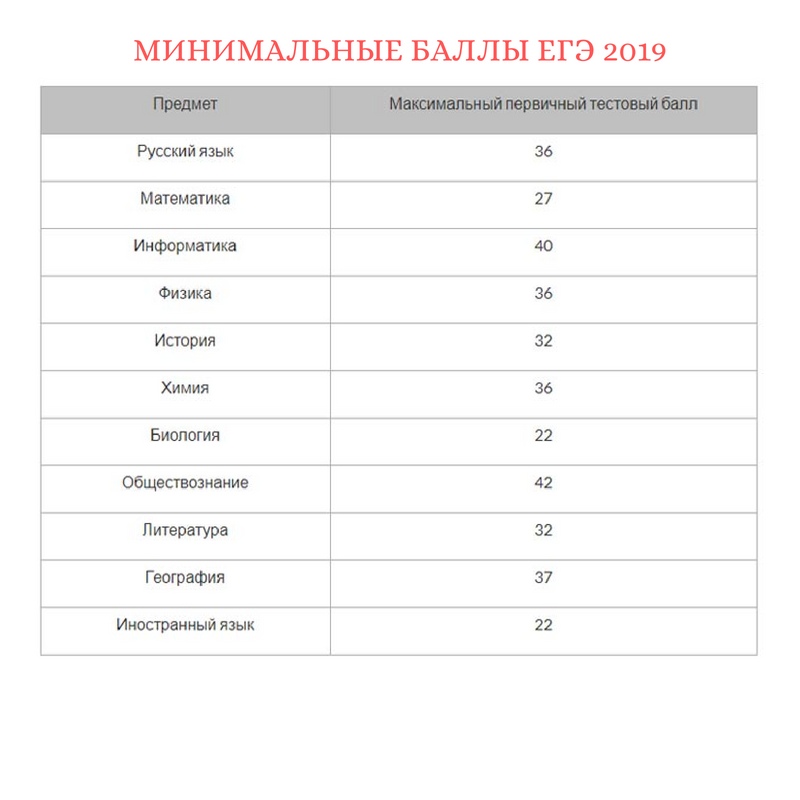
В соответствии с текущим законодательством, для окончания школы с официальным документом об образовании надо обязательно сдать два предмета:
- русский – двадцать четыре;
- математика – двадцать семь.
Все остальные предметы сдаются для поступления в ВУЗ. Это означает, что ученик вправе как не выбрать ничего, за исключением русского языка и математики, так и сдавать хоть все предметы из таблицы.
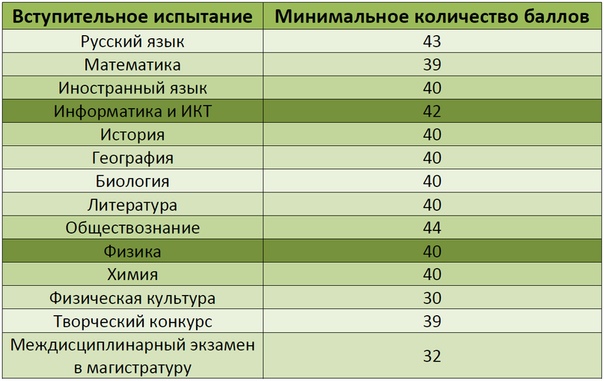
Что касается проходных пунктов для поступления, то высшее учебное заведение самостоятельно определяет порог по каждому предмету, но этот параметр не может быть ниже установленного на государственном уровне.
Показатели выглядят следующим образом:
- Русский язык, химия, биология и физика – тридцать шесть.
- Математика – двадцать семь.
- Информатика – сорок.
- История и литература – тридцать два.
- Иностранные языки – двадцать два.
- Обществознание – сорок два.
- География – тридцать семь.
В данном перечне указаны вторичные баллы, то есть очки уже переведены в стобалльную систему. Важно учитывать то, что конкретный ВУЗ вправе установить завышенные требования разбалловки, это не запрещено законом.
Максимальный балл на ЕГЭ
Максимальный балл на едином государственном экзамене по каждому из предметов равен ста во вторичной системе.
Для того, чтобы определить максимальное количество допустимых пунктов по дисциплине, следует обратиться либо к таблице перевода из первичных во вторичные очки, либо кодификатору по предметам, представленных в каждом среднем тестовом пробном варианте.
Как набрать 100 баллов на ЕГЭ
Для набора максимального количества баллов по ЕГЭ требуется не только хорошо разбираться в тематике, но и уметь грамотно решать тестовые типовые задания.
При подготовке следует руководствоваться следующим:
- В течение нескольких лет ежедневно изучать материал по предметам, которые планируется сдавать по окончании школы.
- Много решать заданий тестового типа, это поможет набить руку и повторить все темы не один раз.
- При решении заданий письменной части стоит обращаться к экспертам, которые помогут в анализе и подскажут правила оформления.
- На самом экзамене вести себя спокойно, если в теме выпускник хорошо ориентируется, то проблем с решениями не возникнет.
Перевод баллов ЕГЭ в оценки – формальность, которая позволяет оценить результаты более привычным методом.
А вот расчет с первичных на вторичные – важный этап. Высшие учебные заведения выставляют планки и проходные стандарты, исходя из стобалльной шкалы.
В ЕГЭ — 2018 изменилась система шкалирования результатов по нескольким предметам
Об этом журналистам рассказала заместитель министра — начальник управления по контролю и надзору за соблюдением законодательства в сфере образования и качеством образования минобрнауки региона Елена Дудина.
«Система шкалирования результатов изменилась по обществознанию, физике, химии, литературе. Минимальный порог по этим предметам остался прежним, однако, чтобы его набрать, выпускникам придётся выполнить больше заданий, чем в прошлом году», — подчеркнула эксперт.
Напомним, основная волна сдачи единого госэкзамена стартует 28 мая. Первыми предметами, которые в этот раз сдадут одиннадцатиклассники, станут география и информатика. Всего в 2018 году в Астраханской области ЕГЭ напишут около четырёх тысяч человек в 31 пункте проведения (ППЭ). Кроме того, несколько пунктов будет открыто на дому у тех школьников, которые не могут явиться на ППЭ по состоянию здоровья.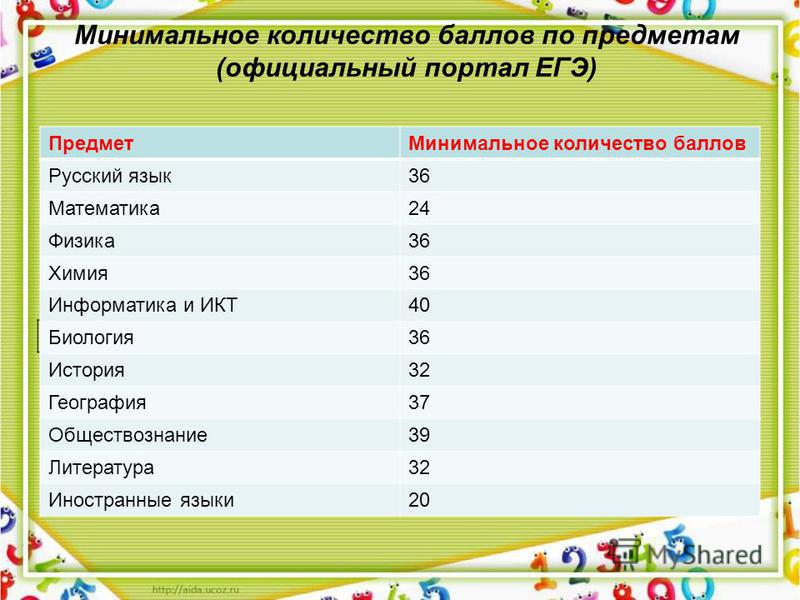
«В 2018 году во всех ППЭ будет применяться технология распечатки и сканирования КИМ в аудиториях, для этого было закуплено всё необходимое оборудование, — сообщила Елена Дудина. — Материалы будут печататься непосредственно перед началом экзамена с защищённых носителей. А после завершения экзаменов работы участников отсканируют также в аудиториях и передадут в электронном виде для проверки. Использование таких технологий позволяет практически полностью исключить человеческий фактор и попытки искажения результатов».
Чтобы основная волна прошла без каких-либо сбоев, в регионе будут проведены тренировочные тестирования. Так, 24 апреля во всех пунктах без участия детей сами организаторы экзамена будут тренироваться проводить ЕГЭ. А 17 мая пройдёт пробная аттестация по обществознанию для учащихся, остановивших свой выбор на данном предмете (это порядка 70 % выпускников).
«Ребята смогут испытать свои силы, посмотрят, как проходит процедура ЕГЭ, потренируются в заполнении всех необходимых бланков — всё это должно снять естественное психологическое напряжение непосредственно на экзаменах», — отметила Елена Дудина.
Кстати, чтобы учащиеся были эмоционально готовы к аттестации, в школах на протяжении года ведётся соответствующая работа: им разъясняются права и обязанности участников ЕГЭ, проводятся тренировки по заполнению бланков, рассказывают, как подать апелляцию и где узнать результаты и так далее.
«Сейчас выпускники гораздо более спокойно относятся к ЕГЭ, нежели их родители. Ребята знают свои силы, понимают, что от них требуется, знакомы с механизмами проведения аттестации, поэтому она не вызывает у них никакой паники», — подчеркнула замминистра.
Напомним, ЕГЭ является одновременно выпускным экзаменом для учащихся 11 классов и вступительным в вуз, он проводится по 14 учебным предметам. Русский язык и математика являются обязательными предметами для выпускников текущего года, остальные экзамены участники ЕГЭ сдают по желанию. Некоторая часть школьников выбирают большее количество предметов по выбору. По словам замминистра Елены Дудиной, это говорит о том, что ещё не все ребята определились со своей будущей профессией, они планируют подавать документы в вузы сразу на несколько разных специальностей, предоставив себе возможность определиться позже.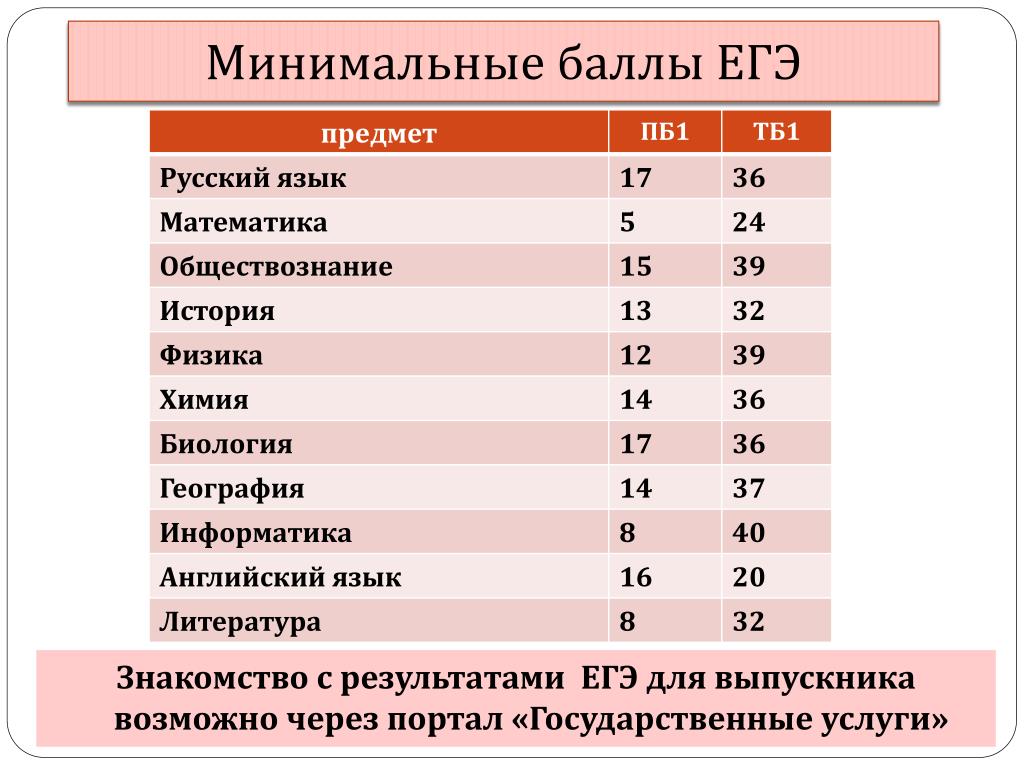
Егэ 85 баллов оценка. Что такое первичный и тестовый балл ЕГЭ? Минимальный аттестационный балл
2018-2019 учебный год станет выпускным для многих российских школьников, которых уже сегодня волнуют вопросы успешного прохождения Единого государственного Экзамена и успешного поступления в хороший ВУЗ.
Мы расскажем, как происходит проверка экзаменационных работ по разным предметам, как работает шкала перевода баллов ЕГЭ в оценки и какие нововведения можно ожидать в 2019 году.
Принципы оценивания работ ЕГЭ 2019 года
На протяжении нескольких последних лет система ЕГЭ по ряду предметов претерпела существенные изменения и была приведена к оптимальному (по мнению организаторов) формату, позволяющему в полной мере оценить объем знаний выпускника по конкретно взятому предмету.
В 2018-2019 году кардинальных перемен не предвидится и можно с уверенностью сказать, что для оценивания работ выпускников будут применены те же принципы, что и в 2017-2018 году:
- автоматизированная проверка бланков;
- привлечение экспертов к проверке заданий с развернутыми ответами.

Как оценивает компьютер?
Первая часть экзаменационной работы предполагает краткий ответ на поставленные вопросы, который участник ЕГЭ должен занести в специальный бланк ответов.
Важно! Перед началом выполнения работы обязательно ознакомьтесь с правилами заполнения бланка, так как неправильно оформленная работа не пройдет автоматизированную проверку.
Оспорить результат компьютерной проверки довольно сложно. Если работа не была засчитана по вине участника, неправильно заполнившего форму, результат приравнивается к неудовлетворительному.
Как оценивают эксперты?
Во многих предметах помимо тестовой части присутствуют задания, на которые необходимо дать полный развернутый ответ. Поскольку автоматизировать процесс проверки таких ответов невозможно, к проверке привлекают экспертов – опытных учителей, имеющих большой стаж работы.
Проверяя ЕГЭ учитель не знает (и даже при большой желании не может узнать), чья работа лежит перед ним и в каком городе (регионе) она была написана. Проверка осуществляется на основании единых критериев оценивания, разработанных специально для каждого предмета. Каждую работу проверяют два эксперта. Если мнение специалистов совпадает, оценка выставляется в бланк, если же независимые оценщики расходятся во мнении, то к проверке привлекают третьего эксперта, чье мнение и будет решающим.
Именно поэтому писать важно разборчиво и аккуратно, чтобы не возникало неоднозначного толкования слов и фраз.
Первичные и тестовые баллы
По результатам проверки участнику ЕГЭ начисляется определенное количество первичных баллов, которые после переводят в текстовые (баллы за весь тест). В разных предметах предусматривается разный максимум первичных баллов, в зависимости от количества заданий. Но после приведения результата по соответствующей таблице участник ЕГЭ получает окончательной тестовый балл, который и является официальным результатом его выпускных испытаний (максимально 100 баллов).
Так, чтобы сдать экзамен достаточно набрать установленный минимальный порог первичного балла:
Минимальные баллы |
||
первичный | тестовый |
|
Русский язык | ||
Математика (профиль) | ||
Информатика | ||
Обществознание | ||
Иностранные языки | ||
Биология | ||
География | ||
Литература | ||
Ориентируясь на эти цифры вы можете точно понять, что экзамен сдан.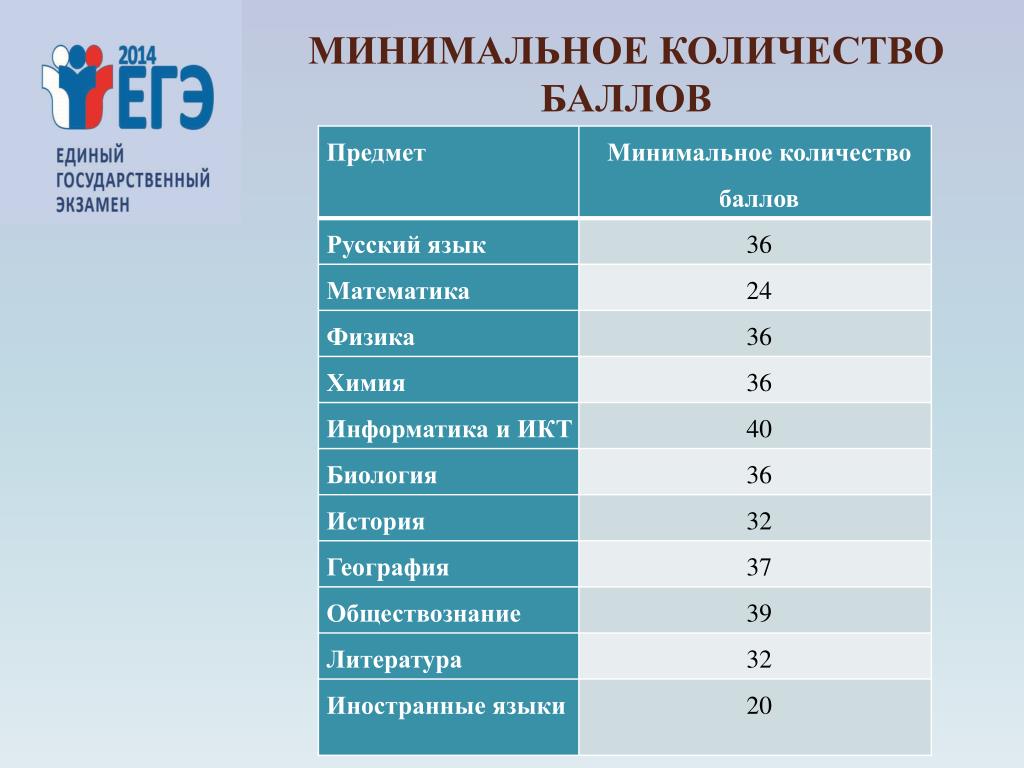 Но та какую оценку? В этом вам поможет online шкала 2018 года, разработанная специально для перевода первичных баллов ЕГЭ в тестовые, которая также будет актуальна и для результатов 2019 года. Удобный калькулятор можно найти на сайте 4ege.ru.
Но та какую оценку? В этом вам поможет online шкала 2018 года, разработанная специально для перевода первичных баллов ЕГЭ в тестовые, которая также будет актуальна и для результатов 2019 года. Удобный калькулятор можно найти на сайте 4ege.ru.
Оглашение официальных результатов
Выпускников всегда волнует вопрос – как быстро можно узнать, какой результат получен при сдаче и какой будет в 2019 году шкала для перевода набранных на ЕГЭ баллов в традиционные оценки.
Успокоить учеников зачастую берутся учителя, прорабатывая сразу после экзамена задания билетов ЕГЭ и оценивая качество выполнения работы воспитанниками и сумму набранных первичных баллов. Официальные результаты необходимо ждать 8-14 дней, согласно установленному регламенту проведения ЕГЭ-2019 года. В среднем организаторы утверждают такие графики проверки:
- 3 дня на проверку работ;
- 5-6 дней на обработку информации на федеральном уровне;
- 1 рабочий день на утверждение результатов ГЭК;
- 3 дня на размещение результатов в сети и передачу данных в учебные заведения.

В случае возникновения непредвиденных ситуаций и технических неполадок эти сроки могут быть пересмотрены.
Узнать совой балл можно:
- непосредственно в своей школе;
- на портале check.ege.edu.ru;
- на сайте gosuslugi.ru.
Перевод балов в оценку
С 2009 года результаты ЕГЭ не вносят в аттестат выпускника. Поэтому сегодня нет официальной государственной системы перевода результата ЕГЭ в оценку по школьной 5-тибальной шкале. В рамках вступительной кампании всегда суммируется и учитывается именно набранный на экзамене тестовый балл. Но, многим учащимся все же интересно узнать, как они сдали экзамен – на 3 или на 4, на 4 или на 5. Для этого существует специальная таблица, в которой подробно прописаны соответствия для каждого из 100 баллов по каждому из предметов.
Русский язык | ||||
Математика | ||||
Информатика | ||||
Обществознание | ||||
Иностранные языки | ||||
Биология | ||||
География | ||||
Литература | ||||
Пользоваться такой таблицей достаточно неудобно. Намного проще узнать, как ты сдал русский язык, математику или историю, воспользовавшись online калькулятором 4ege.ru, в который также строена шкала перевода баллов ЕГЭ, актуальная для выпускников 2019 года.
Намного проще узнать, как ты сдал русский язык, математику или историю, воспользовавшись online калькулятором 4ege.ru, в который также строена шкала перевода баллов ЕГЭ, актуальная для выпускников 2019 года.
Получив результат ЕГЭ, стоит как можно быстрее определится с ВУЗом, сопоставив свои возможности с реальным конкурсом на интересующие специальности. Так, практика прошлых лет показывает, что в ряде случаев на самые востребованные направления в столичных ВУЗах сложно попасть даже с высокими баллами, ведь соревноваться за места будут не только обладатели 100-бальных результатов ЕГЭ, а и призеры крупнейших олимпиад 2018-2019 учебного года.
Всех учеников 11-х классов, которым в 2019 году предстоит сдавать ЕГЭ, интересует вопрос, как будет осуществляться перевод первичных баллов во вторичные и какой будет шкала соответствия результатов ЕГЭ школьным оценкам.
Предлагаем углубиться в вопрос начисления баллов за обязательные предметы выпускных экзаменов и узнать, какие результаты можно считать достаточными для поступления в ВУЗ по предметам на выбор.
Оценивание ЕГЭ 2019
Важно! Кардинальных изменений в системе оценивания экзаменационных работ в 2019 году не произойдет, и шкала перевода первичных баллов в тестовые, разработанная для предыдущего сезона ЕГЭ, будет актуальна для большинства предметов.
Исключением из правила станут биология и обществознание, для которых предусмотрены некоторые нововведения в КИМах, повлекшие за собой незначительное изменение максимального первичного балла, а именно:
Как и в 2018 году, проверка выпускных работ будет осуществляться двумя способами:
- с помощью автоматизированных электронных систем, распознающих типовой бланк ответов ЕГЭ 2019;
- с привлечением экспертов, которым предстоит вручную оценивать развернутые ответы повышенного и высокого уровня сложности.
При проверке работы выпускнику будут насчитывать первичные баллы (далее ПБ), а после уже будет осуществляться их перевод в тестовый балл (далее ТБ), который и будет результирующим, засчитанным как официальный результат экзамена.
Таблицы соответствия баллов для обязательных предметов
Несмотря на громкие обещания расширить круг обязательных экзаменов для выпускников 11-х классов, в этом учебном году обязательными остаются математика и русский язык. Перспектива введения истории и английского языка активно обсуждается и изучается экспертами.
Для каждого предмета ЕГЭ 2019 существует своя таблица соответствия, по которой и будет происходить перевод первичных баллов.
Русский язык
Экзамен по русскому языку будет основным и в 2019 году. Перевод первичных баллов, полученных экзаменуемым по результатам проверки I и II части экзаменационного билета ЕГЭ 2019 во вторичные (результирующие, тестовые) баллы будет осуществляться согласно следующей таблице соответствия.
Таким образом, для получения документа об образовании выпускнику достаточно набрать 10 ПБ (24 ТБ), но вступить в борьбу за бюджетное место в одном из ВУЗов России смогут только те, кто наберет минимум 16 ПБ (36 ТБ).
Математика
Результаты ЕГЭ по математике базового уровня не рассматриваются при поступлении в ВУЗ, а для получения аттестата сдающим данный экзамен достаточно получить 7 (из 20 возможных) первичных баллов, что будет соответствовать оценке «3».
Выпускники, сдающие в 2019 году математику профильного уровня, подсчитав первичный балл, могут самостоятельно определить результат, выполнив перевод из первичных баллов во вторичные (тестовые) по такой таблице:
Таблицы соответствия баллов для предметов по выбору
Разница между интерпретацией результатов по предметам математика и русский, а также других дисциплин ЕГЭ 2019 в том, что для обязательных предметов, осуществляя перевод первичных баллов, выделяют отдельно минимальный порог для получения аттестата и отдельно нижнюю границу результата, позволяющего подавать документы в ВУЗ. Для всех предметов по выбору эти обе нижние границы совпадают.
Биология
Минимальным проходным баллом по биологии в 2019 году будет 16 ПБ, что эквивалентно 32 ТБ.
История
Преодолевшими минимальный порог по истории на ЕГЭ 2019 года будут считаться ребята, набравшие 9 ПБ, которые установленный в таблице перевод первичных баллов интерпретирует как 32 из 100 возможных ТБ.
Информатика
Максимальный первичный балл по информатике – 35, а для преодоления минимального порога достаточно получить всего 6 баллов, что согласно приведенной ниже таблице соответствует 40 ТБ из 100 возможных.
Обществознание
Для того, что бы набрать желаемые для многих 100 ТБ на предстоящем ЕГЭ по обществознанию 2019 года, участнику итоговой аттестации необходимо будет получить максимально возможные 64 первичных балла. При этом минимальный порог по предмету составит 21 ПБ или 42 ТБ.
Химия
Максимально за идеально выполненную работу можно получить 60 первичных баллов. При этом минимальным результатом, позволяющим получить документы об образовании и попробовать продолжить обучение, будет порог в 13 ПБ или же 36 ТБ.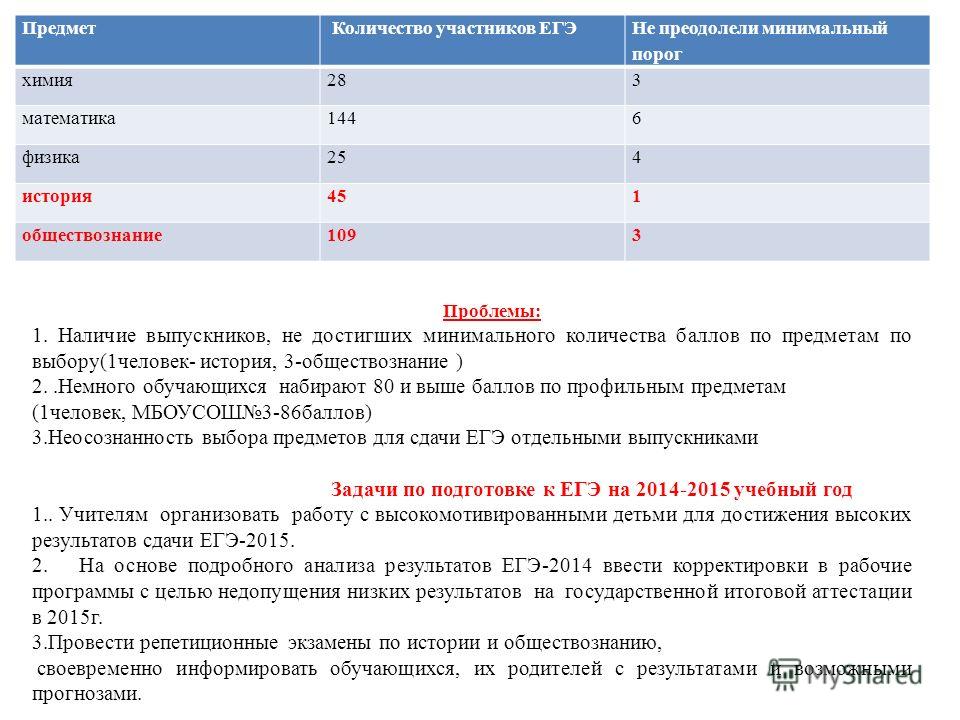
Физика
Дисциплина по праву считается одной из самых сложных среди предметов ЕГЭ по выбору. Хотя минимальный порог составляет всего 10 ПБ (33 ТБ) балла, преодолеть его удается не всем. Но, получив высокий результат, выпускник может уверенно вступить в борьбу за бюджетное место в лучших технических ВУЗах страны.
География
Сегодня предмет не относится сегодня к популярным дисциплинам ЕГЭ, ведь данный сертификат требуют лишь немногие ВУЗы, предоставляющие обучение с узкой специализацией. Если вы твердо решили сдавать именно этот предмет, преодолеть нижнюю планку в 10 ПБ (соответственно 34 ТБ), будет не так уж и сложно. Если же нужен сертификат с близким к максимальному результатом, стоит уделить как можно больше внимания подготовке.
Литература
Экзамен, которые часто выбирают ребята, желающие связать свою жизнь с журналистикой или другими творческими профессиями. Минимальный порог по литературе в 2019 году составит 14 ПБ = 30 ТБ, а максимальный 100-бальный результат можно получить, заработав 58 из 58 возможных начальных баллов.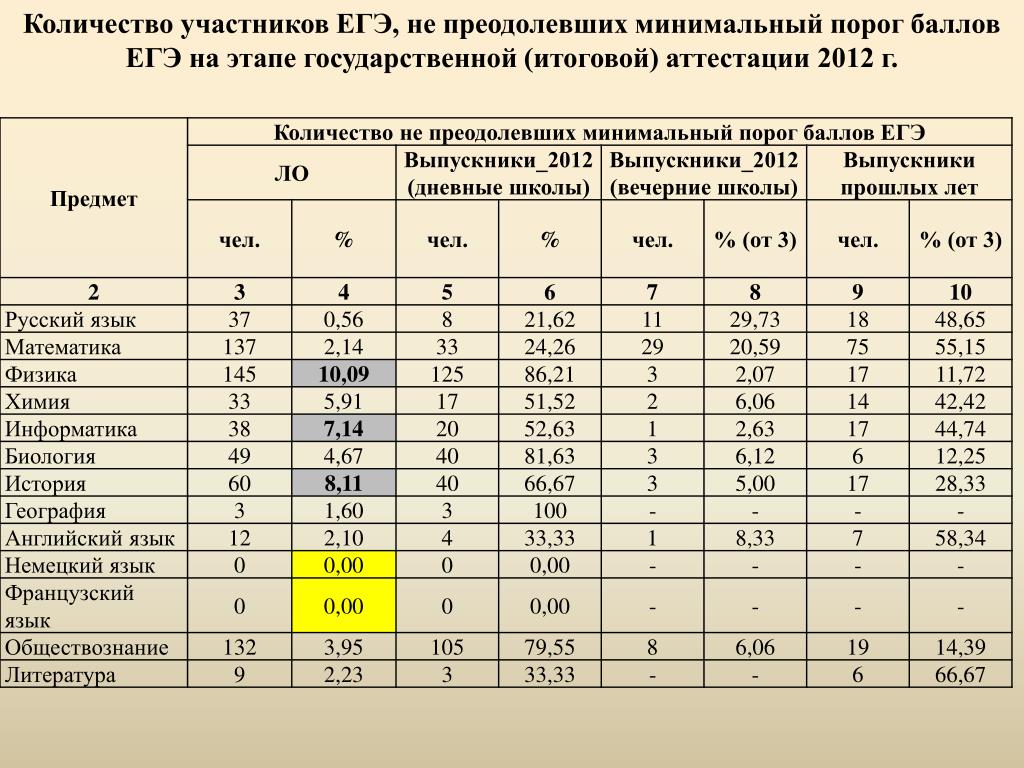
Иностранные языки
Расчет баллов по иностранным языкам наиболее прост, ведь для данной группы предметов ЕГЭ 2019 действует прямой перевод первичных баллов в тестовые по системе «один к одному».
