
Свойства таблицы:общий обзор—Справка | ArcGIS Desktop
Таблицы являются основными объектами базы данных, которые используются для хранения данных, а также «данных о данных» (метаданных). В базе геоданных также имеются системные таблицы, которые хранят информацию о других таблицах, записях и индексах в базе геоданных. Эти таблицы называют таблицами метаданных (metadata table) или таблицами репозитория (repository table).
В базе геоданных существуют также классы таблиц, которые работают вместе для хранения специфических типов пространственных данных. Например, классы пространственных объектов хранят информацию о пространственных объектах. Они состоят из нескольких таблиц, что определяется тем, какую СУБД вы используете для их хранения, и являются ли они версионными. Эти таблицы пространственных данных помимо наличия пространственных свойств имеют те же самые свойства, что и непространственные таблицы.
Свойства обычной таблицы
- Таблицы управляют атрибутами.
 Это означает, что они хранят информацию. В базе геоданных таблицы обычно хранят информацию о географических объектах.
Это означает, что они хранят информацию. В базе геоданных таблицы обычно хранят информацию о географических объектах. - Таблицы содержат строки. Каждая строка представляет собой одну запись. В пространственной таблице одна строка соответствует одному объекту.
- Все строки в таблице имеют одни и те же столбцы. Столбцы также называются полями. Они представляют собой категории содержащейся в таблице информации, например, имена, площади, состояния или номера ID.
- У каждого поля есть тип данных и имя.
Свойства пространственной таблицы
(Эти свойства дополняют свойства обычных таблиц).
- Пространственные таблицы обладают координатами x,y.
- Пространственные таблицы могут содержать координаты измерений (m-) и z-координаты.
- У пространственных таблиц может быть пространственная привязка. В них содержится информация о системе координат, x,y допуске, z- и/или m-допуске (если присутствуют z- и/или m-координаты) и разрешении.
- Пространственные таблицы хранят конкретный тип пространственных объектов — полигон, линию, точку, мультиточку, мультипатч, объект-размер или аннотацию.

Вы можете определять имена таблиц, имена полей и типы данных, когда вы используете ArcGIS для создания таблиц в базе геоданных. Для некоторых пространственных таблиц, например, для класса пространственных объектов, вы также можете определить, будут ли присутствовать m- и z-координаты, определить систему координат, значения допуска, а также тип данных, которые в них будет храниться.
Примечание:
Вы можете использовать контекстные меню в ArcCatalog или использовать инструменты геообработки из ArcToolbox для создания новых таблиц или классов пространственных объектов. Основным различием между использованием мастеров и инструментов геообработки заключается в том, что когда вы используете мастер, вы можете добавить имена полей и определить типы данных. При использовании инструментов геообработки вы не можете создать новые поля; вы можете импортировать пустые поля из существующей таблицы, а новые поля должны быть определены после создания таблицы или класса пространственных объектов.
Связанные разделы
Общие сведения о таблицах
Таблицы — это неотъемлемая часть любой базы данных, так как именно в них содержатся все сведения и данные. Например, база данных предприятия может содержать таблицу «Контакты», в которой хранятся имена всех поставщиков, их адреса электронной почты и номера телефонов. Так как другие объекты базы данных в значительной степени зависят от таблиц, всегда начинайте разработку базы данных с создания всех таблиц, а уже затем создавайте другие объекты. Перед созданием таблиц проанализируйте свои требования и определите, какие именно таблицы могут вам понадобиться. Начальные сведения о планировании и разработке баз базы данных см. в статье Основные сведения о создании баз данных.
В этой статье
Обзор
Обычно реляционная база данных, такая как Access, состоит из нескольких таблиц. В хорошо спроектированной базе данных в каждой таблице хранятся сведения о конкретном объекте, например о сотрудниках или товарах.
-
Запись. Содержит конкретные данные, например информацию об определенном работнике или продукте.
-
Поле. Содержит данные об одном аспекте элемента таблицы, например имя или адрес электронной почты.
-
Значение поля. Каждая запись содержит значение поля, например Contoso, Ltd. или [email protected].
К началу страницы
Свойства таблиц и полей
У таблиц и полей также есть свойства, которые позволяют управлять их характеристиками и работой.
1. Свойства таблицы
 Свойства поля
Свойства поля
В базе данных Access свойствами таблицы называются атрибуты, определяющие ее внешний вид и работу. Свойства таблицы задаются на странице свойств таблицы в Конструкторе. Например, вы можете задать для таблицы свойство Режим по умолчанию, чтобы указать, как она должна отображаться по умолчанию.
Свойство поля применяется к определенному полю в таблице и определяет его характеристики или определенный аспект поведения. Некоторые свойства поля можно задать в Режим таблицы. Вы также можете настраивать любые свойства в Конструкторе с помощью области </c0>Свойства поля.
Типы данных
У каждого поля есть тип данных. Тип данных поля определяет данные, которые могут в нем храниться (например, большие объемы текста или вложенные файлы).
Тип данных является свойством поля, однако он отличается от других свойств:
-
Тип данных поля задается на бланке таблицы, а не в области Свойства поля.

-
Тип данных определяет, какие другие свойства есть у этого поля.
-
Тип данных необходимо указывать при создании поля.
Чтобы создать новое поле в Access, введите данные в новый столбец в режиме таблицы. В таком случае Access автоматически определяет тип данных для поля в зависимости от введенного значения. Если оно не относится к определенному типу, Access выбирает текстовый тип. При необходимости его можно изменить с помощью ленты.
Примеры автоматического определения типа данных
Ниже показано, как выполняется автоматическое определение типа данных в режиме таблицы.
|
 67
67
К началу страницы
Отношения между таблицами
Хотя в каждой из таблиц хранятся данные по отдельному объекту, в базе данных Access все они обычно связаны между собой.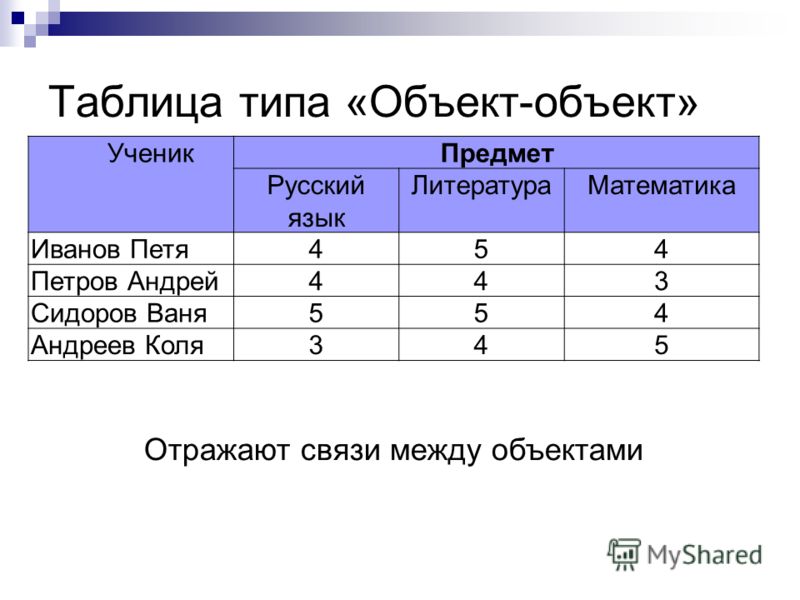 Ниже приведены примеры таблиц в базе данных.
Ниже приведены примеры таблиц в базе данных.
-
Таблица клиентов, содержащая сведения о клиентах компании и их адреса.
-
Таблица продаваемых товаров, включающая цены и изображения каждого из них.
-
Таблица заказов, служащая для отслеживания заказов клиентов.
Так как данные по разным темам хранятся в отдельных таблицах, их необходимо как-то связать, чтобы можно было легко комбинировать данные из разных таблиц. Для этого используются связи. Связь — это логическое отношение между двумя таблицами, основанное на их общих полях. Дополнительные сведения см. в статье Руководство по связям между таблицами.
К началу страницы
Ключи
Поля, формирующие связь между таблицами, называются ключами. Ключ обычно состоит из одного поля, однако может включать и несколько. Есть два вида ключей.
Ключ обычно состоит из одного поля, однако может включать и несколько. Есть два вида ключей.
-
Первичный ключ. В таблице может быть только один первичный ключ. Он состоит из одного или нескольких полей, однозначно определяющих каждую запись в этой таблице. Часто в качестве первичного ключа используется уникальный идентификатор, порядковый номер или код. Например, в таблице «Клиенты» каждому клиенту может быть назначен уникальный код клиента. Поле кода клиента является первичным ключом этой таблицы. Если первичный ключ состоит из нескольких полей, он обычно включает уже существующие поля, формирующие в сочетании друг с другом уникальные значения. Например, в таблице с данными о людях в качестве первичного ключа можно использовать сочетание фамилии, имени и даты рождения. Дополнительные сведения см. в статье Добавление и изменение первичного ключа таблицы.
-
Внешний ключ.
 В таблице также может быть один или несколько внешних ключей. Внешний ключ содержит значения, соответствующие значениям первичного ключа другой таблицы. Например, в таблице «Заказы» каждый заказ может включать код клиента, соответствующий определенной записи в таблице «Клиенты». Поле «Код клиента» является внешним ключом таблицы «Заказы».
В таблице также может быть один или несколько внешних ключей. Внешний ключ содержит значения, соответствующие значениям первичного ключа другой таблицы. Например, в таблице «Заказы» каждый заказ может включать код клиента, соответствующий определенной записи в таблице «Клиенты». Поле «Код клиента» является внешним ключом таблицы «Заказы».
Соответствие значений между полями ключей является основой связи между таблицами. С помощью связи между таблицами можно комбинировать данные из связанных таблиц. Предположим, есть таблицы «Заказчики» и «Заказы». В таблице «Заказчики» каждая запись идентифицируется полем первичного ключа — «Код».
Чтобы связать каждый заказ с клиентом, вы можете добавить в таблицу «Заказы» поле внешнего ключа, соответствующее полю «Код» в таблице «Заказчики», а затем создать связь между этими двумя ключами. При добавлении записи в таблицу «Заказы» можно было бы использовать значение кода клиента из таблицы «Заказчики». При просмотре каких-либо данных о клиенте, сделавшем заказ, связь позволяла бы определить, какие данные из таблицы «Заказчики» соответствуют тем или иным записям в таблице «Заказы».
При просмотре каких-либо данных о клиенте, сделавшем заказ, связь позволяла бы определить, какие данные из таблицы «Заказчики» соответствуют тем или иным записям в таблице «Заказы».
1. Первичный ключ, который определяется по значку ключа рядом с именем поля.
2. Внешний ключ (определяется по отсутствию значка ключа)
Если ожидается, что для каждого представленного в таблице уникального объекта потребуется несколько значений поля, такое поле добавлять не следует. Обратимся к приведенному выше примеру: если нужно отслеживать размещенные клиентами заказы, не следует добавлять поле в таблицу, поскольку у каждого клиента будет несколько заказов. Вместо этого создается новая таблица для хранения заказов, а затем создаются связи между этими двумя таблицами.
К началу страницы
Преимущества использования связей
Раздельное хранение данных в связанных таблицах обеспечивает указанные ниже преимущества.
-
Согласованность . Поскольку каждый элемент данных заносится только один раз в одну таблицу, вероятность появления неоднозначных или несогласованных данных снижается. Например, имя клиента будет храниться только в таблице клиентов, а не в нескольких записях в таблице заказов, которые могут стать несогласованными.
-
Эффективность . Хранение данных в одном месте позволяет сэкономить место на диске. Кроме того, данные из небольших таблиц извлекаются быстрее, чем из больших. Наконец, если не хранить данные по различным темам в разных таблицах, возникают пустые значения, указывающие на отсутствие данных, или избыточные данные, что может привести к неэффективному использованию места и снижению производительности.
-
Простота . Структуру базы данных легче понять, если данные по различным темам находятся в разных таблицах.
Связи между таблицами необходимо иметь в виду еще на этапе планирования таблиц. С помощью мастера подстановок можно создать поле внешнего ключа, если таблица с соответствующим первичным ключом уже существует. Мастер подстановок помогает создать связь. Дополнительные сведения см. в статье Создание и удаление поля подстановки.
К началу страницы
Создание таблицы и добавление полей
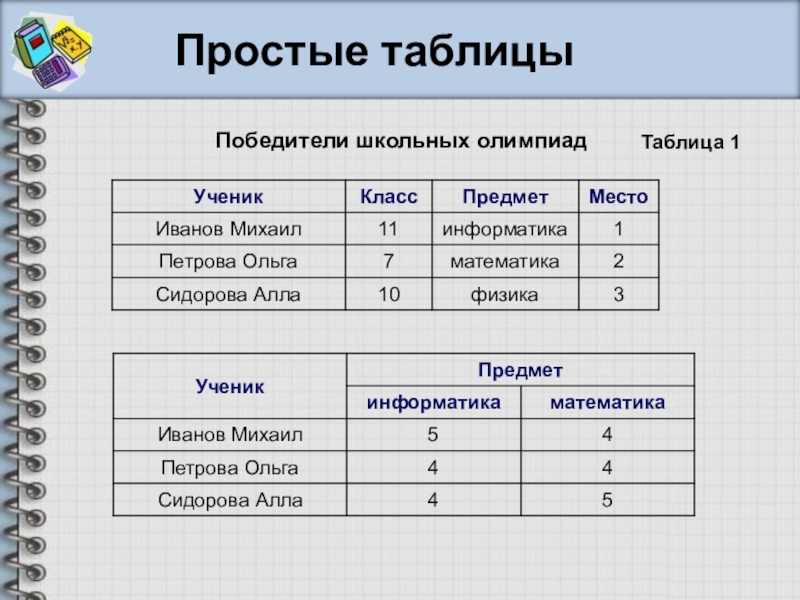
Табличные информационные модели. Типы таблиц
Объект — предмет исследования.Класс объектов — множество объектов, объединенных какими-то общими свойствами.
Свойства — характеристики, признаки объекта.
Каждое свойство объекта имеет название и значение.
Свойства, характеризующие только один объект, называются одиночными.
Свойства, характеризующие сразу пару объектов, называются парными.
Типы таблиц
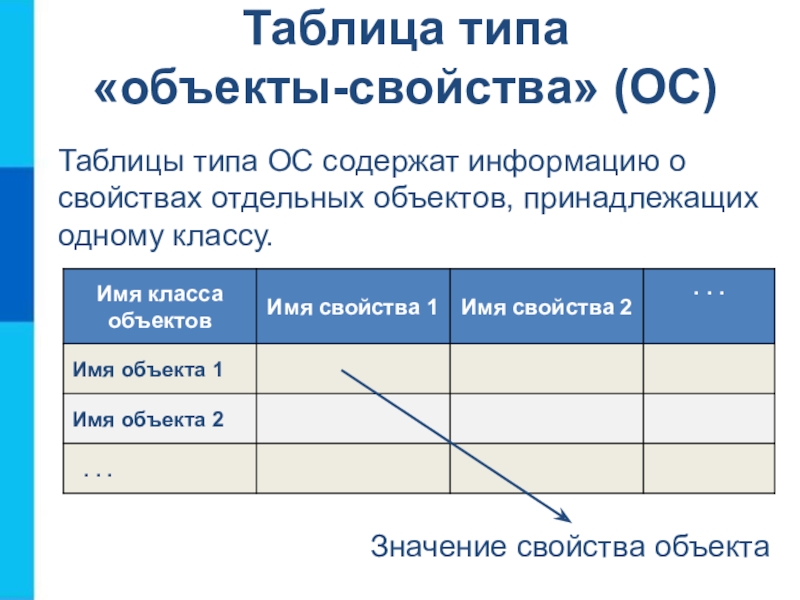
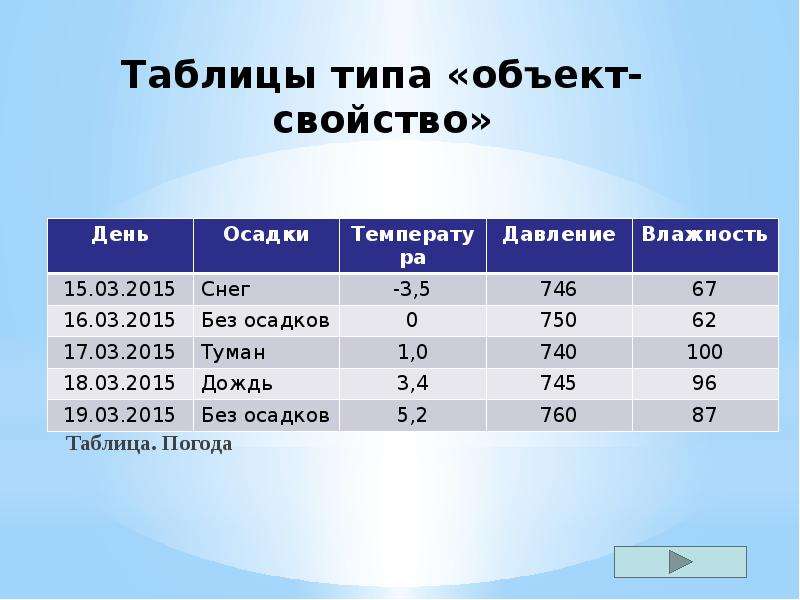
Таблицы типа «объекты — свойства» (ОС)
Если
— рассматриваются отдельные объекты (все свойства относятся не к группе объектов, а к какому-то одному объекту) и
— все объекты принадлежат одному классу.

Порядок построения таблицы типа «Объекты — свойства»
1) Выделить объекты, свойства и значение свойства (для удобства подчеркнуть разными цветами или разными линиями).
2) Назвать класс объектов. Название записать в заголовок таблицы и в заголовок боковика.
3) Названия объектов записать в боковик.
4) Названия свойств записать в головку.
5) Значения свойств записать в прографку.
Таблица типа ОС может быть «перевернута на бок», т.е. строки превращены в графы, а графы — в строки.
Рекомендация. Таблица, в которой много строк и мало граф (столбцов), удобнее, чем таблица, содержащая мало строк, но много графов (столбцов).