1 ПБ = 1 ТБ
В качестве минимального порога для 2019 года принят результат в 22 балла.
Заключение
Указанные в таблицах минимальные баллы дают гипотетическую возможность участвовать в борьбе за бюджетное место. На практике проходные баллы в университет значительно выше. Данный показатель меняется из года в год и зависит от количества абитуриентов, подающих документы на определенную специальность и результатов их сертификатов ЕГЭ.
Узнать, каким был проходной балл на интересующую вас специальность, а также какие сертификаты необходимы для участия в конкурсе на бюджетные места, можно на сайте университета, в который вы планируете подавать документы.
Если вас интересует, какой оценке соответствует полученный тестовый балл, воспользуйтесь неофициальной таблицей интерпретации результатов ЕГЭ 2019:
Каждый выпускник отлично понимает, что для успешного поступления на интересующую специальность необходимо качественно подготовится к ЕГЭ 2018 и набрать максимально возможные баллы. Что же значит «хорошо сдать экзамен» и сколько баллов будет достаточно для того, что бы побороться за бюджетное место в том или ином ВУЗе? Об этом пойдет речь в данной статье.
Что же значит «хорошо сдать экзамен» и сколько баллов будет достаточно для того, что бы побороться за бюджетное место в том или ином ВУЗе? Об этом пойдет речь в данной статье.
Мы затронем такие важные вопросы:
Прежде всего, важно понимать, что существует:
- минимальный балл, дающий право на получение аттестата;
- минимальный балл, позволяющий подать документы в ВУЗ;
- минимальный балл, достаточный для реального поступления на бюджет по конкретной специальности в определенном университете России.
Естественно, что эти цифры существенно отличаются.
Минимальный аттестационный балл
Минимальные аттестационные баллы ЕГЭ установлены для обязательных предметов – русского языка и математики базового уровня и в 2018составляют:
Преодолев данный порог, но, не дотянув до минимального тестового балла, экзаменуемый получит аттестат, но не сможет подать документы в университет.
Минимальный тестовый балл
Тестовый минимум – это пороговое значение, дающее право на вступление в ВУЗ.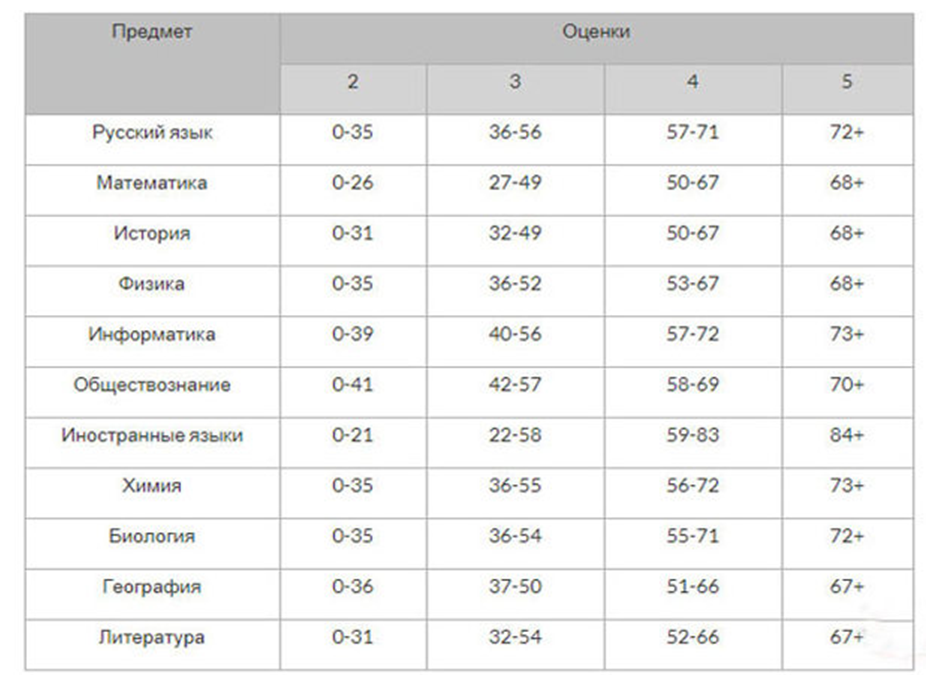 Иными словами, лица, преодолевшие тестовый порог теоретически имеют право вступить в борьбу за бюджетные места. Хотя, на практике, вступить с минимальными показателями в высоко котируемые университеты практически нереально.
Иными словами, лица, преодолевшие тестовый порог теоретически имеют право вступить в борьбу за бюджетные места. Хотя, на практике, вступить с минимальными показателями в высоко котируемые университеты практически нереально.
В 2018 году по всем предметам, кроме русского языка и базовой математики тестовые минимальные баллы ЕГЭ совпадают с аттестационными и составляют:
Предмет | Минимальный тестовый балл |
Русский язык | |
Математика (базовый уровень) | |
Математика (профильный уровень) | |
Обществознание | |
Литература | |
Иностранный язык | |
Биология | |
Информатика | |
География |
Принцип расчета успешности сдачи единого государственного экзамена предполагает, что испытуемый должен продемонстрировать высокий, средний либо достаточный уровень знаний, соответствующий в школьной шкале оценкам «5», «4» и «3».
В случае неудовлетворительного результата, а также при сдаче на балл, который сам экзаменуемый считает для себя недостаточным, выпускникам предоставляется право пересдачи ЕГЭ.
Минимальный балл для поступления на бюджет
Большинство ВУЗов оглашают пороговый балл, необходимый для претендующих на бюджетное место. Это позволяет каждому абитуриенту реально оценивать перспективы поступления и выбирать университеты и специальности с учетом набранных на ЕГЭ баллов.
В 2018 году можно ориентироваться на тот факт, что в прошлом сезоне средние проходные баллы по всем предметам ЕГЭ среди абитуриентов, поступивших в МГИМО и другие высоко котируемые университеты столицы, колебались между пороговым значением 80-90. Но, для большинства региональных ВУЗов РФ конкурентным результатом можно считать уже 65-75 баллов.
Перевод первичного балла в результирующий
Выполняя задания, предложенные в билете ЕГЭ, экзаменуемый набирает так называемые первичные баллы, максимальное значение которых варьируется в зависимости от предмета. При оценивании уровня знаний, такие первичные баллы переводятся в результирующие, которые заносятся в сертификат и являются базовыми при поступлении.
При оценивании уровня знаний, такие первичные баллы переводятся в результирующие, которые заносятся в сертификат и являются базовыми при поступлении.
С помощью онлайн калькулятора, вы сможете сопоставить первичные и тестовые баллы по интересующим предметам.
Также как в прошлом году, в 2018 набранные при прохождении ЕГЭ баллы влияют на балл аттестата и, хотя официально таблица сопоставления тестового балла и традиционных оценок, не принята, можно приблизительно сопоставить свои баллы прямо сейчас, используя универсальный калькулятор.
Проходные баллы топ 10 ВУЗов России
суммарный |
||
| Московский государственный университет им. М.В. Ломоносова | ||
| Московский физико-технический институт | ||
| Национальный исследовательский ядерный университет «МИФИ» | ||
| Санкт-Петербургский государственный университет | ||
| Московский государственный институт международных отношений | ||
| Национальный исследовательский университет «Высшая школа экономики» | ||
Московский государственный технический университет имени Н. Э. Баумана Э. Баумана
| ||
| Национальный исследовательский Томский политехнический университет | ||
| Новосибирский национальный исследовательский государственный университет | ||
| Санкт-Петербургский политехнический университет Петра Великого |
Обратите внимание, что средние проходные баллы по разным специальностям в одном ВУЗе могут существенно отличаться. Эта цифра отображает минимальный балл абитуриентов, поступивших на бюджет, и имеет тенденцию изменяться каждый год. Результаты 2017 года могут служить лишь неким ориентиром для абитуриентов 2018, мотивируя к достижению максимально высоких результатов.
На минимальный проходной балл влияет множество факторов, в числе которых:
- общее количество выпускников, подавших заявления и баллы, указанные в их сертификатах;
- число абитуриентов, предоставивших оригиналы документов;
- количество льготников.
Так, увидев свою фамилию на 20 месте в списке специальности, предусматривающей 40 бюджетных мест, можно с уверенностью считать себя студентом. Но, даже если вы окажитесь в этом списке 45, нет повода расстраиваться, если среди стоящих перед вами числится, 5-10 человек, предоставивших копии документов, ведь скорее всего эти люди настроены на другой ВУЗ и подали документы на эту специальность как на запасной вариант.
При прохождении экзаменационного тестирования учащимся предлагается выполнить 24 базовых задания из первой части. Они требуют от выпускников предоставления краткого ответа, который фиксируется в словесной или цифровой форме. Вторая часть экзаменационного тестирования содержит всего одно задание. Учащимся предлагается написать сочинение.
Каким образом осуществляется перевод баллов ЕГЭ по русскому языку и какое минимальное и максимальное их количество можно получить? Данные вопросы являются одними из наиболее волнующих как для самих учащихся старших классов, так и для их родителей и педагогов.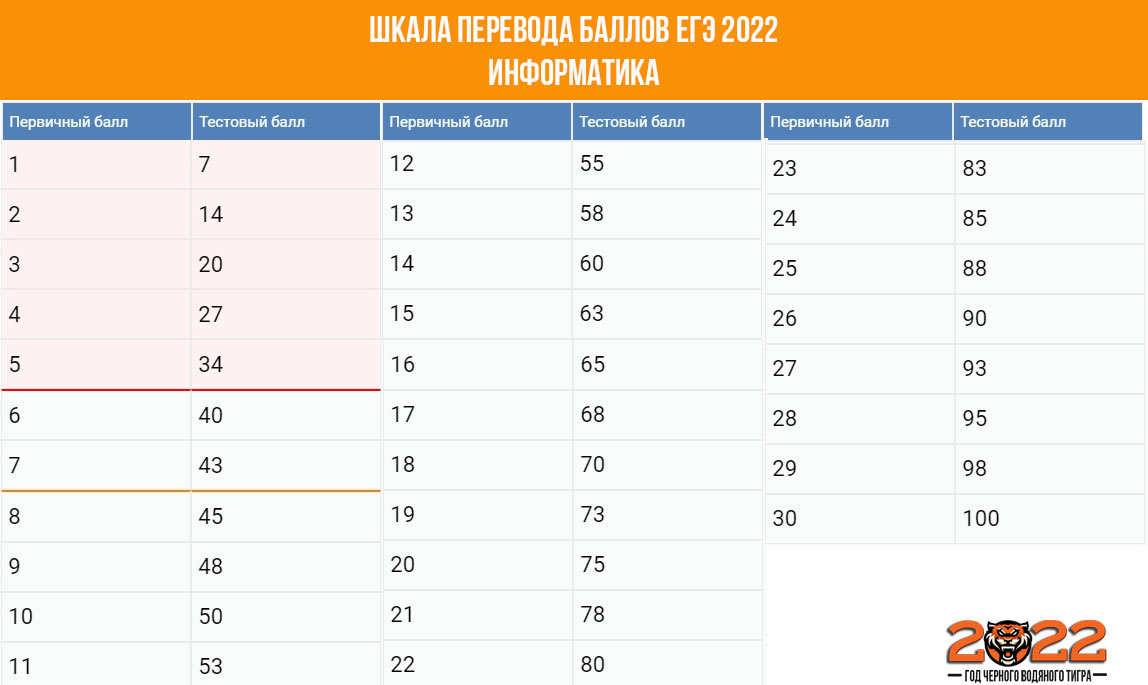 После проверки итогового тестирования выставляется первичный балл: от 0 до 58. Для каждого задания предусмотрено определенное их количество: от 1 до 5. Чем более сложным оно является, тем больше баллов получает выпускник. Оценивание результатов написания сочинения осуществляется по-другому. За него школьникам может быть начислено от 0 до 24 баллов.
После проверки итогового тестирования выставляется первичный балл: от 0 до 58. Для каждого задания предусмотрено определенное их количество: от 1 до 5. Чем более сложным оно является, тем больше баллов получает выпускник. Оценивание результатов написания сочинения осуществляется по-другому. За него школьникам может быть начислено от 0 до 24 баллов.
Затем осуществляется перевод первичных баллов в тестовые. Они указываются в сертификате единого госэкзамена. Именно этот результат учитывается при поступлении в вузы.
Сколько баллов нужно набрать, чтобы говорить об успешной сдаче тестирования? Следует учитывать, что учащиеся, которые получили аттестат, не всегда могут претендовать на поступление в вузы. Говорить об успешном усвоении основной общеобразовательной программы и возможности поступления в вуз можно лишь в том случае, если школьник набрал 16 первичных, или 36 тестовых баллов соответственно. будут учитываться в рейтинге учащегося в списке претендующих абитуриентов. Средний проходной балл составляет не менее 65-75. Выпускники, планирующие поступать в ведущие вузы Москвы и других городов нашей страны, должны принимать во внимание тот факт, что в данном случае эта цифра будет более высокой.
Выпускники, планирующие поступать в ведущие вузы Москвы и других городов нашей страны, должны принимать во внимание тот факт, что в данном случае эта цифра будет более высокой.
Перевод баллов ЕГЭ по русскому языку осуществляется при помощи специальной шкалы. Стоит учитывать, что алгоритм из года в год корректируется.
Таблица баллов ЕГЭ по русскому языку
| Первичный балл | Тестовый балл |
|---|---|
| 1 | 3 |
| 2 | 5 |
| 3 | 8 |
| 4 | 10 |
| 5 | 12 |
| 6 | 15 |
| 7 | 17 |
| 8 | 20 |
| 9 | 22 |
| 10 | 24 |
| 11 | 26 |
| 12 | 28 |
| 13 | 30 |
| 14 | 32 |
| 15 | 34 |
| 16 | 36 |
| 17 | 38 |
| 18 | 39 |
| 19 | 40 |
| 20 | 41 |
| Первичный балл | Тестовый балл |
|---|---|
| 21 | 42 |
| 22 | 44 |
| 23 | 45 |
| 24 | 46 |
| 25 | 47 |
| 26 | 48 |
| 27 | 50 |
| 28 | 51 |
| 29 | 52 |
| 30 | 53 |
| 31 | 54 |
| 32 | 56 |
| 33 | 57 |
| 34 | 58 |
| 35 | 59 |
| 36 | 60 |
| 37 | 62 |
| 38 | 63 |
| 39 | 64 |
| 40 | 65 |
Требования к поступлению в среднее образование и степень – образование
- Минимальный средний балл 3.
 0 при 30 кредитах требуется для получения официального основного статуса среднего образования. Это будет обозначено в ЗАГСе на баннере.
0 при 30 кредитах требуется для получения официального основного статуса среднего образования. Это будет обозначено в ЗАГСе на баннере. - Для продолжения участия в Образовательной программе требуется минимальный средний балл 3.0 при 60 кредитах. Кандидаты, не имеющие минимального среднего балла, будут переведены в основную область содержания бакалавра / бакалавра и должны будут подать заявку на повторное зачисление в программу среднего образования бакалавриата в течение младшего года после достижения совокупного порога среднего балла.
- В весеннем семестре младшего года обучения (крайний срок 1 апреля) кандидаты должны подать онлайн-заявку на семестр профессионального развития (PDS). Процесс подачи заявки включает в себя собеседование с преподавателями предметной области. Кандидаты должны иметь средний балл 3.0, сдать базовый экзамен Praxis (ранее Praxis I), а также исправить любые компоненты, которым не был присвоен проходной балл, и сдать экзамен Praxis Subject Assessment Exam (ранее Praxis II).
- В осеннем семестре старшего года (крайний срок 1 ноября) кандидаты должны подать онлайн-заявку на место преподавателя.Обучение студентов осуществляется в течение весеннего семестра старшего года обучения. Все специальности среднего образования должны иметь совокупный средний балл не менее 3,0 по всем курсам, пройденным в рамках их курсов академического и профессионального образования. Требование к обучению студентов по специальностям среднего образования состоит из одного полного семестра (70 контактных дней) контролируемого обучения.
- В течение учебного семестра кандидаты должны одновременно регистрироваться на ED 340 и никакие другие курсы. Кандидаты несут ответственность за обеспечение собственного транспорта в школу и из школы, в которую они назначены для обучения студентов.Кандидатам, получившим оценку ниже «P» в обучении студентов, может потребоваться пройти дополнительное обучение студентов и / или курсовую работу, прежде чем они получат рекомендацию для выпуска и сертификации.
 Кандидаты должны иметь не менее 3,0 совокупного среднего балла по академическим и профессиональным предметам, необходимым для получения диплома по программам среднего образования.
Кандидаты должны иметь не менее 3,0 совокупного среднего балла по академическим и профессиональным предметам, необходимым для получения диплома по программам среднего образования. - Все требования к общеобразовательным курсам, требования к основным курсам факультетов искусств и наук и бесплатные факультативы должны быть выполнены до начала учебного семестра для студентов (согласно рекомендациям, каталогу курсов и листам программ факультета).
- Все курсы профессионального образования должны быть завершены (см. рекомендуемую последовательность ниже).
- Все кандидаты, обучающиеся по программам среднего образования (аттестация 7–12 классов), должны соответствовать требованиям по знанию иностранных языков.
- Все кандидаты должны иметь учетную запись LiveText и допуск по отпечатку пальца.
- Чтобы получить сертификат учителя государственной школы, необходимо сдать экзамен Praxis Subject Assessment по предметной области каждого кандидата.Экзамен, предлагаемый Службой образовательного тестирования, проверяет базовые знания предметной области, уникальные для каждой области сертификационного обучения.
 Хотя это и не является обязательным требованием для получения диплома, проходные баллы по соответствующим предметным экзаменам Praxis необходимы для поступления в PDS и для завершения программы и последующей рекомендации для сертификации. Копии результатов экзамена Praxis должны быть отправлены сотруднику университета по сертификации образования, находящемуся в Департаменте образования и педагогической психологии (WS 129), чтобы получить допуск к семестру профессионального развития.
Хотя это и не является обязательным требованием для получения диплома, проходные баллы по соответствующим предметным экзаменам Praxis необходимы для поступления в PDS и для завершения программы и последующей рекомендации для сертификации. Копии результатов экзамена Praxis должны быть отправлены сотруднику университета по сертификации образования, находящемуся в Департаменте образования и педагогической психологии (WS 129), чтобы получить допуск к семестру профессионального развития. - Кандидатам настоятельно рекомендуется сохранять обновленную и подписанную копию своей программы. Все требования для этой степени перечислены на этом листе, который можно получить у научного руководителя кандидата или заведующего кафедрой.
Отказ от ответственности в рамках программы: Обратите внимание, что правила сертификации учителей Коннектикута могут быть изменены в связи с законодательными предложениями и мандатами; информация, содержащаяся здесь, может не отражать самые последние изменения в Образовательной программе WCSU. Поэтому крайне важно, чтобы кандидаты часто сверялись со своими консультантами и посещали информационные сессии Департамента образования для получения обновлений и новых требований.
Поэтому крайне важно, чтобы кандидаты часто сверялись со своими консультантами и посещали информационные сессии Департамента образования для получения обновлений и новых требований.
Первокурсник/допрофессиональная курсовая работа и общеобразовательные требования
* Интенсивный курс письма (W)
* PSY 100 Введение в психологию
***HIS 148 Американская история до 1877 г. или
***HIS 149 Американская история с 1877 г.
* COM 160 Публичные выступления или
*
*
COM 161 Принятие решений в группах или
* COM 162 Межличностное общение или
* COM 163 Введение в навыки общения
Курсовая работа для второкурсников/допрофессиональной подготовки
** ED 206 Введение в образование
** ED 212 Педагогическая психология: детство и подростковый возраст II
** HPX 215 Вопросы здравоохранения в школах
Младший год/Область содержания и курс общего образования
Приступить к изучению предметной области и требований к общеобразовательному курсу в соответствии с рекомендациями и листами программ факультета.

Осенний семестр выпускного/профессионального развития Курсовая работа
**ED 385 Методы преподавания в средних школах
**ED 386 Опыт школы профессионального развития среднего образования
** EPY 405 Введение в специальное образование
** ED 440 Языковая интеграцияплюс один из курсов ниже, в зависимости от области содержимого :
**ED/HIS/SS 441 Преподавание истории и социальных наук в средних школах
**ED/BIO/CHE/ES 442 Преподавание естественных наук в средних школах
**ED/ENG 447 Преподавание английского языка в средних школах
**ED/ SPA 448 Преподавание испанского языка в средних школах
**ED/MAT 449 Преподавание математики в средних школах
Весна старшего года/Преподавание учащихся и курсовая работа по обязательному образованию
ED/MED 340 Оценка стратегий преподавания
ED 342 Преподавание учащихся по специальностям среднего образования
Обратите внимание: Кандидатам не следует регистрироваться на какие-либо другие курсы в течение учебного семестра; Компоненты практического опыта требуют, чтобы кандидаты сами обеспечивали транспорт до назначенных школ и обратно.
* Требуется минимум «C»
** Требуется минимум «B»
*** Исключая программы по истории и общественным наукам
Недостаток групповой и индивидуальной обобщаемости представляет собой угрозу для исследования людей. Мы использовали интенсивные данные повторных измерений — данные, которые собирались много раз по многим людям — для сравнения распределений двумерных корреляций, рассчитанных для испытуемых, по сравнению с другими.рассчитанные между субъектами. Поскольку подавляющее большинство исследований в области социальных и медицинских наук агрегируются по предметам, мы стремились оценить, насколько точно такие агрегации отражают составляющих их индивидуумов. Мы предоставляем доказательства того, что выводы, сделанные на основе агрегированных данных, могут быть тревожно неточными. В частности, дисперсия у отдельных лиц до четырех раз больше, чем у групп. Эти данные требуют сосредоточения внимания на идиографии и открытой науке, которые могут существенно изменить руководящие принципы передовой практики в области медицины и поведенческих наук.

Abstract
Только для эргодических процессов выводы, основанные на данных группового уровня, будут обобщаться на индивидуальный опыт или поведение. Поскольку социальные и психологические процессы человека обычно носят индивидуально-изменчивый и изменяющийся во времени характер, они вряд ли будут эргодичными. В этой статье для симметричного сравнения межиндивидуальных и внутрииндивидуальных вариаций использовались шесть исследований с повторными измерениями. Наши результаты определяют потенциальный масштаб и влияние неэргодических данных в исследованиях на людях.Анализ шести выборок (с 87–94 участниками и равным количеством оценок на одного участника) показал некоторую степень согласия в оценках центральной тенденции (среднее значение) между группами и отдельными лицами по конструктам и парадигмам сбора данных. Однако дисперсия ожидаемого значения была в два-четыре раза больше у отдельных людей, чем у групп. Это говорит о том, что литература по социальным и медицинским наукам может переоценивать точность агрегированных статистических оценок. Это наблюдение может иметь серьезные последствия для того, как мы понимаем согласованность между групповыми и индивидуальными корреляциями и обобщаемость выводов между областями.Исследователи должны явно проверять эквивалентность процессов на индивидуальном и групповом уровне в социальных и медицинских науках.
Это наблюдение может иметь серьезные последствия для того, как мы понимаем согласованность между групповыми и индивидуальными корреляциями и обобщаемость выводов между областями.Исследователи должны явно проверять эквивалентность процессов на индивидуальном и групповом уровне в социальных и медицинских науках.
Выводы, сделанные в социальных и медицинских исследованиях, обычно являются результатом статистических тестов, проведенных на агрегированных данных. Неявное предположение состоит в том, что групповые оценки могут применяться для понимания индивидуальной феноменологии, физиологии и поведения. Однако статистические данные на межиндивидуальном (групповом) уровне обобщаются на внутрииндивидуальный (личностный) уровень только в том случае, если рассматриваемые процессы являются эргодическими (1).Эргодические процессы эквивалентны для групп и индивидуумов (критерий однородности), когда их среднее значение и дисперсия остаются постоянными во времени (критерий стационарности) (2). Поскольку психологические и биологические явления организуются внутри людей с течением времени, обобщения, основанные на групповых оценках, неэргодичны, если есть индивидуальные исключения.
Поскольку психологические и биологические явления организуются внутри людей с течением времени, обобщения, основанные на групповых оценках, неэргодичны, если есть индивидуальные исключения.
Групповые оценки могут быть получены на основе поперечного измерения отдельных лиц в определенный момент времени, но для внутрииндивидуального анализа требуются данные, собираемые с течением времени, поскольку размер выборки становится количеством повторных наблюдений.Подобно тому, как случайная выборка должна быть репрезентативной для населения, чтобы поддерживать обобщающие утверждения об этой совокупности, данные, отобранные для отдельного человека во времени, должны быть репрезентативными для этого человека в целом (т. Е. Стационарными). Когда групповые обобщения скрывают подлинные индивидуальные различия, мы можем не описать естественные процессы и их естественные виды (3). Если нашими целями являются научная согласованность (4) и полнота (5), этого сценария следует избегать.
В этой статье мы утверждаем, что ( i ) неэргодичность — в частности, отсутствие возможности обобщения статистических оценок группы на индивидуальные — представляет собой угрозу исследованиям людей, потому что мы не знаем всего масштаба проблемы и недостаточно изучить его; и ( ii ), что ученые должны продемонстрировать согласованность между индивидуальной и групповой изменчивостью, прежде чем обобщать результаты на разных уровнях анализа.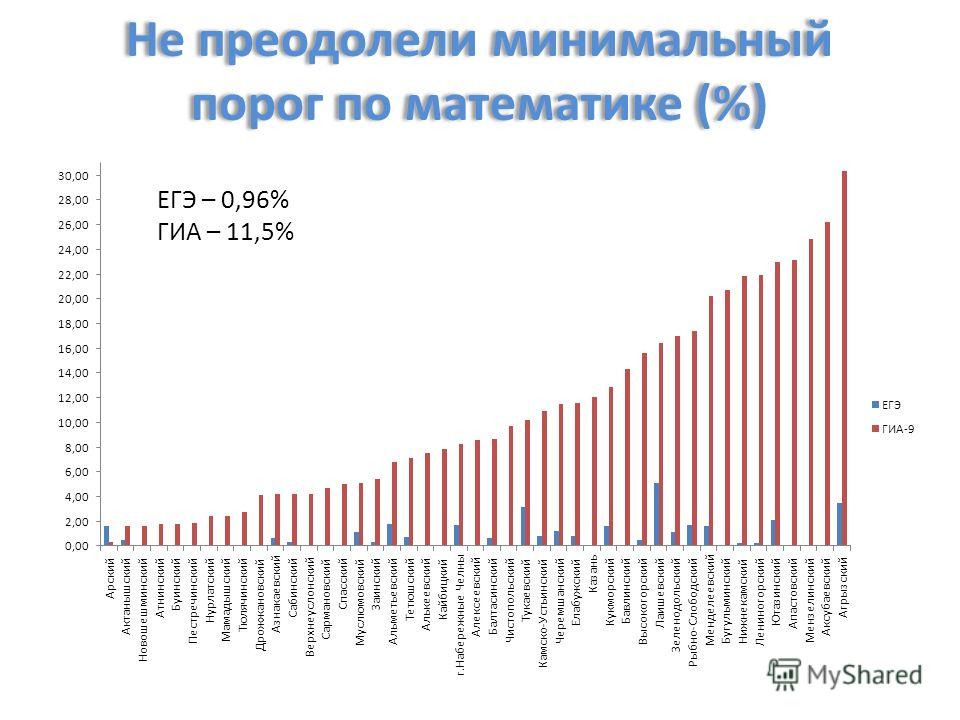 Мы будем ссылаться на это последнее условие как на «групповую-индивидуальную обобщаемость» данной статистической оценки. Однако независимо от того, сформулированы ли они в прозаических терминах или в рамках формальных математических теорем, исследователи систематически не изучали такую обобщаемость в существующей литературе, несмотря на ряд призывов сделать это на протяжении многих лет (см. ссылки 6⇓⇓⇓⇓–11). До сих пор самые влиятельные публикации в области медицинских и социальных наук в значительной степени основывались на данных, агрегированных по большим выборкам, а рекомендации по передовой практике почти исключительно основывались на статистических выводах из групповых моделей.Наихудший сценарий — глобальное единообразное отсутствие групповой и индивидуальной обобщаемости из-за неэргодичности в социальных и медицинских науках — подорвет обоснованность нашего научного канона в этих областях. Однако даже умеренное несоответствие между групповыми и индивидуальными оценками может привести к неточным или потенциально неверным выводам.
Мы будем ссылаться на это последнее условие как на «групповую-индивидуальную обобщаемость» данной статистической оценки. Однако независимо от того, сформулированы ли они в прозаических терминах или в рамках формальных математических теорем, исследователи систематически не изучали такую обобщаемость в существующей литературе, несмотря на ряд призывов сделать это на протяжении многих лет (см. ссылки 6⇓⇓⇓⇓–11). До сих пор самые влиятельные публикации в области медицинских и социальных наук в значительной степени основывались на данных, агрегированных по большим выборкам, а рекомендации по передовой практике почти исключительно основывались на статистических выводах из групповых моделей.Наихудший сценарий — глобальное единообразное отсутствие групповой и индивидуальной обобщаемости из-за неэргодичности в социальных и медицинских науках — подорвет обоснованность нашего научного канона в этих областях. Однако даже умеренное несоответствие между групповыми и индивидуальными оценками может привести к неточным или потенциально неверным выводам.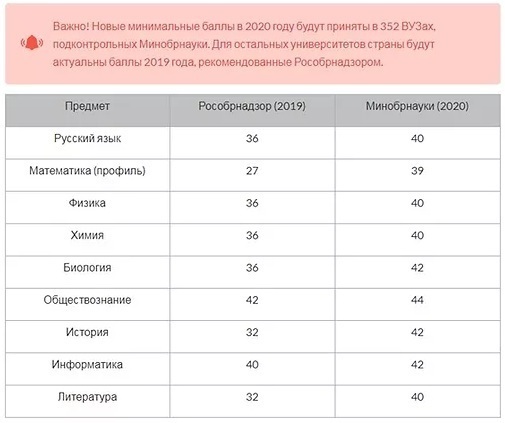 Мы утверждаем, что эта возможность должна быть официально проверена, где это возможно, чтобы быть исключенной.
Мы утверждаем, что эта возможность должна быть официально проверена, где это возможно, чтобы быть исключенной.
Эргодичность, экологическое заблуждение и парадокс Симпсона
Эргодическая теорема — это общее и формальное математическое выражение, которое имеет дело с обобщаемостью статистических явлений на разных уровнях и единицах анализа.[Хотя более подробное объяснение эргодической теоремы выходит за рамки настоящей статьи, читатели отсылаются к Моленаару (1) за исчерпывающим математическим описанием эргодичности в исследованиях с участием людей.] Эргодическая теория постулирует, что необходимые, хотя и не всегда достаточны — условия эргодичности в данных человека испытуемых заключаются в том, что структуры межиндивидуальной и внутрииндивидуальной вариации асимптотически эквивалентны (1). Эргодическую теорему можно понимать как общую систему отсчета для выявления конкретных случаев статистического несоответствия и ошибок вывода, включая парадокс Симпсона и экологическую ошибку.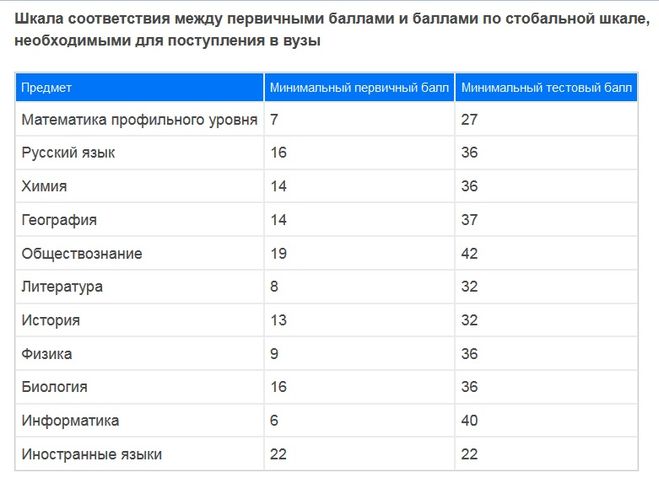 Парадокс Симпсона (12) представляет собой статистический эффект, при котором тенденции в подгруппах отличаются (или даже обратны) общей тенденции при объединении групп. Экологическая ошибка является распространенной и проблематичной ошибкой статистической интерпретации, при которой статистические выводы групп ненадлежащим образом обобщаются на отдельных лиц (13). Наглядный пример приводит Хамакер (14), который описывает взаимосвязь между скоростью набора текста и количеством опечаток. На групповом уровне корреляция отрицательна, так как опытные машинистки быстрее и опытнее.Однако внутри отдельных людей корреляция положительна: чем быстрее данный индивидуум печатает, тем больше ошибок он или она совершит по сравнению с их собственной производительностью на более медленных скоростях. Таким образом, агрегирование данных дает пример парадокса Симпсона, и мы совершим экологическую ошибку, заключив, что отношения, наблюдаемые на групповом уровне, представляют любого из индивидуумов в группе. И парадокс Симпсона, и экологическая ошибка напоминают нам, что индивидуальный уровень и уровень группы не обязательно связаны.
Парадокс Симпсона (12) представляет собой статистический эффект, при котором тенденции в подгруппах отличаются (или даже обратны) общей тенденции при объединении групп. Экологическая ошибка является распространенной и проблематичной ошибкой статистической интерпретации, при которой статистические выводы групп ненадлежащим образом обобщаются на отдельных лиц (13). Наглядный пример приводит Хамакер (14), который описывает взаимосвязь между скоростью набора текста и количеством опечаток. На групповом уровне корреляция отрицательна, так как опытные машинистки быстрее и опытнее.Однако внутри отдельных людей корреляция положительна: чем быстрее данный индивидуум печатает, тем больше ошибок он или она совершит по сравнению с их собственной производительностью на более медленных скоростях. Таким образом, агрегирование данных дает пример парадокса Симпсона, и мы совершим экологическую ошибку, заключив, что отношения, наблюдаемые на групповом уровне, представляют любого из индивидуумов в группе. И парадокс Симпсона, и экологическая ошибка напоминают нам, что индивидуальный уровень и уровень группы не обязательно связаны..jpg) Следовательно, эффекты неэргодичности в данном наборе данных должны быть непосредственно проверены до того, как будут сделаны какие-либо экстраполяции.
Следовательно, эффекты неэргодичности в данном наборе данных должны быть непосредственно проверены до того, как будут сделаны какие-либо экстраполяции.
К сожалению, прикладные тесты на эргодичность редко встречаются в социальных, поведенческих и медицинских науках. В то время как другие отмечают, что процессы внутри людей с течением времени отличаются от процессов, отобранных среди людей (см. ссылки 1, 15 и 16), четкая количественная оценка масштабов и потенциальной угрозы этого несоответствия в психосоциальной и медицинской областях должна быть рутинной задачей. Научное исследование.В то время как Перл (17, 18) продемонстрировал, что не существует единственной диагностики или коррекции парадокса Симпсона, мы предполагаем, что существует относительно простой способ прямой проверки на неэргодичность и, таким образом, групповую и индивидуальную обобщаемость в статистическом анализе. Проще говоря, сравнение первого и второго моментов (среднего значения и дисперсии) внутрииндивидуального и межиндивидуального распределений может сообщить нам о точности обобщений между группами и отдельными лицами. Чтобы тщательно изучить групповую и индивидуальную обобщаемость в социальных и медицинских науках, потребуются огромные совместные усилия во всех областях исследований людей.Тем временем отдельные исследователи могут решать вопрос о пригодности своих данных для обобщения агрегированных результатов для отдельных участников с помощью подходящих планов исследований и парадигм сбора данных. В частности, ученые, которые пытаются обобщить результаты между межиндивидуальными и внутрииндивидуальными уровнями анализа, должны собирать множество измерений у субъектов с течением времени, независимо от того, является ли исследовательский вопрос явно продольным. Более того, обмен данными и результатами может облегчить задачу всесторонней проверки на эргодичность в будущих исследованиях.К счастью, по мере того, как ресурсы данных становятся все более доступными благодаря открытому доступу, мы можем начать коллективно решать эту проблему. Чтобы определить важность этих усилий, мы используем шесть независимых наборов данных о повторно отобранных людях, чтобы провести сравнение между индивидуальными и межиндивидуальными вариациями.
Чтобы тщательно изучить групповую и индивидуальную обобщаемость в социальных и медицинских науках, потребуются огромные совместные усилия во всех областях исследований людей.Тем временем отдельные исследователи могут решать вопрос о пригодности своих данных для обобщения агрегированных результатов для отдельных участников с помощью подходящих планов исследований и парадигм сбора данных. В частности, ученые, которые пытаются обобщить результаты между межиндивидуальными и внутрииндивидуальными уровнями анализа, должны собирать множество измерений у субъектов с течением времени, независимо от того, является ли исследовательский вопрос явно продольным. Более того, обмен данными и результатами может облегчить задачу всесторонней проверки на эргодичность в будущих исследованиях.К счастью, по мере того, как ресурсы данных становятся все более доступными благодаря открытому доступу, мы можем начать коллективно решать эту проблему. Чтобы определить важность этих усилий, мы используем шесть независимых наборов данных о повторно отобранных людях, чтобы провести сравнение между индивидуальными и межиндивидуальными вариациями.
Что именно мы должны тестировать и как?
Чтобы обобщить групповые выводы на индивидуумов, нас должны интересовать меры центральной тенденции и меры ковариации.Центральная тенденция, обычно представляемая как среднее значение или медиана, отражает ожидаемое значение распределения — наиболее вероятное значение переменной — и, таким образом, является общим показателем характера переменной в целом. Для применения группового обобщения к индивидууму центральная тенденция среди индивидуумов, отобранных с течением времени, должна быть такой же, как между индивидуумами. Удобно, что общие показатели доступны для определения сходства (по сравнению с непохожестью) соответствующих центральных тенденций.
Среднее значение выборки обычно используется для определения того, статистически отличается ли одна группа от другой группы, как функция отношения между средней разницей и разбросом вокруг этой разницы (SE). Это отношение сигнал-шум: сигналы, размер которых примерно в два раза превышает размер соответствующего шума, считаются статистически значимыми. В свою очередь, SE, составляющая знаменатель в этом соотношении, является функцией размера выборки, а SD — средним отклонением от среднего значения по выборке.Таким образом, средние значения всегда следует рассматривать в контексте стандартных отклонений, и при тестировании на неэргодичность следует рассматривать и то, и другое.
В свою очередь, SE, составляющая знаменатель в этом соотношении, является функцией размера выборки, а SD — средним отклонением от среднего значения по выборке.Таким образом, средние значения всегда следует рассматривать в контексте стандартных отклонений, и при тестировании на неэргодичность следует рассматривать и то, и другое.
Как помнят читатели, стандартное отклонение — это квадратный корень из дисперсии, а дисперсия, в свою очередь, составляет половину совместной изменчивости — «ковариации» между двумя переменными. Ковариация представляет собой основу количественного анализа в социальных, поведенческих и медицинских науках. Все элементы классической статистики, основанные на общей линейной модели, включая регрессию, дисперсионный анализ, многоуровневое моделирование и моделирование структурными уравнениями, используют ковариацию между переменными для поддержки статистических выводов.Чтобы статистические оценки можно было обобщить с групп на индивидуумов, необходимо, чтобы отношения между внутрииндивидуальными переменными были эквивалентны отношениям между межиндивидуальными переменными.
Таким образом, поскольку центральная тенденция часто используется для представления общих данных, тесты, которые измеряют достоверность групповых и индивидуальных обобщений, должны проверять согласованность среднего значения для групп и отдельных лиц. Поскольку «сигнал», который представляет среднее значение, настолько силен, насколько силен его отношение к дисперсии, мы должны в равной степени заботиться об эквивалентности дисперсии (и SD).Наконец, статистические выводы, сделанные на основе взаимосвязей между переменными, должны быть проверены на согласованность в двумерной и многомерной ковариации между этими переменными.
Что поставлено на карту?
Последствия пренебрежения эргодической теорией в социальной, поведенческой и медицинской областях могут иметь существенные эпистемологические и практические последствия. При отсутствии количественного исследования на индивидуальном уровне последствия могут варьироваться от нулевых, если нам повезет найти один из немногих эргодических процессов в природе (19), до катастрофических, если процесс совершенно неэргодический. В клинических исследованиях диагностические тесты могут быть систематически предвзятыми, и наши системы классификации могут быть, по крайней мере, частично недействительными. С точки зрения развития теории у нас может сложиться ложное впечатление о природе психологических переменных и их взаимодействии. Что касается экспериментов, мы не можем разрабатывать и использовать исследовательские проекты, необходимые для адекватной диагностики этих проблем. В целом нам, возможно, придется пересмотреть то, как мы сообщаем статистические принципы студентам и исследователям, и поощрять их к разработке исследований, способных проводить явные тесты согласованности внутрииндивидуальных и межиндивидуальных вариаций в различных условиях, парадигмах и конструкциях.Здесь мы начинаем рассматривать ставки.
В клинических исследованиях диагностические тесты могут быть систематически предвзятыми, и наши системы классификации могут быть, по крайней мере, частично недействительными. С точки зрения развития теории у нас может сложиться ложное впечатление о природе психологических переменных и их взаимодействии. Что касается экспериментов, мы не можем разрабатывать и использовать исследовательские проекты, необходимые для адекватной диагностики этих проблем. В целом нам, возможно, придется пересмотреть то, как мы сообщаем статистические принципы студентам и исследователям, и поощрять их к разработке исследований, способных проводить явные тесты согласованности внутрииндивидуальных и межиндивидуальных вариаций в различных условиях, парадигмах и конструкциях.Здесь мы начинаем рассматривать ставки.
Сравнение внутрииндивидуальных и межиндивидуальных распределений
По шести ранее опубликованным наборам данных мы количественно оценили внутрииндивидуальные и межиндивидуальные вариации и ковариации для нескольких образцов и конструкций. Мы провели примерно симметричные сравнения, рассчитав внутрииндивидуальные и межиндивидуальные оценки по эквивалентному количеству индивидуальных и перекрестных наборов данных. Учитывая парадигмы повторных измерений, используемые в каждом из исследований, множественные наборы данных поперечного сечения были построены из межсубъектных агрегаций внутрисубъектных данных на основе наблюдения за наблюдением.То есть объединение набора первых строк для данных повторных измерений каждого человека в данной выборке дало набор перекрестных данных с n = число участников. Объединение всех вторых строк также дало набор данных поперечного сечения с n = число участников и т. д. (подробности см. в методе ). Это позволило нам выйти за рамки одноточечных оценок и сравнить распределения сопоставимых перекрестных и внутрииндивидуальных средних и дисперсий — как одномерных описательных переменных исследования, так и двумерных ассоциаций между этими переменными.
Мы провели примерно симметричные сравнения, рассчитав внутрииндивидуальные и межиндивидуальные оценки по эквивалентному количеству индивидуальных и перекрестных наборов данных. Учитывая парадигмы повторных измерений, используемые в каждом из исследований, множественные наборы данных поперечного сечения были построены из межсубъектных агрегаций внутрисубъектных данных на основе наблюдения за наблюдением.То есть объединение набора первых строк для данных повторных измерений каждого человека в данной выборке дало набор перекрестных данных с n = число участников. Объединение всех вторых строк также дало набор данных поперечного сечения с n = число участников и т. д. (подробности см. в методе ). Это позволило нам выйти за рамки одноточечных оценок и сравнить распределения сопоставимых перекрестных и внутрииндивидуальных средних и дисперсий — как одномерных описательных переменных исследования, так и двумерных ассоциаций между этими переменными.
Метод
Настоящее исследование включает набор анализов шести ранее опубликованных наборов данных на групповом и индивидуальном уровнях. Все процедуры исследования были одобрены соответствующими институциональными наблюдательными советами и проводились в соответствии с этическими стандартами.
Все процедуры исследования были одобрены соответствующими институциональными наблюдательными советами и проводились в соответствии с этическими стандартами.
Участники.
Образец 1.
Первая выборка включает 43 человека с основным генерализованным тревожным расстройством (ГТР) и/или большим депрессивным расстройством (БДР) и 35 здоровых участников контрольной группы.Подробная информация о процедурах найма, скрининга и диагностических интервью предоставлена Fisher et al. (20). 78 участников были преимущественно женщинами ( n = 48, 62%) и белыми ( n = 35, 45%). После зачисления в исследование номера мобильных телефонов участников были введены в защищенную веб-систему опроса. Четыре раза в день в течение 30 дней участники получали текстовое сообщение, содержащее гиперссылку на веб-опрос (каждый с отметкой времени). Участники оценивали свое впечатление от каждого элемента за предыдущие часы, используя визуальный аналоговый ползунок от 0 до 100 с якорями «совсем нет» (= 0) и «насколько это возможно» (= 100).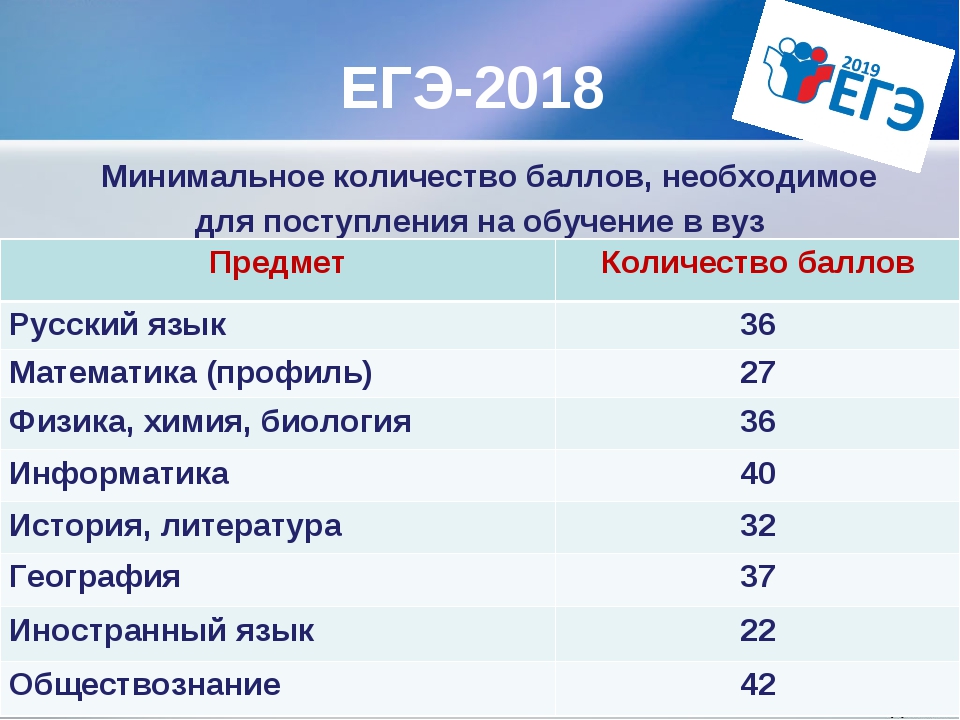 В дополнение к существующим критериям Диагностического и статистического руководства по психическим расстройствам, пятое издание (DSM-5) (21) критериев ГТР и БДР, опросы включали дополнительные 11 пунктов, оценивающих положительный аффект (ПА) (положительный, энергичный, восторженный). , и содержание), негативный аффект (NA) (злость, страх и зацикленность на прошлом) и поведенческое избегание (избегание людей, избегание деятельности, поиск утешения и прокрастинация). Это исследование было одобрено Институциональным наблюдательным советом Калифорнийского университета (протокол Комитета по защите прав человека №2014-03-6138; Название протокола Комитета по защите людей: Персонализированные вмешательства при тревоге и депрессии). Перед участием было получено письменное информированное согласие.
В дополнение к существующим критериям Диагностического и статистического руководства по психическим расстройствам, пятое издание (DSM-5) (21) критериев ГТР и БДР, опросы включали дополнительные 11 пунктов, оценивающих положительный аффект (ПА) (положительный, энергичный, восторженный). , и содержание), негативный аффект (NA) (злость, страх и зацикленность на прошлом) и поведенческое избегание (избегание людей, избегание деятельности, поиск утешения и прокрастинация). Это исследование было одобрено Институциональным наблюдательным советом Калифорнийского университета (протокол Комитета по защите прав человека №2014-03-6138; Название протокола Комитета по защите людей: Персонализированные вмешательства при тревоге и депрессии). Перед участием было получено письменное информированное согласие.
Образец 2.
Участники из образца 2 приняли участие в полисомнографическом исследовании, проведенном в Национальном центре посттравматического стрессового расстройства (ПТСР) в Менло-Парке, Калифорния. В настоящем исследовании используются только данные о частоте сердечных сокращений (ЧСС) и дыхательной синусовой аритмии (ДСА). Полная информация о процедурах рекрутинга, скрининге, диагностическом опросе, а также сборе и методологии физиологических данных (включая очистку и подготовку сигнала электрокардиографии) опубликована в исследовании Fisher and Woodward (22).Настоящая выборка включала 69 человек, 16 здоровых людей из контрольной группы, 23 человека с посттравматическим стрессовым расстройством, 14 человек с паническим расстройством и 16 человек с сопутствующим посттравматическим стрессовым расстройством и паническим расстройством. Групповых различий по ЧСС или RSA обнаружено не было (22). Это исследование было санкционировано Стэнфордской программой защиты исследований человека Пало-Альто по делам ветеранов (VA). Все участники дали письменное информированное согласие.
В настоящем исследовании используются только данные о частоте сердечных сокращений (ЧСС) и дыхательной синусовой аритмии (ДСА). Полная информация о процедурах рекрутинга, скрининге, диагностическом опросе, а также сборе и методологии физиологических данных (включая очистку и подготовку сигнала электрокардиографии) опубликована в исследовании Fisher and Woodward (22).Настоящая выборка включала 69 человек, 16 здоровых людей из контрольной группы, 23 человека с посттравматическим стрессовым расстройством, 14 человек с паническим расстройством и 16 человек с сопутствующим посттравматическим стрессовым расстройством и паническим расстройством. Групповых различий по ЧСС или RSA обнаружено не было (22). Это исследование было санкционировано Стэнфордской программой защиты исследований человека Пало-Альто по делам ветеранов (VA). Все участники дали письменное информированное согласие.
Образец 3.
Участники из образца 3 были взяты из исследования экологической моментальной оценки лиц с клинически диагностированным расстройством личности (23, 24). Участники ( n = 101) заполняли рейтинги психосоциального и межличностного опыта один раз в день в течение 100 дней. Полную информацию о наборе, диагностике и процедурах исследования можно найти в исследованиях Wright et al. (23) и Райт и Симмс (24). В настоящем исследовании использовалась подвыборка из 83 участников, заполнивших как минимум 83 опроса ( Аналитический подход ) по переменным на уровне шкалы PA и NA, используя подмножество элементов Таблицы положительных и отрицательных воздействий (PANAS) (25) оцениваемых элементов. по пятибалльной шкале (очень незначительно или совсем отсутствует, немного, умеренно, совсем немного и очень сильно) «за последние 24 ч.Ежедневный PA измерялся как среднее значение пунктов: активный, бдительный, внимательный, решительный и воодушевленный. Ежедневная NA измерялась как среднее значение страха, стыда, враждебности, нервозности и расстройства. Чтобы соответствовать показателю аффекта, используемому в образце 6 (ниже), следует отметить, что показатели для PA и NA в образце 3 согласуются, в частности, с высоким возбуждением PA и NA.
Участники ( n = 101) заполняли рейтинги психосоциального и межличностного опыта один раз в день в течение 100 дней. Полную информацию о наборе, диагностике и процедурах исследования можно найти в исследованиях Wright et al. (23) и Райт и Симмс (24). В настоящем исследовании использовалась подвыборка из 83 участников, заполнивших как минимум 83 опроса ( Аналитический подход ) по переменным на уровне шкалы PA и NA, используя подмножество элементов Таблицы положительных и отрицательных воздействий (PANAS) (25) оцениваемых элементов. по пятибалльной шкале (очень незначительно или совсем отсутствует, немного, умеренно, совсем немного и очень сильно) «за последние 24 ч.Ежедневный PA измерялся как среднее значение пунктов: активный, бдительный, внимательный, решительный и воодушевленный. Ежедневная NA измерялась как среднее значение страха, стыда, враждебности, нервозности и расстройства. Чтобы соответствовать показателю аффекта, используемому в образце 6 (ниже), следует отметить, что показатели для PA и NA в образце 3 согласуются, в частности, с высоким возбуждением PA и NA. Это исследование было одобрено Университетом Буффало, Государственным университетом Нью-Йорка, Институциональным наблюдательным советом. Перед участием было получено письменное информированное согласие.
Это исследование было одобрено Университетом Буффало, Государственным университетом Нью-Йорка, Институциональным наблюдательным советом. Перед участием было получено письменное информированное согласие.
Образец 4.
Участники из образца 4 были отобраны из рандомизированного контролируемого исследования (РКИ) клинической депрессии, в котором 64 человека были рандомизированы для получения имипрамина или плацебо (26). Перед лечением участники принимали участие в интенсивной парадигме повторных измерений, в которой они выполняли опросы 10 раз в день в течение 6 дней. Эти данные подробно описаны в другом месте (см. ссылки 26 и 27). Средний возраст участников составлял 42,5 года (стандартное отклонение 9,1), и большую часть выборки составляли женщины (74%).В настоящем исследовании используются шкала PA (среднее значение энергичного, веселого, удовлетворенного, бдительного, спокойного, восторженного, сильного и счастливого) и шкалы NA (среднее значение враждебного, подавленного, напряженного, одинокого, тревожного, неуверенного в себе, виноватого, измученного и беспокойного). раздражительный). Все процедуры исследования были одобрены Комитетом по медицинской этике Медицинского центра Маастрихтского университета, и все участники подписали форму информированного согласия.
раздражительный). Все процедуры исследования были одобрены Комитетом по медицинской этике Медицинского центра Маастрихтского университета, и все участники подписали форму информированного согласия.
Образец 5.
Пятый образец был взят из РКИ по когнитивной терапии, основанной на осознанности (MBCT), в котором 64 человека были рандомизированы для MBCT, а 66 были рандомизированы для контрольной группы ожидания (28).В настоящем исследовании использовались только те люди, которые были рандомизированы для MBCT. Как и в случае с образцом 4, участники ежедневно заполняли парадигму опроса перед лечением. Каждому участнику были выданы цифровые наручные часы и оценочные формы для заполнения ежедневных самоотчетов. Часы были запрограммированы так, чтобы сигнализировать участнику через случайные промежутки времени в каждом из 10 90-минутных блоков между 7:30 и 22:30. Оценки проводились в течение 6 дней подряд, максимум 60 сигналов за период исследования. По каждому сигналу участников просили заполнить формы самооценки.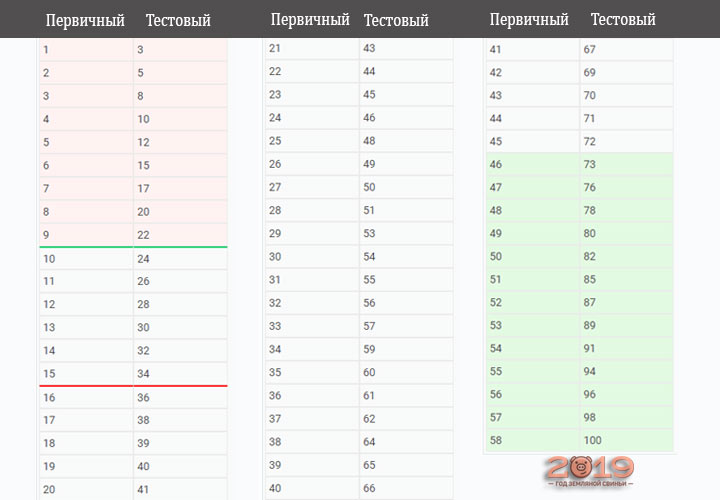 Текущее настроение и контекст оценивались по семибалльной шкале Лайкерта. В соответствии с образцами 3 и 4, в настоящем исследовании использовались шкалы для PA (среднее значение счастливого, удовлетворенного, сильного, восторженного, любопытного, воодушевленного и воодушевленного) и NA (среднее значение подавленности, беспокойства, одиночества, подозрительности, разочарования, неуверенности, и виновен). Все процедуры исследования были одобрены Комитетом по медицинской этике Медицинского центра Маастрихтского университета, и все участники подписали форму информированного согласия.
Текущее настроение и контекст оценивались по семибалльной шкале Лайкерта. В соответствии с образцами 3 и 4, в настоящем исследовании использовались шкалы для PA (среднее значение счастливого, удовлетворенного, сильного, восторженного, любопытного, воодушевленного и воодушевленного) и NA (среднее значение подавленности, беспокойства, одиночества, подозрительности, разочарования, неуверенности, и виновен). Все процедуры исследования были одобрены Комитетом по медицинской этике Медицинского центра Маастрихтского университета, и все участники подписали форму информированного согласия.
Образец 6.
Окончательная выборка была взята из продолжающегося натуралистического исследования «Как орехи являются голландцами» (HoeGekIsNL), в котором 975 участников заполняли дневники три раза в день в течение 30 дней. Полную методологию и процедуры исследования можно найти в van der Krieke et al. (29). В этой подвыборке среднее количество дневниковых ответов составило 60,53 (СО 18,10). Выборка на 82% состояла из женщин ( n = 449), а средний возраст составил 40,68 года (стандартное отклонение 13,53). Переменными, использованными в настоящем исследовании, были PA и NA с высоким уровнем возбуждения и PA и NA с низким уровнем возбуждения, рассчитанные на основе вопросов 5–16 ежедневного дневника (см.29, с. 129). Настоящее исследование включало 535 участников (55%), заполнивших не менее 44 анкет. Протокол исследования HND был оценен Комитетом по медицинской этике Университетского медицинского центра Гронингена и признан освобожденным от действия Закона о медицинских исследованиях с участием людей (на голландском языке: ВМО), поскольку он касался нерандомизированного открытого исследования, нацеленного на анонимных добровольцев в целом. общественный (регистрационный № M13.147422).
Переменными, использованными в настоящем исследовании, были PA и NA с высоким уровнем возбуждения и PA и NA с низким уровнем возбуждения, рассчитанные на основе вопросов 5–16 ежедневного дневника (см.29, с. 129). Настоящее исследование включало 535 участников (55%), заполнивших не менее 44 анкет. Протокол исследования HND был оценен Комитетом по медицинской этике Университетского медицинского центра Гронингена и признан освобожденным от действия Закона о медицинских исследованиях с участием людей (на голландском языке: ВМО), поскольку он касался нерандомизированного открытого исследования, нацеленного на анонимных добровольцев в целом. общественный (регистрационный № M13.147422).
Аналитический подход.
Мы стремились количественно оценить степень, в которой групповые данные могут описывать отдельных участников, путем сравнения внутрииндивидуальных и межиндивидуальных вариаций и ковариаций в нескольких выборках и конструкциях.Мы использовали интенсивные данные повторных измерений для сравнения одномерных распределений каждой переменной, а также распределений двумерных корреляций, рассчитанных внутри субъектов, и распределений, рассчитанных между субъектами. Как указано ниже, одни и те же данные (участники и переменные) использовались для межиндивидуальных и внутрииндивидуальных сравнений, чтобы мы могли напрямую оценить степень, в которой агрегации отражают составляющих их индивидуумов.
Как указано ниже, одни и те же данные (участники и переменные) использовались для межиндивидуальных и внутрииндивидуальных сравнений, чтобы мы могли напрямую оценить степень, в которой агрегации отражают составляющих их индивидуумов.
Временная зависимость.
Как подробно обсуждалось в другом месте, статистические оценки данных повторных измерений могут быть смещены из-за временной зависимости (см.исх. 30 и 31). То есть люди будут иметь тенденцию коррелировать сами с собой с течением времени, что приведет к коррелированным ошибкам в моделях, которые не учитывают лежащую в основе автокорреляцию. Хотя одним из распространенных способов обработки временной зависимости при повторных измерениях является использование многоуровневой модели, которая разделяет дисперсию зависимых переменных на фиксированные и случайные эффекты (32), эти модели не отражают истинную внутрииндивидуальную вариацию (33). Вместо этого они отражают индивидуальные отклонения (в точке пересечения и наклоне) от агрегированных оценок. Чтобы выделить истинную внутрииндивидуальную вариацию и ковариацию, мы использовали тест Дарбина-Ватсона (34) для оценки степени временной зависимости каждой внутрииндивидуальной переменной.
Чтобы выделить истинную внутрииндивидуальную вариацию и ковариацию, мы использовали тест Дарбина-Ватсона (34) для оценки степени временной зависимости каждой внутрииндивидуальной переменной.