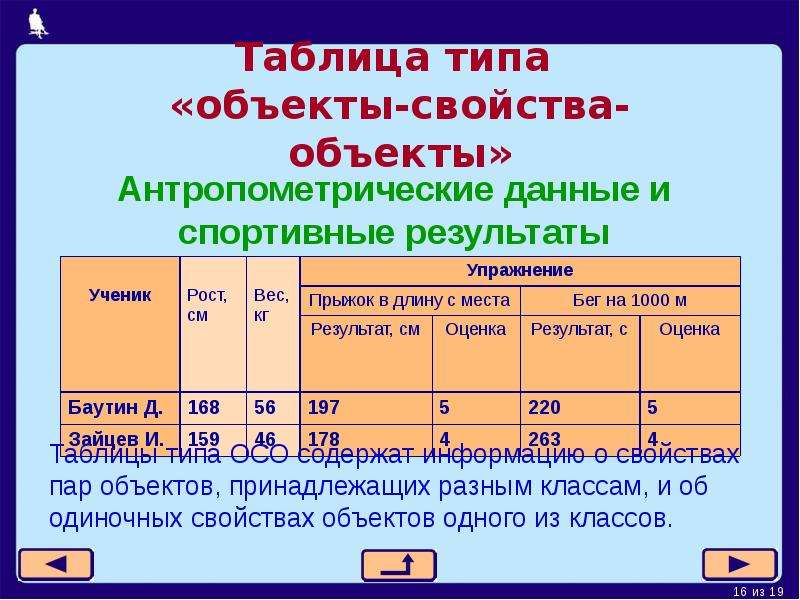
Таблицы типа «объекты — объекты» (ОО)
Если
— описываются пары объектов (свойства характеризуют не один объект, а пару) и
— свойство только одно.
Пример
Алгоритм построения таблицы типа ОО
1) Выделить объекты и свойства.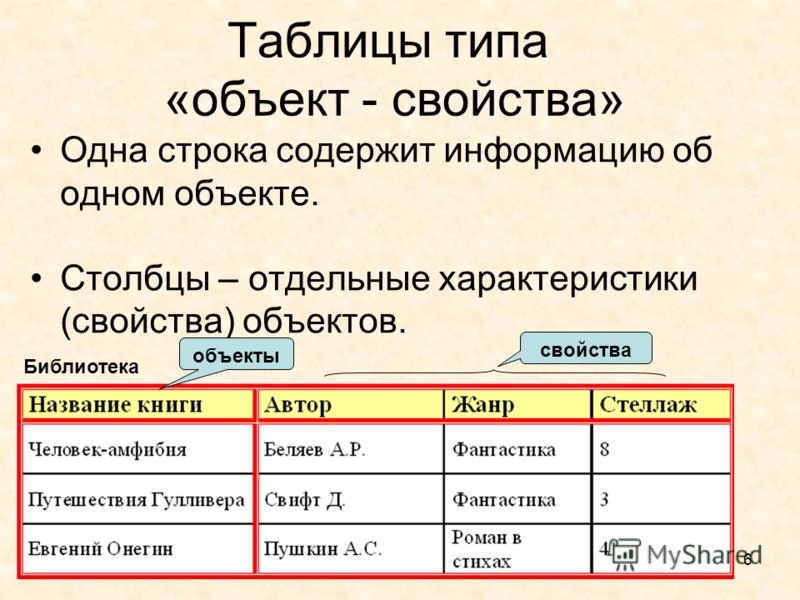
2) Название свойства записать в заголовок таблицы.
3) Назвать класс первых объектов в паре. Название записать в заголовок боковика.
4) Назвать класс вторых объектов в паре. Название записать в верхний ярус головки.
5) Названия первых объектов записать в боковик.
6) Названия вторых объектов записать в нижний ярус головки.
7) Заполнить таблицу.
Таблица типа ОО может быть «перевернута на бок» — строки превращены в графы, а графы — в строки.
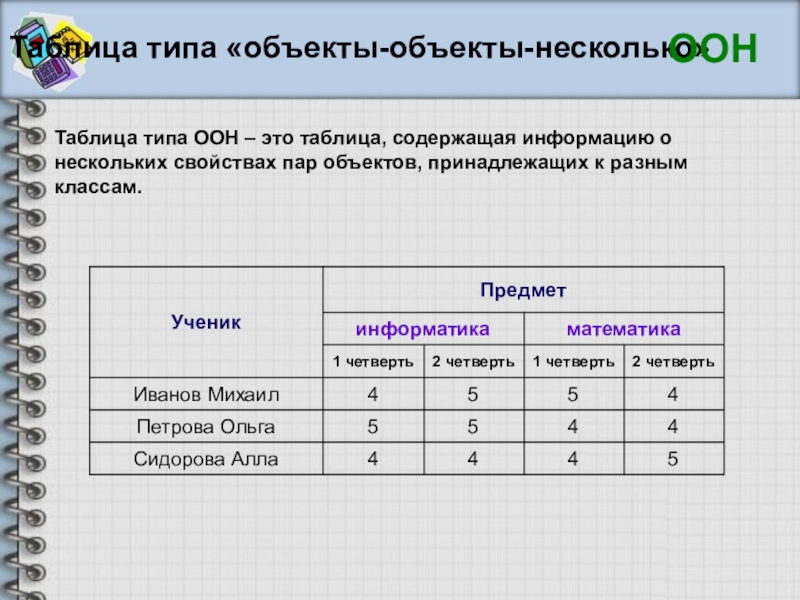
Таблицы типа «объекты — объекты — несколько» (ООН)
Если
— описывают пары объектов (свойства характеризуют не один объект, а пару) и
— свойств пары объектов несколько и
— других свойств нет.
Алгоритм построения таблицы типа ООН
1) Выделить объекты и свойства.
2) Название свойств записать в заголовок таблицы.
3) Назвать класс первых объектов в паре. Название записать в верхний ярус боковика.
4) Назвать класс вторых объектов в паре. Название записать в верхний ярус головки.
5) Названия первых объектов записать в боковик.
6) Названия вторых объектов записать в средний ярус головки.
7) Названия свойств записать в нижний ярус головки, повторив их для каждого объекта из среднего яруса.
8) Значения свойств записать в прографку.
Пример
Таблица типа ООН может быть «повернута набок». Поворот может качаться только объектов, а может — всей головки.
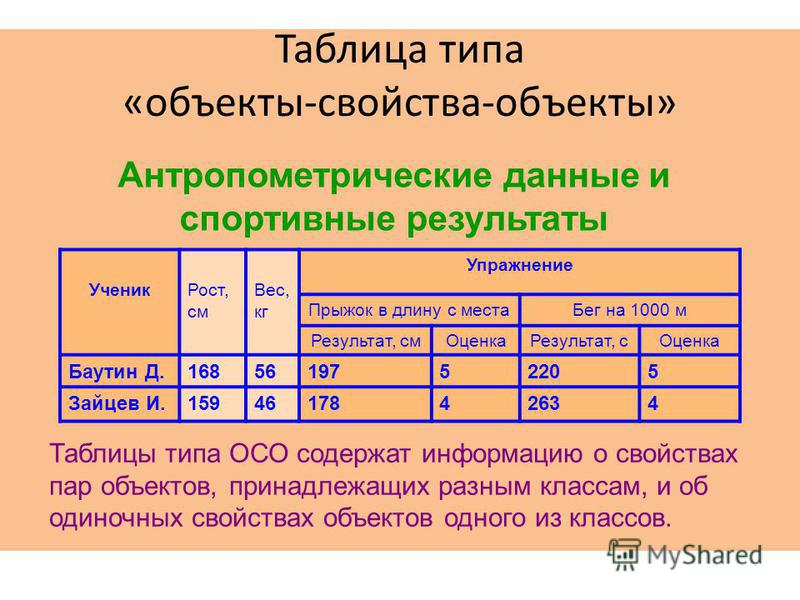
Таблицы типа «объекты — свойства — объекты» (ОСО)
Если
— описываются пары объектов (существуют свойства, которые характеризуют не один объект, а пару объектов) и
— существуют свойства, которые характеризуют только один объект в паре и
— нет свойств, которые характеризуют только другой объект в паре.
Пример
Таблица ОСО строится следующим способом. Берется таблица типа «объекты — объекты» и раздвигается: прографка «отодвигается» от боковика и в освободившееся место вставляются новые графы со свойствами, которые относятся только к объектам, которые «командуют» строками, но не относятся к объектам, которые «командуют» графами.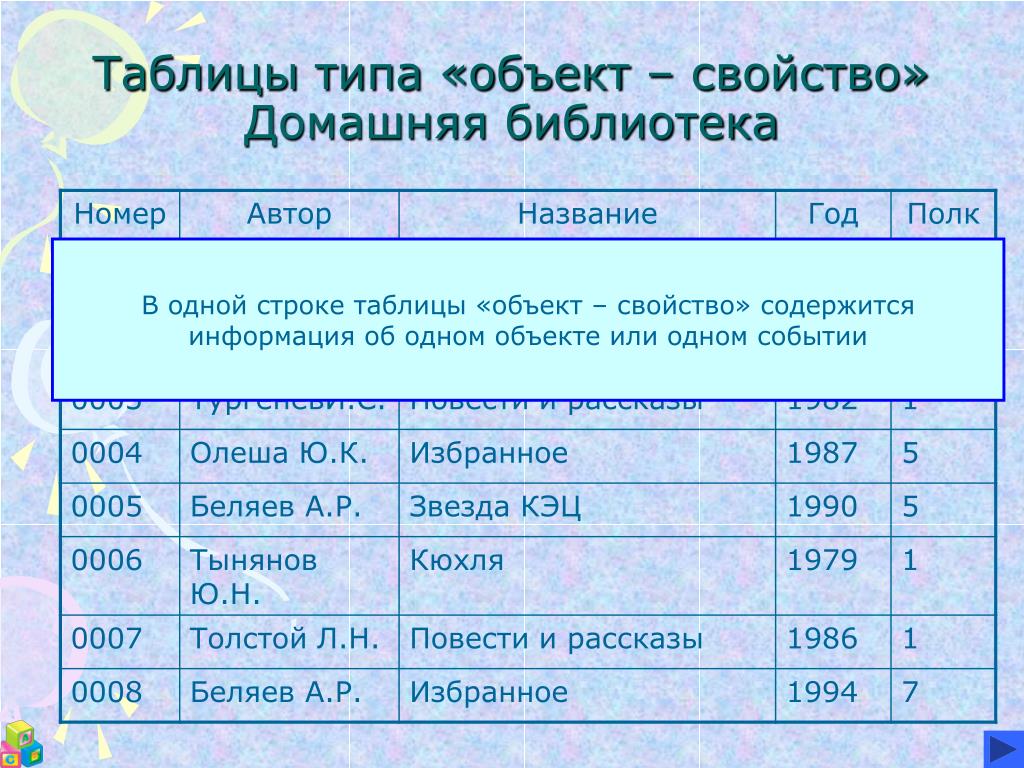
Порядок построения таблицы типа ОСО
1) Выделить объекты и свойства..
2) Название парных свойств записать в заголовок таблицы.
3) Определить и назвать класс объектов, для которых указаны одиночные свойства. Название этого класса записать в заголовок боковика.
4) Названия одиночных свойств записать в головку рядом с заголовком боковика. Каждое свойство записывается в отдельную графу. В оставшейся части таблицы (правее одиночных свойств) головка будет трехярусной. Будем называть эту часть таблицы III частью.
5) Назвать класс объектов, для которых указаны только парные свойства, но не указаны одиночные. Название записать в верхний ярус головки в III части таблицы.
6) Названия объектов первого класса записать в боковик.
7) Названия объектов второго класса записать в средний ярус головки в III часть таблицы.
8) Названия парных свойств записать в нижний ярус головки в III часть таблицы, повторив их для каждого объекта из среднего яруса.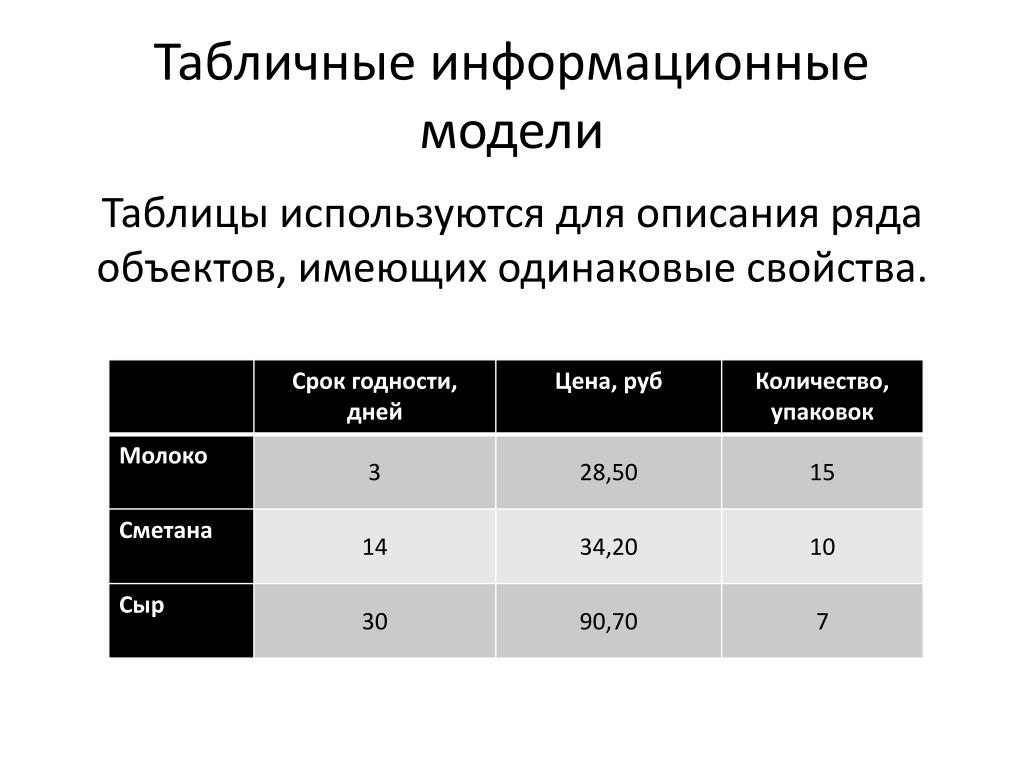
9) Заполнить таблицу.
Таблицы типа ОСО нельзя «повернуть на бок».
Информационные объекты или причина одного заблуждения / Хабр
Введение
В
прошлой статьемы рассмотрели понятие
функциональный объекти посмотрели, как моделируются его части. Сегодня я хочу рассказать про то, как в логической парадигме трактуется
информационный объект, и что из этого следует. Помимо этого, мы увидим, как родилось одно занятное заблуждение: идея о том, что термины
объекти
экземпляр объектаякобы указывают на разные объекты предметной области. И поймем причины этого заблуждения.
Термины
Сразу замечу, что я не претендую на их правильность. Беда в том, что мне не удалось найти согласованных определений модели и информации ни в одном из словарей. Поскольку область психических функций человека — не моя стихия, то я, скорее всего, не знаю точных определений этих терминов. Однако мне важно было подчеркнуть ту мысль, что информация и модель – это то, что существует в воображении у субъекта, а в объектной реальности – только их представления. Поэтому я ввожу рабочие определения, не претендуя на их точность.
Поэтому я ввожу рабочие определения, не претендуя на их точность.
- Модель – это то, что каким-то образом отвечает на вопросы об интересующем нас объекте и иметь разную степень детализации. Даже название будет нами считаться моделью, потому что оно несет важную информацию об объекте. Оно говорит о том, что объект существует.
- Информация – это модель какой-то части реальности, существующая в сознании людей (человека).
- Информационный объект – это представление модели в материальном виде, необходимом для хранения информации и передачи ее другим людям.
Примеры информационных объектов
Модели существуют только в сознании людей, но обмен моделями происходит, как правило, при помощи физических объектов, исполняющих роль информационных (мы рассматриваем общепринятые европейские способы передачи информации, и не рассматриваем мистические). Эти физические объекты называются представлениями информации, или представлениями модели.
Напомню, что мы работаем в 4-Д пространстве, где объекты существуют во времени, а время не существует без объектов. Примером информационных объектов могут быть Договор, Билет, Рекламный щит, Купюра, Книга, Электрические напряжения на выводе контактной группы, Произнесенная речь, Фильм. Например, речь – это звуковые колебания, поэтому тоже является физическим 4-Д объектом. С каждым годом количество физических объектов, которые были созданы с единственной целью — нести информацию, становится все больше и больше. В первобытном обществе количество информации, передаваемой от субъекта к субъекту, было небольшим. Сейчас это огромный поток. Однако даже сейчас природа информационных объектов для многих остается тайной. Я предлагаю попробовать разобраться с этим вопросом.
В мире мы работаем исключительно с информационными объектами, которые есть лишь представления моделей, но не сами модели. Это отличие ввел в употребление стандарт ИСО 15926, чтобы различить модель в головах от ее представления в виде материального носителя. Хотя очень часто модель в головах и информационный объект мы не различаем и называем одним именем – модель.
Хотя очень часто модель в головах и информационный объект мы не различаем и называем одним именем – модель.
Например, купюра – есть информационный объект, который призван хранить информацию о том, что может себе позволить сделать владелец этой купюры. И это не обязательно возможность совершать покупку товара в магазине. Это также может быть возможность совершать какие-то другие действия. Информация о том, что может позволить себе владелец существует у нас в головах, сама купюра – лишь представляет эту информацию в виде материального объекта. Сама бумажка в отрыве от социального соглашения по ее поводу не имеет никакой ценности. Для того чтобы купюра имела ценность, должна существовать некая общепризнанная модель в головах людей, составляющих некую социальную группу. В этом проявляется ее информационная природа. С другой стороны, сама бумажка – есть физический объект. Эта бумажка вполне может стать причиной гибели мухи, если воспользоваться купюрой как мухобойкой. Кстати, тогда бумажка исполнит роль функционального объекта мухобойка.Это будет означать, что одни и те же атомы бумаги в одно и то же время исполняли роль и информационного объекта и функционального. Но это еще не все. Пусть у вас есть купюра и пусть эта купюра порвалась. Вы идете в банк, и вам дают взамен утратившей свой внешний вид купюры новую купюру. Информация о том, что позволительно Вам, не изменилась. Носитель же этой информации изменился. Следовательно, много информационных объектов могут представлять одну модель.
Со всем этим пересечением объектов должна была справиться логическая парадигма, которая пришла на смену Аристотелевской логике.
Другой пример. Пусть есть договоренность между двумя юридическими лицами. Моделью этой договоренности является модель в головах у тех, кто участвовал в достижении этой договоренности. Представлением этой модели является бумажный документ, на котором стоят подписи должностных лиц. Таких бумажных документов может быть множество: как минимум два — по одному на каждую сторону. Вопрос: эти два бумажных документа есть один объект, или два? Вопрос, кажущийся простым, оказывается очень сложным для современных аналитиков.Мы вернемся к нему чуть позже.