Источники запаздывающей и перекрестно запаздывающей временной зависимости были исследованы для каждой пары двумерных переменных, проанализированных ниже. Были построены регрессионные модели, в которых каждая внутрииндивидуальная переменная подвергалась регрессии по ее авторегрессии первого порядка (т. е. запаздывание-1) и перекрестному запаздыванию первого порядка для любых двумерных пар. Например, поскольку мы изучили отдельные двумерные корреляции для подавленного настроения с ангедонией и подавленного настроения с тревогой (выборка 1), были построены две регрессионные модели для переменной депрессивного настроения, одна с перекрестными запаздываниями измерений ангедонии и одна с перекрестными запаздываниями. запаздывающие измерения беспокоят .Для любой двумерной пары X и Y соответствующие модели регрессии выражаются алгебраически следующим образом: Yt=β1Yt−1+β2Xt−1+et,Xt=β1Xt−1+β2Yt−1+et.
Критерий Дарбина-Ватсона применялся для оценки степени временной зависимости остатков каждой регрессионной модели.
Включение запаздывающих и перекрестно запаздывающих переменных первого порядка эффективно удалило временную зависимость (т.е. отбелило) большинство индивидуальных данных для каждой из поведенческих переменных из выборок 1, 3, 4, 5 и 6 (диапазон, 86–99%, средний процент 97%).Однако после проведения регрессионных моделей первого порядка временная зависимость осталась в небольшом количестве этих поведенческих данных и в большинстве психофизиологических данных из выборки 2. Для каждой внутрииндивидуальной переменной, которая дала статистику теста Дарбина-Уотсона P < 0,05, были проведены дополнительные регрессионные модели — каждая с дополнительным набором запаздывающих и перекрестно запаздывающих параметров — до тех пор, пока не было обнаружено, что остатки для регрессионной модели эффективно отбеливаются. Модели, включающие переменные лаг-2, эффективно обесценивали оставшуюся часть всех, кроме одной, внутрииндивидуальных поведенческих переменных, 57% внутрииндивидуальных данных ЧСС и 72% данных RSA. Требовались модели с тремя или более лагами для одной внутрииндивидуальной переменной PA из выборки 4, 39% данных HR и 16% данных RSA из выборки 2. каждой переменной.
Требовались модели с тремя или более лагами для одной внутрииндивидуальной переменной PA из выборки 4, 39% данных HR и 16% данных RSA из выборки 2. каждой переменной.
Как только регрессионная модель давала незначительную статистику теста Дарбина-Ватсона, остатки сохранялись для дальнейшего анализа. Мы называем эти данные остатками AR. Таким образом, для каждой двумерной корреляции, представленной ниже, мы сообщаем средние значения и стандартные отклонения для внутрииндивидуальных оценок, полученных из необработанных данных, а также из остаточных данных AR.
Построение межиндивидуальных сечений.
Как отмечалось выше, настоящее исследование было направлено на сравнение перекрестных агрегированных данных с индивидуальными, меняющимися во времени данными, чтобы исследовать степень, в которой агрегации представляют составляющие их индивидуумы. Для проведения таких сравнений нам потребовались множественные внутрииндивидуальные временные ряды и межиндивидуальные срезы, которые должны состоять из одних и тех же лиц. Сохранившиеся данные шести исследований состояли из первых: отдельных временных рядов длиной от 69 до 900 наблюдений.Таким образом, эти временные ряды включают повторные наблюдения во времени, собранные как минимум в 69 отдельных случаях. Для проведения перекрестных сравнений каждое повторное наблюдение использовалось дважды: как отдельное наблюдение в рамках отдельного временного ряда и как отдельный участник в агрегированном поперечном сечении. То есть, если в исследовании участвуют 100 человек, и каждый человек предоставляет 100 наблюдений с течением времени, мы можем представить всю выборку данных в матрице 100 (наблюдения) × 100 (индивиды).Таким образом, мы можем рассматривать каждую строку как выборку из 100 отдельных людей, измеренных один раз, а каждый столбец как временной ряд для одного человека, измеренный 100 раз. Распространяя это на многомерное пространство, если временные ряды каждого человека организованы таким образом, что наблюдения во времени находятся в строках, а переменные — в столбцах, объединение набора первых строк даст набор перекрестных данных с размером выборки между субъектами n = 100.
Сохранившиеся данные шести исследований состояли из первых: отдельных временных рядов длиной от 69 до 900 наблюдений.Таким образом, эти временные ряды включают повторные наблюдения во времени, собранные как минимум в 69 отдельных случаях. Для проведения перекрестных сравнений каждое повторное наблюдение использовалось дважды: как отдельное наблюдение в рамках отдельного временного ряда и как отдельный участник в агрегированном поперечном сечении. То есть, если в исследовании участвуют 100 человек, и каждый человек предоставляет 100 наблюдений с течением времени, мы можем представить всю выборку данных в матрице 100 (наблюдения) × 100 (индивиды).Таким образом, мы можем рассматривать каждую строку как выборку из 100 отдельных людей, измеренных один раз, а каждый столбец как временной ряд для одного человека, измеренный 100 раз. Распространяя это на многомерное пространство, если временные ряды каждого человека организованы таким образом, что наблюдения во времени находятся в строках, а переменные — в столбцах, объединение набора первых строк даст набор перекрестных данных с размером выборки между субъектами n = 100. Объединение всех вторых строк также даст набор данных поперечного сечения с n = 100 и так далее.
Объединение всех вторых строк также даст набор данных поперечного сечения с n = 100 и так далее.
Для каждого образца мы стремились сделать сравнения, которые были бы симметричными по масштабу и максимально мощными. Симметрию преследовали, чтобы ограничить степень, в которой различия в статистической мощности влияют на сравнение межиндивидуальных и внутрииндивидуальных вариаций. Исключения из симметрии описаны ниже. Для каждой выборки мы определили количество участников и строк на одного участника, которые дадут максимальное количество наборов данных внутри и между людьми.
Образцы 1, 2 и 3 содержали образцы размером 78, 69 и 101 человек соответственно.Парадигмы сбора данных для каждого исследования давали отдельные временные ряды со средним числом наблюдений 130, 925 и 90 в каждом. Поскольку длина временных рядов в выборках 1 и 2 была больше, чем количество участников для каждого исследования, мы сгенерировали строки случайных чисел, чтобы выбрать случайное подмножество из 78 и 69 строк из каждого индивидуального набора данных в выборках 1 и 2 соответственно. Как описано выше, каждая случайно выбранная строка была извлечена из каждого из индивидуальных наборов данных и объединена между участниками, чтобы получить межиндивидуальный набор данных поперечного сечения.Для выборки 1 сравнение межиндивидуальных и внутрииндивидуальных вариаций проводилось между 78 наборами данных для отдельных лиц со средней длиной временного ряда 130 наблюдений и 78 наборами данных для отдельных лиц, каждый с размером выборки между субъектами n = 78. Сравнение для выборка 2 включала 69 внутрииндивидуальных наборов данных со средней длиной временного ряда 925 наблюдений и 69 межиндивидуальных наборов данных, каждый с размером выборки между субъектами n = 69.
Как описано выше, каждая случайно выбранная строка была извлечена из каждого из индивидуальных наборов данных и объединена между участниками, чтобы получить межиндивидуальный набор данных поперечного сечения.Для выборки 1 сравнение межиндивидуальных и внутрииндивидуальных вариаций проводилось между 78 наборами данных для отдельных лиц со средней длиной временного ряда 130 наблюдений и 78 наборами данных для отдельных лиц, каждый с размером выборки между субъектами n = 78. Сравнение для выборка 2 включала 69 внутрииндивидуальных наборов данных со средней длиной временного ряда 925 наблюдений и 69 межиндивидуальных наборов данных, каждый с размером выборки между субъектами n = 69.
Выборка 3 содержала большее количество участников (101), чем среднее количество наблюдений на одного участника (в среднем 89). Мы определили максимальное количество участников с эквивалентным минимальным количеством наблюдений на одного участника, равным 83, и взяли первые 83 наблюдения каждого интраиндивидуального набора данных для построения наборов данных перекрестного сравнения. Таким образом, для выборки 3 сравнение межиндивидуальной и внутрииндивидуальной изменчивости проводилось между 83 наборами данных внутри индивидуума со средней длиной временного ряда 94 наблюдения и 83 наборами данных между индивидуумами, каждый с размером выборки между субъектами n = 83.
Таким образом, для выборки 3 сравнение межиндивидуальной и внутрииндивидуальной изменчивости проводилось между 83 наборами данных внутри индивидуума со средней длиной временного ряда 94 наблюдения и 83 наборами данных между индивидуумами, каждый с размером выборки между субъектами n = 83.
Образцы 4 и 5 содержали 63 и 64 участника, каждый из которых выполнил 30–60 наблюдений. Чтобы создать симметричные сравнения для этих выборок, мы разрешили отдельным наборам данных иметь переменные размеры выборки. То есть для обеих выборок межиндивидуальные наборы данных 1–30 содержали 63 и 64 участника соответственно. По мере увеличения количества индивидуальных наборов данных общий размер выборки для каждого набора уменьшался. Для выборки 4 минимальный объем индивидуальной выборки составил n = 58, а для выборки 5 минимальный объем индивидуальной выборки составил n = 52.
Наконец, выборка 6 содержала 975 участников с временными рядами от 0 до 93 наблюдений. Симметричные сравнения между индивидуальными и межиндивидуальными данными потребовали бы отбрасывания более 800 участников. Учитывались ( i ) минимальное количество наблюдений, чтобы получить надежные оценки двумерных корреляций для каждого человека, и ( ii ) максимальное количество участников с эквивалентным минимальным количеством наблюдений на участника.Размер выборки 44 был выбран в качестве минимального порога для внутрииндивидуальных корреляций, что дало выборку из 535 наборов данных внутри индивидуума со средним значением 68 наблюдений на человека. Что касается межиндивидуальных сравнений, мы определили 58 участников с минимум 85 наблюдениями. Первые 85 последовательных строк этих 58 индивидуальных наборов данных были объединены для создания 85 отдельных наборов данных, каждый с размером выборки 58. Таким образом, для выборки 6 симметрия была исключена для анализа полного набора из 535 выбранных временных рядов.Сравнение межиндивидуальной и внутрииндивидуальной изменчивости проводилось между 535 наборами внутрииндивидуальных данных со средней длиной временного ряда 68 наблюдений и 85 наборами межиндивидуальных данных, каждый с размером выборки между субъектами n = 58.
Симметричные сравнения между индивидуальными и межиндивидуальными данными потребовали бы отбрасывания более 800 участников. Учитывались ( i ) минимальное количество наблюдений, чтобы получить надежные оценки двумерных корреляций для каждого человека, и ( ii ) максимальное количество участников с эквивалентным минимальным количеством наблюдений на участника.Размер выборки 44 был выбран в качестве минимального порога для внутрииндивидуальных корреляций, что дало выборку из 535 наборов данных внутри индивидуума со средним значением 68 наблюдений на человека. Что касается межиндивидуальных сравнений, мы определили 58 участников с минимум 85 наблюдениями. Первые 85 последовательных строк этих 58 индивидуальных наборов данных были объединены для создания 85 отдельных наборов данных, каждый с размером выборки 58. Таким образом, для выборки 6 симметрия была исключена для анализа полного набора из 535 выбранных временных рядов.Сравнение межиндивидуальной и внутрииндивидуальной изменчивости проводилось между 535 наборами внутрииндивидуальных данных со средней длиной временного ряда 68 наблюдений и 85 наборами межиндивидуальных данных, каждый с размером выборки между субъектами n = 58.
Результаты
Одномерные распределения .
Сначала мы исследовали одномерное распределение каждой из 15 исследуемых переменных на межиндивидуальном и внутрииндивидуальном уровнях. Средние значения и стандартные отклонения для каждой переменной на каждом уровне анализа представлены в таблице 1.Средние оценки были статистически эквивалентны по 14 из 15 переменных (все p > 0,05), при этом относительные межиндивидуальные и внутрииндивидуальные средние значения находились в пределах 7% друг от друга (среднее расхождение, 3%). Средние оценки внутрииндивидуальной и межиндивидуальной ФА в выборке 4 продемонстрировали значительное расхождение в 45% ( P = 0,003). Однако, несмотря на согласованность средних оценок, стандартные отклонения для внутрииндивидуальных и межиндивидуальных оценок демонстрировали заметные расхождения, причем первые не менее 3.В 79 раз больше, чем последнее, по всем 15 переменным (минимальное соотношение 3,79:1, максимальное соотношение 13,20:1, среднее соотношение 7,85:1).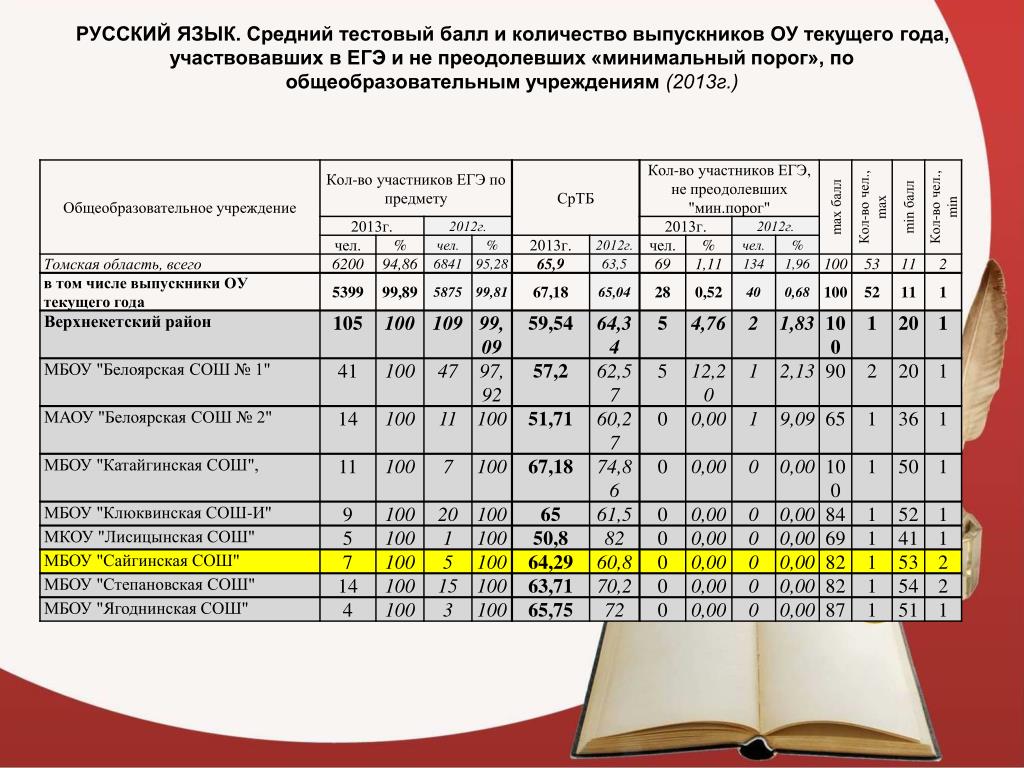
Средние значения и стандартные отклонения переменных, рассчитанные на основе внутрииндивидуальных распределений (слева) и межиндивидуальных распределений (справа)
Двумерные корреляции.
Образец 1.
Для сравнения относительных распределений внутрииндивидуальной ковариации и межиндивидуальной ковариации из выборки 1 были выбраны три двумерных корреляции: ( i ) депрессивное настроение и ангедония, ( ii ) депрессивное настроение и тревога и ( iii ) избегание деятельности и страх.Депрессивное настроение и ангедония являются основными симптомами БДР, и для постановки клинического диагноза необходим хотя бы один из двух симптомов. Беспокойство является основным симптомом ГТР, расстройства, которое чаще всего сочетается с БДР (35). Поведенческое избегание является общей чертой как настроения, так и симптоматики тревоги, обычно считается, что оно отрицательно подкрепляется временным уменьшением страха и тревоги, тем самым сохраняя симптомы в течение долгого времени (36).
Двумерные корреляции между тремя выбранными парами переменных были проведены на основе 78 наборов данных, полученных внутри отдельных лиц, и 78 наборов данных, полученных между отдельными лицами.На рис. 1 представлены гистограммы внутрииндивидуальных корреляций (красный) и межиндивидуальных корреляций (синий) с результатами, рассчитанными на основе необработанных данных (вверху) и остаточных данных AR (внизу). Сплошные линии отражают среднюю корреляцию, а пунктирные линии — медианную корреляцию. Средние внутрииндивидуальные корреляции (со стандартным отклонением в скобках) составили r = 0,47 (0,23), r = 0,40 (0,22) и r = 0,23 (0,23) для необработанных данных и r = 0,41 (0,22). ), r = 0.33 (0,21) и r = 0,19 (0,21) для остатков AR. Средние межиндивидуальные корреляции составили r = 0,75 (0,07), r = 0,71 (0,08) и r = 0,46 (0,11). Различия между внутриуровневыми и взаимодоступными корреляциями составляли R = 0,28, R = 0,31 и R = 0,22 для необработанных данных и R = 0,34, R = 0,38, а R = 0,27 для Остатки AR со средней разницей r = 0. 27 для необработанных данных и r = 0,33 для остаточных данных AR. Более того, во всех трех сравнениях индивидуальные стандартные отклонения были в 2,71 раза больше, чем межиндивидуальные стандартные отклонения для необработанных данных, и в 2,46 раза больше для остаточных данных AR. Эти результаты отражают значительно более широкий диапазон вариабельности внутрииндивидуальных оценок, независимо от поправки на временную зависимость.
27 для необработанных данных и r = 0,33 для остаточных данных AR. Более того, во всех трех сравнениях индивидуальные стандартные отклонения были в 2,71 раза больше, чем межиндивидуальные стандартные отклонения для необработанных данных, и в 2,46 раза больше для остаточных данных AR. Эти результаты отражают значительно более широкий диапазон вариабельности внутрииндивидуальных оценок, независимо от поправки на временную зависимость.
Гистограммы внутрииндивидуальных (красный) и межиндивидуальных (синий) корреляций для четырех двумерных отношений в выборке 1. Top отображает внутрииндивидуальные корреляции, рассчитанные на основе необработанных данных. Внизу показаны внутрииндивидуальные корреляции, рассчитанные на основе данных с удаленной временной зависимостью.
Образец 2.
Для образца 2 одно сравнение было рассчитано для двумерной корреляции между ЧСС и RSA, двумя наиболее распространенными переменными, используемыми в психофизиологических исследованиях (37).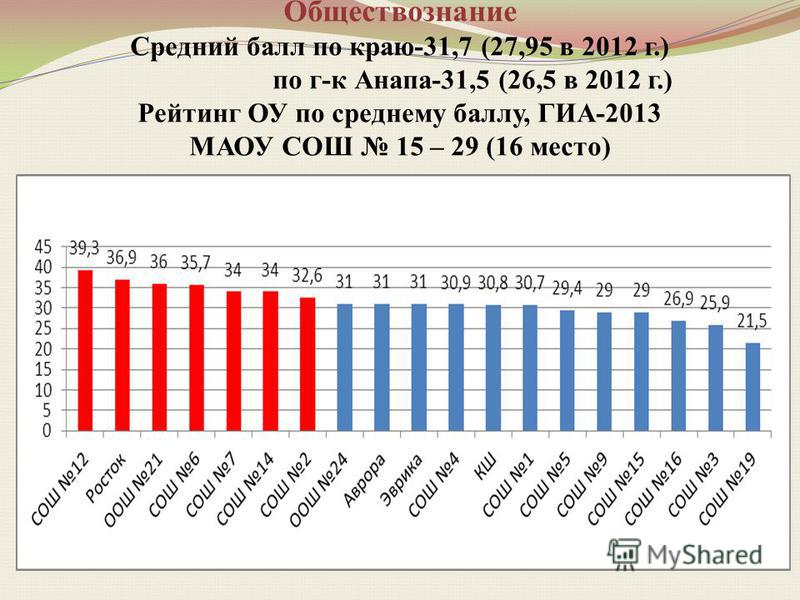 На рис. 2 представлены гистограммы внутрииндивидуальных (красный) и межиндивидуальных (синий) корреляций между HR и RSA, с внутрииндивидуальными оценками, полученными из необработанных данных слева, и внутрииндивидуальными оценками, полученными из остатков AR, справа.Средняя внутрииндивидуальная корреляция (и SD) для HR и RSA в выборке 2 составила r = -0,35 (0,22) для необработанных данных и r = -0,18 (0,13) для остаточных данных AR. Средняя межиндивидуальная корреляция составила r = -0,39 (0,08). Расхождение между средними значениями составило r = 0,04 для необработанных данных и r = 0,21 для остаточных данных AR. Следует отметить, что в то время как внутрииндивидуальное стандартное отклонение для необработанных данных было в 2,75 раза больше, чем межиндивидуальное стандартное отклонение, стандартное отклонение для остаточных данных AR составляло всего 1.в 63 раза больше, уменьшение магнитуды на 59%.
На рис. 2 представлены гистограммы внутрииндивидуальных (красный) и межиндивидуальных (синий) корреляций между HR и RSA, с внутрииндивидуальными оценками, полученными из необработанных данных слева, и внутрииндивидуальными оценками, полученными из остатков AR, справа.Средняя внутрииндивидуальная корреляция (и SD) для HR и RSA в выборке 2 составила r = -0,35 (0,22) для необработанных данных и r = -0,18 (0,13) для остаточных данных AR. Средняя межиндивидуальная корреляция составила r = -0,39 (0,08). Расхождение между средними значениями составило r = 0,04 для необработанных данных и r = 0,21 для остаточных данных AR. Следует отметить, что в то время как внутрииндивидуальное стандартное отклонение для необработанных данных было в 2,75 раза больше, чем межиндивидуальное стандартное отклонение, стандартное отклонение для остаточных данных AR составляло всего 1.в 63 раза больше, уменьшение магнитуды на 59%.
Гистограммы внутрииндивидуальных (красный) и межиндивидуальных (синий) корреляций для RSA и HR. Слева показаны внутрииндивидуальные корреляции, рассчитанные на основе необработанных данных. Справа показаны внутрииндивидуальные корреляции, рассчитанные на основе данных с удаленной временной зависимостью.
Слева показаны внутрииндивидуальные корреляции, рассчитанные на основе необработанных данных. Справа показаны внутрииндивидуальные корреляции, рассчитанные на основе данных с удаленной временной зависимостью.
Поскольку симметричный анализ исключил более 800 потенциальных случаев межиндивидуального сравнения, мы повторно провели межиндивидуальный анализ с размером выборки n = 900.Результаты были последовательными, со средней межиндивидуальной корреляцией r = -0,40 и SD 0,09.
Образцы 3, 4 и 5.
В соответствии с образцом 2 для образцов 3, 4 и 5 было выполнено одно сравнение. В каждом образце были представлены данные для PA и NA, хотя операционализация этих переменных отличалась в разных исследованиях ( Метод ). На рис. 3 представлены гистограммы внутрииндивидуальных (красный) и межиндивидуальных (синий) корреляций между ФА и NA для образцов 3, 4 и 5 (слева направо).На верхних панелях показаны сравнения, рассчитанные с использованием необработанных интраиндивидуальных данных, а на нижних панелях показаны сравнения, рассчитанные с использованием остаточных интраиндивидуальных данных AR.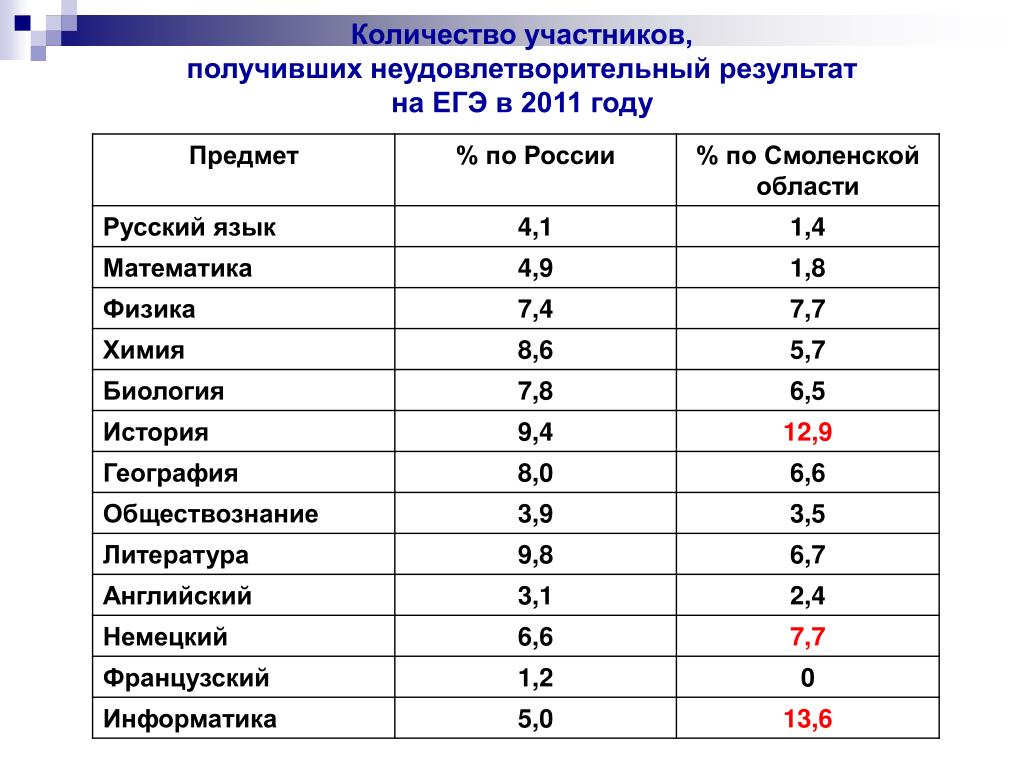 Средние внутрииндивидуальные корреляции для PA и NA в выборках 3, 4 и 5 составили r = 0,05 (0,23), r = -0,33 (0,28) и r = -0,58 (0,21) соответственно для необработанные данные и r = 0,04 (0,21), r = -0,31 (0,24) и r = -0,55 (0,19) соответственно для остаточных данных AR.Средние межиндивидуальные корреляции для выборки 3, 4 и 5 составили r = 0,01 (0,09), r = -0,26 (0,07) и r = -0,50 (0,09) соответственно. Расхождение между внутриуровневыми и взаимодоступными средними оценками составила всего г = 0,04, R = 0,07 и R = 0,08 и R = 0,08 для необработанных данных и R = 0,03, R = 0,05 и R = 0,05 для остаточных данных AR. Однако, как и в случае с образцом 1, внутрииндивидуальные стандартные отклонения для образцов 3–5 были значительно выше, чем межиндивидуальные стандартные отклонения, с соотношением 2.56:1, 4:1 и 2,33:1 для необработанных данных и 2,33:1, 3,42:1 и 2,11:1 для остаточных данных AR.
Средние внутрииндивидуальные корреляции для PA и NA в выборках 3, 4 и 5 составили r = 0,05 (0,23), r = -0,33 (0,28) и r = -0,58 (0,21) соответственно для необработанные данные и r = 0,04 (0,21), r = -0,31 (0,24) и r = -0,55 (0,19) соответственно для остаточных данных AR.Средние межиндивидуальные корреляции для выборки 3, 4 и 5 составили r = 0,01 (0,09), r = -0,26 (0,07) и r = -0,50 (0,09) соответственно. Расхождение между внутриуровневыми и взаимодоступными средними оценками составила всего г = 0,04, R = 0,07 и R = 0,08 и R = 0,08 для необработанных данных и R = 0,03, R = 0,05 и R = 0,05 для остаточных данных AR. Однако, как и в случае с образцом 1, внутрииндивидуальные стандартные отклонения для образцов 3–5 были значительно выше, чем межиндивидуальные стандартные отклонения, с соотношением 2.56:1, 4:1 и 2,33:1 для необработанных данных и 2,33:1, 3,42:1 и 2,11:1 для остаточных данных AR. Средние отношения SD в трех исследованиях составили 2,96:1 и 2,62:1 для необработанных и остаточных данных соответственно.
Средние отношения SD в трех исследованиях составили 2,96:1 и 2,62:1 для необработанных и остаточных данных соответственно.
Гистограммы внутрииндивидуальных (красный) и межиндивидуальных (синий) корреляций между положительным аффектом (PA) и негативным аффектом (NA) в выборках 3, 4 и 5. Top отображает внутрииндивидуальные корреляции, рассчитанные на основе необработанных данных. Внизу показаны внутрииндивидуальные корреляции, рассчитанные на основе данных с удаленной временной зависимостью.
Образец 6.
Наконец, для образца 6 мы рассчитали внутрииндивидуальные корреляции для двух операционализации PA и NA, низкого и высокого возбуждения, среди 535 участников. На рис. 4 представлены графики плотности для внутрииндивидуальных корреляций PA и NA при низком возбуждении (слева) и PA и NA при высоком возбуждении (справа). Верхние панели отображают сравнения, сделанные с необработанными данными, а нижние панели отображают сравнения, сделанные с остаточными данными AR.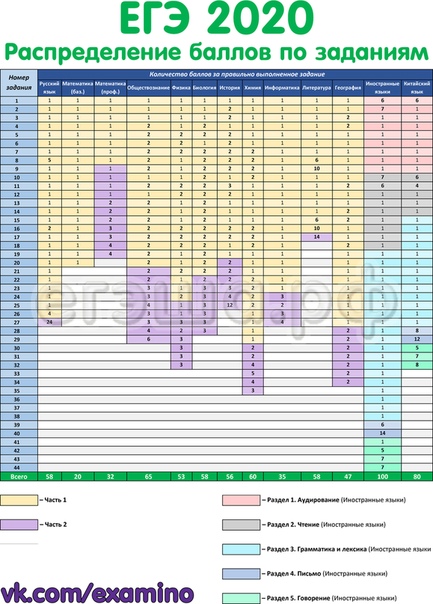 Графики плотности использовались из-за большого несоответствия между размером интраиндивидуальной выборки ( n = 535) и объемом индивидуальной выборки ( n = 85).Графики плотности отражают форму лежащих в основе гистограмм, независимо от масштаба измерения. Средняя внутрииндивидуальная корреляция (и SD) для PA и NA с низким уровнем возбуждения составила r = -0,46 (0,21) для необработанных данных и r = -0,42 (0,22) для остаточных данных AR. Средняя межиндивидуальная корреляция для слабой возбудимости PA и NA составила r = -0,66 (0,07). Расхождение между средними значениями составило r = 0,20 для необработанных данных и r = 0,24 для остаточных данных AR. Средняя внутрииндивидуальная корреляция (и SD) для PA и NA с высоким возбуждением составила r = -0.39 (0,22) для необработанных данных и r = -0,37 (0,22) для остаточных данных AR. Средняя межиндивидуальная корреляция для PA и NA с высоким возбуждением составила r = -0,43 (0,08).
Графики плотности использовались из-за большого несоответствия между размером интраиндивидуальной выборки ( n = 535) и объемом индивидуальной выборки ( n = 85).Графики плотности отражают форму лежащих в основе гистограмм, независимо от масштаба измерения. Средняя внутрииндивидуальная корреляция (и SD) для PA и NA с низким уровнем возбуждения составила r = -0,46 (0,21) для необработанных данных и r = -0,42 (0,22) для остаточных данных AR. Средняя межиндивидуальная корреляция для слабой возбудимости PA и NA составила r = -0,66 (0,07). Расхождение между средними значениями составило r = 0,20 для необработанных данных и r = 0,24 для остаточных данных AR. Средняя внутрииндивидуальная корреляция (и SD) для PA и NA с высоким возбуждением составила r = -0.39 (0,22) для необработанных данных и r = -0,37 (0,22) для остаточных данных AR. Средняя межиндивидуальная корреляция для PA и NA с высоким возбуждением составила r = -0,43 (0,08).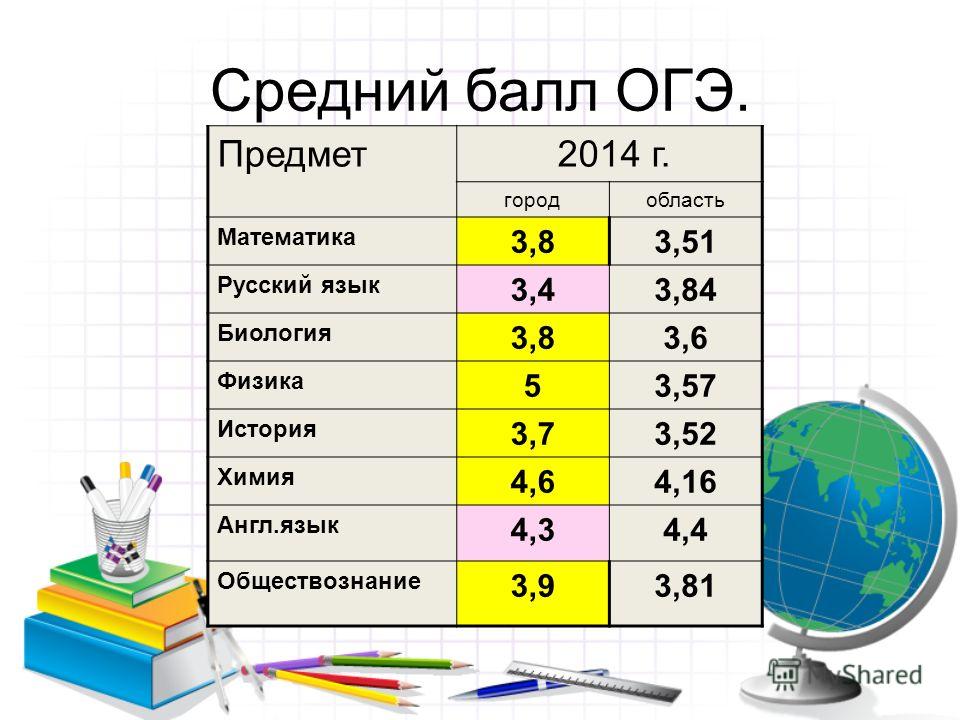 Расхождение между средними значениями составило r = 0,04 для необработанных данных и r = 0,06 для остаточных данных AR. Отношение внутрииндивидуального SD к межиндивидуальному SD составляло 3:1 для исходных данных и 2,75:1 для остаточных данных AR.
Расхождение между средними значениями составило r = 0,04 для необработанных данных и r = 0,06 для остаточных данных AR. Отношение внутрииндивидуального SD к межиндивидуальному SD составляло 3:1 для исходных данных и 2,75:1 для остаточных данных AR.
Графики плотности распределения корреляций в образце 6 между положительным аффектом (PA) и отрицательным аффектом (NA) при низком возбуждении ( слева ) и PA и NA при высоком возбуждении ( справа ).Красным цветом показаны распределения, относящиеся к 535 отдельным респондентам. Синим цветом показаны распределения 85 наборов данных сравнения поперечных сечений. Индивидуальные корреляции рассчитывались на основе необработанных данных ( Top ) и данных с удаленной временной зависимостью ( Bottom ).
Обсуждение
В настоящем исследовании мы провели сравнение внутрииндивидуальных и межиндивидуальных вариаций в шести независимых выборках из США и Нидерландов. Используя интенсивные данные повторных измерений, мы сравнили относительное распределение индивидуальных и групповых корреляций по ряду конструкций и парадигм сбора данных, используя как необработанные данные, так и данные, остаточные по сравнению с авторегрессией первого порядка. Одномерные распределения выявили относительно согласованные средние оценки. Однако соотношение внутрииндивидуальных и межиндивидуальных СО колебалось от 3,79 до 13,20, причем первые в среднем в 7,85 раза превышали вторые. Что касается ожидаемых значений распределений двумерных корреляций, мы обнаружили двусмысленные результаты — те, к которым применялась и не применялась межгрупповая обобщаемость.То есть мы нашли свидетельство совпадения центральной тенденции четырех из девяти сравнений и расхождения в остальных пяти сравнениях. В частности, наблюдалось довольно сильное совпадение ожидаемых значений корреляции между PA и NA, операционализированных образцами 3, 4 и 5. В связи с этим операционализация PA и NA с высоким уровнем возбуждения в образце 6 продемонстрировала довольно сильную согласованность.
Используя интенсивные данные повторных измерений, мы сравнили относительное распределение индивидуальных и групповых корреляций по ряду конструкций и парадигм сбора данных, используя как необработанные данные, так и данные, остаточные по сравнению с авторегрессией первого порядка. Одномерные распределения выявили относительно согласованные средние оценки. Однако соотношение внутрииндивидуальных и межиндивидуальных СО колебалось от 3,79 до 13,20, причем первые в среднем в 7,85 раза превышали вторые. Что касается ожидаемых значений распределений двумерных корреляций, мы обнаружили двусмысленные результаты — те, к которым применялась и не применялась межгрупповая обобщаемость.То есть мы нашли свидетельство совпадения центральной тенденции четырех из девяти сравнений и расхождения в остальных пяти сравнениях. В частности, наблюдалось довольно сильное совпадение ожидаемых значений корреляции между PA и NA, операционализированных образцами 3, 4 и 5. В связи с этим операционализация PA и NA с высоким уровнем возбуждения в образце 6 продемонстрировала довольно сильную согласованность. внутрииндивидуальной и межиндивидуальной изменчивости. Среднее расхождение между внутрииндивидуальными и межиндивидуальными оценками составило r = 0.06 для необработанных данных и 0,04 для остаточных данных AR.
внутрииндивидуальной и межиндивидуальной изменчивости. Среднее расхождение между внутрииндивидуальными и межиндивидуальными оценками составило r = 0.06 для необработанных данных и 0,04 для остаточных данных AR.
Однако, что касается дисперсии вокруг ожидаемого значения, во всех шести выборках и во всех девяти сравнениях внутрииндивидуальная ковариация продемонстрировала разброс, который варьировался от 2,09 до 4 раз больше, чем наблюдаемый для межиндивидуальных оценок при расчете по необработанным данным (среднее отношение 2,84). :1) и диапазон в 1,63–3,43 раза больше при расчете по остаточным данным AR (среднее соотношение 2,56:1). То есть стандартное отклонение корреляций для отдельных лиц было в среднем почти в три раза выше, чем для групп в исходных данных, и более чем в два с половиной раза больше в остаточных данных.Таким образом, в то время как была обнаружена сомнительная поддержка групповой и индивидуальной обобщаемости средних оценок, текущее исследование не обнаружило поддержки эргодического соответствия между дисперсиями, связанными с внутрииндивидуальными и межиндивидуальными статистическими оценками.
Из этих открытий можно сделать два важных вывода: ( i ) тот факт, что мы наблюдаем существенное численное расхождение между индивидуальными и групповыми оценками, и ( ii ) последствия обобщения групповых данных на индивидуумов.Первый вывод говорит сам за себя, но его стоит подчеркнуть: агрегированные оценки не всегда согласуются с индивидуальными оценками. В то время как в предыдущей работе отмечалась неправдоподобность эргодичности в исследованиях на людях, включая предоставление математических доказательств (1), настоящее исследование обеспечивает эмпирическую демонстрацию этого эффекта в различных условиях и конструкциях. Что касается обобщаемости агрегированных оценок, настоящие результаты показывают, что корреляции между переменными внутри отдельных людей демонстрируют как минимум в два раза большую изменчивость, чем корреляции внутри групп.Настоящие результаты показывают, что в лучшем случае групповые оценки можно считать ожидаемыми значениями для нормально распределенных оценок, таких как корреляции, сопровождаемых значительно большей изменчивостью, чем групповое стандартное отклонение. То есть даже в лучшем случае мы не должны думать о корреляции в групповых данных как об оценке, которая обобщается для любого конкретного индивидуума в популяции. Говоря прямо, это означает, что искушение использовать агрегированные оценки для выводов об основной единице социальной и психологической организации — личности — гораздо менее точно или обоснованно, чем это может показаться в литературе.Действительно, даже самый лучший сценарий вызывает тревогу: только 68% всех индивидуальных корреляционных значений попадают в диапазон, который, по прогнозам групповых данных, покрывает 99,7% всех возможных корреляций — расхождение почти 32%.
То есть даже в лучшем случае мы не должны думать о корреляции в групповых данных как об оценке, которая обобщается для любого конкретного индивидуума в популяции. Говоря прямо, это означает, что искушение использовать агрегированные оценки для выводов об основной единице социальной и психологической организации — личности — гораздо менее точно или обоснованно, чем это может показаться в литературе.Действительно, даже самый лучший сценарий вызывает тревогу: только 68% всех индивидуальных корреляционных значений попадают в диапазон, который, по прогнозам групповых данных, покрывает 99,7% всех возможных корреляций — расхождение почти 32%.
Наихудший сценарий явно ужасен: вполне вероятно, что невнимание к неэргодичности и отсутствие групповой и индивидуальной обобщаемости угрожают достоверности бесчисленных исследований, заключений и рекомендаций передового опыта. Как показывают наши результаты всего в нескольких исследованиях, природа угрозы различается по степени и виду в зависимости от областей исследования и методов измерения. Например, расхождения в выборке 1 касаются оценки, классификации и лечения психических синдромов. Золотой стандарт лечения фобического избегания основан на предположении, что смягчение поведения избегания посредством воздействия — облегчение повторного контакта между человеком и раздражителем, которого боятся, — со временем уменьшит переживание страха. Однако наши результаты показывают, что в среднем сила связи между страхом и избеганием слабее, чем можно было бы предположить в групповых оценках, и что для некоторых людей между этими явлениями вообще нет никакой связи.Таким образом, крайне важно проверить, представляют ли люди, не имеющие отношения, особый естественный вид, который не поддается лечению.
Например, расхождения в выборке 1 касаются оценки, классификации и лечения психических синдромов. Золотой стандарт лечения фобического избегания основан на предположении, что смягчение поведения избегания посредством воздействия — облегчение повторного контакта между человеком и раздражителем, которого боятся, — со временем уменьшит переживание страха. Однако наши результаты показывают, что в среднем сила связи между страхом и избеганием слабее, чем можно было бы предположить в групповых оценках, и что для некоторых людей между этими явлениями вообще нет никакой связи.Таким образом, крайне важно проверить, представляют ли люди, не имеющие отношения, особый естественный вид, который не поддается лечению.
Точно так же сильная положительная ковариация между депрессивным настроением и тревогой воспроизводилась настолько постоянно, что некоторые утверждали, что их соответствующие клинические диагнозы — ГТР и БДР — должны принадлежать к одному и тому же классу психических расстройств (38). В соответствии с этим ожидаемое значение групповой корреляции между беспокойством и депрессивным настроением составило r = 0.71. Однако ожидаемое значение корреляции между этими конструктами у индивидуумов было на 44% ниже в необработанных данных ( r = 0,40), на 55% ниже в остаточных данных AR ( r = 0,32) и продемонстрировало общее варьируются от r = -0,11 до r = 0,89, что позволяет предположить, что предполагаемая ковариация между этими синдромами в существующей литературе может недооценивать значительную изменчивость отношений между людьми. Таким образом, таксономические решения, основанные на предполагаемой групповой корреляции между этими параметрами, скорее всего, будут лишены экологической и клинической обоснованности и могут подорвать планирование лечения и его результаты.Эти результаты также предполагают, что наши таксономии вряд ли охватят разнообразие естественных видов, которые могут существовать среди людей.
В соответствии с этим ожидаемое значение групповой корреляции между беспокойством и депрессивным настроением составило r = 0.71. Однако ожидаемое значение корреляции между этими конструктами у индивидуумов было на 44% ниже в необработанных данных ( r = 0,40), на 55% ниже в остаточных данных AR ( r = 0,32) и продемонстрировало общее варьируются от r = -0,11 до r = 0,89, что позволяет предположить, что предполагаемая ковариация между этими синдромами в существующей литературе может недооценивать значительную изменчивость отношений между людьми. Таким образом, таксономические решения, основанные на предполагаемой групповой корреляции между этими параметрами, скорее всего, будут лишены экологической и клинической обоснованности и могут подорвать планирование лечения и его результаты.Эти результаты также предполагают, что наши таксономии вряд ли охватят разнообразие естественных видов, которые могут существовать среди людей.
Взятые вместе, мы считаем, что результаты настоящего исследования указывают на континуум сценариев для выявления неэргодичности путем изучения согласованности между групповыми и индивидуальными корреляциями и степени, в которой выводы из одной области могут быть обобщены на другую. Оформляя такие тесты в рамках эргодической теоремы, которая устанавливает строгие и неукоснительные условия для обобщений между уровнями анализа, мы можем решать основные вопросы биопсихосоциальных исследований.Текущие данные еще больше подтверждают опасность экологической ошибки, эмпирически демонстрируя, что групповые оценки не следует считать точными показателями индивидуальных процессов. Что касается парадокса Симпсона — агрегации могут искажать подгруппы или отдельных лиц — настоящее исследование согласуется с рекомендацией Kievit et al. (39), которые подчеркнули, что данные должны быть явно проверены на согласованность оценок на разных уровнях анализа.
Оформляя такие тесты в рамках эргодической теоремы, которая устанавливает строгие и неукоснительные условия для обобщений между уровнями анализа, мы можем решать основные вопросы биопсихосоциальных исследований.Текущие данные еще больше подтверждают опасность экологической ошибки, эмпирически демонстрируя, что групповые оценки не следует считать точными показателями индивидуальных процессов. Что касается парадокса Симпсона — агрегации могут искажать подгруппы или отдельных лиц — настоящее исследование согласуется с рекомендацией Kievit et al. (39), которые подчеркнули, что данные должны быть явно проверены на согласованность оценок на разных уровнях анализа.
Важно отметить, что визуальный осмотр распределений корреляций для внутрииндивидуальных и межиндивидуальных данных показал, что последние, по-видимому, лучше приближаются к нормальности, чем первые.Таким образом, тесты, предполагающие нормальность, могут быть более подходящими для анализа между субъектами, чем для анализа внутри субъектов, а стандартная ошибка среднего может быть более подходящей мерой межиндивидуальной изменчивости. Более того, в дополнение к несоответствиям в межиндивидуальных и внутрииндивидуальных статистических моментах, неэргодичность в естественных науках также может быть обусловлена вариациями временных зависимостей между индивидуумами в выборке. Хотя наши текущие результаты подтверждают необходимость более тщательного рассмотрения неэргодичности в целом, они остаются в силе независимо от того, учитываются ли явным образом временные зависимости ( SI Приложение ).Однако наличие этой вариации в реальных данных может послужить дополнительным стимулом для тщательного изучения изменчивости на индивидуальном уровне, прежде чем делать выводы на основе группы.
Более того, в дополнение к несоответствиям в межиндивидуальных и внутрииндивидуальных статистических моментах, неэргодичность в естественных науках также может быть обусловлена вариациями временных зависимостей между индивидуумами в выборке. Хотя наши текущие результаты подтверждают необходимость более тщательного рассмотрения неэргодичности в целом, они остаются в силе независимо от того, учитываются ли явным образом временные зависимости ( SI Приложение ).Однако наличие этой вариации в реальных данных может послужить дополнительным стимулом для тщательного изучения изменчивости на индивидуальном уровне, прежде чем делать выводы на основе группы.
Одним из возможных ограничений настоящего исследования является то, что для некоторых источников данных мы сосредоточились на подвыборках данных, чтобы соответствовать относительной шкале поперечных и индивидуальных измерений. Хотя это было сделано, чтобы уменьшить погрешность при сравнении групповых и индивидуальных данных, важно отметить, что небольшие размеры выборки могут снизить согласованность между индивидуальными и групповыми данными, поскольку небольшие пакеты данных могут не отражать большую совокупность наблюдений (40). Явное использование моделей, которые применяются к большим выборкам, учитывают вариации во времени и моделируют влияние ковариат, может помочь отделить проблемы, связанные с неэргодичностью, от проблем, связанных с немоделируемыми вариациями из других источников. Наши результаты показывают, что исследователям, собирающим перекрестные данные, может быть целесообразно собирать подвыборки внутрисубъектных данных для проверки потенциальной неэргодичности. Кроме того, может оказаться важным применять процедуры группировки, если наблюдаются категорически разные типы внутрииндивидуальной изменчивости, облегчающие научные открытия и более подходящие заявления об обобщении.
Явное использование моделей, которые применяются к большим выборкам, учитывают вариации во времени и моделируют влияние ковариат, может помочь отделить проблемы, связанные с неэргодичностью, от проблем, связанных с немоделируемыми вариациями из других источников. Наши результаты показывают, что исследователям, собирающим перекрестные данные, может быть целесообразно собирать подвыборки внутрисубъектных данных для проверки потенциальной неэргодичности. Кроме того, может оказаться важным применять процедуры группировки, если наблюдаются категорически разные типы внутрииндивидуальной изменчивости, облегчающие научные открытия и более подходящие заявления об обобщении.
Важно отметить, что мы можем использовать другие подходы для рассмотрения внутриличностных и межличностных вариаций, чтобы поддержать выводы, которые более репрезентативны для внутрииндивидуальных вариаций, где может наблюдаться неэргодичность. Здесь мы сосредоточились на простых подходах, которые измеряют свойства дисперсии и ковариации, которые, в свою очередь, могут поддерживать более сложные методы анализа данных. Существует множество более сложных инструментов для изучения моделей компонентов дисперсии (41, 42), многоуровневых моделей (43), одновременных и запаздывающих моделей структурных уравнений (44) и временных рядов в более общем плане (45).Наши результаты показывают, что точно так же, как простые измерения могут демонстрировать значительные различия в вариациях внутри и между субъектами, как вариации внутри, так и между субъектами должны быть явно смоделированы при любом подходе, и все модели должны оцениваться с точки зрения того, как хорошо, они представляют процессы на индивидуальном уровне, прежде чем делать обобщения из совокупных оценок.
Существует множество более сложных инструментов для изучения моделей компонентов дисперсии (41, 42), многоуровневых моделей (43), одновременных и запаздывающих моделей структурных уравнений (44) и временных рядов в более общем плане (45).Наши результаты показывают, что точно так же, как простые измерения могут демонстрировать значительные различия в вариациях внутри и между субъектами, как вариации внутри, так и между субъектами должны быть явно смоделированы при любом подходе, и все модели должны оцениваться с точки зрения того, как хорошо, они представляют процессы на индивидуальном уровне, прежде чем делать обобщения из совокупных оценок.
В заключение, с усилением акцента на так называемый «кризис репликации» (46) и признанием того, что структуры стимулов могут привести к вредным научным практикам (47), настоящая статья добавляет голос в хор ученых, призывающих для повышения прозрачности и подотчетности.Вполне возможно, что акцент на открытых данных поможет нам обнаружить и охарактеризовать примеры неэргодичности в науках о жизни в целом.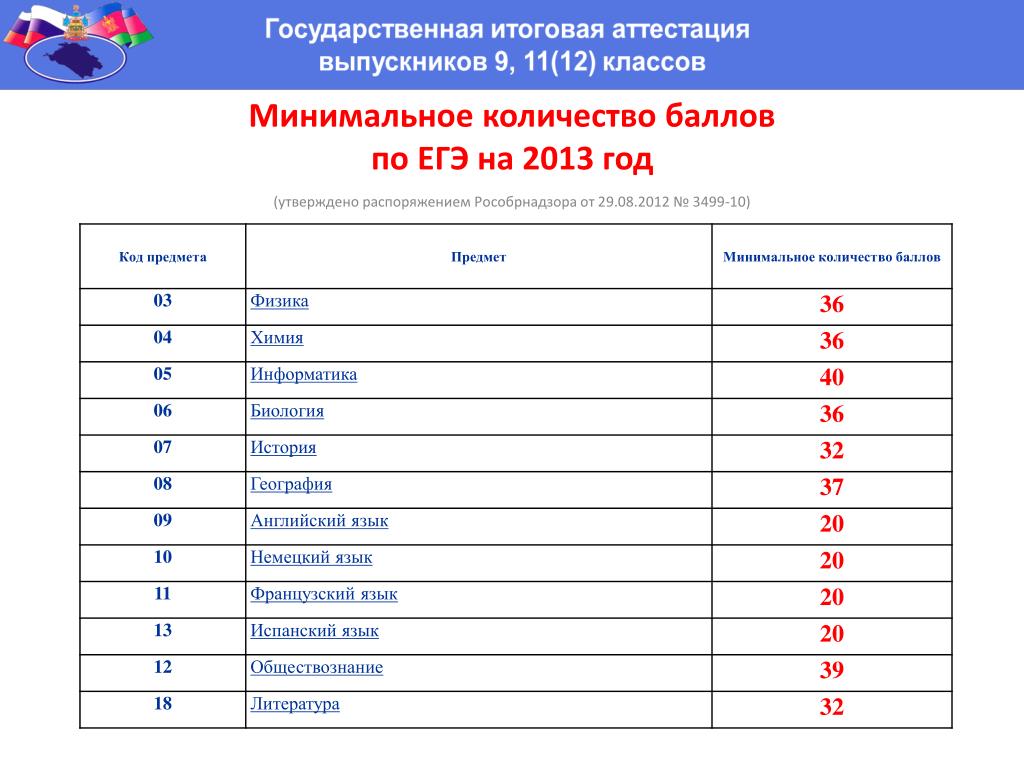 Например, работа с открытыми данными привела к увеличению взаимодействия исследователей и открытых дискуссий о воспроизводимости и достоверности в сравнительной биоинформатике (40), прогнозировании рака молочной железы (48) и масштабных вычислительных экспериментах (49). По крайней мере, доступ к открытым данным позволит исследователям изучить, в какой степени ранее опубликованные результаты могут демонстрировать различную степень неэргодичности.
Например, работа с открытыми данными привела к увеличению взаимодействия исследователей и открытых дискуссий о воспроизводимости и достоверности в сравнительной биоинформатике (40), прогнозировании рака молочной железы (48) и масштабных вычислительных экспериментах (49). По крайней мере, доступ к открытым данным позволит исследователям изучить, в какой степени ранее опубликованные результаты могут демонстрировать различную степень неэргодичности.
Наше внимание к действительно фундаментальной, но редко рассматриваемой дилемме в исследованиях на людях выдвигает на первый план вопросы научной точности и обобщаемости. Даже если стимулы будут скорректированы, наша способность делать обоснованные выводы на индивидуальном уровне потребует значительных усилий в личностно-ориентированной науке. Обнадеживает тот факт, что с увеличением числа общедоступных крупноразмерных наборов данных мы можем не только начать количественно определять, насколько всепроникающей может быть неэргодическая угроза, мы можем начать расширять наши науки, чтобы количественно определять и формулировать как внутрииндивидуальные, так и межиндивидуальные различия, и, таким образом, создавать модели физиологии и поведения человека, которые улучшают качество и точность статистических выводов по уровням и единицам анализа.
Благодарности
Мы благодарим всех участников шести исследований за их участие и ценный вклад в этот исследовательский проект. Стивен Хиншоу и Родольфо Мендоза-Дентон выражают благодарность за комментарии к более ранним черновикам этой рукописи. Мы благодарны Steven Woodward, Aidan Wright, Nicole Geschwind, Evelien Snippe, Nancy Nicolson, Marieke Wichers и Daniela Barge-Schaapveld за обмен данными и помощь в подготовке данных. Дж.Д.М. признает поддержку со стороны Управления директора и Национального института психического здоровья при Национальных институтах здравоохранения (1-DP5-OD021352).
Сноски
-
Вклад авторов: A.J.F. проектное исследование; А.Дж.Ф. проведенное исследование; А.Дж.Ф. проанализированные данные; и A.J.F., J.D.M. и B.F.J. написал бумагу.
-
Авторы заявляют об отсутствии конфликта интересов.
-
Эта статья является прямой отправкой PNAS.
-
Эта статья содержит вспомогательную информацию в Интернете по адресу www.
pnas.org/lookup/suppl/doi:10.1073/pnas.1711978115/-/DCSupplemental.
Глобальный набор данных о качестве образования (1965-2015 гг.)
Abstract
В данной статье представлены крупнейшие в мире сопоставимая панельная база данных качества образования.База данных включает 163 страны и региона за 1965-2015 гг. То глобально сопоставимые результаты достижений были построены с помощью связывая стандартизированные, психометрически надежные международные и региональные тесты достижений. Бумага способствует литературы следующими способами: (1) это самый большой и самый последний глобально сопоставимый набор данных, охватывающий более более 90 процентов населения мира; (2) набор данных включает в себя 100 развивающихся направлений и наиболее развивающихся страны, включенные в такой набор данных на сегодняшний день — страны, которые больше всего выиграют от потенциального преимущества качественного образования; (3) набор данных содержит достоверные показатели глобально сопоставимых распределение достижений, а также средние баллы; (4) набор данных использует несколько методов для увязки оценок, включая средние и процентильные методы связывания, таким образом повышение надежности набора данных; (5) набор данных включает стандартные ошибки для оценок, что позволяет явная количественная оценка степени надежности каждого оценивать; и (6) набор данных может быть дезагрегирован по пол, социально-экономический статус, проживание в сельской/городской местности, язык и иммиграционный статус, что позволяет более точно и анализ капитала. Первый анализ набора данных показывает
несколько важных тенденций: результаты обучения в развитии
страны часто группируются в нижней части глобального
шкала; хотя различия в производительности высоки в
развивающихся странах лучшие исполнители по-прежнему часто выступают
хуже, чем худшие показатели в развитых странах;
гендерные разрывы относительно невелики, с высокой вариабельностью
направление зазора; и распределения раскрывают содержательно
тенденции, отличные от средних показателей, с менее чем 50 процентами
учащихся, достигших глобального минимального порога
знание в развивающихся странах относительно 86 процентов
в развитых странах.Газета также находит положительные и
существенная связь между образовательными достижениями и
экономический рост. Набор данных можно использовать для сравнения
глобального прогресса в области качества образования, а также выявить
потенциальных драйверов качества образования, роста и развития.
Первый анализ набора данных показывает
несколько важных тенденций: результаты обучения в развитии
страны часто группируются в нижней части глобального
шкала; хотя различия в производительности высоки в
развивающихся странах лучшие исполнители по-прежнему часто выступают
хуже, чем худшие показатели в развитых странах;
гендерные разрывы относительно невелики, с высокой вариабельностью
направление зазора; и распределения раскрывают содержательно
тенденции, отличные от средних показателей, с менее чем 50 процентами
учащихся, достигших глобального минимального порога
знание в развивающихся странах относительно 86 процентов
в развитых странах.Газета также находит положительные и
существенная связь между образовательными достижениями и
экономический рост. Набор данных можно использовать для сравнения
глобального прогресса в области качества образования, а также выявить
потенциальных драйверов качества образования, роста и развития.
Цитата
«Алтинок, Надир; Ангрист, Ноам; Патринос, Гарри Энтони. 2018. Глобальный набор данных о качестве образования (1965–2015 гг.). Рабочий документ по исследованию политики; No.8314. Всемирный банк, Вашингтон, округ Колумбия. © Всемирный банк. https://openknowledge.worldbank.org/handle/10986/29281 Лицензия: CC BY 3.0 IGO».
5 Воспроизводимость | Воспроизводимость и воспроизводимость в науке
случаев, получивших широкую огласку, тот факт, что он одинаково вреден для науки, означает, что он заслуживает внимания в рамках этого исследования.
Исследователи, сознательно использующие сомнительные исследовательские методы с намерением ввести в заблуждение, совершают неправомерные действия или мошенничество. На практике может быть трудно провести различие между добросовестными ошибками и преднамеренным неправомерным поведением, потому что основное действие может быть одним и тем же, а намерение — другим.
Воспроизводимость и воспроизводимость стали общими проблемами в науке примерно в то же время, когда возобновилось внимание к неправомерным действиям и пагубным исследовательским методам. Интерес как к воспроизводимости, так и к воспроизводимости, а также к неправомерным действиям был вызван некоторыми из тех же тенденций и небольшим количеством широко освещаемых случаев, когда обнаружение сфабрикованных или фальсифицированных данных задерживалось, а практика журналов, исследовательских институтов и отдельных лабораторий была нарушена. причастны к возникновению таких задержек (Национальные академии наук, инженерии и медицины, 2017; Levelt Committee et al., 2012).
Интерес как к воспроизводимости, так и к воспроизводимости, а также к неправомерным действиям был вызван некоторыми из тех же тенденций и небольшим количеством широко освещаемых случаев, когда обнаружение сфабрикованных или фальсифицированных данных задерживалось, а практика журналов, исследовательских институтов и отдельных лабораторий была нарушена. причастны к возникновению таких задержек (Национальные академии наук, инженерии и медицины, 2017; Levelt Committee et al., 2012).
В случае с Анилом Потти из Университета Дьюка позже было обнаружено, что исследователь, проводивший геномный анализ больных раком, фальсифицировал данные. Этот опыт послужил поводом для исследования и отчета «Эволюция трансляционных омиков: извлеченные уроки и путь вперед » (Институт медицины, 2012 г.), что, в свою очередь, привело к новым рекомендациям по исследованиям омиков в Национальном институте рака. Примерно в то же время в Нидерландах стал известен случай, когда социальный психолог Дидерик Стапель перешел от манипулирования к фабрикации данных в течение своей карьеры с десятками мошеннических публикаций. Точно так же получившие широкую огласку опасения по поводу неправомерных действий профессора Корнельского университета Брайана Вансинка подчеркивают, как постоянное несоблюдение передовых методов сбора, анализа и представления данных — преднамеренное или нет — может стереть грань между полезными и бесполезными источниками неповторяемости. В этом случае комитет факультета Корнелла приписал Вансинку: «академические проступки в его исследованиях и стипендиях, включая искажение данных исследований, проблематичные статистические методы, неспособность должным образом документировать и сохранить результаты исследований и ненадлежащее авторство. 12
Точно так же получившие широкую огласку опасения по поводу неправомерных действий профессора Корнельского университета Брайана Вансинка подчеркивают, как постоянное несоблюдение передовых методов сбора, анализа и представления данных — преднамеренное или нет — может стереть грань между полезными и бесполезными источниками неповторяемости. В этом случае комитет факультета Корнелла приписал Вансинку: «академические проступки в его исследованиях и стипендиях, включая искажение данных исследований, проблематичные статистические методы, неспособность должным образом документировать и сохранить результаты исследований и ненадлежащее авторство. 12
В этом контексте появился последующий отчет «Содействие честности в исследованиях » (Национальные академии наук, инженерии и медицины, 2017 г.), и некоторые из его центральных тем имеют отношение к вопросам, поставленным в этом отчете.