Что хранится в базе данных?
Информационный объект – это объект, который хранит информацию об объектах (в том числе об информационных объектах). В базе данных хранятся только информационные объекты. Эти объекты являются объектами в виде намагниченных доменов, например. Они призваны хранить информацию о других объектах. О чем хранят информацию те объекты, которые в базах данных называются договор и накладная? О договорах и о накладных? Тогда это будет значить, что в системе хранятся информационные объекты, которые хранят информацию о других информационных объектах – договорах и накладных. Или о реальных договоренностях и о реальных поставках? Тогда это будет значить, что в системе хранятся информационные объекты, которые хранят информацию о реальных объектах: договорах и поставках. О чем они на самом деле хранят информацию? Разобраться в этих вопросах очень непросто. Возможно, в одной из статей я расскажу про то, как информация о разных частях предметной области, перемешиваясь с информацией о других ее частях и информацией об информационных объектах, «размазывается» по структуре данных. И о причинах, по которым это происходит.
И о причинах, по которым это происходит.
4 модели для создания информационного объекта
Давайте посмотрим, какие модели нам нужны для создания модели договоренности (у себя в голове).
- Модель договоренности опирается на отраслевые нормы и правила. В этих правилах зафиксированы те термины, которые необходимо использовать при создании модели договоренности, те события, которые необходимо оговорить сторонам (поставку деталей), и те события, которые наступят независимо от того, будут они прописаны в договоре или нет (подписание накладных, например). Эти нормы – модель 1 (ее еще можно назвать контекстом). Этими моделями владеют юристы и бухгалтера. Представлены они в законодательных актах.
- На основе модели 1 мы создаем модель 2 — модель самой договоренности.
- Теперь необходимо модель договоренности зафиксировать в виде представления, то есть, на материальном носителе. Какие модели необходимо знать, чтобы сделать это? Для этого нам понадобится иметь модель, которая описывает, как модель договоренности должна быть представлена.
 Эту информацию можно найти в специальной нормативной документации. Это – модель 3.
Эту информацию можно найти в специальной нормативной документации. Это – модель 3. - И четвертое – надо знать, как мы будем различать договора, которые моделируют одну договоренность (Различные экземпляры договора) – модель 4.
Имея эти четыре модели, мы можем создать конкретное представление модели 2 конкретной договоренности (экземпляр договора). Используемые термины, связи между ними, события по умолчанию будут взяты из модели 1, юридические реквизиты и прочие данные – из модели 2, структура текста и его оформление – из модели 3, учет подписанных экземпляров – из модели 4. Итого 4 модели необходимы, чтобы создать один экземпляр договора. Две из них относятся к модели предметной области. А две – к представлению модели. Такое деление на модели является универсальным для представления любого информационного объекта. Если у вас есть информационный объект, ищите 4 модели, которые лежат всегда где-то рядом.
Разница между терминами объект и экземпляр объекта
Так, все-таки, разные бумажки с печатями – это разные объекты или одинаковые? Последнее время я слышу такой ответ: это один объект, но экземпляры этого объекта – разные! Причину, по которой произошла деформация, приведшая к такого рода ответу, нам следует выяснить.
История:Сидит напротив меня бизнес-аналитик и просто человек с улицы. Я показываю аналитику операцию: подношу ко рту чашку чая и делаю глоток. Спрашиваю аналитика: «Можно ли назвать это операцией?» — Да, конечно. Тогда я повторяю те же действия и спрашиваю аналитика: Можно ли назвать и это действие операцией? Ответ утвердительный. Я спрашиваю: а это разные операции, или одна? Аналитик бодро отвечает: одна, конечно! Операция одна, а экземпляров ее много. Человек с улицы немного двинул бровь. Тогда я спрашиваю далее: Перед нами 100 спортсменов все как один в одних трусах и майках. Это один спортсмен, или много спортсменов? Ответ: много спортсменов? А что у них общего спрашиваю я. Внешний вид у них — общий, был ответ. Хорошо, а почему тогда операция-то одна? Аналитик задумался. Я поясняю: операций много, но внешний вид у них одинаковый! Правильно? Сомнения… Тогда я продолжаю: у них общее описание, а операции разные. Ну конечно! Описание операции — одно, а операций, удовлетворяющих этому описанию — много.

Если задуматься, то ответ аналитика кажется стороннему наблюдателю нелепым. Проверено! Однако к этой трактовке часто прибегают современные аналитики, и это стало похоже на заблуждение, принявшее массовый характер. Я все чаще слышу тезис о том, что надо различать термины
договори
экземпляр договора, например. При этом авторы этих тезисов так и не смогли мне объяснить, чем эти термины отличаются. Они намекали, что два термина указывают на совершенно разные объекты, но в какой парадигме термины экземпляр договора и договор указывают на разные объекты, мне так и не сказали. Я считаю это очень серьезным заблуждением и попытаюсь объяснить причины его возникновения.
В логике Аристотеля, у которого мы позаимствовали слово экземпляр, термины рыба и экземпляр рыбы – это обозначения одного и того же объекта. При этом я сознательно не говорю, что экземпляр – это термин. Слово экземпляр в логике Аристотеля неотделимо от второго слова, образую вместе с ним неделимый термин. Однако, за пределами логики Аристотеля термины рыба и экземпляр рыбы, указывая нам на один и тот же объект (рыбу), тем не менее, отличаются друг от друга. Вопрос чем?
Однако, за пределами логики Аристотеля термины рыба и экземпляр рыбы, указывая нам на один и тот же объект (рыбу), тем не менее, отличаются друг от друга. Вопрос чем?
Мы должны выяснить, чем они отличаются, и откуда в головах появилась мысль о том, что эти термины отличаются чем-то иным. Разобраться в этом меня подвигла задача описания имитационного моделирования бизнес-систем. О том, с какими терминологическими трудностями я столкнулся, и как пришлось их преодолевать – рассказать можно лишь в отдельной книге. Сейчас же я сконцентрируюсь только на одном вопросе: что такое объект и что такое экземпляр объекта?
Пусть есть высказывание: «я держу экземпляр книги «Три мушкетера». Оно интерпретируется следующим образом:
- Есть тип книг «Три мушкетера», и есть конкретный экземпляр этого типа объектов – конкретная книга. Слово экземпляр дает нам строгое указание на используемый нами контекст. Контекстом будет логика Аристотеля, или филологи используют термин интенсиональный контекст.

Однако данное высказывание может быть сокращено до следующего: «Я держу книгу «Три мушкетера». Это высказывание может интерпретироваться уже двумя способами:
- Можно сказать, что объект, который я держу в руках, имеет свойство. Это свойство объекта — быть книгой под названием «Три мушкетера (логика Аристотеля, или интенсиональный контекст). Данная трактовка совпадает с той трактовкой, которую порождает термин экземпляр книги.
- А можно сказать, что перед нами объект (элемент) класса книг «Три мушкетера». Такое высказывание говорит о том, что мы находимся в рамках логической парадигмы или, как говорят филологи, в экстенсиональном контексте.
Вывод: Термин ЭКЗЕМПЛЯР ОБЪЕКТА указывает нам на интенсиональный контекст явно, а термин ОБЪЕКТ предполагает, что контекст мы вольны выбрать сами (интенсиональный, или экстенсиональный).
Один объект, или много?
Вернемся к вопросу о том, что есть разные бумажки с надписью договор? Ответы, как мы видели, могут быть такими:
- это два разных договора,
- это один договор, но экземпляры его разные.
Если аналитик настаивает на второй интерпретации, я задаю вопрос: где, в какой парадигме существуют объекты и их экземпляры? Ответить на этот вопрос аналитик не может, поскольку такой парадигмы не существует. Однако в некоторых книгах существует путаница в терминах, благодаря которой такое выражение появилось на свет и активно распространилось.
Мне приходится проводить экскурс в историю и объяснять аналитику, что термин экземпляр связан с термином тип. И что термин экземпляр книги имеет такую трактовку: существует тип книг, и есть конкретный экземпляр этого типа книг, — конкретная книга. И нет такой трактовки: есть объект книга, и есть ее экземпляр.
Напомню: мы помним, что тип у Аристотеля – это набор параметров. Экземпляр – это значения этих параметров.
После того, как аналитик решает продолжить исследование, мы продолжаем двигаться с ним, полагаясь теперь только на логику.
Мы можем также считать, что существуют одновременно два термина: экземпляр договора купли-продажи и экземпляр договора купли-продажи от 30-го июня. Понятно, что одна и та же бумажка может быть экземпляром договора купли-продажи и экземпляром договора от 30-го июня. Это значит, что мы допустили существование двух типов, к которым может относиться один объект реального мира! Но этот парадокс был одним из тех, который в итоге привел к появлению теории множеств. Аристотелевская модель не смогла дать ответ на множественность типов.
Понятно, что одна и та же бумажка может быть экземпляром договора купли-продажи и экземпляром договора от 30-го июня. Это значит, что мы допустили существование двух типов, к которым может относиться один объект реального мира! Но этот парадокс был одним из тех, который в итоге привел к появлению теории множеств. Аристотелевская модель не смогла дать ответ на множественность типов.
Можно переформулировать вопрос и так: какими параметрами обладает тот тип договоров, на который ссылается аналитик, употребляя термин экземпляр договора? Тогда я использую следующий сценарий опроса:
Далее я задаю второй вопрос: какими параметрами обладает тот тип договоров, о котором упомянул аналитик, предлагая на выбор:
- Первый тип относится только к тем объектам, которые зафиксировали информацию о конкретной договоренности. Он содержит параметр «Чей экземпляр?» (подрядчика, заказчика). Пример использования данного типа: экземпляр договора от 30-го апреля.

- Второй содержит параметры: дата подписания, предмет соглашения, юридические лица, и так далее. Пример использования данного типа: экземпляр договора купли-продажи.
Если аналитик дает первый ответ, то я задаю вопрос: допускает ли он существование такого типа договоров, который включает в себя все экземпляры всех договоров купли-продажи? Если да, то, как мы отличаем в разговоре, о каком типе идет речь? И получается, что один и тот же экземпляр может относиться к двум разным типам договоров? Но это модернизация Аристотелевской логики, про которую мы ничего не знаем. Получается, что объект может быть одновременно и машиной и кораблем. На это логика Аристотеля не смогла дать ответ, и потому нам пришлось изобретать теорию множеств.
Если аналитик отвечает вторым образом, я задаю второй вопрос: Содержит ли упомянутый тип параметр «Чей экземпляр?» Ответов может быть два:
- Да, содержит
- Нет, не содержит. Это самый распространенный ответ, поскольку во всех системах документооборота и учета именно этот тип активно поддерживается.

Если я получаю первый ответ, то я задаю вопрос: а что есть тот тип, экземпляром которого является экземпляр договора от 30-го июня?
Если я получаю второй ответ, то я уточняю, а что есть объекты, которые содержат этот параметр? Ответ вы слышали: объект один, а экземпляров его много, что возвращает нас к вопросу о логичности и корректности такого тезиса.
Пример представления модели предметной области
Давайте посмотрим, как обычно аналитики моделируют стандартные предметные области. Например, такую:
Мы видим, что все множество вооружений делится на классы. Каждый класс вооружений, в свою очередь, делится на подклассы. Мы видим, что класс подлодок – есть подмножество класса вооружений, а класс Акула – есть подмножество класса подлодок.
Часто встречающаяся реализация этой модели в виде таблиц такая:
Таблица 1 моделирует подклассы класса оружие. Таблица 2 – подклассы класса подводных лодок. Связь между таблицей 1 и таблицей 2 моделирует специализацию вооружений. Таблица 1 моделирует подводные лодки, а связь между таблицей 2 и таблицей 1 моделирует классификацию подводных лодок. (Термины специализация и классификация взяты из логической парадигмы и не случайны). Понятно, что одному подклассу вооружений «подводная лодка» соответствует много подклассов класса подводных лодок и понятно, что одному подклассу подводных лодок может принадлежать много подводных лодок, что обозначено «Вороньей лапкой» на конце связи между таблицами. Принято считать, что структура таблиц и есть модель предметной области, но, как вы видите, информации в структуре таблиц намного меньше, чем в модели предметной области.
Таблица 1 моделирует подводные лодки, а связь между таблицей 2 и таблицей 1 моделирует классификацию подводных лодок. (Термины специализация и классификация взяты из логической парадигмы и не случайны). Понятно, что одному подклассу вооружений «подводная лодка» соответствует много подклассов класса подводных лодок и понятно, что одному подклассу подводных лодок может принадлежать много подводных лодок, что обозначено «Вороньей лапкой» на конце связи между таблицами. Принято считать, что структура таблиц и есть модель предметной области, но, как вы видите, информации в структуре таблиц намного меньше, чем в модели предметной области.
Эта модель очень похожа на другие, подобные ей:
Модель предметной области в парадигме Аристотеля
Вспоминая то, о чем я говорил в статье о том, что в Аристотелевской логике таблица – есть описание типа объектов, а запись в таблице – это описание объекта, нарисуем модель предметной области в парадигме типов и экземпляров. (В этой парадигме чаще всего происходит обсуждение предметной области и именование таблиц). Для этого применим формальный подход, который я озвучил в статье. То есть таблица – обозначает тип объектов, а записи в ней – экземпляры.
Для этого применим формальный подход, который я озвучил в статье. То есть таблица – обозначает тип объектов, а записи в ней – экземпляры.
Полученная модель выглядит так:
Таблица 3 моделирует тип подводных лодок. Запись в таблице моделирует экземпляр подводной лодки. Связь с записью в таблице 2 моделирует тот факт, что подводная лодка принадлежит определенному классу подводных лодок. Но с таблицей 2 мы не можем определиться. Что за тип объектов моделирует эта таблица? Экземпляр чего есть запись в этой таблице? Терминов в Аристотелевской логике для этих сущностей не предусмотрено. Мы можем попытаться придумать сами название тому типу объектов, которые хранятся в таблице 2, например: тип классов. Тогда Класс Акула будет экземпляром класса. (Замечу, что экземпляр класса указывает на класс, а не на объект класса, как некоторые могли бы подумать. На объект класса указывает ЭЛЕМЕНТ КЛАССА, а не ЭКЗЕМПЛЯР КЛАССА!). Полученная модель выглядит теперь так:
Проблема в том, что одновременно в одной модели мы видим и типы объектов и классы. (Я иногда встречал таблицы, озаглавленные: типы классов, виды типов, виды классов и так далее…) Надо понимать, что типы существуют только в Аристотелевской логике, а классы – только в логической. И они не смешиваются. Поэтому класс Акула нам следует переименовать в тип подводных лодок Акула. Риторика была бы такая: наряду с экземпляром подводной лодки у нас появляется экземпляр Акулы, где под Акулой понимается тип подводных лодок. Однако в данной статье я предлагаю остановиться и посмотреть, что будет с другими моделями – собак и сварных швов.
(Я иногда встречал таблицы, озаглавленные: типы классов, виды типов, виды классов и так далее…) Надо понимать, что типы существуют только в Аристотелевской логике, а классы – только в логической. И они не смешиваются. Поэтому класс Акула нам следует переименовать в тип подводных лодок Акула. Риторика была бы такая: наряду с экземпляром подводной лодки у нас появляется экземпляр Акулы, где под Акулой понимается тип подводных лодок. Однако в данной статье я предлагаю остановиться и посмотреть, что будет с другими моделями – собак и сварных швов.
Ограничения парадигмы Аристотеля
В случае с собаками таблица 2 – есть описание типа пород. И в случае со швами – типа типов. И вот тут засада возникла. Представляете: на совещании аналитиков мы обсуждаем структуру таблиц и у нас возникают термины: тип типов. Это мало кто поймет. Это слишком сложно для обыденной речи и обыденного понимания. Лично я, если встречал такой термин, то крайне редко. Проблема в том, что Аристотель не проработал терминологию для описания структур сложнее классов, например, класса классов. Это сделала теория множеств много позже. Но наши аналитики пока не знают о существовании теории множеств и пытаются выкрутиться в рамках Аристотелевской логики. Для этого они меняют риторику. Новая риторика была заимствована из описания информационных объектов. В описании информационных объектов задолго до возникновения проблемы с типами типов, было найдено «решение». «Решение» возникло само собой, поскольку никто не задумывался над этим.
Это сделала теория множеств много позже. Но наши аналитики пока не знают о существовании теории множеств и пытаются выкрутиться в рамках Аристотелевской логики. Для этого они меняют риторику. Новая риторика была заимствована из описания информационных объектов. В описании информационных объектов задолго до возникновения проблемы с типами типов, было найдено «решение». «Решение» возникло само собой, поскольку никто не задумывался над этим.
Постановка задачи
Давайте посмотрим, как выглядит оно в применении к сварным швам. Сначала была такая структура таблиц, описывающая такую модель предметной области:
В такой модели шов №234 можно назвать двумя способами: экземпляр сварного шва и экземпляр стыкового шва. Оба эти термина являются корректными терминами, и объяснить их удобно в рамках теории множеств. Понятно, что шов №234 принадлежит классу сварных швов. Понятно, что шов №234 принадлежит также классу стыковых швов, являющимся подклассом сварных швов:
В структуре данных это отражено так: запись в таблице «сварные швы» говорит нам о первой классификации объекта, а связь с записью в таблице «типы сварных швов» говорит нам о второй классификации.
Замечу, что две разные формы моделирования одной и той же связи «классификация», которая есть между швом и классом сварных швов и между швом и классов стыковочных швов, говорит нам о том, что моделирование при помощи таблиц не создано для корректного моделирования предметной области.
Но вот объяснить, что тип стыковых швов есть экземпляр типов сварных швов, становится уже неловко.
«Решение»
Чтобы избавиться от столь замысловатых терминов, иногда рисуют вот такую структуру:
Теперь у нас в разговорной речи все нормально. Можете проверить.
Конструкция на первый взгляд кажется разумной, но ровно до тех пор, пока не нарисуем модель терминов:
Теперь у нас появилось несколько сюрпризов:
- Запись «Стыковой шов» моделирует (сюрприз!) нет, не шов! Он моделирует целый класс швов!
- Таблица СВАРНЫЕ ШВЫ содержит (сюрприз!) не информацию о сварных швах, нет! Она содержит информацию о классе сварных швов!
- ТИП сварных швов не имеет никакого отношения к типу сварных швов.

- ЭКЗЕМПЛЯР сварного шва — не есть экземпляр сварного шва.
- ЭКЗЕМПЛЯР стыкового шва — не есть экземпляр стыкового шва.