В соответствии с определением, принятым федеральным правительством США в 2000 г. , неправомерным проведением исследований является фабрикация данных, фальсификация данных или плагиат «при предложении, проведении или обзоре исследований или при сообщении результатов исследований» (Управление по научно-технической политике , 2000, с.76262). Федеральная политика требует, чтобы научно-исследовательские учреждения сообщали обо всех
, неправомерным проведением исследований является фабрикация данных, фальсификация данных или плагиат «при предложении, проведении или обзоре исследований или при сообщении результатов исследований» (Управление по научно-технической политике , 2000, с.76262). Федеральная политика требует, чтобы научно-исследовательские учреждения сообщали обо всех
___________________
12 См. http://statements.cornell.edu/2018/20180920-statement-provost-michael-kotlikoff.cfm.
Проблема ложного срабатывания автоматического обнаружения ботов в социальных исследованиях
Abstract
Идентификация ботов — важная и сложная задача. Классификатор ботов «Ботометр» был успешно введен как способ оценки количества ботов в заданном списке учетных записей и, как следствие, часто использовался в академических публикациях.Учитывая его актуальность для академических исследований и наше понимание присутствия автоматизированных учетных записей в любом конкретном дискурсе Twitter, нас интересует диагностическая способность ботометра с течением времени. Для этого мы собрали оценок Botometer для пяти наборов данных (три подтверждены как боты, два подтверждены как люди; n = 4134) на двух языках (английский/немецкий) в течение трех месяцев. Мы показываем, что оценки ботометра неточны, когда дело доходит до оценки ботов; особенно на другом языке.Кроме того, при анализе результатов ботометров с течением времени мы показываем, что пороги ботометров , даже при очень консервативном использовании, склонны к дисперсии, что, в свою очередь, приведет к ложноотрицательным результатам (т. е. боты будут классифицироваться как люди). ) и ложные срабатывания (например, люди классифицируются как боты). Это имеет непосредственные последствия для академических исследований, поскольку в большинстве исследований в области социальных наук с использованием этого инструмента большое количество пользователей по незнанию будет считаться ботами, и наоборот.Мы завершаем наше исследование обсуждением того, как социологи-вычислители должны оценивать системы машинного обучения, разработанные для выявления ботов.
Для этого мы собрали оценок Botometer для пяти наборов данных (три подтверждены как боты, два подтверждены как люди; n = 4134) на двух языках (английский/немецкий) в течение трех месяцев. Мы показываем, что оценки ботометра неточны, когда дело доходит до оценки ботов; особенно на другом языке.Кроме того, при анализе результатов ботометров с течением времени мы показываем, что пороги ботометров , даже при очень консервативном использовании, склонны к дисперсии, что, в свою очередь, приведет к ложноотрицательным результатам (т. е. боты будут классифицироваться как люди). ) и ложные срабатывания (например, люди классифицируются как боты). Это имеет непосредственные последствия для академических исследований, поскольку в большинстве исследований в области социальных наук с использованием этого инструмента большое количество пользователей по незнанию будет считаться ботами, и наоборот.Мы завершаем наше исследование обсуждением того, как социологи-вычислители должны оценивать системы машинного обучения, разработанные для выявления ботов.
Образец цитирования: Rauchfleisch A, Kaiser J (2020) Проблема ложного срабатывания автоматического обнаружения ботов в социальных исследованиях. ПЛОС ОДИН 15(10): е0241045. https://doi.org/10.1371/journal.pone.0241045
Редактор: Фабиана Золло, Венецианский университет Ка’ Фоскари, ИТАЛИЯ
Поступила в редакцию: 14 апреля 2020 г .; Принято: 7 октября 2020 г .; Опубликовано: 22 октября 2020 г.
Авторское право: © 2020 Rauchfleisch, Kaiser.Это статья с открытым доступом, распространяемая в соответствии с условиями лицензии Creative Commons Attribution License, которая разрешает неограниченное использование, распространение и воспроизведение на любом носителе при условии указания автора и источника.
Доступность данных: Данные, лежащие в основе этого исследования, можно загрузить с Harvard Dataverse, V3 (https://doi.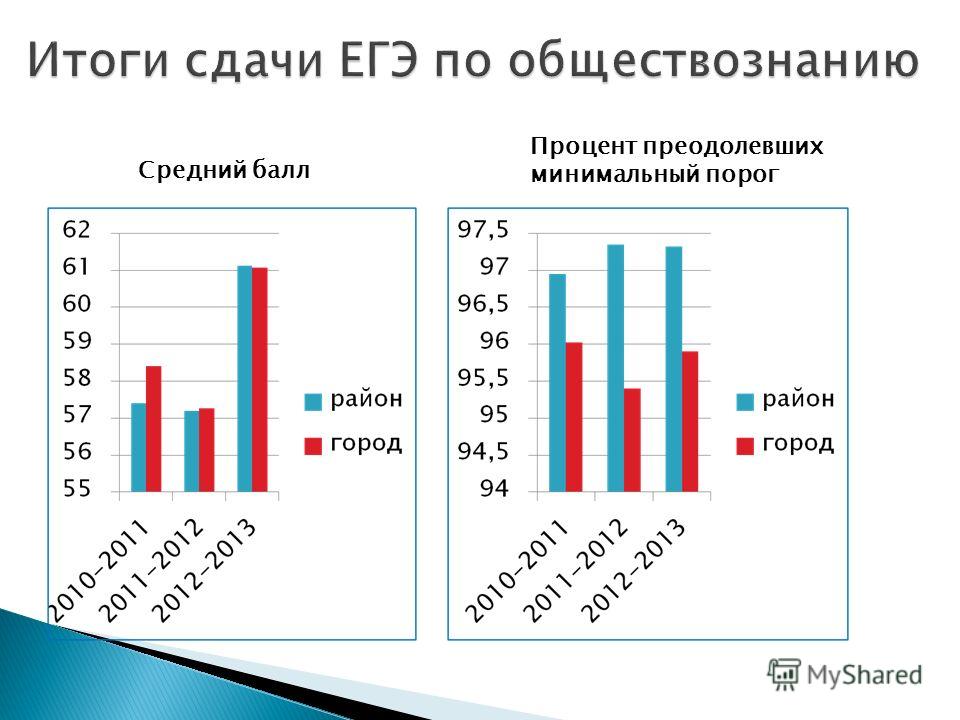 org/10.7910/DVN/XVCKRS).
org/10.7910/DVN/XVCKRS).
Финансирование: Эта работа была поддержана Министерством науки и технологий Тайваня (Р.O.C) (Грант № 108-2410-H-002-007-MY2). Спонсоры не участвовали в разработке исследования, сборе и анализе данных, принятии решения о публикации или подготовке рукописи.
Конкурирующие интересы: Авторы заявили об отсутствии конкурирующих интересов.
Введение
Выявление ботов (здесь это означает полностью автоматизированные учетные записи) на платформах социальных сетей, таких как Twitter, — задача столь же важная, сколь и сложная. Действительно, возможность оценить подлинность рассуждений в Твиттере путем обнаружения вредоносных ботнетов или определения количества «настоящих» (т.е. людей) последователей, которых имеет политик, является важной отправной точкой для компьютерных социологов. Это актуально не только в контексте политической коммуникации, но особенно когда речь идет об обнаружении дезинформационных кампаний и усилении безопасности платформы. Следовательно, для решения этой проблемы было введено несколько методов, в том числе общий фильтр активности [1], анализ шаблонов публикации [2], а также классификаторы на основе машинного обучения [3]. Особенно хорошо зарекомендовал себя в социальных науках обученный классификатор Botometer [3, 4] для оценки количества ботов в заданном наборе данных.
Следовательно, для решения этой проблемы было введено несколько методов, в том числе общий фильтр активности [1], анализ шаблонов публикации [2], а также классификаторы на основе машинного обучения [3]. Особенно хорошо зарекомендовал себя в социальных науках обученный классификатор Botometer [3, 4] для оценки количества ботов в заданном наборе данных.
Например, в апреле 2018 года исследовательский центр Pew Research Center опубликовал крупномасштабное исследование, посвященное анализу твитов со ссылками на популярные веб-сайты, и обнаружил, что две трети проанализированных твитов публикуются автоматическими учетными записями [5]. Другое исследование Бесси и Феррары [6] показало, что 19% твитов, опубликованных во время президентских выборов 2016 года в США, были размещены «социальными ботами». Исследование, проведенное в Германии, показало, что 9,9% подписчиков аккаунтов немецких национальных партий в Твиттере являются «социальными ботами» [7].А исследование, опубликованное в журнале Science, показало, что фейковые новости быстрее распространяются в Твиттере благодаря людям, а не ботам [8].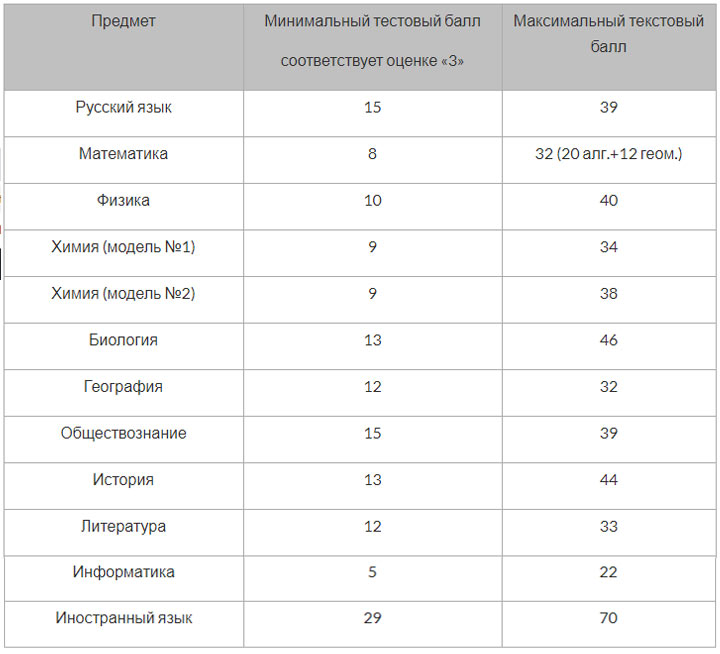 Эти исследования имеют общую черту: инструмент обнаружения ботов Botometer [4], ранее известный как BotOrNot [3]. Однако стоит отметить, что это далеко не единственные исследования, в которых используется именно эта форма метода обнаружения ботов. Простой поиск в Google Scholar по запросу «botometer ИЛИ «botornot»» дает 918 результатов (по состоянию на 28 июля 2020 г.) с 439 результатами с 2019 г.Таким образом, будет справедливо сказать, что этот инструмент, возможно, является самым популярным методом обнаружения ботов в социальных науках, и приложения инструментов были опубликованы как в специализированных журналах, таких как «Политическая коммуникация » [7], так и в высокорейтинговых общих журналах. журналы по интересам, такие как Science [8] или Nature Communications [9]. Таким образом, можно предположить, что ботометр является стандартом де-факто для обнаружения ботов в вычислительной социальной науке.
Эти исследования имеют общую черту: инструмент обнаружения ботов Botometer [4], ранее известный как BotOrNot [3]. Однако стоит отметить, что это далеко не единственные исследования, в которых используется именно эта форма метода обнаружения ботов. Простой поиск в Google Scholar по запросу «botometer ИЛИ «botornot»» дает 918 результатов (по состоянию на 28 июля 2020 г.) с 439 результатами с 2019 г.Таким образом, будет справедливо сказать, что этот инструмент, возможно, является самым популярным методом обнаружения ботов в социальных науках, и приложения инструментов были опубликованы как в специализированных журналах, таких как «Политическая коммуникация » [7], так и в высокорейтинговых общих журналах. журналы по интересам, такие как Science [8] или Nature Communications [9]. Таким образом, можно предположить, что ботометр является стандартом де-факто для обнаружения ботов в вычислительной социальной науке.
ботов, как известно, сложно.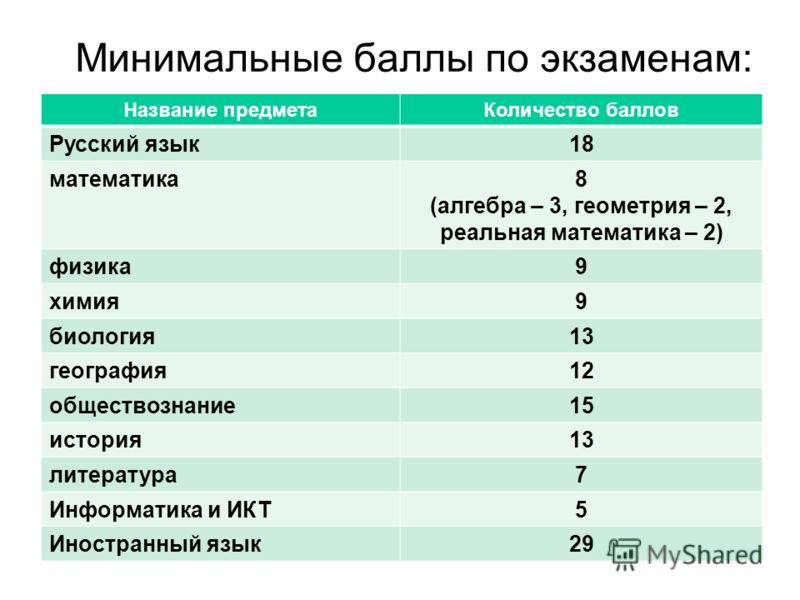 Создатели ботов (особенно в контексте мошеннических социальных ботов, выдающих себя за людей) будут не только пытаться убедить пользователей, а также исследователей, применяющих свои методы обнаружения, в том, что их боты являются законными людьми, но и приспосабливают своих ботов к новейшим методам идентификации. и, таким образом, часто будет на шаг впереди исследователей. Это, конечно, идет рука об руку с определенной неопределенностью, когда дело доходит до обнаружения ботов. Есть множество случаев, когда учетные записи Twitter выглядят как боты, но на самом деле являются людьми, и наоборот; некоторые учетные записи являются одновременно полуавтоматическими и полуавтоматическими.Чтобы учесть эту сложность, Botometer не говорит, является ли пользователь ботом или нет, а скорее дает оценку вероятности от 0 до 1 (1 = скорее всего бот, 0 = скорее всего человек; шкала также может быть от 0 до 5, как показано на домашней странице ботометра ). Следовательно, исследователи должны вручную определить пороговое значение, которое кажется им разумным, если они хотят классифицировать учетные записи бинарным способом.
Создатели ботов (особенно в контексте мошеннических социальных ботов, выдающих себя за людей) будут не только пытаться убедить пользователей, а также исследователей, применяющих свои методы обнаружения, в том, что их боты являются законными людьми, но и приспосабливают своих ботов к новейшим методам идентификации. и, таким образом, часто будет на шаг впереди исследователей. Это, конечно, идет рука об руку с определенной неопределенностью, когда дело доходит до обнаружения ботов. Есть множество случаев, когда учетные записи Twitter выглядят как боты, но на самом деле являются людьми, и наоборот; некоторые учетные записи являются одновременно полуавтоматическими и полуавтоматическими.Чтобы учесть эту сложность, Botometer не говорит, является ли пользователь ботом или нет, а скорее дает оценку вероятности от 0 до 1 (1 = скорее всего бот, 0 = скорее всего человек; шкала также может быть от 0 до 5, как показано на домашней странице ботометра ). Следовательно, исследователи должны вручную определить пороговое значение, которое кажется им разумным, если они хотят классифицировать учетные записи бинарным способом. Если учетная запись имеет более высокий балл, чем определенный порог, она будет определена исследователями как бот.Войчик и др. [5], например, выбрали 0,43, а Келлер и Клингер [7] выбрали 0,76. Напротив, Zhang et al. [10] используют довольно низкий порог 0,25 для вероятности полной автоматизации (CAP), которая также обеспечивается ботометром .
Если учетная запись имеет более высокий балл, чем определенный порог, она будет определена исследователями как бот.Войчик и др. [5], например, выбрали 0,43, а Келлер и Клингер [7] выбрали 0,76. Напротив, Zhang et al. [10] используют довольно низкий порог 0,25 для вероятности полной автоматизации (CAP), которая также обеспечивается ботометром .
Для исследователей такие признанные инструменты, как Botometer , которые поставляются с большим количеством рецензируемых публикаций, придающих инструменту авторитет и легитимность, а также простой доступ к API, являются важным ресурсом в их цели пролить свет на роль ботов в социальных сетях, таких как Twitter, и их потенциальное влияние на общественное мнение.Впрочем, ботометр не выдерживает критики. Гримм и др. [11] показывают в своем исследовании, например, что Botometer не может точно классифицировать гибридные и полностью автоматизированные учетные записи ботов, которые создали авторы. Первоначальные создатели признают эти потенциальные ограничения своего инструмента и признают, что «многие алгоритмы машинного обучения, в том числе используемые ботометром , не упрощают интерпретацию их классификаций» [12]. Они также предлагают в официальном FAQ на домашней странице Botometer , что «заманчиво установить произвольную пороговую оценку и считать все, что выше этого числа, ботом, а все, что ниже человека, но это, вероятно, не лучший способ подумай об этом [оценка бота]» [13].Тем не менее, как мы уже указывали выше, во многих исследованиях, использующих ботометр в качестве инструмента, используется фиксированный порог [5, 7, 8].
Первоначальные создатели признают эти потенциальные ограничения своего инструмента и признают, что «многие алгоритмы машинного обучения, в том числе используемые ботометром , не упрощают интерпретацию их классификаций» [12]. Они также предлагают в официальном FAQ на домашней странице Botometer , что «заманчиво установить произвольную пороговую оценку и считать все, что выше этого числа, ботом, а все, что ниже человека, но это, вероятно, не лучший способ подумай об этом [оценка бота]» [13].Тем не менее, как мы уже указывали выше, во многих исследованиях, использующих ботометр в качестве инструмента, используется фиксированный порог [5, 7, 8].
Тем не менее, в литературе есть несколько заметных исключений, когда исследователи проверяли существующие инструменты, такие как Bototmeter , на первом этапе, а затем вместо этого выбирали самостоятельно разработанное решение. Не обсуждая явно диагностические возможности ботометра , Fernquist et al. [14] указывают в своем исследовании шведских данных Twitter, что Botometer борется с твитами не на английском языке, и сообщают, что их собственный контролируемый классификатор превосходит Botometer .Эчеверрия и др. [15] разработали собственный подход и показали, что Botometer борется с некоторыми наборами данных их ботов. Креши и его коллеги [16], например, сравнивают производительность более ранней версии Botometer (BotOrNot) с другими методами, а также со своим собственным методом [17] и показывают, что BotOrNot борется с более поздними версиями спам-ботов. Таким образом, хотя Botometer является одним из самых популярных средств обнаружения ботов, некоторые исследователи показали, что другие подходы превосходят Botometer на определенных наборах данных [16, 18, 19].Приведенные выше примеры показывают, что помимо метода ботометра существует множество различных методов. Ораби и др. [20] определили 53 различных метода в своем обзоре литературы по классификации ботов.
[14] указывают в своем исследовании шведских данных Twitter, что Botometer борется с твитами не на английском языке, и сообщают, что их собственный контролируемый классификатор превосходит Botometer .Эчеверрия и др. [15] разработали собственный подход и показали, что Botometer борется с некоторыми наборами данных их ботов. Креши и его коллеги [16], например, сравнивают производительность более ранней версии Botometer (BotOrNot) с другими методами, а также со своим собственным методом [17] и показывают, что BotOrNot борется с более поздними версиями спам-ботов. Таким образом, хотя Botometer является одним из самых популярных средств обнаружения ботов, некоторые исследователи показали, что другие подходы превосходят Botometer на определенных наборах данных [16, 18, 19].Приведенные выше примеры показывают, что помимо метода ботометра существует множество различных методов. Ораби и др. [20] определили 53 различных метода в своем обзоре литературы по классификации ботов.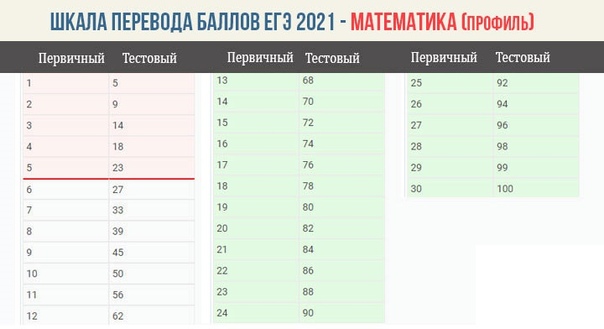 В целом можно выделить контролируемые и неконтролируемые методы [20], которые иногда даже комбинируют [21]. Креши [22] указывает в своем обзоре исследований по обнаружению ботов за последнее десятилетие, что в то время как первые дни методов обнаружения ботов были придуманы контролируемыми классификаторами, ориентированными на отдельные учетные записи, в последнее время многие неконтролируемые методы [17, 23] фокусируются на группах. [23] вместо отдельных счетов были разработаны.Помимо этих в основном выводных подходов, Гримме и его коллеги [11] обсуждают описательные подходы, при которых исследователи обычно вручную анализируют конкретные кампании. Некоторые из этих описательных подходов представляют собой комбинацию классификаторов и ручного анализа [24]. Несмотря на то, что каждый год разрабатывается множество новых методов обнаружения ботов, в некоторых случаях превосходящих ботометр [15, 16, 18], мы сосредоточимся на ботометре , поскольку это, безусловно, наиболее часто используемый инструмент в исследованиях, анализирующих ботов в Твиттере [15, 16, 18]. 12], особенно в социальных науках [5, 7, 10].
В целом можно выделить контролируемые и неконтролируемые методы [20], которые иногда даже комбинируют [21]. Креши [22] указывает в своем обзоре исследований по обнаружению ботов за последнее десятилетие, что в то время как первые дни методов обнаружения ботов были придуманы контролируемыми классификаторами, ориентированными на отдельные учетные записи, в последнее время многие неконтролируемые методы [17, 23] фокусируются на группах. [23] вместо отдельных счетов были разработаны.Помимо этих в основном выводных подходов, Гримме и его коллеги [11] обсуждают описательные подходы, при которых исследователи обычно вручную анализируют конкретные кампании. Некоторые из этих описательных подходов представляют собой комбинацию классификаторов и ручного анализа [24]. Несмотря на то, что каждый год разрабатывается множество новых методов обнаружения ботов, в некоторых случаях превосходящих ботометр [15, 16, 18], мы сосредоточимся на ботометре , поскольку это, безусловно, наиболее часто используемый инструмент в исследованиях, анализирующих ботов в Твиттере [15, 16, 18]. 12], особенно в социальных науках [5, 7, 10].
В этой статье мы будем использовать термин «бот». Мы признаем, что другие исследователи говорили об «автоматизированных учетных записях» [1] или «социальных ботах» [7], но поскольку создатели Botometer специально говорят об идентификации «ботов», мы будем использовать ту же терминологию [13]. Примечательно, что создатели Botometer обычно говорят о «социальных ботах» в своих научных работах [3, 6, 12, 25], но до недавнего времени не использовали этот термин в системе часто задаваемых вопросов инструмента.В Luceri et al. [26], один из создателей оригинального Botometer даже понимает bot как сокращение от «бот для социальных сетей», что еще больше усугубляет путаницу. В то время как существует согласие по поводу определения «бота» (автоматизация как решающий фактор), социальное в «социальном боте» оспаривается. Тем не менее, обсуждение этой части выходит за рамки данной статьи, и Горва и Гильбо [27] уже прояснили многие аспекты концептуальной путаницы в их типологии ботов.
У этой статьи две цели.Во-первых, мы хотим критически оценить, как мы показали выше, один из самых популярных инструментов обнаружения ботов, используемых в социальных науках. Во-вторых, мы хотим стимулировать размышления о роли вычислительных методов, поскольку некоторые из наших результатов помогают лучше понять ограничения систем машинного обучения, разработанных для выявления ботов на платформах социальных сетей.
Вопросы исследования
Учитывая, что обнаружить ботов очень сложно, а также известность Ботометр в социальных науках, мы спрашиваем: Насколько точен Ботометр в обнаружении ботов ? В частности, нас интересуют четыре различных вопроса исследования.Во-первых, нас интересует общая диагностическая способность ботометра . Мы хотим оценить ботометр с помощью кривой рабочих характеристик приемника (ROC), поскольку это распространенный подход, используемый, например, Varol et al. [4]. Этот подход позволяет нам оценить, насколько хорошо ботометр может различать ботов и людей в целом.
RQ1: Насколько хороши диагностические возможности ботометра для пяти различных наборов учетных записей Twitter?
Тем не менее, на практике многие исследователи анализируют наборы данных, взятые из общей совокупности пользователей Twitter, и вручную определяют пороговые значения того, что считается ботом, а что нет.Таким образом, нас интересует точность (процент учетных записей, которые классифицируются как боты), а также полнота (процент идентифицированных ботов от всего населения).
RQ2: Насколько хороши точность и полнота результатов Botometer при использовании для пяти различных наборов учетных записей Twitter, представляющих соотношение бот/человек в общей популяции Twitter?
Как уже показывает анализ Fernquist et al. [14], могут быть различия между языками в отношении производительности Botometer .Анализ данных по первым двум исследовательским вопросам позволяет нам также конкретно оценить, существуют ли различия между языками.
RQ3: Отличается ли производительность ботометра в зависимости от языка?
В экспериментальных условиях Grimme et al. [11] показали, что классификационная оценка не стабильна во времени. Поэтому мы заинтересованы не только в том, чтобы измерить балл Botometer один раз, но и в том, чтобы отслеживать учетные записи в течение более длительного периода времени.
RQ4: Насколько стабильны классификации Botometer с течением времени?
Отвечая на эти четыре вопроса, мы хотим дополнить литературу о ботах, пролив свет на некоторые проблемы, связанные с ботометром , и обсудить, какие последствия это имеет для социологов, занимающихся исследованиями ботов.
Данные и методы
Чтобы ответить на эти исследовательские вопросы, мы опираемся на пять наборов данных. Мы включили все официальные учетные записи немецких членов парламента на основе списка лично подтвержденных официальных учетных записей ( немецких политиков : n = 532) и всех членов 115-го U.С. Конгресс с аккаунтом в Твиттере ( политиков США : n = 516) [28] как «человеческие» аккаунты. Мы также создали список очевидных ботов ( новых ботов : n = 935). Мы использовали всех ботов, перечисленных в базе данных https://botwiki.org/, с целью сохранения интересных и креативных ботов Twitter, а также ряда других ботов, отмеченных нами в Twitter. Большинство из этих учетных записей помечены как боты, а для многих даже их код доступен на GitHub. Поскольку большинство этих ботов используют английский язык, мы также собрали дополнительный список ботов на немецком языке ( немецких ботов : n = 27).В качестве пятого набора данных мы используем аннотированный вручную набор данных с учетными записями людей (n = 1747) и ботов (n = 826), который был создан создателями Botometer [4]. Мы объединили эти наборы данных для нашего анализа данных (см. Таблицу 1). Для первых трех исследовательских вопросов нам нужны как боты, так и учетные записи людей, поскольку мы оцениваем, насколько хорошо ботометр может отличать автоматические учетные записи от учетных записей людей. Поэтому мы объединяем разные наборы данных (см. Таблицу 1). Однако для RQ4 мы можем использовать отдельные наборы данных, состоящие только из ботов или людей.
Наш выбор наборов данных основан на одном основном предположении: инструменты обнаружения ботов, такие как Botometer , будут лучше различать ботов и людей, когда случаи будут четкими. Как видно на рис. 1, отчетливые учетные записи ботов часто в своем описании прямо заявляют, что они на самом деле являются ботами; иногда даже делился кодом на GitHub. Точно так же четко очерченные человеческие случаи часто будут иметь индикаторы, которые сигнализируют об их подлинности, такие как синяя галочка (значок подтверждения Twitter) или их личный веб-сайт.Чтобы было еще понятнее, мы выбрали избранных национальных политиков с их официальными аккаунтами, то есть людей, которые находятся в центре внимания общественности и часто имеют большое количество подписчиков, подозрительная активность которых в Твиттере автоматически привлечет внимание СМИ и повышенное внимание. В Германии, например, журналисты обнаружили сеть вокруг учетных записей политиков AfD в Twitter, которая состояла из марионеток, которые повышали уровень вовлеченности [29]. Это не означает, что политики могут не использовать какую-либо автоматизацию, а скорее то, что эту форму автоматизации нельзя путать с ботами или социальными ботами.Наконец, мы также включили список Варола, в который вошли как боты, так и люди. Хотя мы не всегда могли индивидуально проверить, была ли учетная запись ботом или человеком, мы верим в первоначальную категоризацию, на которой основаны части обучения ботометра . В результате у нас есть четыре набора данных учетных записей, по которым программистам не составит труда отличить ботов от людей, и один, который использовался для обучения классификатора Botometer . Основываясь на этих критериях, мы ожидаем, что инструмент Botometer будет работать довольно хорошо, поскольку «реальные» данные из Twitter гораздо более беспорядочны.
Для проведения этого теста мы создали скрипт Python, который запускался каждый день в 00:00 по всемирному координированному времени на сервере Ubuntu Linux в течение 3 месяцев (3 марта — 2 июня 2019 г.). Сбор данных шел непрерывно. Для каждой учетной записи в нашей выборке (n = 4583) мы запросили данные Twitter через API поиска Twitter и оценки пользователей Botometer через API Botometer , что дало нам в общей сложности 374 724 действительных оценки. Для анализа мы использовали Botometer v3 [12], последнюю версию инструмента на март 2019 года.Помимо пустой временной шкалы ( Botometer требуется хотя бы один твит — необходимо исключить 2021 звонок), отсутствующих учетных записей (в основном из набора данных Варола, который включает учетные записи, которые больше не существуют — 11 197 звонков) и частных учетных записей (также в основном из базы данных Варола). набор данных — 33 608 вызовов пришлось исключить), только 86 вызовов (менее 0,05% всех вызовов) вернули ошибку из-за технической проблемы API от Botometer или Twitter API. В конечном итоге мы смогли проанализировать 4134 существующих учетных записи, к которым можно было получить доступ хотя бы один раз в процессе сбора данных и которые имели хотя бы один твит на своей временной шкале (см. Таблицу 1).Для следующего анализа мы используем независимую от языка универсальную оценку ботометра от 0 до 1 (что соответствует оценке 0–5, также используемой ботометром — например, 0,5 будет 2,5), конкретную оценку ботометра английского языка между 0 и 1, а также недавно интегрированный английский язык Botometer и универсальная вероятность полной автоматизации (CAP) (в диапазоне от 0 до 1). Хотя мы знаем, что создатели ботометра предлагают более детализированные оценки характеристик, помимо общих универсальных оценок, мы сосредоточимся на универсальных общих оценках, поскольку они используются социологами в своих исследованиях и не зависят от языка, на котором они основаны. аккаунты в Твиттере.Тем не менее, поскольку нас интересуют языковые различия, мы также сообщаем баллы Botometer по английскому языку для нашего третьего исследовательского вопроса (см. также рисунки S1–S5 для всех других визуализаций с баллами по английскому языку и CAP).
Для RQ1 мы сравнили ROC-AUC (рабочие характеристики приемника — площадь под кривой) со старым ROC-AUC, о котором сообщалось в более ранних исследованиях для ботометра , чтобы оценить диагностические возможности ботометра . ROC-AUC указывает, насколько хорошо модель различает два класса (бот и отсутствие бота).Истинная положительная частота на оси y нанесена на график против ложноположительной скорости на оси x. Хотя эта статистика полезна для прямого сравнения общей производительности различных моделей и помеченных наборов данных с точки зрения точности классификации, этот метод оценки также имеет свои ограничения [30, 31]. Исследователей, например, часто интересуют не все потенциальные пороговые значения баллов, используемые в подходе AUC-ROC, а только конкретные классификационные значения [32]. Подход AUC-ROC не учитывает стоимость ложноположительных и ложноотрицательных результатов и не полностью учитывает дисбаланс в общей популяции [33].Однако в своей исходной статье для первой версии инструмента ( BotOrNot ) авторы прозрачно предупреждают, что точность их модели (они получили ROC-AUC 0,95/0,94) завышает будущую производительность из-за возраста обучения. данные [3].
Поскольку подход ROC-AUC имеет ограничения, мы также используем другой подход для RQ2. В исследованиях ботов самой большой проблемой является более низкая встречаемость ботов по сравнению с людьми. В общей популяции всех пользователей Твиттера настоящих пользователей больше, чем ботов.Однако подход ROC-AUC не учитывает базовый уровень населения Twitter. Это общая проблема с классификаторами, если игнорируется структура генеральной совокупности, в которой впоследствии должен использоваться классификатор. В случае с ботами мы хотим четко идентифицировать ботов и делать заявления о количестве ботов в наборе данных. Это становится еще яснее, если принять во внимание основную цель, а также формулировку в исследованиях ботов. Исследователей интересует количество ботов, а не количество пользователей-людей.Поэтому даже небольшой процент ложноположительных результатов (FPR) оказывает большое влияние на результаты. Данные, используемые для тестирования (как в нашем случае) и обучения Botometer , часто более сбалансированы, чем довольно несбалансированная общая популяция Twitter. Saito и Rehmsmeier [33] рекомендуют в таких случаях оценивать производительность классификатора на основе кривых Precision-Recall (PR), поскольку они «позволяют точно и интуитивно интерпретировать практическую производительность классификатора». В то время как так называемый коэффициент корреляции Мэтьюса лучше, чем оценка F1, если исследователи используют только один конкретный порог, кривые PR рекомендуются [34, 35], если существуют разные пороговые уровни, как в случае с ботометром .Чтобы смоделировать популяцию, которая представляет такое же предполагаемое реальное соотношение общей популяции Twitter с 15% ботов [4] и 85% не-ботов, мы передискретизировали различные наборы данных для RQ2.
Результаты
Наш анализ (см. рис. 2 и таблицу 2) показывает, что ROC-AUC хуже с нашими полными данными (AUC = 0,85), чем с наборами данных, использованными в оригинальных статьях создателей Botometer , которые получили AUC 0,94 [4]. Однако их базовая модель также получила только AUC, равную 0.85 в оригинальной статье. Чем ближе кривая ROC (рис. 2) к верхнему левому углу и чем больше места под кривой, тем лучше ботометр может различать ботов и людей. В левом нижнем углу кривая начинается с порога 0 для ботометра , что означает, что частота ложных срабатываний равна 0, но в то же время будет идентифицировано 0 ботов в популяции. Кривая заканчивается порогом 1 в правом верхнем углу, так как тогда будут идентифицированы все боты в популяции.Однако такой порог также означает, что все учетные записи людей будут ошибочно классифицированы как боты (коэффициент ложных срабатываний = 1). Таким образом, каждая точка на кривой представляет собой определенный порог, для которого показана доля истинно положительных результатов, а также доля ложноположительных результатов.
Рис. 2. Кривая рабочих характеристик приемника для ботометра и универсальный балл (средний за 3 месяца для каждой учетной записи).
По оси x отложена доля ложноположительных результатов, а по оси Y – доля истинно положительных результатов (чувствительность).
https://doi.org/10.1371/journal.pone.0241045.g002
Применяя это к нашим наборам данных, мы видим, что классификатор имеет самый высокий показатель AUC для набора данных политиков и ботов США (0,93) за которым следует помеченный набор данных Varol et al. (0,86). Оценка для немецких политиков и немецких ботов дает более низкую оценку (0,76). Поскольку у нас было всего несколько немецких ботов, мы также протестировали немецких политиков и ботов (с новыми ботами вместо немецких), у которых был немного более высокий AUC (0.78).
Затем мы рассчитали ROC-AUC для универсального CAP (вероятность полной автоматизации; рис. 3 и таблица 3). Мы могли наблюдать те же результаты, что и раньше, для универсального балла: политики из США получили самую высокую AUC (0,94), за ними следуют Varol et al. (0,86), полный набор данных (0,86), немецкие политики с новыми ботами (0,78) и немецкие политики и немецкие боты (0,77).
Рис. 3. Кривая рабочих характеристик приемника для ботометра и универсальная вероятность полной автоматизации (CAP) (среднее значение за 3 месяца для каждой учетной записи).
По оси x отложена доля ложноположительных результатов, а по оси Y – доля истинно положительных результатов (чувствительность).
https://doi.org/10.1371/journal.pone.0241045.g003
Для RQ2 мы предлагаем мысленный эксперимент, основанный на наборах данных, проанализированных в этом исследовании. Хотя наборы данных не идеально сбалансированы, они определенно не отражают несбалансированное соотношение ботов и учетных записей людей к реальному населению Twitter. Таким образом, мы предполагаем для нашего моделирования, что население Twitter состоит из 15% ботов [4] и 85% не-ботов.Сначала мы присвоили каждой отдельной учетной записи вероятность выборки, отражающую возникновение случаев в популяции Twitter (n ботов/0,15 и n людей/0,85), и взяли 100 000 случайных выборок с заменой для каждого анализируемого набора данных. В результате мы создали новые наборы данных, содержащие 15 000 ботов и 85 000 не-ботов. Затем мы рассчитали для всех наборов данных ROC-AUC, а также PR-AUC (см. Таблицы 2 и 3). Как и ожидалось, ROC-AUC одинаков с новыми выборочными данными для всех проанализированных наборов данных, что также соответствует тому, что показывают Сайто и Ремсмейер [33] в своем исследовании.Однако PR-AUC показывает другую оценку для наборов данных с повторной выборкой, поскольку PR-AUC изменяется в зависимости от дисбаланса в наборе данных. Единственным исключением является сильно искаженный набор данных немецких политиков и немецких ботов в исходной форме, который показывает улучшение, но в целом по-прежнему имеет чрезвычайно низкий балл (от 0,10 до 0,27).
Кривые PR позволяют нам лучше оценить, сколько ботов будет среди учетных записей, классифицированных Botometer как боты, и сколько ботов не будет идентифицировано, если мы используем высокий порог (как это делается во многих исследованиях с помощью этого инструмента, например.грамм. [7]). Кривые PR начинаются справа с порога оценки Botometer , равного 0. Если используется чрезвычайно низкий порог, все боты в популяции будут идентифицированы (отзыв = 1), но количество ложноположительных случаев будет чрезвычайно высоким. Таким образом, точность составляет 0,15, поскольку 85% аккаунтов в выборке — люди. Слева кривая заканчивается чрезвычайно высоким порогом для оценки Botometer , что означает, что точность чрезвычайно высока (все классифицированные учетные записи ботов являются ботами), но отзыв чрезвычайно низок (почти все боты в общей популяции являются ботами). не опознан).Теперь мы также можем проверить точность и вспомнить определенные пороговые значения. Например, если 0,76 используется в качестве порога для перевыборки всех наборов данных, 59% реальных ботов (точность = 0,59) и 41% ложноположительных людей будут среди учетных записей, классифицированных как боты (см. рис. 4). Однако около 80% (отзыв = 0,2) ботов в популяции не будут идентифицированы (ложноотрицательные результаты). Если мы рассмотрим набор данных немецких политиков и ботов , результаты будут еще хуже. Из учетных записей, классифицированных как «бот», только около 24% (точность = 0.24) будут ботами, а 76% учетных записей будут ложноположительными учетными записями людей. Более того, около 90% (отзыв = 0,1) ботов в популяции Twitter не будут идентифицированы (см. рис. 4).
Рис. 4. Кривые точности и полноты универсальной оценки для наборов данных с повторной выборкой.
Мы учитываем базовый уровень населения в Твиттере (15% ботов) для универсальной оценки ботометра, черные точки указывают на точность и отзыв для оценки ботометра 0,76. С набором данных немецких политиков и ботов почти для каждого порогового уровня в идентифицированной выборке ботов больше людей, чем реальных ботов (точность).Ось x представляет отзыв (чувствительность), а ось y представляет точность.
https://doi.org/10.1371/journal.pone.0241045.g004
Затем мы также рассчитали PR-AUC для универсального CAP с новыми взвешенными повторными выборками (см. Таблицу 3). Что касается PR-AUC и ROC-AUC, то результаты практически такие же, как и для универсального ботометра баллов . При расчете CAP и использовании порога 0,25, как это использовалось Zhang et al. [10], учетные записи, классифицированные как боты с помощью ботометра , будут состоять примерно на 55% из ботов (точность = 0.55) и 45% людей. Однако около 71% (отзыв = 0,29) ботов в популяции не будут идентифицированы. Если мы посчитаем то же самое для немецких политиков с ботами , у нас будет 70% ложноположительных учетных записей людей и 30% ботов (точность = 0,3) в выборке, которую Botometer классифицировал как «боты» (см. рис. 5). Около 82% ботов (отзыв = 0,18) в популяции не будут идентифицированы. Для этих тестов мы также использовали повторную выборку из 100 000 учетных записей для каждого набора данных, основанного на предположении, что 15% ботов присутствуют в популяции Twitter.Таким образом, этот количественный мысленный эксперимент показывает, какое влияние эти оценки могут оказать на результаты оценки количества людей и ботов.
Рис. 5. Кривые полноты CAP для наборов данных после повторной выборки.
Мы учитываем базовый уровень населения в Твиттере (15% ботов) для универсальной оценки CAP Botometer. Черные точки указывают на точность и отзыв для универсальной CAP 0,25. С немецкими политиками и ботами почти для каждого порогового уровня в идентифицированной выборке ботов больше людей, чем реальных ботов (точность).Ось x представляет отзыв (чувствительность), а ось y представляет точность.
https://doi.org/10.1371/journal.pone.0241045.g005
В нашем третьем исследовательском вопросе нас интересует разница между языками. Прежде всего, оценка английского языка Botometer (таблица 4) лучше работает с учетными записями на английском языке (например, набор данных Varol et al.: ROC-AUC английский = 0,90; универсальный = 0,86; образец PR-AUC английский = 0,69; универсальный = 0,58) и хуже работает с главным образом неанглоязычными учетными записями (например,г., набор данных немецких политиков и немецких ботов: ROC-AUC English = 0,69; универсальный = 0,76; PR-AUC образца английского языка = 0,23; универсальный = 0,27). То же самое справедливо для универсального и английского CAP (табл. 5). Сравнение различных наборов данных показывает, что инструмент лучше работает с данными из США/английского языка (см. рис. 2–5, а также см. рис. S1 и S3). Однако ботометр плохо работает ни с немецкими политиками, ни с новыми протестированными нами англоязычными ботами, даже с английскими баллами.Далее мы проверили с помощью непарных тестов Делонга [36, 37], отличаются ли ROC-AUC для немецких наборов данных статистически от других наборов данных. Наш тест показывает, что ROC-AUC для немецких наборов данных значительно отличается от ROC-AUC американских политиков и ботов в отношении универсальной оценки (немецкие политики и боты: D = -10,58, df = 2133.1, p < 0,001 Немецкие политики и немецкие боты: D = -4,67, df = 586.12, р < 0,001; поправка Бонферрони α = 0,005), а также универсальный CAP (немецкие политики и боты: D = -4,81, df = 579,12, p < 0,001; немецкие политики и немецкие боты: D = -10,65, df = 2066,3, p < 0,001, поправка Бонферрони α = 0,005, см. также табл. 2 и 3). То же самое относится и к английским баллам. Кроме того, если Botometer используется с немецкими учетными записями, реальный уровень ложноположительных результатов выше, чем могут предположить исследователи, когда их единственным показателем эффективности является ROC-AUC.Хотя подход ROC-AUC является хорошим индикатором для исходного исследования и набора данных, исследователи должны быть осторожны, предполагая, что такой же уровень дискриминационной силы может быть достигнут с новым набором данных из другой совокупности учетных записей. Кроме того, исследователи должны учитывать абсолютное количество ложноположительных результатов в классифицированной выборке и сообщать MCC, точность, а также отзыв для порога, используемого в исследовании.
Наконец, в RQ4 нас интересует временная волатильность баллов ботометра .Мы выявили существенные изменения в оценках ботов на индивидуальном уровне. Сначала мы рассчитали стандартное отклонение универсальной оценки, а также универсальную CAP для каждой отдельной учетной записи, т.е. для каждой учетной записи в нашем анализе на основе всех отдельных измерений с течением времени, а затем наносили на график плотность SD всех отдельных учетных записей для каждого отдельного набора данных, чтобы оценить волатильность оценок с течением времени. Стандартное отклонение будет высоким, если показатели Botometer учетной записи имеют высокую изменчивость во времени.Наш анализ показывает, что особенно учетные записи в наборах данных ботов демонстрируют высокие стандартные отклонения и, следовательно, довольно изменчивы с течением времени (рис. 6). Единственная заслуживающая внимания разница между универсальной оценкой и универсальной CAP заключается в том, что CAP в целом кажется несколько менее изменчивым в целом (см. также рис. S2).
Рис. 6. График плотности SD для отдельных аккаунтов, построенный для каждой группы.
Слева — универсальный балл ботометра, справа — ботометр CAP. Полоса пропускания 0.015 использовался для CAP и универсальных показателей. Ось x представляет собой стандартное отклонение, а ось y представляет плотность.
https://doi.org/10.1371/journal.pone.0241045.g006
Наконец, мы также проверили, сколько учетных записей в каждом наборе данных классифицируются по-разному в течение трех месяцев. Сама по себе волатильность является проблемой только в том случае, если отдельные учетные записи зависят от дня ниже или выше выбранного порога, используемого исследователями для классификации ботов. Если мы выбрали порог 0.76, 27,2% новых ботов, 22,2% немецких ботов и 13,9% ботов Varol хотя бы раз будут иметь ежедневное измерение выше и ниже порога. Для людей изменчивость менее серьезна по сравнению с классификацией, основанной на высоком пороге. 7,4% немецких политиков, 3,1% людей-варолов и только 0,6% американских политиков имеют ежедневное измерение выше и ниже порога хотя бы один раз.
Мы также рассчитали изменение классификации для порога 0.25 для универсального CAP. Мы видим, что 37,5% новых ботов, 33,3% немецких ботов, 10,7% немецких политиков, а также 1% американских политиков хотя бы раз имеют рейтинг ниже или выше порога. Из набора данных ботов Varol 17,7% и из набора данных о людях Varol 4,7% хотя бы раз были ботами или людьми.
Мы дополнительно рассчитали процент аккаунтов, которые за три месяца имеют оценку ниже или выше порогового значения хотя бы один раз для всех пороговых значений от 0 до 1 с шагом 0.05 (см. рис. 7; см. также рис. S3). Наш анализ показывает, что в целом боты более склонны иметь оценку ниже или выше порогового значения как для универсального CAP, так и для универсальной оценки хотя бы один раз. Тем не менее, универсальный CAP лучше работает для новых ботов , а также для немецких ботов .
Рис. 7. Изменение оценки с течением времени.
Процент аккаунтов (ось Y), которые хотя бы один раз за три месяца получили оценку ниже или выше порогового значения для всех пороговых значений от 0 до 1 с шагом 0.05. Ось X представляет выбранный порог для оценки Botometer . Слева для универсального балла, справа для универсального CAP.
https://doi.org/10.1371/journal.pone.0241045.g007
Обсуждение
В то время, когда часто используются такие термины, как «вычислительная пропаганда» [38], «кампании по дезинформации» [39] или «скоординированное недостоверное поведение» [40], идентифицируя автоматизированные учетные записи, которые распространяют дезинформацию или пытаются изменить разговор кажется первостепенным.Действительно, возможность оценить степень неаутентичного поведения в рамках данного онлайн-дискурса и понять его модели может привести к выявлению скоординированных кампаний по дезинформации. Следовательно, был и остается академический спрос на такие инструменты, как Botometer , которые поставлялись не только с API, но, что более важно, также с необходимыми академическими полномочиями (т.е. учреждением и цитатами). Botometer был и остается очень хорошим примером того, как можно обучать контролируемые модели машинного обучения, анализирующие отдельные учетные записи, и каков может быть потенциальный результат.
Тем не менее, как мы показываем в этом исследовании, исследователи должны быть осторожны, используя инструменты, разработанные другими учеными, иногда в совершенно другом контексте. Высокий показатель ROC-AUC с исходным набором данных и условиями исследования не означает хорошей «точности» для вычислительных исследований в области социальных наук, исследующих другой контекст, как мы показываем для Botometer v3. Таким образом, наши результаты согласуются с тем, что некоторые предыдущие исследования могли показать для более старых версий ботометра [14, 16].Даже хорошая диагностическая способность (ROC-AUC) приводит к проблематичным результатам, если учитывать исходный уровень населения. Другими словами: то, что модель работает с тестовым набором данных, не означает, что результаты надежны для конкретного варианта использования. Как ученые, мы должны заботиться о надежности, валидности и воспроизводимости [41, 42]. Во многих социальных исследованиях, в которых используется ботометр , эти критерии игнорировались. Как мы показали в нашем анализе, ботометр имеет проблемы с выявлением ложноположительных и ложноотрицательных результатов в наших коллекциях при применении аналитических подходов из вычислительных социальных наук; особенно с порогами, использованными в предыдущих исследованиях.Это примечательно, поскольку наши наборы данных состояли либо из учетных записей, на которых непосредственно обучался ботометр , либо в случаях, когда случаи были четкими и легко идентифицируемыми для человека-кодировщика. Создатели ботометра [43] утверждают в своей последней статье, что некоторые учетные записи немецких политиков, использованные в нашем исследовании, могут иметь определенную степень автоматизации. Тем не менее, мы вручную проверили все ложноположительные учетные записи политиков (оценка выше 0,76), и только один из 27 ложноположительных политиков демонстрирует поведение, которое может быть классифицировано Botometer как автоматизация.А именно, политик синхронизировал свою учетную запись Facebook со своей учетной записью Twitter, и все сообщения Facebook также были отправлены через Twitter. Это показывает, что неправильная классификация ботометра не связана с реальной автоматизацией политических аккаунтов. Действительно, большинство других учетных записей, которые были ложно классифицированы как боты, были в основном неактивными и не писали в Твиттере в этот период времени. Кроме того, мы показываем, что оценки меняются со временем, что делает исследования, в которых используются данные ботометра за один день или неделю, трудно воспроизвести. Ботометр , что неудивительно, работал лучше на учетных записях, на которых алгоритм обучался даже в нашем анализе с течением времени. Однако со временем инструмент стал неточным для новых ботов, а также для немецкого набора данных. Кроме того, боты, которые не предназначены для развлечения других пользователей, а скорее нацелены на то, чтобы скрыть их автоматическую личность и реальные цели (например, распространение дезинформации), будут притворяться людьми, что еще больше затруднит их идентификацию инструментами обнаружения ботов [11, 16]. В этом смысле четкое различие между людьми и ботами — это минимум, которого должны достичь инструменты обнаружения ботов.Действительно, как исследователи, мы должны быть осторожны, полагаясь на существующие инструменты, и, как показал наш мысленный эксперимент, также должны помнить о населении, к которому мы применяем классификаторы. Если количество ботов составляет меньшинство для населения в целом (как мы предполагаем в данном случае в Твиттере), даже небольшой процент ложноположительных результатов может привести к большому количеству учетных записей людей, ошибочно классифицированных как боты.
Таким образом, возникает вопрос, должны ли исследователи вообще использовать Ботометр .И хотя аргумент в пользу ботометра будет заключаться в том, что, хотя он и не идеален, он, по крайней мере, является приближенным к идентификации ботов в Твиттере, наш контраргумент будет заключаться в том, что проблема ложноположительных и ложноотрицательных показателей для определенных порогов с наборы данных, основанные на общей численности населения Twitter, а также уязвимость инструмента к временным изменениям или различным языкам ставят под сомнение классификации инструмента. Решение, которое могут предложить исследователи, состоит в том, чтобы сместить акцент с пороговых значений на общее распределение необработанных показателей, чтобы оценить распространенность ботов в наборе данных, т.е.е. для измерения «ботинки». Однако, основываясь на нашем анализе, мы бы не рекомендовали такой подход, поскольку разные наборы данных с одинаковым соотношением людей и ботов, а также наши наборы данных о людях могут выглядеть по-разному на графиках плотности (см. рис. 8; см. также рис. S5). Хотя переход от индивидуальных учетных записей, анализируемых с помощью контролируемых классификаторов, к неконтролируемым классификаторам, фокусирующимся на групповом поведении, является многообещающим [16, 22], исследователи также должны быть осторожны, если они произвольно выбирают пороги [44]. Даже хороший классификатор может быть плохим, если исследователи используют его в неправильном контексте без какой-либо проверки.
Рис. 8. Графики плотности для различных наборов данных.
Слева: графики плотности для различных комбинированных наборов данных в нашем анализе, показывающие распределение универсального балла ботометра. Мы использовали наборы данных с повторной выборкой с 15% ботов и 85% людей с общим числом n = 100 000 для каждого набора данных. Справа: графики плотности наборов данных учетных записей людей. Линии указывают медиану, для всех наборов данных использовалась пропускная способность 0,04. По оси X отложен балл Botometer , а по оси Y — плотность.
https://doi.org/10.1371/journal.pone.0241045.g008
Однако мы также должны добавить в качестве ограничения, что мы протестировали инструмент с несколькими конкретными наборами данных. Мы выбрали наборы данных, которые упрощают нам оценку достоверности, и мы по-прежнему ожидаем очень похожих результатов при будущем анализе. Кроме того, мы использовали набор данных о ботах, который включает наиболее очевидных ботов. Если исследователи снова вручную проверят инструмент с помощью собственного уникального анализа данных, им, конечно же, следует использовать этот инструмент.Наш анализ также показывает, что Сайто и Ремсмайер [33] рекомендуют в своем исследовании: PR-кривая более информативна, если мы имеем дело с несбалансированными данными в популяции.
Сказав это, мы хотим подчеркнуть, что мы не думаем, что Ботометр является плохим инструментом в целом; мы скорее предлагаем, чтобы исследователи знали об ограничениях Botometer при использовании инструмента и заботились о проверке с помощью своих собственных помеченных наборов данных, таких как Fernquist et al. [14], Cresci и соавт. [16], а также Echeverrìa et al.[15] сделали в своих исследованиях. Наши результаты согласуются с этим предыдущим исследованием, поскольку Botometer борется с определенными типами учетных записей, ботами и людьми, которые не охвачены обучающими данными [18]. Мы считаем, что ботометр по-прежнему может быть полезным инструментом для исследователей, журналистов, а также граждан. Совсем недавно была выпущена новая версия (v4) ботометра , в которой учтены некоторые аспекты нашей критики [43] и в целом производительность выше, чем у предыдущих версий ботометра , таких как версия (v3), проанализированная в нашем исследовании.Тем не менее, основные моменты критики, которые мы выявили здесь, такие как неясность в отношении того, какой тип бота определяет ботометр , неадекватные обучающие данные для других языков и потенциальная уязвимость к временным шаблонам, по-прежнему применимы к новой версии ботометра . Таким образом, ботометр в этом контексте должен быть лишь одним из этапов многоэтапного процесса, построенного на изучении человеком индивидуальных учетных записей [11]. Хотя предыдущие исследования показали, что люди в случае краудсорсинга терпят неудачу с более сложными ботами [16], мы считаем, что опытные исследователи все же смогут идентифицировать ботов с помощью комбинации классификаторов и ручного криминалистического анализа.Однако мы считаем, что для ученых-социологов, работающих в масштабе, неопределенность слишком высока. По крайней мере, исследователи должны знать о данных, используемых в качестве обучающих данных для классификатора, который может охватывать только определенные типы ботов [15, 16, 18]. Если исследователи хотят использовать ботометр для своих наборов данных или даже разработать свои собственные новые классификаторы, мы предлагаем определенные шаги в будущем:
- Ручная классификация: они должны вручную проанализировать значительную выборку классифицированных учетных записей ботов и людей, которые были классифицированы системой машинного обучения.Затем исследователи могли рассчитать интеркодерную надежность между классификацией системы машинного обучения и классификацией человеческого кодера. Хотя процентное совпадение уже является интересным индикатором, мы настоятельно рекомендуем использовать такое измерение, как альфа Криппендорфа [45], которое учитывает случайное совпадение. Они также должны всегда вручную проверять, если это возможно, все учетные записи, которые были классифицированы как боты системой машинного обучения, если исследователи хотят делать заявления о количестве ботов в популяции.Когда набор данных слишком велик для полного ручного анализа, исследователи должны, по крайней мере, взять подходящую случайную выборку для ручной классификации. Кроме того, если учетные записи в наборе данных неоднородны (например, разные языки, разный тематический контекст), исследователи должны использовать стратегию стратифицированной выборки для ручной постфактум проверки (см. также пункт 4 ниже).
- Время: исследователи должны проверять свои результаты с течением времени. Как мы показали на примере ботометра , показатели подвержены изменениям с течением времени.Следовательно, исследователи, использующие ботометр или разрабатывающие новый классификатор машинного обучения, должны проверять свой набор данных с течением времени и следить за изменениями с течением времени. Язык
- : исследователи должны знать об ограничениях ботометра (о которых даже заявляют создатели инструмента), когда дело доходит до классификации учетных записей, которые твитят на других языках. Следовательно, ученым придется рассмотреть возможность использования других инструментов для проверки количества ботов в их наборе данных; например, ручное кодирование.Будущие системы машинного обучения также должны учитывать разные языки.
- Обмен данными: исследователи, анализирующие ботов, должны делиться идентификаторами пользователей классифицированных «ботов», поскольку условия для разработчиков Twitter позволяют исследователям делиться идентификаторами пользователей. В то время как создатели Botometer публикуют свои списки ботов на своей официальной домашней странице, социологи, использующие Botometer или аналогичные системы машинного обучения в своих исследованиях, часто даже не сообщают идентификаторы учетных записей, которые были классифицированы как боты. Улучшения
- : в будущем исследователи должны поддерживать инструменты, которые не основаны на черных ящиках, а скорее привержены идее открытой науки. Мы должны быть в состоянии работать вместе над поиском решений и улучшением этих решений с течением времени. Таким образом, это также позволило бы нам более прозрачно бороться с потенциальными недостатками.
Наконец, есть и другие способы идентификации ботов в Twitter, такие как Cresci [22] и Orabi et al. [20] показывают в своих обзорах. Мы считаем важным учитывать контекст, поскольку Bastos и Mercea [2], например, исследовали подозрительные шаблоны на основе коммуникационных показателей, а также сетевой аналитики.И хотя этот метод может быть более сложным и дорогостоящим в вычислительном отношении, он предлагает социологам путь вперед в выявлении ботов и понимании моделей дезинформационных кампаний. В целом также важно расширить перспективу и больше сосредоточиться на политическом цифровом астротурфинге [46], для которого боты являются лишь одним из потенциальных аспектов [47]. Потенциальное решение может состоять в том, чтобы, как предлагается в литературе, больше сосредоточиться на групповом поведении с помощью неконтролируемых классификаторов [22] в сочетании с описательным цифровым криминалистическим анализом [11].Тем не менее, наши предложения сверху остаются верными даже в этом новом сценарии, как показывают Варгас и его коллеги [44] при оценке таких методов.
Вспомогательная информация
S3 Рис. Изменение оценки с течением времени.
Процент аккаунтов (ось Y), которые хотя бы один раз за три месяца получили оценку ниже или выше порогового значения для всех пороговых значений от 0 до 1 с шагом 0,05. Слева для оценки английского языка, справа для английского CAP.
https://doi.org/10.1371/journal.pone.0241045.s003
(DOCX)
S4 Рис. Кривые полноты CAP для наборов данных после повторной выборки.
Мы учитываем базовый уровень населения в Твиттере (15% ботов) для оценки английского языка (слева) и оценки английского языка CAP (справа). Черные точки указывают на точность и полноту для ботометра по английскому языку 0,76 (слева) и для английского CAP 0,25 (справа). С немецкими политиками и ботами почти для каждого порогового уровня в идентифицированной выборке ботов больше людей, чем реальных ботов (точность).
https://doi.org/10.1371/journal.pone.0241045.s004
(DOCX)
S5 Рис. Графики плотности для различных наборов данных.
Слева: Графики плотности для различных комбинированных наборов данных в нашем анализе, показывающие распределение оценки английского языка Botometer. Мы использовали наборы данных с повторной выборкой с 15% ботов и 85% людей с общим числом n = 100 000 для каждого набора данных. Справа: графики плотности наборов данных учетных записей людей. Линии указывают медиану, для всех наборов данных использовалась пропускная способность 0,04.
https://doi.org/10.1371/journal.pone.0241045.s005
(DOCX)
Благодарности
Мы благодарим Chung-hong Chan, а также Momin M. Malik за их ценные отзывы, которые помогли нам существенно улучшить нашу статью. Мы также хотим поблагодарить Мартина Фукса за предоставленный нам список членов парламента Германии, проверенный вручную.