- Два термина «Экземпляр сварного шва» и «сварной шов» до этого момента указывали на один объект – сварной шов. Однако теперь я иногда слышу от некоторых аналитиков, что надо различать сварной шов и экземпляр сварного шва, как будто это разные вещи!
Такая конструкция является самопальной и ошибочной. Причина в том, что она не опирается ни на одну из онтологий и являет из себя подмену понятий. Как я уже говорил, в парадигме Аристотеля термины экземпляр стыкового шва и стыковой шов указывают на один и тот же объект реального мира – на конкретный стыковой шов. В нарисованной структуре объект справочника Стыковой шов указывает не на объект, а на класс объектов!
В результате некоторое количество аналитиков начинают мыслить искаженным способом: они перестают различать различные объекты, называя их одним термином: Стыковой шов. Риторика их следующая: есть один объект «Стыковой шов» и есть различные его ЭКЗЕМПЛЯРЫ. У них в сознании есть один спортсмен и множество его ЭКЗЕМПЛЯРОВ! Надо понимать, что под термином ЭКЗЕМПЛЯР эти аналитики понимают нечто такое, что не было ведомо ни Аристотелю, ни кому бы то ни было еще. Это самопальный термин, который выглядит ужасно с любых точек зрения: с логической и лингвистической точек зрения. То есть, ЭКЗЕМПЛЯР стыкового шва для них обозначает: есть объект СТЫКОВОЙ ШОВ и есть его ЭКЗЕМПЛЯРЫ. Хорошо, что Аристотель этого не слышит!
Риторика их следующая: есть один объект «Стыковой шов» и есть различные его ЭКЗЕМПЛЯРЫ. У них в сознании есть один спортсмен и множество его ЭКЗЕМПЛЯРОВ! Надо понимать, что под термином ЭКЗЕМПЛЯР эти аналитики понимают нечто такое, что не было ведомо ни Аристотелю, ни кому бы то ни было еще. Это самопальный термин, который выглядит ужасно с любых точек зрения: с логической и лингвистической точек зрения. То есть, ЭКЗЕМПЛЯР стыкового шва для них обозначает: есть объект СТЫКОВОЙ ШОВ и есть его ЭКЗЕМПЛЯРЫ. Хорошо, что Аристотель этого не слышит!
Другой пример подобного «Решения»
Теперь приведем пример подобного рода моделирования, которое мы встречаем повсюду. Возьмем наши любимые договора. В любой системе мы найдем такой справочник:
Каждая запись в этом справочнике моделирует… А что она моделирует? Название предполагает, что запись в этом справочнике либо является договором, либо моделирует договора. Запись в базе не содержащая подписи сторон, не может быть договором. Поэтому здесь хранится информация о договорах, то есть, информация о других информационных объектах. Мы знаем, что одна запись в базе данных соответствует множеству экземпляров договора от 30-го июня, отличающихся тем, кому они принадлежат: Заказчику или Подрядчику. Давайте попробуем нарисовать модель терминов:
Поэтому здесь хранится информация о договорах, то есть, информация о других информационных объектах. Мы знаем, что одна запись в базе данных соответствует множеству экземпляров договора от 30-го июня, отличающихся тем, кому они принадлежат: Заказчику или Подрядчику. Давайте попробуем нарисовать модель терминов:
Мы видим ту самую картину, которую анализировали ранее. Вот откуда пришли к нам понятия объект и его экземпляр! Из некорректного моделирования информационных объектов! Мы видим в этой модели разные экземпляры одного договора. Что и требовалось показать. Только в некорректной модели могут родиться некорректные термины: объект и его экземпляр.
Причина такого рода заблуждений кроется в незнании логики и в неправильном понимании сути информационных объектов.
Правильное решение
Давайте применим правильный подход к моделированию договоров и посмотрим, как должна выглядеть структура данных непротиворечивым образом с точки зрения Аристотелевской логики (не считая типов типов и наличие множественности типов).
Итак, в базе данных в таблице Договора, оказывается, хранилась информация о типе договоров, а не о договоре! Заметьте, существует устойчивое мнение, что мы храним информацию об информационном объекте, а не о множестве информационных объектов! Справочники, с которыми мы работаем каждый день, так и называются: Договора, Накладные, Счета-фактуры, и так далее. А не типы договоров, типы накладных и типы счетов-фактур. Это привело к массовому заблуждению, которое проявилось сейчас в убежденности многих аналитиков, что существует объект и есть его экземпляр. Вспомните, стандарты моделирования бизнес-процессов! Это заблуждение проникло и в стандарты!
А как же тогда называют справочник, в котором хранится информация о договорах (в Таблице 3, если придерживаться в нашей практике обозначений)? Я видел много названий, среди которых: Подписанные договора (как будто есть не подписанные), Экземпляры договоров (как будто есть объект и его экземпляры), Разосланные договора, Сформированные договора, Выполненные договора, Распечатанные договора. Каждый, кто сталкивался с необходимостью учета реальных информационных объектов, придумывает свои названия.
Каждый, кто сталкивался с необходимостью учета реальных информационных объектов, придумывает свои названия.
Наконец, мы пришли к ответу на вопрос, заданному ранее: разные бумажки с печатями и подписями — это разные объекты, или это разные экземпляры? Ответ очевиден — это разные объекты! Мы видим, что существующая практика именования таблиц не выдерживает никакой критики. Теперь, когда мы выяснили, что у нас каждый документ – это отдельный документ, нам предстоит построить корректную модель этих объектов. Чтобы понять, как это сделать, не исковеркав язык (порождая виды, типы, классы, рода и прочее), нам придется обратиться к теории множеств.
Решение в логической парадигме
В теории множеств есть три класса объектов: объекты, классы и классы классов, а также классы отношений между объектами и классами. Всех возможных конструкций я перечислять не буду, но по мере необходимости буду давать пояснения.
Пусть у нас есть множество всех договоров (в смысле каждая бумажка – отдельный договор). Каждый договор принадлежит классу договоров.
Каждый договор принадлежит классу договоров.
Тогда говорят, что договор связан с классом договоров связью классификация.
Класс договоров купли-продажи есть подмножество всех договоров.
Связь между классом всех договоров и классом договоров купли-продажи – называется специализация.
Класс договоров купли-продажи, класс договором аренды и проч. – есть объекты множества, которое есть множество всех подмножеств класса договоров.
Множество всех подмножеств класса договоров – есть класс классов, и связывает его с классом всех договоров, классом договоров купли продажи связь классификация.
Среди всех подмножеств множества договоров можно выделить те подмножества, которые относятся к одной сделке. Объединив эти подмножества в один класс, назовем его подклассы класса договоров. То есть, договора одного класса представляют модель одного объекта – одной сделки.
Теперь мы готовы нарисовать структуру таблиц и дать им имена.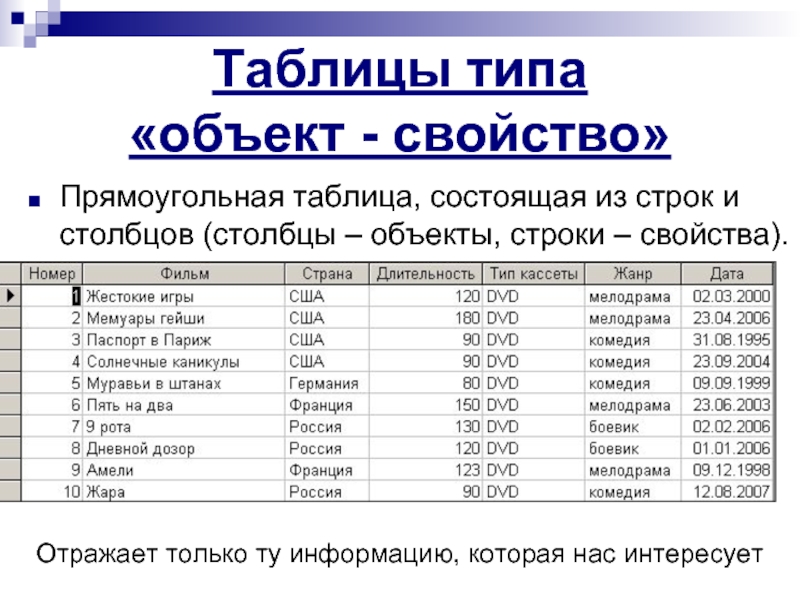
Модель предметной области в логической парадигме выглядит так:
А структура таблиц, реализующая эту модель, такая:
Как это будет звучать на практике?
- Таблица 3 моделирует класс договоров и содержит модели договоров.
- Таблица 2 моделирует класс классов договоров, относящихся к одной сделке, и содержит модели классов договоров, относящихся к одной сделке.
- Связь между записями таблиц моделирует связь классификация между классами договоров, относящихся к одной сделке, и договорами.
Замечу, что диаграммы отношений между сущностями предметной области в логической парадигме рисуются просто, однозначно и демонстрируют полноту. Смысл их легко читается, если помнить и знать смысл названий и обозначений. Данные модели демонстрируют полноту в отличие от моделей предметной области, сделанных в виде ER–моделей. Для моделирования одной и той же информации можно построить разные ER-модели. Это хорошо видно, когда есть модель предметной области в логической парадигме. Становится очевидным произвольность выбора таблиц для хранения информации о предметной области.
Становится очевидным произвольность выбора таблиц для хранения информации о предметной области.
Чтобы завершить разговор об информационных объектах и о их моделировании, я предлагаю обратить внимание на «размазанность» информации об объекте предметной области по структуре данных. Это дает нам основания говорить, что нет однозначного соответствия между объектами предметной области и объектами в системе. Более того, часто одна запись в таблице хранит одновременно данные об объекте и о классе объектов! Всего этого лишена логическая модель данных. Поэтому она иногда называется моделью данных в последней нормальной форме.
Еще одна пострадавшая предметная область
В последнее время я все чаще слышу тезис о том, что надо различать процесс и экземпляр процесса. После того, как вы прочитали пост, у вас должно закрасться сомнение в истинности этого утверждения. Возможно, я когда-нибудь напишу причины этого заблуждения. Причины эти не связаны с неправильным пониманием того, что такое информационный объект. Причина в неправильном понимании того, что такое процесс. Но это совсем другая история…
Причина в неправильном понимании того, что такое процесс. Но это совсем другая история…
Атрибуты векторных данных
Цель: |
Этот раздел рассказывает о том, что такое атрибутивные данные, как они связаны с векторными объектами и как их использовать для настройки отображения данных. |
|
Основные понятия: |
Атрибут, база данных, поля, данные, вектор, символика |
Обзор
Если все линии на карте будут иметь один и тот же цвет, одинаковую ширину и подпись, будет очень трудно понять что к чему. Такая карта будет малоинформативной. Взгляните на рисунок figure_map_attributes.
Figure Attributes on map:
Карта становится пригодной к использованию, когда различные типы объектов можно отличить друг от друга по цвету и внешнему виду. Вы сможете различить реки, дороги и горизонтали на карте слева? А вот сделать это при помощи карты, показанной справа, намного проще.
В этом разделе мы узнаем как атрибутивные данные помогают создавать интересные и информативные карты. В предыдущих разделах, посвященных векторным данным, мы кратко объясняли, что атрибутивные данные используются для описания векторных объектов. Посмотрите на изображенные на рисунке figure_house дома.
Figure House 1:
Каждый объект имеет характеристики. Это могут быть как видимые вещи, так и информация, которую мы просто знаем (например, год постройки).
Геометрия этих объектов полигональная (соответствует плану дома), а в качестве атрибутов мы используем цвет крыши, наличие балкона и год постройки. Обратите внимание, что в качестве атрибутов не обязательно выступают видимые признаки — также можно использовать любую известную информацию об объекте, например год постройки дома. В ГИС-приложении мы можем отобразить дома в виде полигонального слоя, а их атрибуты в виде таблицы атрибутов (см. figure_house_gis).
Figure House 2:
Слой зданий. Здания имеют атрибуты, описывающие цвет крыши и другие свойства. Таблица атрибутов (нижнее изображение) показывает атрибуты домов, видимых на карте. Если объект выделен в таблице атрибутов, он будет подсвечен желтым цветом на карте.
Тот факт, что объекты в ГИС-приложении наряду с геометрией имеют и атрибуты, открывает широкие возможности. Например, мы может использовать значения атрибутов, чтобы задать цвет и стиль отрисовки объектов (см. рисунок figure_style_by_attribute). Процесс настройки цветов и стилей отображения часто называется настройкой символики.
Figure Feature Style 1:
ГИС-приложение может отображать объекты по-разному, в зависимости от их атрибутов. Слева показаны полигоны зданий, раскрашеные в тот же цвет, который указан в атрибуте «цвет крыши». Справа показаны здания, окрашенные по наличию или отсутствию балкона.
Атрибутивные данные также могут использоваться при создании подписей. Большинство ГИС-приложений позволяют указать атрибут, который будет использоваться для подписывания каждого объекта.
Большинство ГИС-приложений позволяют указать атрибут, который будет использоваться для подписывания каждого объекта.
Если вы когда-либо искали на карте определенное место или объект, вы должны знать как много времени может уходить на это. Наличие атрибутивных данных может сделать поиск заданного объекта быстрым и легким. На рисунке figure_search_by_attribute показан процесс поиска по атрибутам в ГИС.
Figure Feature Search 1:
ГИС-приложения также позволяют выполнять поиск объектов по атрибутам. Здесь показаны здания с черной крышей. Результат поиска отображается на карте желтым цветом, а в таблице атрибутов — бирюзовым.
B наконец, атрибутивные даные могут быть весьма полезны при выполнении пространственного анализа. Пространственный анализ сочетает пространственную информацию, хранящуюся в геометрии объекта, с его атрибутами. Это позволяет нам изучать объекты и их взаимоотношения. Существует множество разновидностей пространственного анализа, например, вы можете использовать ГИС для того, чтобы узнать сколько домов с красными крышами находится в заданном районе. Если у вас есть слой деревьев, вы можете использовать ГИС для выяснения того, какие виды будут затронуты если будет разрабатываться определенных участок земель. Мы можем использовать атрибуты, содержащие пробы воды по течению реки, чтобы узнать где происходит загрязнение. Возможности бесконечны! Более подробно пространственный анализ рассмотрен в следующих разделах.
Если у вас есть слой деревьев, вы можете использовать ГИС для выяснения того, какие виды будут затронуты если будет разрабатываться определенных участок земель. Мы можем использовать атрибуты, содержащие пробы воды по течению реки, чтобы узнать где происходит загрязнение. Возможности бесконечны! Более подробно пространственный анализ рассмотрен в следующих разделах.
Прежде чем мы двинемся дальше, подведем итоги.
Объекты это предметы реального мира, такие как дороги, границы участков, подстанции и т.д. Объект имеет геометрию (которая может быть точкой, линией или полигоном) и атрибуты (которые описывают объект). Это показано на рисунке figure_features_at_glance.
Figure Feature Summary 1:
Векторные объекты.
Подробнее об атрибутах
Атрибуты векторных объектов хранятся в таблице. Каждый столбец таблицы назывется полем. Каждая строка — записью. Таблица table_house_attributes является простейшим примером таблицы атрибутов в ГИС. Каждая запись таблицы атрибутов в ГИС соответсвует одному объекту. Обычно информация из таблицы атрибутов хранится в некоторой базе данных. ГИС-приложения связывают атрибутивные записи с геометрией объекта, так что вы можете найти запись в таблице выделив объект на карте и наоборот, найти объект на карте выбрав запись в таблице.
Каждая строка — записью. Таблица table_house_attributes является простейшим примером таблицы атрибутов в ГИС. Каждая запись таблицы атрибутов в ГИС соответсвует одному объекту. Обычно информация из таблицы атрибутов хранится в некоторой базе данных. ГИС-приложения связывают атрибутивные записи с геометрией объекта, так что вы можете найти запись в таблице выделив объект на карте и наоборот, найти объект на карте выбрав запись в таблице.
Таблица атрибутов |
Поле 1 : YearBuilt |
Поле 2: RoofColour |
Поле 3: Balcony |
|---|---|---|---|
запись 1 |
1998 | Красный |
Да |
Запись 2 |
2000 | Чёрный |
Нет |
Запись 3 |
2001 | серебристый |
Да |
Table House Attributes 1: Таблица атрибутов имеет поля (столбцы) и записи (в строках).
Каждое поле таблицы атрибутов имеет определенный тип данных — текст, число или дата. Выбор типа данных для атрибута требует вдумчивого планирования. В нашем примере с домами, мы выбрали в качестве атрибутов цвет крыши, наличие балкона и год постройки. Мы также можем выбрать и другие параметры зданий такие как:
количество этажей
количество комнат
число жильцов
тип здания (коттедж, кирпичный дом, многоэтажный и т.д.)
год постройки
жилая площадь
и другие…
Как имея такой широкий выбор определить какие именно атрибуты должны быть у объекта? Обычно всё зависит от того, что вы собираетесь делать с данными. Если вы хотите создать карту на которой дома раскрашены в зависимости от возраста, стоит озадобиться наличием атрибута «Год постройки». Если вы абсолютно уверены, что никогда не будете нуждаться в подобной карте — лучше не хранить эту информацию. Сбор и хранение избыточной информации плохая идея, т. к. это требует дополнительных материальных и временных ресурсов. Очень часто мы получаем векторные данные от организаций, друзей или правительства. Как правило, в таких случаях невозможно запросить определенные атрибуты и приходится работать с тем, что есть.
к. это требует дополнительных материальных и временных ресурсов. Очень часто мы получаем векторные данные от организаций, друзей или правительства. Как правило, в таких случаях невозможно запросить определенные атрибуты и приходится работать с тем, что есть.
Обычный знак
Если объекты отображаются без использования значений атрибутивной таблицы, они могут быть отрисованы только обычным знаком. Например, для точечных объектов можно задать цвет и маркер (окружность, квадрат, звезда и т.д.) и это всё. Вы не можете заставить ГИС отрисовывать объекты, используя значения одного из атрибутов. Чтобы сделать это, необходимо использовать градуированный, непрерывный или уникальный знак. Все они описаны ниже.
ГИС-приложение позволяет настроить внешний вид объектов слоя при помощи диалога, похожего на рисунок figure_single_symbol_1. В этом диалоге можно указать используемые цвета и стили знаков. В зависимости от типа геометрии слоя, доступны разные настройки. Так, для точечных слоёв можно задать тип маркера. Для линейных и полигональных слоёв возможность настройки маркера отсутствует, но можно выбрать тип линии и цвет, например оранжевый пунктир для гравийных дорог, сплошная оранжевая для второстепенных дорог и т.д. (см. рисунок figure_single_symbol_2). Для полигональных слоёв кроме того можно указать тип заливки и её цвет.
В зависимости от типа геометрии слоя, доступны разные настройки. Так, для точечных слоёв можно задать тип маркера. Для линейных и полигональных слоёв возможность настройки маркера отсутствует, но можно выбрать тип линии и цвет, например оранжевый пунктир для гравийных дорог, сплошная оранжевая для второстепенных дорог и т.д. (см. рисунок figure_single_symbol_2). Для полигональных слоёв кроме того можно указать тип заливки и её цвет.
Figure Single Symbol 1:
При использовании обычного знака все объекты отображаются одинаково, внешний вид не зависит от атрибутов. Здесь показан диалог для точечных объектов.
Figure Single Symbol 2:
Настройка обычного знака для линейных и полигональных объектов несколько отличается.
Градуированный знак
Иногда векторные объекты представляют вещи с изменяющимися цифровыми значениями. Хорошим примером могут служить горизонтали. Каждая горизонталь имеет атрибут, назывемый «высота», который содержит информацию о высоте над уровнем моря. Ранее в этом разделе мы показывали горизонтали, отрисованные одним цветом. Раскраска горизонталей в разные цвета поможет нам интерпретировать их значения. Например, мы можем отрисовать низинные области одним цветом, среднегорье — другим, а высокогорные области — третьим.
Каждая горизонталь имеет атрибут, назывемый «высота», который содержит информацию о высоте над уровнем моря. Ранее в этом разделе мы показывали горизонтали, отрисованные одним цветом. Раскраска горизонталей в разные цвета поможет нам интерпретировать их значения. Например, мы можем отрисовать низинные области одним цветом, среднегорье — другим, а высокогорные области — третьим.
Figure Graduated Symbol 1:
Значение высоты может использоваться для разделения горизонталей на три класса. Горизонтали, находящиеся в диапазоне от 980 м до 1120 м будут показаны коричневым, находящиеся в диапазоне от 1120 м до 1240 м — зеленым, а находящиеся в диапазоне от 1240 м до 1500 м — фиолетовым.
Figure Graduated Symbol 2:
Так выглядит карта отрисованная градуированным знаком.
В QGIS отрисовка в зависимости от дискретных групп значений атрибута называется градуированным знаком. Процесс настройки показан на рисунках figure_graduated_symbol_1 и figure_graduated_symbol_2. Градуированный знак наиболее полезен когда необходимо показать различие между объектами с различными диапазонами значений в атрибутах. ГИС-приложение анализирует атрибуты (например, высоту) и, основываясь на заданном количестве классов, группирует значения. Процесс можно проиллюстрировать при помощи таблицы table_graduated_1.
Градуированный знак наиболее полезен когда необходимо показать различие между объектами с различными диапазонами значений в атрибутах. ГИС-приложение анализирует атрибуты (например, высоту) и, основываясь на заданном количестве классов, группирует значения. Процесс можно проиллюстрировать при помощи таблицы table_graduated_1.
Значение атрибута |
Класс и цвет |
|---|---|
| 1 | Класс 1 |
| 2 | Класс 1 |
| 3 | Класс 1 |
| 4 | Класс 2 |
| 5 | Класс 2 |
| 6 | Класс 2 |
| 7 | Класс 3 |
| 8 | Класс 3 |
| 9 | Класс 3 |
Table Graduaded 1: Градуированный знак разбивает значения атрибута на заданное количество классов. Каждый класс отображается своим цветом.
Каждый класс отображается своим цветом.
Непрерывный знак
В предыдущем параграфе о градуированном знаке мы видели, что объекты можно отрисовать с разбивкой на группы классов. Иногда бывает необходимо отобразить объекты в виде градиента от одного цвета к другому. ГИС-приложение будет использовать числовой атрибут объекта (например, высоту или уровень загрязнения), чтобы выбрать цвет. Таблица table_continuous_1 показывает как используются значения атрибутов для создания непрерывного диапазона цветов.
Значение атрибута |
Цвет (классы или группировка отсутствуют) |
|---|---|
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 | |
| 9 |
Table Continuous 1: Непрерывный знак использет начальный цвет (например, светло-оранжевый, как показано здесь) и конечный цвет (например, темно-коричневый), а затем создаёт серию промежуточных цветов между ними.
Используя тот же пример с горизонталями, посмотрим как будет выглядеть карта, отрисованная непрерывным знаком. Процесс начинается с настройки свойств слоя при помощи диалога, показанного на рисунке figure_continuos_symbol_1.
Figure Continuous Symbol 1:
Настройка непрерывного знака. Высота горизонтали используется для определения цвета. Цвета задаются для минимального и максимального значения. Затем ГИС-приложение создаёт градиент из этих цветов и задаёт цвет объекта в зависимости от значения атрибута (в данном случае высоты).
После указания цветов, соответствующим минимальному и максимальному значениям, цвет объекта будет выбран в зависимости от того в каком месте диапазона между максимальным и минимальным значением находится значение атрибута. Например, если горизонтали начинаются с отметки 1000 м и заканчиваются на отметке 1400 м, диапазон значений будет простираться от 1000 до 1400. Если для минимального значения выбран оранжевый цвет, а для максимального — черный, горизонтали со значениями близкими к 1400 м будут отображаться цветом близким к черному. Аналогично, горизонтали со значениями близкими к 1000 м будут отображаться цветом близким к оранжевому (см. рисунок figure_continuous_symbol_2).
Аналогично, горизонтали со значениями близкими к 1000 м будут отображаться цветом близким к оранжевому (см. рисунок figure_continuous_symbol_2).
Figure Graduated Symbol 2:
Карта, отрисованная непрерывным знаком
Уникальный знак
Иногда атрибуты объектов являются не числовыми, а строковыми. В компьютерном понимании «строка» это последовательность букв, цифр и других видимых символов. Строковые атрибуты часто используются для классификации объектов по имени. Мы можем заставить ГИС-приложение отображать каждое уникальное значение своим цветом и знаком. Дороги могут иметь разный тип (например, «улица», «второстепенная дорога», «главная дорога» и т.д.), каждый из которых будет отображаться на карте своим цветом и стилем. В качестве иллюстрации посмотрите на таблицу table_unique_1.
Значение атрибута |
Цвет и символ |
|---|---|
Автомагистраль |
|
Главная дорога |
|
Второстпенная дорога |
|
Пешеходная дорога |
Table Unique 1: Уникальные значения атрибута объекта (например, дорог) имеют свои собственные символы.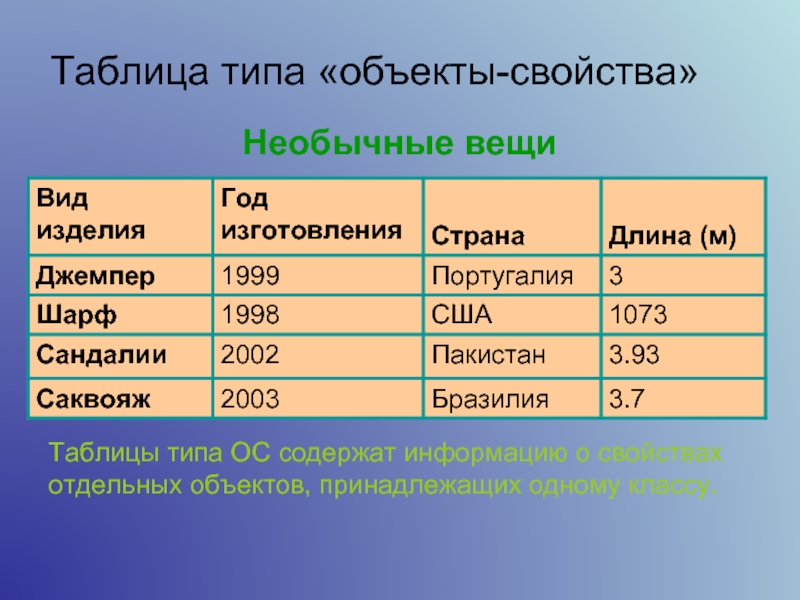
ГИС-приложения позволяют использовать уникальный знак для слоя. ГИС просканирует все значения атрибута и создаст список уникальных строк или чисел. Затем каждому уникальному значению можно назначить цвет и символ, как показано на рисунке figure_unique_symbol_1.
Figure Unique Symbol 1:
Настройка отрисовки дорог уникальным знаком в зависимости от типа дороги.
Когда ГИС выполняет визуализацию слоя, она смотрит на значение атрибута каждого объекта. В зависимости от значения атрибута, дорога будут отрисованы соответствующим цветом и символом (а полигональные объекты ещё и заливкой), как показано на рисунке figure_unique_symbol_2.
Figure Unique Symbol 2:
Слой дорог, отрисованный уникальным знаком (классификация по типу дороги).
Необходимо помнить
Выбор необходимых атрибутов и стиля отображения требует тщательного обдумывания. Перед тем как собирать какие-либо пространственные данные, необходимо убедиться, что вы знаете какие атрибуты нужны и как данные будут отображаться.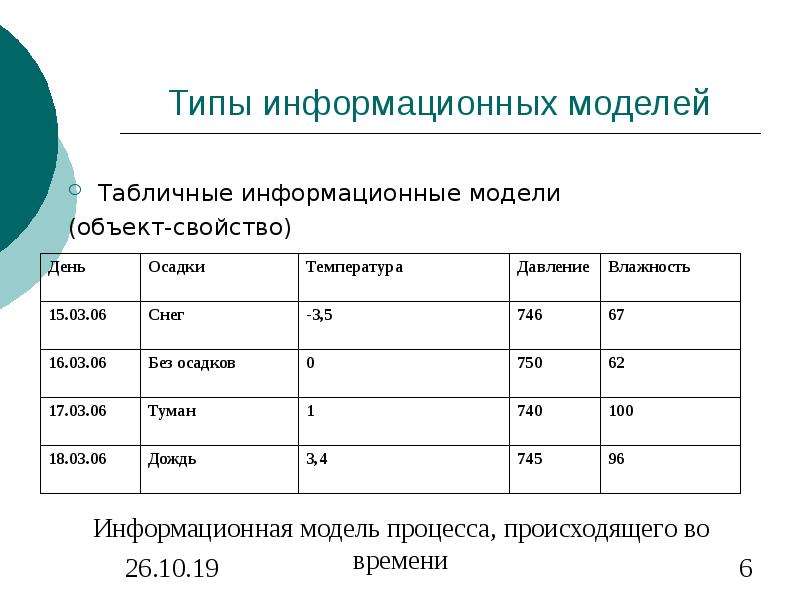 Если вы ошибетесь, будет довольно трудно вернуться назад и всё переделать. Помните, что цель сбора атрибутивных данных — помочь в анализе и интерпретации пространственной информации. Как вы это сделаете, зависит от вопросов на которые нужно ответить. Символика это визуальный язык, помогающий людям понять атрибуты объектов, глядя на используемые цвета и символы. Поэтому необходимо хорошо подумать как именно отобразить объекты, чтобы карту можно было легко понять.
Если вы ошибетесь, будет довольно трудно вернуться назад и всё переделать. Помните, что цель сбора атрибутивных данных — помочь в анализе и интерпретации пространственной информации. Как вы это сделаете, зависит от вопросов на которые нужно ответить. Символика это визуальный язык, помогающий людям понять атрибуты объектов, глядя на используемые цвета и символы. Поэтому необходимо хорошо подумать как именно отобразить объекты, чтобы карту можно было легко понять.
Что мы узнали?
Подведём итоги:
Векторные объекты имеют атрибуты
Атрибуты описывают свойства объекта
Атрибуты хранятся в таблице
Строки таблицы называются записями
В векторном слое одна запись соответстсвует одному объекту
Столбцы таблицы называются полями
Поля описывают свойства объекта, например высоту, цвет крыши и т.
 д.
д.Поля могут содержать числовые, строковые (любой текст) данные и даты
Атрибуты объекта могут использоваться для настройки его *символики
Градуированный знак группирует данные в дискретные классы
Непрерывный знак назначает цвет объекту из диапазона цветов
Уникальный знак сопоставляет каждому уникальному значению атрибута свой знак (цвет и символ)
Если атрибуты слоя не используются при его отрисовке, он отображается обычным знаком
Попробуйте сами!
Вот некоторые идеи для заданий:
Используя таблицу, созданную в предыдущем разделе, добавьте новый столбец с названием знака, который будет использоваться для каждого объекта. Попросите учащихся решить какой знак они будет использовать (в качестве примера см. таблицу table_example_symbols_1).
Попробуйте определить какой знак будет использоваться для следующих типов объектов:
точки, показывающие значение pH грунта, собранные вокруг школы
линии, отображающие сеть дорог города
полигоны домов с атрибутом, указывающим на материал (кирпич, дерево или «другой»)
Объект реального мира |
Тип геометрии |
Знак |
|---|---|---|
Флагшток |
Точка |
Обычный знак |
Футбольное поле |
Полигон |
Обычный знак |
Тропинки вокруг школы |
Полилиния |
Попросите учащихся подсчитать количество учеников на каждой тропинке перед началом занятий, а замет использовать градуированный знак чтобы показать популярность каждой дорожки |
Места расположения кранов |
Точка |
Обычный знак |
Кабинеты |
Полигон |
Уникальные значения в зависимости от возраста учащихся в классе |
Забор |
Полилиния |
Попросите учащихся оценить состояние забора вокруг школы, разбив его на участки и оценив каждый участок по десятибальной шкале. |
Кабинеты |
Полигон |
Подсчитайте количестве учеников в каждом кабинете и используйте непрерывный знак со шкалой от красного к синему. |
 Используйте градуированный знак чтобы отобразить состоение забора.
Используйте градуированный знак чтобы отобразить состоение забора.Table Example Symbols 1: Пример таблицы с описанием типов объектов и их символикой.
Стоит учесть
Если у вас нет компьютера, можно использовать прозрачную пленку и фрагмент карты масштаба 1:500000, чтобы показать различные типы символов. Например, совместите пленку и карту, и используя разноцветные фломастеры обведите красным все горизонтали ниже 900 м (или другой величины), а зеленым все горизонтали выше или равные 900м. Подумайте как показать другие типы знаков используя такую технику.
Дополнительная литература
Сайт: http://en.wikipedia.org/wiki/Cartography#Map_symbology
Подробную информацию о работе с атрибутами векторных данных в QGIS можно найти в Руководстве пользователя QGIS.
Что дальше?
Следующий раздел будет посвящен оцифровке. Мы на практике применим полученные знания о векторных объектах и их атрибутах, создавая новые даные.
Подробнее об объектной модели — JavaScript
JavaScript — это объектно-ориентированный язык, основанный на прототипировании, а не на классах. Из-за этого, менее очевидно то, каким образом JavaScript позволяет создавать иерархии объектов и обеспечивает наследование свойств и их значений. Эта глава является скромной попыткой прояснить ситуацию.
Эта глава предполагает что читатель знаком с основами JavaScript, и имеет опыт использования функций для создания простейших объектов.
Основанные на классах объектно-ориентированные языки программирования, такие как Java и C++, строятся на концепции двух отдельных сущностей: класс и экземпляр.
- Класс определяет все свойства (учитывая методы и все поля в Java, или свойства в C++), которые характеризуют группу объектов.
 Класс это абстрактная вещь, а не какой-либо конкретный член множества объектов, которые он описывает. Например, класс
Класс это абстрактная вещь, а не какой-либо конкретный член множества объектов, которые он описывает. Например, класс Employeeможет описывать множество всех сотрудников. - Экземпляр, это воплощение класса в виде конкретного объекта. Например,
Victoriaможет быть экземпляром классаEmployee, представляющий собой конкретного сотрудника. Экземпляр класса имеет ровно столько свойств, сколько и родительский класс (не больше и не меньше).
Прототипно-ориентированный язык, например JavaScript, не реализует данное различие: он имеет только объекты. Языки, основанные на прототипах, имеют понятие прототипа объекта — это объект, используемый в качестве шаблона, с целью получить изначальные свойства для нового объекта. Любой объект может иметь собственные свойства, присвоенные либо во время создания, либо во время выполнения. В дополнение, любой объект может быть указан в качестве прототипа для другого объекта, это позволит второму объекту использовать свойства первого.
Определение класса
В классо-ориентированных языках, вы можете определить класс. В этом определении вы можете указать специальные методы, называемые конструкторами, которые позволят создать экземпляр класса. Метод конструктор может задать начальные значения для свойств экземпляра и выполнять другие действия, в момент создания. Вы можете использовать оператор new, совместно с методом конструктора, для создания экземпляров классов.
JavaScript использует похожую модель, но не имеет определения класса отдельно от конструктора. Вместо этого, вы определяете функцию-конструктор для создания объектов с начальным набором свойств и значений. Любая функция в JavaScript может быть использована, как конструктор. Вы должны использовать оператор new для создания нового объекта.
Подклассы и наследование
В языках, основанных на классах, вы создаёте иерархию классов через объявление классов. В объявлении класса вы можете указать, что новый класс является подклассом уже существующего класса. При этом, подкласс унаследует все свойства суперкласса и в дополнение сможет добавить свои свойства или переопределить унаследованные. Например, предположим, что класс
При этом, подкласс унаследует все свойства суперкласса и в дополнение сможет добавить свои свойства или переопределить унаследованные. Например, предположим, что класс Employee включает два свойства: name и dept, а класс Manager является подклассом Employee и добавляет свойство reports. В этом случае, экземпляр класса Manager будет иметь три свойства: name, dept, и reports.
JavaScript реализует наследование, позволяя связать прототипный объект с любой функцией-конструктором. Итак, вы можете создать объект точь-в-точь, как в примере Employee — Manager, но используя несколько иную технику. Для начала нужно определить функцию-конструктор Employee, которая определяет свойства name и dept. Затем, определяем функцию-конструктор Manager, в которой в свою очередь, будет явно вызываться конструктор Employee и определяться новое свойство reports. Наконец, присваиваем новый экземпляр
Наконец, присваиваем новый экземпляр Employee, в качестве prototype для функции-конструктора Manager. Теперь, когда вы создадите нового Manager, он унаследует свойства name и dept из объекта Employee.
Добавление и удаление свойств
В языках, основанных на классах, вы, как правило, создаёте класс во время компиляции, а затем вы создаёте экземпляры класса либо во время компиляции, либо во время выполнения. Вы не можете изменить количество или тип свойств класса после определения класса. В JavaScript, однако, вы можете добавлять или удалять свойства любого объекта. Если вы добавляете свойство к объекту, который используется в качестве прототипа для множества объектов, то все эти объекты, для которых он является прототипом, также получат это свойство.