Каталожные номера
- 1. Ховард П.Н., Колланьи Б. Ботс, #Strongerin и #Brexit: вычислительная пропаганда во время референдума между Великобританией и ЕС.Журнал ССРН. 2016.
- 2. Bastos MT, Mercea D. Ботнет Brexit и гиперпартизанские новости, создаваемые пользователями. Компьютерный обзор социальных наук. 2019; 37:38–54.
- 3. Дэвис К.А., Варол О., Феррара Э., Фламмини А., Менцер Ф. BotOrNot: система оценки социальных ботов. В: Bourdeau J, Hendler JA, Nkambou RN, Horrocks I, Zhao BY, редакторы. Материалы 25-й Международной конференции Companion on World Wide Web — WWW ’16 Companion. Нью-Йорк, Нью-Йорк, США: ACM Press; 2016.стр. 273–4.
- 4. Варол О., Феррара Э., Дэвис С., Менцер Ф., Фламмини А. Онлайн-взаимодействия человека и робота: обнаружение, оценка и характеристика; 2017. https://aaai.org/ocs/index.php/ICWSM/ICWSM17/paper/view/15587/14817.
- 5. Войцик С., Мессинг С., Смит А., Рейни Л., Хтилин П. Боты Twitter: анализ доли автоматических учетных записей ссылок. 2018 [по состоянию на 27 февраля 2019 г.]. http://www.pewinternet.org/2018/04/09/bots-in-the-twittersphere.
- 6. Бесси А., Феррара Э.Социальные боты искажают онлайн-дискуссию о президентских выборах в США в 2016 году. Первый понедельник. 2016; 21.
- 7. Келлер Т. Р., Клингер У. Социальные боты в избирательных кампаниях: теоретические, эмпирические и методологические последствия. Политическая коммуникация. 2019; 36:171–89.
- 8. Восуги С., Рой Д., Арал С. Распространение правдивых и ложных новостей в Интернете. Наука. 2018; 359: 1146–51. пмид:295
- 9. Шао С, Чампалья Г.Л., Варол О., Ян К.-С., Фламмини А., Менцер Ф.Распространение ненадежного контента социальными ботами. Нац коммун. 2018; 9:4787. пмид:30459415.
- 10. Чжан Ю., Шах Д., Фоли Дж., Абхишек А., Лукито Дж., Сук Дж. и др. Чья жизнь имеет значение? Массовые расстрелы и дискурсы сочувствия и политики в социальных сетях, 2012–2014 гг. Журнал компьютерных коммуникаций. 2019; 24:182–202.
- 11. Гримме К., Ассенмахер Д., Адам Л. Изменение точки зрения: достаточно ли этого для обнаружения социальных ботов. В: Meiselwitz G, редактор.Социальные вычисления и социальные сети. Пользовательский опыт и поведение. Чам: Springer International Publishing; 2018. С. 445–61.
- 12. Yang K-C, Varol O, Davis CA, Ferrara E, Flammini A, Menczer F. Вооружение общественности искусственным интеллектом для борьбы с социальными ботами. Hum Behav & Emerg Tech. 2019; 1:48–61.
- 13. Ботометр. ВОПРОСЫ-ОТВЕТЫ. 2019 [по состоянию на 24 июня 2019 г.]. https://botometer.iuni.iu.edu/#!/faq.
- 14. Фернквист Дж., Каати Л., Шредер Р.Политические боты и всеобщие выборы в Швеции. Международная конференция IEEE по информатике разведки и безопасности (ISI) 2018 г. ИЭЭЭ; 2018. С. 124–9.
- 15. Эчеверрия Дж., Кристофаро Э. де, Куртеллис Н., Леонтиадис I, Стрингини Г., Чжоу С. ЛОБО. Материалы 34-й ежегодной конференции по приложениям компьютерной безопасности. Нью-Йорк, штат Нью-Йорк, США: ACM; 2018. С. 137–46.
- 16. Креши С., Ди Пьетро Р., Петрокки М., Спогнарди А., Тескони М. Смена парадигмы социальных спам-ботов.В: Барретт Р., Каммингс Р., Агиштейн Э., Габрилович Э., редакторы. Материалы 26-й Международной конференции World Wide Web Companion — WWW ’17 Companion. Нью-Йорк, Нью-Йорк, США: ACM Press; 2017. С. 963–72.
- 17. Креши С., Ди Пьетро Р., Петрокки М., Спогнарди А., Тескони М. Социальные отпечатки пальцев: обнаружение групп спам-ботов с помощью поведенческого моделирования на основе ДНК. IEEE Trans Надежные и безопасные вычисления. 2017:1.
- 18. Ян К-С, Варол О, Хуэй П-М, Менцер Ф.Масштабируемое и универсальное обнаружение социальных ботов посредством выбора данных. АААИ. 2020; 34:1096–103.
- 19. Мацца М., Креши С., Аввенути М., Кватрочиокки В., Тескони М. РТбюст. В: Boldi P, Welles BF, Kinder-Kurlanda K, Wilson C, Peters I и др., редакторы. Материалы 10-й конференции ACM по веб-науке — WebSci ’19. Нью-Йорк, Нью-Йорк, США: ACM Press; 2019. С. 183–92.
- 20. Ораби М., Мухеб Д., Аль Агбари З., Камель И. Обнаружение ботов в социальных сетях: систематический обзор.Обработка информации и управление. 2020; 57:102250.
- 21. Дайя А.А., Салахуддин М.А., Лимам Н., Бутаба Р. BotChase: обнаружение ботов на основе графа с использованием машинного обучения. IEEE Trans Netw Serv Управление. 2020; 17:15–29.
- 22. Креши С. Десятилетие обнаружения социальных ботов. Коммунальный АКМ. 2020; 63:72–83.
- 23. Чавоши Н., Хамуни Х., Муин А. ДеБот: Обнаружение ботов в Твиттере с помощью искаженной корреляции. 2016 16-я Международная конференция IEEE по интеллектуальному анализу данных (ICDM).ИЭЭЭ; 12.12.2016–15.12.2016. стр. 817–22.
- 24. Хегелич С., Янецко Д. Являются ли социальные боты в Твиттере политическими акторами? Эмпирические данные украинского социального ботнета. Десятая международная конференция AAAI по Интернету и социальным сетям. АААИ Пресс; 2016.
- 25. Феррара Э., Варол О., Дэвис С., Менцер Ф., Фламмини А. Рост социальных ботов. Коммунальный АКМ. 2016; 59:96–104.
- 26. Лучери Л., Деб А., Джордано С., Феррара Э. Эволюция поведения ботов и человека во время выборов.Первый понедельник. 2019; 24. Доступно по ссылке: https://journals.uic.edu/ojs/index.php/fm/article/view/10213.
- 27. Горва Р., Гильбо Д. Распаковка бота для социальных сетей: типология для руководства исследованиями и политикой. Политика и Интернет. 2018; 40:420.
- 28. Менеджер социальных сетей. Список дескрипторов Twitter для членов Конгресса. 2017 [по состоянию на 27 февраля 2019 г.]. https://gwu-libraries.github.io/sfm-ui/posts/2017-05-23-congress-seed-list.
- 29. Рейтер М.Fälschen, züchten und verstärken: Fragwürdige Twitter-Tricks bei der AfD. 23.05.2019 [по состоянию на 27 июля 2020]. https://netzpolitik.org/2019/faelschen-zuechten-und-verstaerken-fragwuerdige-twitter-tricks-bei-der-afd/.
- 30. Халлиган С., Альтман Д.Г., Маллетт С. Недостатки использования площади под кривой рабочей характеристики приемника для оценки тестов визуализации: обсуждение и предложение альтернативного подхода. Евро Радиол. 2015 г.; 25:932–9. пмид: 25599932.
- 31. Дэвис Дж., Годрич М.Взаимосвязь между кривыми Precision-Recall и ROC. В: Коэн В., Мур А., редакторы. Материалы 23-й международной конференции по машинному обучению — ICML ’06. Нью-Йорк, Нью-Йорк, США: ACM Press; 2006. С. 233–40.
- 32. Лобо Дж. М., Хименес-Вальверде А., Реал Р. AUC: вводящая в заблуждение мера эффективности прогнозирующих моделей распределения. Глобальная экологическая биогеография. 2008 г.; 17:145–51.
- 33. Сайто Т., Ремсмейер М. График точного отзыва более информативен, чем график ROC, при оценке двоичных классификаторов на несбалансированных наборах данных.ПЛОС ОДИН. 2015 г.; 10:e0118432. пмид: 25738806.
- 34. Чикко Д. Десять быстрых советов по машинному обучению в вычислительной биологии. Биоданные Мин. 2017; 10:35. пмид:29234465
- 35. Чикко Д., Юрман Г. Преимущества коэффициента корреляции Мэтьюза (MCC) по сравнению с оценкой F1 и точностью в оценке бинарной классификации. Геномика BMC. 2020; 21:6. пмид:31898477.
- 36. Делонг Э.Р., Делонг Д.М., Кларк-Пирсон Д.Л. Сравнение площадей под двумя или более коррелированными кривыми рабочих характеристик приемника: непараметрический подход.Биометрия. 1988 год; 44:837. пмид:3203132
- 37. Sun X, Xu W. Быстрая реализация алгоритма Делонга для сравнения площадей под коррелированными кривыми рабочих характеристик приемника. IEEE Signal Process Lett. 2014; 21:1389–93.
- 38. Брэдшоу С., Ховард П.Н., Колланьи Б., Нойдерт Л.М. Поиск и автоматизация политических новостей и информации в социальных сетях в США, 2016–2018 гг. Политическая коммуникация. 2019; 15:1–21.
- 39. Брэдшоу С., Ховард П.Н.ГЛОБАЛЬНАЯ ОРГАНИЗАЦИЯ ДЕЗИНФОРМАЦИОННЫХ КАМПАНИЙ В СОЦИАЛЬНЫХ СЕТЯХ. Журнал международных отношений. 2018; 71:23–32. Доступно по адресу: https://www.jstor.org/stable/26508115.
- 40. Фейсбук. 20. Неискреннее поведение. 2020 [по состоянию на 27 июля 2020 г.]. https://www.facebook.com/communitystandards/inauthentic_behavior.
- 41. Кристенсен Г.С., Фриз Дж., Мигель Э. Прозрачное и воспроизводимое исследование социальных наук. Как заниматься открытой наукой / Гаррет Кристенсен, Джереми Фриз и Эдвард Мигель.Окленд, Калифорния: Издательство Калифорнийского университета; 2019.
- 42. Фернандес Д.М., Грациотин Д., Вагнер С., Сейбольд Х. Открытая наука в программной инженерии; 2019. https://arxiv.org/abs/1904.06499.
- 43. Сайядихариканде М., Варол О., Ян К.С., Фламмини А., Менцер Ф. Обнаружение новых социальных ботов ансамблями специализированных классификаторов. 2020 [по состоянию на 6 октября 2020 г.]. https://arxiv.org/abs/2006.06867.
- 44. Варгас Л., Эмами П., Трейнор П. Об обнаружении активности кампании по дезинформации с помощью сетевого анализа; 2020.https://arxiv.org/abs/2005.13466v1.
- 45. Хейс А.Ф., Криппендорф К. Ответ на призыв к стандартному показателю надежности для кодирования данных. Методы и меры коммуникации. 2007 г.; 1: 77–89.
- 46. Келлер Ф.Б., Шох Д., Стиер С., Ян Дж. Политический астротурфинг в Твиттере: как координировать кампанию по дезинформации. Политическая коммуникация. 2019; 63:1–25.
- 47. Кович М., Раухфлейш А., Селе М., Каспар С. Цифровой астротурфинг в политике: определение, типология и меры противодействия: исследования в области коммуникационных наук; 2018.
ENG Требования для получения степени бакалавра | Инженерный колледж
Посмотреть листы планирования программы бакалавриата
Посмотреть регистрационную информацию
Посмотреть информацию о внутриуниверситетском переводе на ENG
Требования к математике и естественным наукам
Все студенты бакалавриата инженеров должны набрать как минимум 30 кредитов курсовой работы по математике и естественным наукам. Конкретные требования в каждой из этих предметных областей описаны ниже:Математика
Требуются следующие четыре курса по расчету в колледже:
CAS MA 123 | Расчет I
CAS MA 124 | Исчисление II
CAS MA 225 | Многомерное исчисление
CAS MA 226 | Дифференциальные уравнения
Студенты в первом семестре обучения обычно записываются в CAS MA 123, Исчисление I, если они не имеют продвинутого кредита или перевода кредита по математическому анализу.
Учащимся с авансом или переводным зачетом по исчислению I рекомендуется использовать его для выполнения требования CAS MA 123. Такие учащиеся зачисляются в CAS MA 124, затем в CAS MA 225, а затем в CAS MA 226.
Студентам с авансовым или переводным кредитом по исчислению I и II рекомендуется использовать его для выполнения требований CAS MA 123 и CAS MA 124. Эти студенты зачисляются в CAS MA 225, а затем в CAS MA 226.
Учащимся, имеющим предыдущий опыт в области исчисления, но не получившим авансовый зачет или переводной зачет, рекомендуется сначала записаться на курс CAS MA 123.В исключительных обстоятельствах и с одобрения своего преподавателя такие студенты могут вместо этого начать с CAS MA 124. Эти студенты должны пройти технический курс с четырьмя кредитами, чтобы восполнить дефицит кредитов, который у них возникнет, если они пропустят MA 123.
Курсыс отличием по математическому анализу и дифференциальным уравнениям (CAS MA 230, CAS MA 231) являются приемлемой заменой для CAS MA 225 и CAS MA 226 соответственно.
Естественные науки
Все студенты бакалавриата должны пройти как минимум три курса естественных наук:
CAS CH 101 или 131 | Введение в химию
CAS PY 211 | Физика I
CAS PY 212 | Физика II
Студентам некоторых специальностей необходимо пройти дополнительные курсы по естественным наукам; см. конкретные учебные планы для каждой программы.Обратите внимание: студенты, которые не указали свою специализацию, но вообще рассматривают биомедицинскую инженерию как специализацию, должны зарегистрироваться в CAS CH 101 вместо CAS CH 131.
Учащиеся, желающие получить более глубокие знания по химии, могут записаться на один из следующих двухкурсов вместо последовательностей CAS CH 101 и CAS CH 102:
1. CAS CH 109 и CAS CH 110
2. КАС КХ 111 и КАС КХ 112
Учащиеся, желающие получить более глубокие знания в области физики, могут записаться на следующую последовательность из двух курсов вместо CAS PY 211 и CAS PY 212:
1. КАС ПИ 251 и КАС ПИ 252
Студенты, желающие получить более глубокие знания по физике, могут записаться на один из следующих курсов вместо CAS PY 313:
1. CAS PY 351 и CAS PY 352
Основные инженерные требования
Все программы бакалавриата на получение степени инженера требуют следующих основных инженерных курсов, охватывающих основные инженерные науки. Большинство из этих курсов завершаются на первом и втором курсе. ENG EK 103 | Вычислительная линейная алгебра (3 кредита)
(EK 102 для студентов, поступивших до осени 2018 г.)
ENG EK 125 | Programming for Engineers (4 кредита)
(EK 127 для студентов, поступивших до осени 2017 г.)
ENG EK 131 | Введение в инженерное дело (2 кредита)
ENG EK 210 | Введение в инженерное проектирование (2 кредита)
ENG EK 301 | Инженерная механика I (4 балла)
ENG EK 307 | Электрические цепи (4 кредита)
ENG EK 381 | Вероятность, статистика и наука о данных для инженеров (4 кредита)
(BE 200 для студентов BME, поступивших до осени 2017 г.; EC 381 для студентов ECE, поступивших до осени 2016 г.; ME 366 для студентов ME, поступивших до осени 2018 г. )
Требования BU Hub (для студентов, поступивших на первый курс осенью 2018 г. или позже)
Все учащиеся, поступающие на первый курс осенью 2018 г. и позже, будут проходить курсовую работу в BU Hub, общеобразовательной программе, которая интегрирована во все программы бакалавриата.Требования BU Hub (bu.edu/hub) являются гибкими и могут быть удовлетворены различными способами, посредством курсовой работы по специальности и за ее пределами, а в некоторых случаях и посредством дополнительных учебных занятий. Все студенты Инженерного колледжа должны пройти семинар первого года обучения письму (4 кредита) и семинар по письму, исследованиям и исследованиям (4 кредита) или эквивалентный им. Все требования BU Hub в отношении количественного мышления, коммуникации и набора интеллектуальных инструментов, а также в области научных исследований обычно удовлетворяются за счет требований инженерного колледжа и за счет обязательной курсовой работы по соответствующим специальностям.Щелкните здесь для получения информации о том, как эти единицы соотносятся с требованиями инженерной степени.
Учащимся необходимо пройти восемь дополнительных разделов по крайней мере в четырех факультативах Hub. Эти единицы:
- Философские исследования и смыслы жизни (1 ед.)
- Эстетическое исследование (1 шт.)
- Историческое сознание (1 ед.)
- Личность в сообществе (1 шт.)
- Глобальная гражданственность и межкультурная грамотность (2 единицы)
- Этическое обоснование (1 шт.)
- Social Inquiry (I или II, 1 блок)
Чтобы завершить четырехлетнее обучение без добавления каких-либо дополнительных курсовых/факультативных занятий Hub, важно, чтобы учащиеся поместили восемь дополнительных блоков Hub в четыре слота Hub по выбору, включенные в каждая программа на получение степени, что означает, что два модуля Hub должны быть завершены с каждым факультативным модулем Hub, и что каждый из восьми факультативных модулей Hub будет встречаться один и только один раз.Здесь вы можете искать курсы по школам/колледжам, количеству кредитов и/или конкретным единицам Hub.
Последовательность, описанная выше, может быть альтернативно выполнена путем участия в основной учебной программе CAS или Kilachand Honors College; для получения дополнительной информации об этих программах свяжитесь с офисом программ бакалавриата.
Требования к BU Hub (для переводных студентов, зачисленных осенью 2020 г. или позже)
Переводные студенты, поступающие осенью 2020 г. и позже, будут проходить курсовую работу в BU Hub, общеобразовательной программе, интегрированной в программу бакалавриата.Требования BU Hub (bu.edu/hub) являются гибкими и могут быть удовлетворены различными способами, посредством курсовой работы по специальности и за ее пределами, а в некоторых случаях и посредством дополнительных учебных занятий.Студенты проходят курсы BU, которые выполняют единицы в каждой из областей Hub, указанных ниже, и должны заработать все 10 единиц Hub, чтобы получить высшее образование. Эти блоки HUB следующие:
Здесь вы можете искать курсы по школам/колледжам, количеству кредитов и/или конкретным единицам Hub.
Общие образовательные требования (для учащихся, зачисленных до осени 2018 г., и переводных учащихся, зачисленных до осени 2020 г.)
Требования к общему образованию Инженерного колледжа предназначены для повышения эффективности коммуникации и лучшего понимания влияния инженерных решений в глобальном, экономическом, экологическом и/или социальном контексте.
Все студенты бакалавриата инженеров должны набрать как минимум 24 кредита по общеобразовательным курсам: последовательность из двух курсов письма, распределение из трех курсов по гуманитарным и общественным наукам; и общеобразовательный факультатив:
Требование к записи | 8 кредитов
Социальные и гуманитарные науки Распространение | 12 кредитов
Общее образование по выбору | 4 кредита
Последовательность общего образования, описанная выше, может быть альтернативно удовлетворена, участвуя в основной учебной программе CAS или Kilachand Honors College; для получения дополнительной информации об этих программах свяжитесь с офисом программ бакалавриата.
Требование к письму
Все студенты бакалавриата инженерного колледжа должны сдать экзамены CAS WR 120 и CAS WR 151, 152, 153 или эквивалентные им. Требование к письму может быть выполнено такой программой, как CAS Core Curriculum или Kilachand Honors College.
Требование к распространению социальных и гуманитарных наук
Все студенты бакалавриата инженерного колледжа должны набрать как минимум 12 кредитов (3 курса) по гуманитарным и социальным наукам, записавшись как минимум на один курс социальных наук и хотя бы на один курс гуманитарных наук.
Социальные науки : Социальные науки изучают индивидуальные отношения в обществе и с ним. Студенты должны пройти хотя бы один курс социальных наук. Курсы, отвечающие этому требованию, должны быть выбраны из утвержденного списка курсов социальных наук.
Гуманитарные науки : Гуманитарные науки — это отрасли знаний, связанные с людьми и их культурой. Студенты должны пройти хотя бы один курс гуманитарных наук. Курсы, отвечающие этому требованию, должны быть выбраны из утвержденного списка гуманитарных курсов.
Общеобразовательный факультатив
Общеобразовательный факультативный предмет позволяет учащимся познакомиться с областями обучения, выходящими за рамки социальных и гуманитарных наук, для дальнейшего расширения своего образования. Этот 4-х кредитный факультатив может быть удовлетворен соответствующей комбинацией 1-4-х кредитных курсов, которые включают, среди прочего, дополнительное письмо, социальные науки, гуманитарные науки, языки, изобразительное искусство. Курсы, отвечающие этому требованию, должны быть выбраны из утвержденного списка общеобразовательных курсов по выбору.Обратите внимание: лица, не являющиеся носителями английского языка, не могут использовать языковые курсы на своем родном языке для выполнения этого требования. Учащиеся, говорящие на двух языках или свободно владеющие языком, отличным от английского, не могут использовать курс разговорной речи на этом языке для выполнения этого требования. Если они не умеют читать или писать на своем втором языке, они могут использовать курс грамматики или сочинения для выполнения этого требования.
Учащиеся, которые переводят кредит из другого учебного заведения для выполнения любого из своих требований к общему образованию, могут столкнуться с недостатком кредита, если какой-либо из этих переведенных курсов составляет менее 4 кредитов.Учащиеся несут ответственность за восполнение любой нехватки кредитов по своим общеобразовательным курсам, чтобы набрать 24 необходимых кредита.
Несовершеннолетние, концентрации и специальные программы
Пожалуйста, имейте в виду, что несовершеннолетние, концентрации и специальные программы должны быть объявлены до закрытия весенней регистрации младшего года и подлежат официальному утверждению. Информацию о требованиях для этих программ можно найти здесь:Несовершеннолетние
Концентрации
Специальные программы
Петиции
Петиции — это просьбы об отклонении от требований к степени.Чтобы запросить отказ от академического регламента или требования, необходимо подать петицию. В петиции должно быть четко указано, что запрашивается, и причина(ы) запроса. Ходатайства следует обсуждать с консультантом факультета студента, требуя рекомендации и подписи консультанта. Пожалуйста, имейте в виду, что рекомендуется подавать ходатайство о замене курса до регистрации на этот курс. Заполненные петиции должны быть отправлены в (студенческий архив).Поданные петиции рассматриваются как соответствующим отделом, так и заместителем декана. Студенты обычно уведомляются о результатах в течение трех недель; необычные запросы могут занять больше времени. Формы петиций можно найти в соответствующем разделе здесь:Формы петиций
Предварительный кредит
Студенты бакалавриата по инженерным специальностям могут получить авансовый кредит, набрав квалификационный балл на соответствующем экзамене College Board AP. Студенты также могут получить кредит Международного бакалавриата, набрав квалификационный балл на соответствующем предметном экзамене.Во всех случаях экзамены AP или IB должны быть сданы до поступления в Бостонский университет. Чтобы просмотреть список расширенных кредитных курсов, ознакомьтесь с Расширенными руководствами по кредитам.
Учащиеся, сдавшие экзамены на расширенный кредит, должны иметь официальные отчеты о результатах CEEB, представленные в приемную комиссию, чтобы определить право на получение расширенного кредита. В случае присуждения кредита учащиеся должны подтвердить публикацию кредита в своей студенческой записи через ссылку для студентов.Обратите внимание: если студент решит записаться на тот же или эквивалентный курс, за который был присужден продвинутый кредит, дублирующие кредиты не будут применяться к степени. Курсы, пройденные в Бостонском университете, имеют приоритет перед кредитом AP. Первокурсники должны решить все сложные кредитные вопросы в течение 6 месяцев с момента первоначальной регистрации в Бостонском университете.
Дефицит кредитов
Когда студент выполнил все требования курса и учебной программы для программы на получение степени, но набрал меньше кредитов, чем требуется для получения степени (например,г., в связи с переводом курсов из другой школы), студент должен восполнить дефицит кредитов дополнительными курсовыми работами. Эта дополнительная курсовая работа не может включать PDP, курсы ниже требований степени и/или дублировать кредиты. С любыми вопросами обращайтесь в офис ENG Records ([email protected]).
Pre-Med Интерес
Студенты, которые заинтересованы в поступлении в области медицины, стоматологии, ветеринарии или других областях, связанных со здоровьем, после получения инженерной степени, должны связаться с предпрофессиональным консультационным бюро BU в начале своей карьеры в бакалавриате.Этот офис может проконсультировать по всем вопросам, касающимся профессиональных целей, учебной программы, требований для поступления в профессиональные школы и процесса подачи заявления. Офис также организует встречи для заинтересованных студентов на протяжении всего обучения и поддерживает обширную библиотеку доврачебной и медицинской карьеры. Студенты предмедицинского факультета BU также могут быть заинтересованы в программе MMEDIC.
Студенты подготовительных медицинских курсов должны помнить, что продвинутые кредиты (AP/IB/и т. д.) по основному научному курсу, как правило, не удовлетворяют требованиям домедицинского образования, поскольку медицинские школы предпочитают, чтобы научные требования выполнялись во время учебы в колледже.Если учащийся решит применить расширенный кредит для одного из этих курсов, ему рекомендуется пройти альтернативный курс более высокого уровня по той же дисциплине.
Минимальные требования для большинства медицинских программ:
1. 1 год биологии с лабораторией
2. 1 год общей химии с лабораторией
3. 1 год органической химии с лабораторией
4. 1-курс физики с лабораторией
5. 1-курс английского языка на уровне колледжа: сочинение и/или литература
6. 1 год изучения математики рекомендуется и требуется некоторыми школами
Кроме того, требования Инженерного колледжа по социальным и гуманитарным наукам могут быть использованы для выполнения предлагаемых учебных программ по психологии и социологии.
За дополнительной информацией обращайтесь в Консультационный отдел BU Pre-Professional:
100 Bay State Road, 4-й этаж
[email protected]
(617) 353-4866
Выпускные требования
Чтобы получить высшее образование, студенты должны выполнить все требования для получения степени для соответствующих программ получения степени.Кроме того, студенты должны иметь совокупный средний балл не ниже 2.00.Все учащиеся также должны соответствовать требованиям Hub или General Education, изложенным выше (в соответствии с годом, когда они поступили в BU), а также требованиям по математике, естественным наукам и ординатуре, описанным выше.
Требования к резидентуре: в дополнение к удовлетворению всех требований степени бакалавра наук, в Бостонском университете необходимо набрать не менее 48 кредитов курсовой работы по программе старшего отделения. Программа старших классов состоит из программных требований и/или факультативных программ, необходимых для специальности студента, как указано в листе планирования программы для младших и старших классов.Общеобразовательные занятия, факультативы Hub и / или курсы письма, пройденные в младших или старших классах, не могут учитываться в этом требовании. Требование о проживании должно быть выполнено в течение пяти лет, предшествующих официальной дате выпуска студента, за исключением военной службы.
Не более 12 кредитов с оценкой D могут применяться к курсовой работе по специальности (все курсы, кроме CAS WR 120, CAS WR 15x и четырех факультативов Hub). Четыре дополнительных кредита с оценкой D могут быть применены к CAS WR 120, CAS WR 15x и факультативам Hub.(Эта политика соответствует Политике университета в отношении оценок D для студентов бакалавриата.) Если курс повторяется для выполнения этого требования, оба курса включаются в расчет совокупного среднего балла.
Учащиеся, перешедшие на курсы из другого колледжа или университета и выполнившие все требования курса, но не набравшие необходимого количества кредитов для получения диплома, должны восполнить дефицит кредитов
Академический статус и список деканов
Академический статус каждого студента проверяется в конце каждого семестра.Неспособность добиться удовлетворительного прогресса и сохранить хорошую репутацию может привести к академическому испытательному сроку, отстранению от занятий на указанное время или до тех пор, пока не будут выполнены указанные условия, или увольнению, как подробно описано ниже. Определение GPI и GPA:
GPI или индекс оценок — это показатель за один семестр, рассчитываемый путем деления заработанных баллов на количество попыток зачетных единиц.
GPA или средний балл — это совокупный средний балл, рассчитанный по всем зачисленным семестрам.
Список декана
Лучшие 30% студентов каждого учебного года помещаются в список академических почетных званий декана каждый семестр. Студенты, включенные в список декана, должны достичь семестрового GPI не менее 3,0 по всем курсам, пройденным с не менее чем 12 академическими кредитными часами оцениваемой курсовой работы, и не иметь неполных, отсутствующих или невыполненных оценок.
Хорошая академическая успеваемость
Студенты очной формы обучения сохраняют хорошую академическую успеваемость, если они достигают всех трех из следующих условий:
(1) заработать не менее 12 академических кредитов в только что завершенном семестре
(2) получить GPI за семестр не менее 2.00
(3) поддерживать совокупный средний балл не менее 2,00
Примечание. Академические кредиты не включают кредиты PDP. Оценки за переводные баллы не учитываются в среднем балле. Неполные оценки не включаются в кредитные часы, используемые для определения хорошей академической успеваемости; студент с неполными оценками может быть помещен на академический испытательный срок, если выполненная курсовая работа падает ниже 12 кредитов. Неполные оценки также могут повлиять на право на получение финансовой помощи, а также на проживание в кампусе, если в семестре не набрано как минимум 12 кредитов.
Академический испытательный срок
Студент подвергается академическому испытательному сроку, если он/она находится в опасности недостаточного академического прогресса для получения степени, если его GPI или GPA ниже 2,00, или он не набрал 12 кредитов за семестр. Студенты проходят проверку после одного семестра на академическом испытательном сроке. Те, кто заработает GPI и GPA 2.00 или выше и наберет 12 кредитов в течение испытательного семестра, вернутся к Good Standing . Те учащиеся, которые не наберут Good Standing (как определено выше) в течение испытательного семестра, будут переведены на академическое отстранение , отчисление или на второй семестр академический испытательный срок , как определено школой или колледжем зачисления. .Студенты могут находиться на академическом испытательном сроке не более двух семестров подряд. Академический испытательный срок не запрещает учащимся участвовать во внеклассных мероприятиях или межвузовских спортивных состязаниях.
Студенты, которые в настоящее время находятся на академическом испытательном сроке и закончили летние курсы Бостонского университета, могут запросить пересмотр своей академической успеваемости в конце летней сессии. Такой обзор будет объединять летнюю сессию и предыдущий семестр зачисления учащегося в целях удовлетворения требований порога кредита, связанных с хорошей репутацией, а также для расчета GPI и GPA.