Подытожим различия
Следующая таблица даёт краткий обзор некоторых из этих различий. А оставшаяся часть этой главы описывает детали использования конструкторов и прототипов JavaScript для создания иерархии объектов и сравнивает это с тем, как вы могли бы сделать это в Java.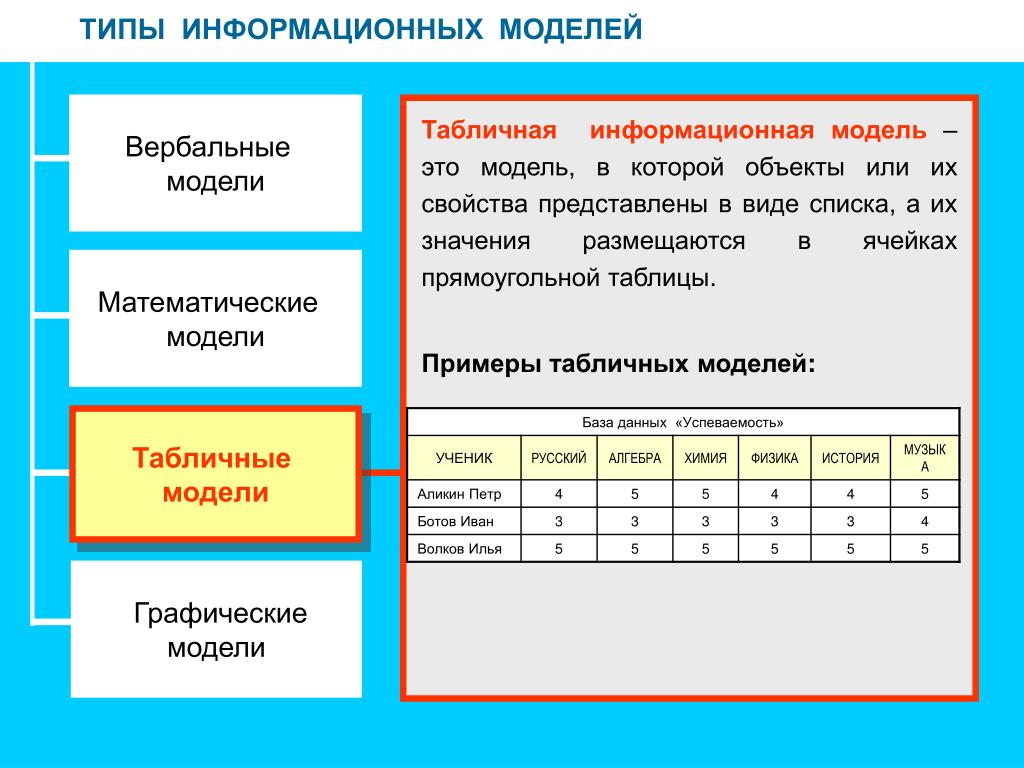
| Основанные на классах (Java) | Основанные на базе прототипов (JavaScript) |
|---|---|
| Класс и экземпляр являются разными сущностями. | Все объекты могут наследовать свойства другого объекта. |
| Определяем класс с помощью определения класса; создаём экземпляр класса с помощью метода-конструктора. | Определение и создание объекта происходит с помощью функций-конструкторов. |
Создание отдельного объекта с помощью оператора new. |
Так же. |
| Иерархия объектов строится с помощью определения классов и их подклассов. |
Построение иерархии объектов происходит путём присвоения объекта в качестве прототипа функции-конструктора. |
| Наследование свойств в цепочке классов. | Наследование свойств в цепочке прототипов.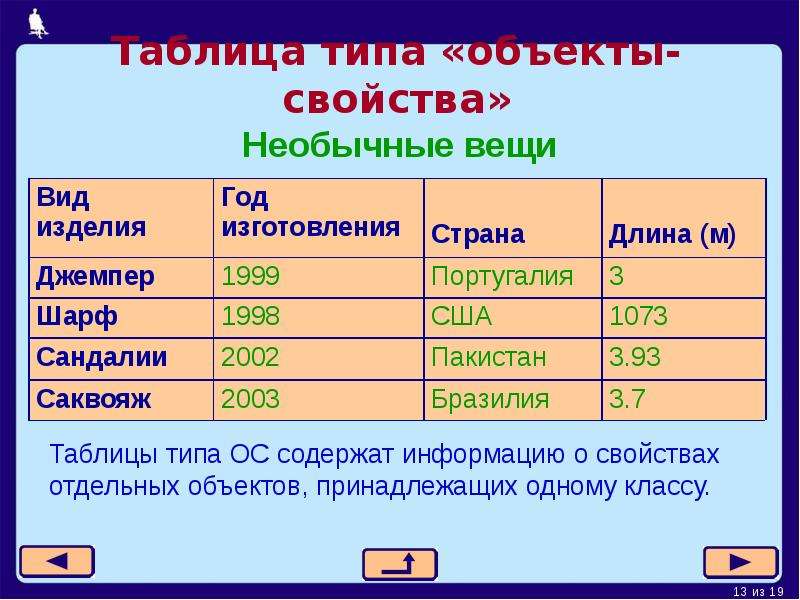 |
| Определение класса определяет все свойства всех экземпляров класса. Нельзя динамически добавлять свойства во время выполнения. | Функция-конструктор или прототип задаёт начальный набор свойств. Можно добавить или удалить свойства динамически к отдельным объектам или всей совокупности объектов. |
Оставшаяся часть этой главы объясняет иерархию сотрудников, показанную на следующем рисунке:
Рисунок 8.1: Простая иерархия объектов
Этот пример использует следующие объекты:
Employeeимеет свойствоname(значение которого по умолчанию пустая строка) иdept(значение которого по умолчанию «general»).Managerосновывается наEmployee. Он добавляет свойствоreports(значение которого по умолчанию пустой массив, предназначенный для хранения массива объектовEmployee).
WorkerBeeтак же основан наEmployee. Он добавляет свойствоprojects(значение которого по умолчанию пустой массив, предназначенный для хранения строк).SalesPersonоснован наWorkerBee. Он добавляет свойствоquota(значение которого по умолчанию 100). Он также переопределяет свойствоdept, со значением «sales», указывая, что все продавцы находятся в одном отделе.Engineerоснован наWorkerBee. Он добавляет свойствоmachine(значение которого по умолчанию пустая строка), а так же определяет свойствоdeptзначением «engineering».
Известно несколько способов определить подходящие функции-конструкторы, которые реализуют иерархию Employee. Выбор способа определения в большей степени зависит от того, на что рассчитано ваше приложение.
В этом разделе приведены очень простые (и сравнительно не гибкие) определения, для демонстрации того, как же работает наследование.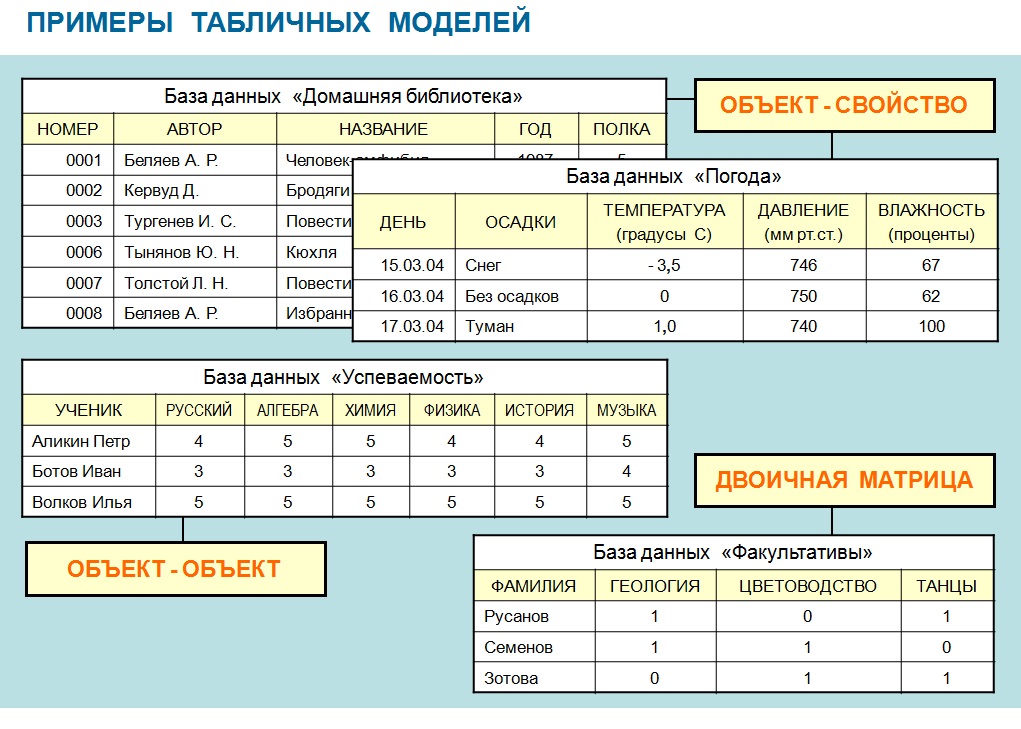 В этих определениях, вы не можете указать значения свойствам при создании объекта. Свойства вновь созданного объекта попросту получают значения по умолчанию, которые можно изменить позднее.
В этих определениях, вы не можете указать значения свойствам при создании объекта. Свойства вновь созданного объекта попросту получают значения по умолчанию, которые можно изменить позднее.
В реальном приложении, вы, вероятно, будете определять конструкторы, которые позволяют устанавливать нужные вам значения свойств во время создания объекта (см Более гибкие конструкторы). В данном же случае конструкторы упрощены сознательно для того, чтобы сфокусироваться на сути наследования.
Следующие определения Employee для языков Java и JavaScript довольно похожи. Единственное отличие состоит в том, что вам необходимо указать тип каждого свойства в Java, но не в JavaScript (потому что Java является строго типизированным языком, в то время как JavaScript слабо типизированный).
| JavaScript | Java |
|---|---|
|
|
Определения классов Manager и WorkerBee показывают разницу в определении вышестоящего объекта в цепочке наследования. В JavaScript вводится связующий объект (прототипный экземпляр), который присваивается в качестве значения свойству
В JavaScript вводится связующий объект (прототипный экземпляр), который присваивается в качестве значения свойству prototype функции-конструктора. Вы можете сделать это в любое время после того, как вы создали конструктор. В Java, необходимо указать суперкласс внутри определения класса. Вы не можете изменить суперкласс вне определения класса.
| JavaScript | Java |
|---|---|
|
|
Классы Engineer и SalesPerson создают объекты, которые происходят от WorkerBee и, следовательно, от Employee. Объект этих типов имеет свойства всех объектов, расположенных над ним в иерархии. Также, эти классы переопределяют наследуемое значение свойства
Объект этих типов имеет свойства всех объектов, расположенных над ним в иерархии. Также, эти классы переопределяют наследуемое значение свойства dept своими значениями, характерными для этих объектов.
| JavaScript | Java |
|---|---|
|
|
Используя эти определения, вы можете создавать экземпляры объектов, которые получат значения по умолчанию для своих свойств. Рисунок 8.3 иллюстрирует использование этих определений и показывает значения свойств у полученных объектов.
Рисунок 8.3 иллюстрирует использование этих определений и показывает значения свойств у полученных объектов.
jane является экземпляром Engineer. Аналогично, хотя термины parent, child, ancestor и descendant (родитель, ребёнок, предок и потомок) не имеют формальных значений в JavaScript, вы можете использовать их неформально для ссылки на объекты выше или нижевцепочке прототипов.null
Рисунок 8.3: Создание объектов с простыми определениями
Этот раздел о том, как объекты наследуют свойства из других объектов в цепочке прототипов, и что происходит, когда вы добавляете свойство во время выполнения.
Наследование свойств
Предположим, вы создаёте объект mark в качестве WorkerBee (как показано на Рисунок 8.3) с помощью следующего выражения:
var mark = new WorkerBee;
Когда JavaScript видит оператор new, он создаёт новый обобщённый объект и неявно устанавливает значение внутреннего свойства [[Prototype]] в WorkerkBee., затем передаёт этот новый объект в качестве значения  prototype
prototypethis в функцию-конструктор WorkerBee. Внутреннее свойство [[Prototype]] определяет цепочку прототипов, используемых для получения значений свойств. После того, как эти свойства установлены, JavaScript возвращает новый объект, а оператор присваивания устанавливает переменную mark для этого объекта.
Этот процесс не задаёт значения свойств (локальных значений), которые унаследованы по цепочке прототипов, объекта mark напрямую. Когда вы запрашиваете значение свойства, JavaScript сначала проверяет, существует ли это значение в данном объекте. Если так и есть, тогда возвращается это значение. Если значение не найдено в самом объекте, JavaScript проверяет цепочку прототипов (используя внутреннее свойство [[Prorotype]]). Если объект в цепочке прототипов имеет значение для искомого свойства, это значение возвращается. Если такое свойство не найдено, JavaScript сообщает, что объект не обладает свойством. Таким образом, объект
Таким образом, объект mark содержит следующие свойства и значения:
mark.name = '';
mark.dept = 'general';
mark.projects = [];
Значения для свойств name и dept объекту mark присваиваются из конструктора Employee. Также из конструктора WorkerBee присваивается локальное значение для свойства projects. Это даёт вам наследование свойств и их значений в JavaScript. Некоторые детали этого процесса обсуждаются в Тонкости наследования свойств.
Поскольку эти конструкторы не позволяют вводить значения, специфичные для экземпляра, добавленная информация является общей. Значения свойств устанавливаются по умолчанию одинаковыми для всех объектов, созданных функцией WorkerBee. Конечно, вы можете изменить значения любого из этих свойств. Так, вы можете добавить специфичную информацию для mark следующим образом:
mark.name = 'Doe, Mark';
mark. dept = 'admin';
mark.projects = ['navigator'];
dept = 'admin';
mark.projects = ['navigator'];Добавление свойств
В JavaScript вы можете добавить свойства для любого объекта в реальном времени. Вы не ограничены только свойствами, установленными функцией-конструктором. Чтобы добавить свойство, специфичное для конкретного объекта, вы присваиваете ему значение в объекте, вот так:
Теперь объект mark имеет свойство bonus, но никакой другой WorkerBee не имеет этого свойства.
Если вы добавляете новое свойство в объект, который используется в качестве прототипа для функции-конструктора, вы добавляете это свойство для всех объектов, наследующих свойства из этого прототипа. Например, вы можете добавить свойство specialty для всех сотрудников с помощью следующего выражения:
Employee.prototype.specialty = 'none';
Как только JavaScript выполняет это выражение, объект mark также получает свойство specialty со значением "none". Следующий рисунок показывает результат добавления этого свойства в прототип
Следующий рисунок показывает результат добавления этого свойства в прототип Employee и последующее переопределение его в прототипе Engineer.
Рисунок 8.4: Добавление свойств
Функции-конструкторы, показанные до сих пор, не позволяют задавать значения свойств при создании экземпляра. Как и в Java, вы можете передать аргументы в конструкторах для инициализации значений свойств экземпляров. На следующем рисунке показан один из способов сделать это.
Рисунок 8.5: Определение свойств в конструкторе, вариант 1
Следующая таблица показывает определения для этих объектов в JavaScript и Java.
| JavaScript | Java |
|---|---|
|
|
|
|
|
|
 name = name;
this.dept = dept;
}
}
name = name;
this.dept = dept;
}
}
В JavaScript эти определения используют специальную идиому для установки значений по умолчанию:
В JavaScript логический оператор ИЛИ (||) оценивает свой первый аргумент. Если этот аргумент преобразуется в true, оператор возвращает его. Иначе, оператор возвращает значение второго аргумента. Следовательно, эта строчка кода проверяет, содержит ли аргумент
Если этот аргумент преобразуется в true, оператор возвращает его. Иначе, оператор возвращает значение второго аргумента. Следовательно, эта строчка кода проверяет, содержит ли аргумент name значение, пригодное для свойства name. Если так и есть, this.name определяется этим значением. В противном случае, значению this.name присваивается пустая строка. Эта глава использует такую идиому для краткости; тем не менее, с первого взгляда она может озадачить.
С помощью таких определений, создавая экземпляр объекта, вы можете указать значения для локально определённых свойств. Как показано на Рисунок 8.5, можно использовать следующее выражение для создания нового Engineer:
var jane = new Engineer('belau');
Свойства созданного объекта jane:
jane.name == '';
jane.dept == 'engineering';
jane.projects == [];
jane.machine == 'belau'
Обратите внимание, что с таким способом вы не можете указать начальное значение наследуемого свойства, такого как name. Если вы хотите задать начальное значение для наследуемых свойств в JavaScript, вам нужно добавить больше кода в функцию-конструктор.
Если вы хотите задать начальное значение для наследуемых свойств в JavaScript, вам нужно добавить больше кода в функцию-конструктор.
До сих пор функция-конструктор создавала обобщённый объект, а затем определяла локальные свойства и значения для нового объекта. Вы можете использовать конструктор, который добавляет дополнительные свойства путём непосредственного вызова функции-конструктора для объекта, расположенного выше в цепочке прототипов. На следующем рисунке показаны эти новые определения.
Рисунок 8.6: Определение свойств в конструкторе, вариант 2
Давайте рассмотрим одно из этих определений детальнее. Вот новое определение функции-конструктора Engineer:
function Engineer (name, projs, mach) {
this.base = WorkerBee;
this.base(name, 'engineering', projs);
this.machine = mach || '';
}
Предположим, вы создаёте новый объект, используя Engineer, следующим образом:
var jane = new Engineer('Doe, Jane', ['navigator', 'javascript'], 'belau');
JavaScript выполняет следующие действия:
- Оператор
newсоздаёт обобщённый объект и устанавливает его свойству__proto__значениеEngineer.. prototype
prototype - Оператор
newпередаёт этот новый объект в конструкторEngineerв качестве значения ключевого словаthis. - Конструктор создаёт новое свойство с именем
baseдля этого объекта и присваивает значение свойстваbaseиз конструктораWorkerBee. Это делает конструкторWorkerBeeметодом объекта, созданногоEngineer. Имя свойстваbaseне является специальным словом. Вы можете использовать любое допустимое для свойства имя;baseвсего-лишь напоминает о предназначении свойства. - Конструктор вызывает метод
base, передавая в качестве аргументов два аргумента, переданных конструктору ("Doe, Jane"и["navigator", "javascript"]), а также строку"engineering". Явное использование"engineering"в конструкторе указывает на то, что все объекты, созданныеEngineer, имеют одинаковое значение для наследуемого свойстваdept, это значение переопределяет значение, унаследованное изEmployee.
- Поскольку
baseявляется методомEngineer, внутри вызоваbaseJavaScript привязывает ключевое свойствоthisк объекту, созданному в шаге 1. Таким образом, функцияWorkerBeeпередаёт поочерёдно аргументы"Doe, Jane"и"engineering"в функцию-конструкторEmployee. Получив результат изEmployee, функцияWorkerBeeиспользует оставшийся аргумент для установки значения свойстваprojects. - После возвращения из метода
base, конструкторEngineerинициализирует свойство объектаmachineсо значением"belau". - После возвращения из конструктора, JavaScript присваивает новый объект переменной
jane.
Можно подумать, что вызвав WorkerBee из конструктора Engineer, вы настроили соответствующим образом наследование для объектов, создаваемых Engineer. Это не так. Вызов конструктора
Это не так. Вызов конструктора WorkerBee обеспечивает только то, что объект Engineer запускается со свойствами, определёнными во всех функциях-конструкторах, которые были вызваны. Так, если позже добавить свойства в прототипы Employee или WorkerBee, эти свойства не наследуются объектами из Engineer. Например, предположим, вы использовали следующие определения:
function Engineer (name, projs, mach) {
this.base = WorkerBee;
this.base(name, 'engineering', projs);
this.machine = mach || '';
}
var jane = new Engineer('Doe, Jane', ['navigator', 'javascript'], 'belau');
Employee.prototype.specialty = 'none';
В примере выше jane не унаследует свойство specialty. Для динамического наследования необходимо явно устанавливать прототип, что и сделано в следующем дополнении:
function Engineer (name, projs, mach) {
this.base = WorkerBee;
this.base(name, 'engineering', projs);
this. machine = mach || '';
}
Engineer.prototype = new WorkerBee;
var jane = new Engineer('Doe, Jane', ['navigator', 'javascript'], 'belau');
Employee.prototype.specialty = "none";
machine = mach || '';
}
Engineer.prototype = new WorkerBee;
var jane = new Engineer('Doe, Jane', ['navigator', 'javascript'], 'belau');
Employee.prototype.specialty = "none";
Теперь свойство specialty объекта jane имеет значение «none».
Другой способ вызвать родительский конструктор в контексте создаваемого объекта это использование методов call() / apply(). Следующие блоки эквивалентны:
|
|
Использование метода call() является более чистой реализацией наследования, так как он не требует создания дополнительного свойства, именованного в примере как base.
В секции выше рассказывалось каким образом конструкторы и прототипы в JavaScript обеспечивают иерархию и наследование. В секции ниже будут затронуты тонкости, которые выше были не так очевидны.
Локальные значения против унаследованных
Когда вы пытаетесь получить значение некоторого свойства объекта, JavaScript выполняет следующие шаги, которые уже перечислялись ранее в этой главе:
- Проверяется, существует ли локальное свойство с запрашиваемым именем. Если да, то возвращается значение этого свойства.
- Если локального свойства не существует, проверяется цепочка прототипов (через использование свойства
__proto__). - Если один из объектов в цепочке прототипов имеет свойство c запрашиваемым именем, возвращается значение этого свойства.
- Если искомое свойство не обнаружено, считается, что объект его не имеет.
Результат выполнения этих шагов будет зависеть от того, в каком порядке вы создаёте объекты, прототипы и их свойства.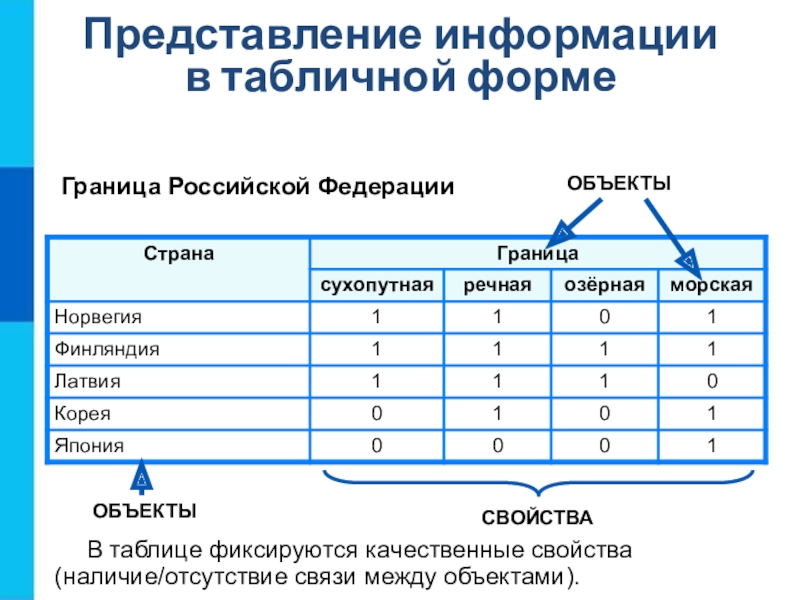 Рассмотрим пример:
Рассмотрим пример:
function Employee () {
this.name = "";
this.dept = "general";
}
function WorkerBee () {
this.projects = [];
}
WorkerBee.prototype = new Employee;
Предположим, на основе конструкции выше, вы создаёте объект amy как экземпляр класса WorkerBee следующим выражением:
В результате, объект amy будет иметь одно локальное свойство — projects. Свойства name и dept не будут локальными для amy но будут взяты из прототипа (объект на который ссылается свойство __proto__ объекта amy). Таким образом, amy имеет три свойства:
amy.name == "";
amy.dept == "general";
amy.projects == [];
Теперь предположим, что вы изменили значение свойства name у прототипа Employee:
Employee.prototype.name = "Unknown"
На первый взгляд вы можете ожидать, что это изменение распространится на все экземпляры Employee. Однако этого не случится.
Однако этого не случится.
Когда вы устанавливаете прототип для WorkerBee вы создаёте новый объект Employee, таким образом WorkerBee.prototype получает своё собственное локальное свойство name (в данном примере пустую строку). Следовательно, когда JavaScript ищет свойство name у объекта amy (экземпляра WorkerBee), он первым делом натыкается на него в прототипе WorkerBee.prototype, и до проверки Employee.prototype дело не доходит.
Если у вас есть необходимость изменять некоторое свойство объекта во время работы приложения, и применять это изменение на все существующие экземпляры, не нужно создавать это свойство внутри конструктора. Вместо этого добавьте свойство в прототип, принадлежащий конструктору. Для примера, предположим, вы изменили код, который был показан выше, следующим образом:
function Employee () {
this.dept = "general";
}
Employee. prototype.name = "";
function WorkerBee () {
this.projects = [];
}
WorkerBee.prototype = new Employee;
var amy = new WorkerBee;
Employee.prototype.name = "Unknown";
prototype.name = "";
function WorkerBee () {
this.projects = [];
}
WorkerBee.prototype = new Employee;
var amy = new WorkerBee;
Employee.prototype.name = "Unknown";
в таком случае свойство name у объекта amy примет значение «Unknown».
Как показано в этом примере, если вы хотите иметь значения свойств по умолчанию, и иметь возможность менять эти значения во время работы приложения, создавайте их в прототипе конструктора, а не в самом конструкторе.
Разбираемся во взаимосвязи экземпляров
Поиск свойств в JavaScript начинается с просмотра самого объекта, и если в нем свойство не найдено, поиск переключается на объект, на который указывает ссылка __proto__. Это продолжается рекурсивно и такой процесс поиска называется «поиск в цепочке прототипов».
Специальное свойство __proto__ устанавливается автоматически при создании объекта. Оно принимает значение свойства prototype функции-конструктора.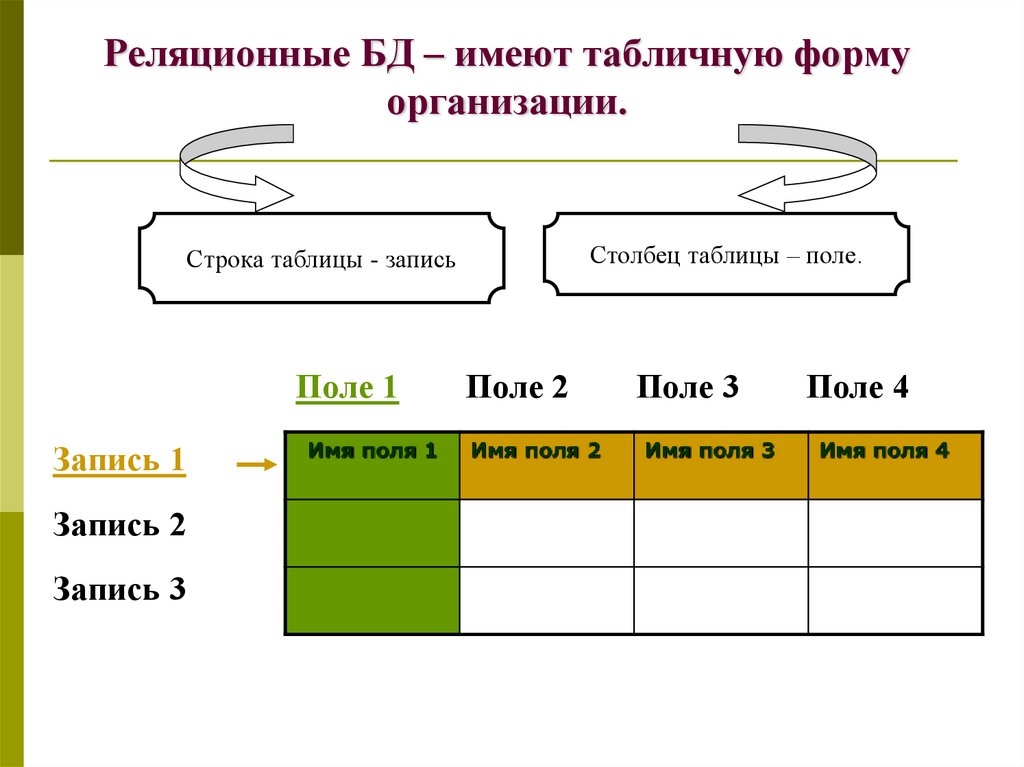 Таким образом,
Таким образом, new Foo() создаст объект для которого справедливо выражение __proto__ == . Вследствие этого, любые изменения свойств у Foo.prototypeFoo.prototype, оказывают эффект на процесс поиска свойств во всех объектах, созданных при помощи new Foo().
Все объекты (за исключением глобального объекта Object) имеют свойство __proto__. Все функции имеют свойство prototype. Благодаря этому, могут быть установлены родственные связи в иерархии объектов. Вы можете установить родство и происхождение объекта, сравнив его свойство __proto__ со свойством prototype конструктора. Здесь JavaScript представляет оператор instanceof как более простой способ проверки, наследуется ли объект от конкретного конструктора. Для примера:
var f = new Foo();
var isTrue = (f instanceof Foo);Для более детального примера, предположим, у вас имеются те же определения, что приведены в разделе Inheriting properties. Создадим экземпляр
Создадим экземпляр Engineer как показано здесь:
var chris = new Engineer("Pigman, Chris", ["jsd"], "fiji");
Для полученного объекта будут истинными все из следующих выражений:
chris.__proto__ == Engineer.prototype;
chris.__proto__.__proto__ == WorkerBee.prototype;
chris.__proto__.__proto__.__proto__ == Employee.prototype;
chris.__proto__.__proto__.__proto__.__proto__ == Object.prototype;
chris.__proto__.__proto__.__proto__.__proto__.__proto__ == null;
Зная это, вы можете написать свою функцию instanceOf как показано ниже:
function instanceOf(object, constructor) {
object = object.__proto__;
while (object != null) {
if (object == constructor.prototype)
return true;
if (typeof object == 'xml') {
return constructor.prototype == XML.prototype;
}
object = object.__proto__;
}
return false;
}
 Это сделано для того, чтобы обойти особенность представления XML объектов в последних версиях JavaScript. Смотрите описание ошибки баг 634150 если вам интересны детали.
Это сделано для того, чтобы обойти особенность представления XML объектов в последних версиях JavaScript. Смотрите описание ошибки баг 634150 если вам интересны детали.
Следующие вызовы функции instanceOf, заданной выше, вернут истинные значения:
instanceOf (chris, Engineer) instanceOf (chris, WorkerBee) instanceOf (chris, Employee) instanceOf (chris, Object)
Но следующее выражение вернёт false:
instanceOf (chris, SalesPerson)
Глобальные данные в конструкторах
При написании конструкторов, следует с особым вниманием относиться к изменению глобальных переменных. Например, если вам нужен уникальный ID, который был бы автоматически назначен каждому экземпляру Employee, вы примените следующий подход для определения Employee:
var idCounter = 1;
function Employee (name, dept) {
this.name = name || "";
this.dept = dept || "general";
this.id = idCounter++;
}
Здесь, когда вы создаёте новый экземпляр Employee, конструктор присваивает ему все новый и новый ID увеличивая значение глобальной переменной idCounter. Следовательно, при выполнении кода ниже,
Следовательно, при выполнении кода ниже, victoria.id станет равным 1 а harry.id — 2:
var victoria = new Employee("Pigbert, Victoria", "pubs")
var harry = new Employee("Tschopik, Harry", "sales")
Навскидку, все выглядит предсказуемо. Однако, idCounter увеличивается при создании каждого объекта Employee вне зависимости от цели его создания. Если вы создаёте полную иерархию класса Employee, показанную выше в этой главе, конструктор Employee будет так же вызван каждый раз, когда вы устанавливаете прототип для подклассов. Следующий код раскрывает суть возможной проблемы:
var idCounter = 1;
function Employee (name, dept) {
this.name = name || "";
this.dept = dept || "general";
this.id = idCounter++;
}
function Manager (name, dept, reports) {...}
Manager.prototype = new Employee;
function WorkerBee (name, dept, projs) {...}
WorkerBee.prototype = new Employee;
function Engineer (name, projs, mach) {. ..}
Engineer.prototype = new WorkerBee;
function SalesPerson (name, projs, quota) {...}
SalesPerson.prototype = new WorkerBee;
var mac = new Engineer("Wood, Mac");
..}
Engineer.prototype = new WorkerBee;
function SalesPerson (name, projs, quota) {...}
SalesPerson.prototype = new WorkerBee;
var mac = new Engineer("Wood, Mac");
Предположим, каждый из конструкторов, тело которого опущено для краткости, содержит вызов конструктора прародителя. Это приведёт к тому, что id у объекта mac примет значение 5 вместо ожидаемой единицы.
В зависимости от приложения, лишние увеличения счётчика могут быть не критичны. В случае же, когда точный контроль за значениями счётчика важен, одним из возможных решений станет такой код:
function Employee (name, dept) {
this.name = name || "";
this.dept = dept || "general";
if (name)
this.id = idCounter++;
}
Когда вы создаёте экземпляр Employee в качестве прототипа, вы не предоставляете аргументы в конструктор за ненадобностью. Конструктор выше проверяет наличие аргумента name, и в случае, если значение не указано, идентификатор id объекту не присваивается, а значение глобального счётчика idCounter не увеличивается. Таким образом, для получения уникального
Таким образом, для получения уникального id становится обязательным указание параметра name при вызове конструктора Employee. С внесёнными в пример выше изменениями, mac.id станет равным долгожданной, заветной единице.
Никакого множественного наследования
Некоторые из объектно-ориентированных языков предоставляют возможность множественного наследования. Когда один объект может унаследовать свойства и методы множества других, не связанных друг с другом объектов. В JavaScript такого не предусмотрено.
В JavaScript наследование свойств осуществляется путём поиска в цепочке прототипов. Так как объект может иметь лишь единственный присвоенный ему прототип, JavaScript не может осуществить наследование более чем от одной цепочки прототипов.
Однако конструктор в JavaScript может вызывать любое количество вложенных конструкторов. Это даёт некоторую, хоть и ограниченную (отсутствием прототипной связанности) видимость множественного наследования. Рассмотрим следующий фрагмент:
Рассмотрим следующий фрагмент:
function Hobbyist (hobby) {
this.hobby = hobby || "scuba";
}
function Engineer (name, projs, mach, hobby) {
this.base1 = WorkerBee;
this.base1(name, "engineering", projs);
this.base2 = Hobbyist;
this.base2(hobby);
this.machine = mach || "";
}
Engineer.prototype = new WorkerBee;
var dennis = new Engineer("Doe, Dennis", ["collabra"], "hugo")
Предполагается, что определение WorkerBee задано ранее, как уже было показано в этой главе. В таком случае список свойств для объекта dennis примет следующий вид:
dennis.name == "Doe, Dennis"
dennis.dept == "engineering"
dennis.projects == ["collabra"]
dennis.machine == "hugo"
dennis.hobby == "scuba"
Мы видим, что dennis получил свойство hobby из конструктора Hobbyist. Однако, если вы добавите любое свойство в прототип конструктора Hobbyist:
Hobbyist.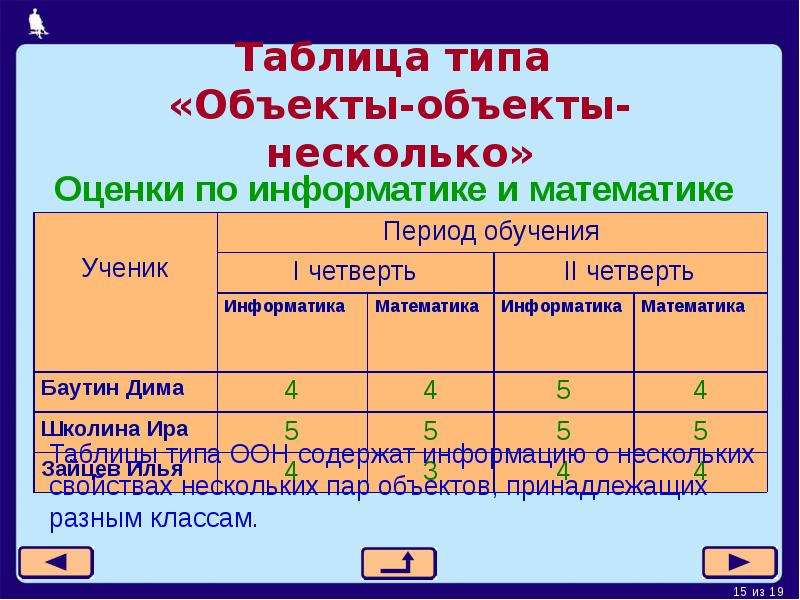 prototype.equipment = ["mask", "fins", "regulator", "bcd"]
prototype.equipment = ["mask", "fins", "regulator", "bcd"]
Объект dennis этого свойства не унаследует.
Структура и правила оформления таблиц (7 класс) Информатика и ИКТ
Для описания ряда объектов, обладающих одинаковыми наборами свойств, наиболее часто используются таблицы, состоящие из столбцов и строк.
Вам хорошо известно табличное представление расписания уроков, в табличной форме представляются расписания движения автобусов, самолетов, поездов и многое другое.
Представленная в таблице информация наглядна, компактна и легко обозрима.
В таблице может содержаться информация о различных свойствах объектов, об объектах одного класса и разных классов, об отдельных объектах и группах объектов.
Правильно оформленная таблица имеет структуру:
Необходимо соблюдать следующие правила оформления таблиц.
- Заголовок таблицы должен давать представление о содержащейся в ней информации.
- Заголовки граф и строк должны быть краткими, не содержать лишних слов и, по возможности, сокращений.

- В таблице должны быть указаны единицы измерения. Если они общие для всей таблицы, то указываются в заголовке таблицы (либо в скобках, либо через запятую после названия). Если единицы измерения различаются, то они указываются в заголовках строк или граф.
- Желательно, чтобы все ячейки таблицы были заполнены. При необходимости в них заносят следующие условные обозначения:
- ? — данные неизвестны;
- х — данные невозможны;
- ↓ — данные должны быть взяты из вышележащей ячейки.
Для того чтобы на основании информации, представленной в текстовой форме, составить табличную модель, необходимо:
- выделить в тексте имена объектов, имена свойств объектов и значения свойств объектов;
- уточнить структуру таблицы;
- «заселить» таблицу, перенеся в нее информацию из текста.
При выделении в тексте имен объектов, имен свойств и их значений удобно подчеркивать их разными линиями. Договоримся подчеркивать имена объектов прямой, имена свойств — двойной, а значения свойств — пунктирной линиями.
Например:
Каждое из рассмотренных в этих примерах свойств ( «столица», «глубина», «имя») характеризует только один объект. Такие свойства будем называть одиночными.
Очень часто свойство характеризует сразу пару объектов. Такое парное свойство договоримся подчеркивать тройной линией.
Например:
У словно все множество таблиц можно разделить на простые и сложные.
Коротко о главном:
- Для описания ряда объектов, обладающих одинаковыми наборами свойств, наиболее часто используются таблицы, состоящие из столбцов и строк. Представленная в таблице информация наглядна, компактна и легко обозрима.
Вопросы и задания:
- Какие преимущества обеспечивают табличные информационные модели по сравнению со словесными описаниями? Приведите пример.
- Любое ли словесное описание можно заменить табличной информационной моделью? Приведите пример.
- Приведите примеры табличных информационных моделей, с которыми вы сталкивались на уроках в школе.

(Таблица умножения, таблица Брадиса, таблица Менделеева, школьный дневник, школьный журнал, расписание уроков.) - Приведите примеры табличных информационных моделей, с которыми вы сталкивались в повседневной жизни.
(Школьный дневник, расписание автобусов, меню, сканворды и кроссворды, календари) - Каких правил следует придерживаться при составлении таблиц?
- Информация каких видов размещается в графах таблицы? Можно ли там размещать графические изображения? Приведите пример.
Содержание
Access 2013: Введение в объекты
Урок 4: Знакомство с объектами
/ ru / access2013 / Introduction-to-databases / content /
Введение
Базы данных в Access состоят из четырех объектов: таблиц , запросов , форм и отчетов . Вместе эти объекты позволяют вам вводить, хранить, анализировать и компилировать ваши данные, как вы хотите.
В этом уроке вы узнаете о каждом из четырех объектов и поймете, как они взаимодействуют друг с другом для создания полнофункциональной реляционной базы данных.
Таблицы
К этому моменту вы уже должны понимать, что база данных — это совокупность данных, организованных во множество связанных списков . В Access все данные хранятся в таблиц , что делает таблицы основой любой базы данных.
Возможно, вы уже знаете, что таблицы организованы в вертикальных столбцов и горизонтальных строк .
Строки и столбцы в таблице доступа В Access строки и столбцы называются записями и полями .Поле — это больше, чем просто столбец; это способ организации информации по типу данных. Каждая часть информации в поле относится к одному и тому же типу . Например, каждая запись в поле с названием Имя будет именем, а каждая запись в поле с названием Street Address будет адресом.
Каждая часть информации в поле относится к одному и тому же типу . Например, каждая запись в поле с названием Имя будет именем, а каждая запись в поле с названием Street Address будет адресом.
Аналогично, запись — это больше, чем просто строка; это единица информации. Каждая ячейка в данной строке является частью записи этой строки.
ЗаписьОбратите внимание, что каждая запись занимает несколько полей. Несмотря на то, что информация в каждой записи организована в поля, она принадлежит другой информации в этой записи. Видите номер слева в каждой строке? Идентификационный номер идентифицирует каждую запись. Идентификационный номер записи относится к каждой части информации, содержащейся в этой строке.
Запись идентификационных номеров Таблицы хороши для хранения тесно связанной информации .Допустим, у вас есть пекарня и база данных, которая включает в себя таблицу с именами и информацией ваших клиентов, такими как их номера телефонов, домашние адреса и адреса электронной почты. Поскольку все эти фрагменты информации являются подробными сведениями о ваших клиентах, вы должны включить их все в одну таблицу . Каждый покупатель будет представлен уникальной записью , и каждый тип информации об этих покупателях будет храниться в своем собственном поле. Если вы решили добавить дополнительную информацию — например, день рождения клиента — вы просто создадите новое поле в той же таблице.
Поскольку все эти фрагменты информации являются подробными сведениями о ваших клиентах, вы должны включить их все в одну таблицу . Каждый покупатель будет представлен уникальной записью , и каждый тип информации об этих покупателях будет храниться в своем собственном поле. Если вы решили добавить дополнительную информацию — например, день рождения клиента — вы просто создадите новое поле в той же таблице.
Формы, запросы и отчеты
Хотя в таблицах хранятся все ваши данные, три других объекта — формируют , запросов и отчеты — предлагают способы работы с ними. Каждый из этих объектов взаимодействует с записями , хранящимися в таблицах вашей базы данных.
Формы
Формы используются для ввода , для изменения и для просмотра записей. Скорее всего, вам приходилось заполнять формы во многих случаях, например, когда вы посещали кабинет врача, устраивались на работу или записывались в школу. Формы используются так часто, потому что они помогают людям правильно вводить данные. Когда вы вводите информацию в форму в Access, данные поступают именно туда, куда хочет их разработчик: в одну или несколько связанных таблиц.
Формы используются так часто, потому что они помогают людям правильно вводить данные. Когда вы вводите информацию в форму в Access, данные поступают именно туда, куда хочет их разработчик: в одну или несколько связанных таблиц.
упрощают ввод данных. Работа с обширными таблицами может сбивать с толку, и когда вы подключили таблицы, вам может потребоваться работать с несколькими таблицами одновременно, чтобы ввести набор данных. Однако с помощью форм можно одновременно вводить данные в несколько таблиц в одном месте.Разработчики баз данных могут даже установить ограничения для отдельных компонентов формы, чтобы все необходимые данные были введены в правильном формате. В общем, формы помогают поддерживать последовательность и организованность данных, что очень важно для точной и мощной базы данных.
Запросы
Запросы — это способ поиска и компиляции данных из одной или нескольких таблиц. Выполнение запроса похоже на задание подробного вопроса вашей базы данных. Когда вы создаете запрос в Access, вы определяете конкретные условия поиска , чтобы найти именно те данные, которые вам нужны.
Когда вы создаете запрос в Access, вы определяете конкретные условия поиска , чтобы найти именно те данные, которые вам нужны.
Запросы намного мощнее, чем простой поиск, который вы можете выполнить в таблице. В то время как поиск может помочь вам найти имя одного клиента в вашей компании, вы можете запустить запрос , чтобы найти имя и номер телефона каждого клиента, совершившего покупку за последнюю неделю. Хорошо продуманный запрос может предоставить информацию, которую вы, возможно, не сможете найти, просто просматривая данные в своих таблицах.
Разработка запросаОтчеты
Отчеты предлагают вам возможность представить ваши данные в печатном виде .Если вы когда-либо получали компьютерную распечатку расписания занятий или распечатанный счет за покупку, вы видели отчет из базы данных. Отчеты полезны, потому что они позволяют вам представить компоненты вашей базы данных в удобном для чтения формате.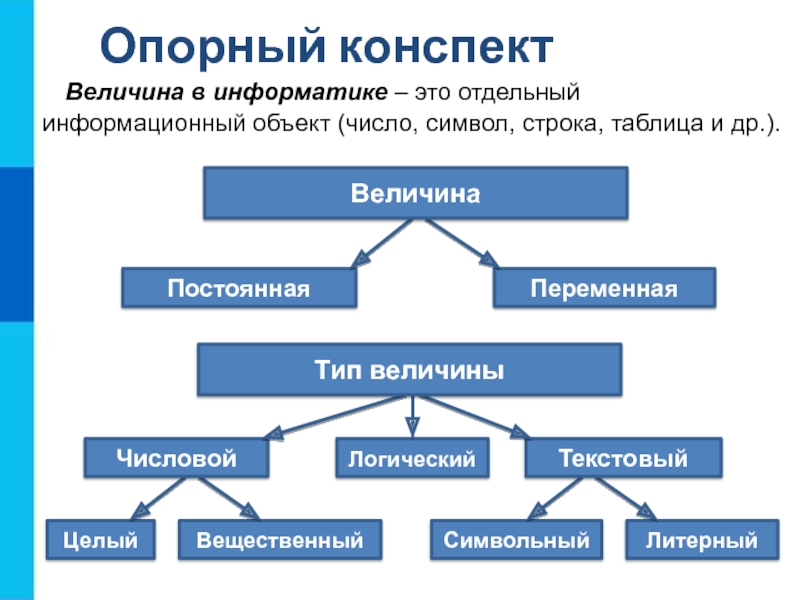 Вы даже можете настроить внешний вид отчета, чтобы сделать его визуально привлекательным. Access предлагает вам возможность создать отчет из любой таблицы или запроса .
Вы даже можете настроить внешний вид отчета, чтобы сделать его визуально привлекательным. Access предлагает вам возможность создать отчет из любой таблицы или запроса .
Собираем все вместе
Даже если у вас есть хорошее представление о том, как можно использовать каждый объект, сначала может быть трудно понять, как все они работают вместе.Помните, что все они работают с одними и теми же данными. Каждый фрагмент данных, который использует запрос , из или отчет, который использует , хранится в одной из таблиц вашей базы данных.
Четыре объекта доступа Формы позволяют как добавлять данные в таблицы, так и просматривать данные , которые уже существуют. Отчеты представляют данные из таблиц, а также из запросов, которые затем ищут и анализируют данные в тех же таблицах.
Эти отношения кажутся сложными, но на самом деле они работают вместе настолько хорошо и естественно, что мы часто даже не замечаем, когда используем связанные объекты базы данных. Вы когда-нибудь использовали электронный карточный каталог для поиска книги в библиотеке? Скорее всего, вы вошли в поисковый запрос примерно так:
Электронный карточный каталогПри выполнении поиска вы вводили условия поиска в форму , которая затем создала и выполнила запрос на основе вашего запроса.Когда запрос завершил поиск в таблицах базы данных записей, соответствующих вашему поисковому запросу, вам был показан отчет , в котором была извлечена информация из запроса и связанных таблиц — в данном случае это список книг, соответствующих условиям вашего поиска. Вы можете представить связи между объектами следующим образом:
Поиск книги. Данные, представленные в форме, используются в запросе к базе данных, который извлекает данные из соответствующих таблиц. Результаты запроса представлены в отчете.
Результаты запроса представлены в отчете.Допустим, вместо использования этих инструментов вам пришлось искать в гигантской таблице, содержащей все книги в библиотечной системе. Соответствующие записи, вероятно, будут распределены по множеству таблиц: таблица названий и описаний книг, таблица, содержащая информацию о том, какие книги возвращены или выгружены, и таблица с каждой ветвью библиотеки, и это лишь некоторые из них.
Для того, чтобы найти книгу, узнать ее местонахождение и проверить, отметили ли она, вам нужно будет выполнить поиск по крайней мере в трех таблицах! Легко представить, насколько сложно найти подходящую книгу.Если вы не будете осторожны, вы можете даже что-то испортить, случайно удалив или отредактировав запись. Легко увидеть, как объекты базы данных делают этот поиск более управляемым.
В нашем уроке «Введение в базы данных» мы обсудили концепцию реляционной базы данных , которая представляет собой базу данных, способную понять, как разные наборы данных соотносят друг с другом. Именно в таких ситуациях, как приведенный выше пример, люди находят реляционные базы данных такими полезными.Без реляционной базы данных то, что должно быть простой задачей — поиск книги и проверка того, зарегистрировано ли она и где — становится невероятно сложной и требует много времени. Знание того, как использовать четыре объекта Access, может сделать даже сложные задачи довольно удобными для пользователя.
Именно в таких ситуациях, как приведенный выше пример, люди находят реляционные базы данных такими полезными.Без реляционной базы данных то, что должно быть простой задачей — поиск книги и проверка того, зарегистрировано ли она и где — становится невероятно сложной и требует много времени. Знание того, как использовать четыре объекта Access, может сделать даже сложные задачи довольно удобными для пользователя.
/ ru / access2013 / Getting-started-with-access / content /
| Аннотация | Указывает, поддерживает ли таблица наследование.Значение по умолчанию — Нет. Если значение Да, таблица не может быть прямой целью операторов X ++ SQL, таких как update_recordset и select. Это свойство недоступно, если для свойства SupportInheritance задано значение Нет. Дополнительные сведения см. В разделе Обзор наследования таблиц. | AX 2012 | ||||
| AnalysisDimensionType | Определяет тип измерения, созданного на основе значения свойства IsLookup. Вы можете указать одно из следующих значений. Вы можете указать одно из следующих значений.
|
|||||
| Идентификатор анализа | Задает поле, которое будет использоваться в качестве идентификатора измерения в кубе служб SQL Server Analysis Services (SSAS). | |||||
| Авторизация AOS | Задает тип операции, которую пользователь может выполнять с таблицей, в зависимости от полномочий пользователя. Если для свойства установлено значение Нет , проверка авторизации не выполняется. | |||||
| CacheLookup | Определяет, как кэшировать записи, полученные во время операции поиска. Это свойство CacheLookup существует только для таблиц, которые не наследуются от другой таблицы.В корневой таблице наследования это свойство не может быть установлено на Полная таблица с помощью окна свойств AOT. Вы не должны использовать другие методы для присвоения этого значения корневым таблицам наследования. Например, не используйте метод AOTsetProperty класса TreeNode для присвоения этого значения. Вы не должны использовать другие методы для присвоения этого значения корневым таблицам наследования. Например, не используйте метод AOTsetProperty класса TreeNode для присвоения этого значения. |
|||||
| ClusterIndex | Задает индекс кластера. Это свойство используется только в целях оптимизации SQL. | |||||
| Ключ конфигурации | Задает ключ конфигурации для таблицы.Ключи конфигурации позволяют системному администратору включать и отключать определенные части приложения. | |||||
| Страна Код региона | Задает коды регионов страны, для которых таблица применима или действительна. Клиентская платформа и приложение могут использовать это свойство для включения или отключения функций, специфичных для страны или региона. Это реализовано в виде списка кодов стран ISO, разделенных запятыми, в одной строке. Значения должны соответствовать данным, содержащимся в глобальной адресной книге. |
AX 2012 | ||||
| СтранаRegionContextField | Задает поле, которое будет использоваться для определения контекста страны. Это относится к свойству CountryRegionCodes . | AX 2012 | ||||
| Создано пользователем | Указывает, поддерживает ли система поле CreatedBy для записей в таблице. Это поле содержит информацию о том, кто создал конкретную запись. | |||||
| CreatedDateTime | Указывает, поддерживает ли система поля CreationDate и CreationTime для записей в таблице.Это поле содержит дату создания записи. | AX 2012 | ||||
| CreatedTransactionId | Указывает, поддерживает ли система поле CreatedTransactionId для записей в таблице. Это поле содержит информацию о том, какая транзакция создала запись. |
|||||
| CreateRecIdIndex | Указывает, создан ли индекс для поля ID записи . | |||||
| Документация для разработчиков | Описывает назначение таблицы и объясняет, как она используется.Описание обычно состоит не более чем из пяти предложений и пишется как один абзац. | |||||
| EntityRelationshipType | Классифицирует таблицу в соответствии с нотацией модели данных общего отношения сущностей (ER). Таблица классифицируется как объект или отношение. Сущность представляет собой объект. Отношение представляет собой связь между двумя объектами. | |||||
| Удлинитель | Производит таблицу из другой таблицы, выбранной в качестве значения свойства.Значение равно null, если для свойства SupportInheritance задано значение Yes. Для получения дополнительной информации см. Обзор наследования таблиц. |
AX 2012 | ||||
| FormRef | Задает элемент меню отображения, который активируется при обращении к таблице. Пункт меню отображения связан с формой. Когда вы используете в отчете поле первичного индекса, эта форма доступна в виде ссылки в отчете. Первичный индекс указывается с помощью свойства PrimaryIndex .Если оставить это поле пустым, система попытается отобразить форму, имя которой совпадает с именем таблицы. | |||||
| ID | Задает идентификатор таблицы, созданный системой. Дополнительные сведения см. В разделе «Идентификаторы объектов приложения». | |||||
| IsLookup | Для моделей отчетов он указывает, включается ли информация таблицы в другие таблицы, которые ссылаются на нее при создании модели отчета. Для кубов OLAP он определяет, следует ли создавать консолидированное измерение или отдельное измерение.Вы можете указать одно из следующих значений.
|
|||||
| Этикетка | Задает метку для таблицы. | |||||
| ListPageRef | Задает элемент меню отображения, указывающий на форму, которая может отображать список этого типа записи. | AX 2012 | ||||
| Модель | Указывает, в какой модели находится таблица. Модель — это логическая группа элементов в слое. Элемент может существовать только в одной модели в слое. Примеры элементов — таблица или класс. Тот же элемент может существовать в настроенной версии в модели на более высоком уровне. |
AX 2012 | ||||
| Изменено по | Указывает, поддерживает ли система поле ModifiedBy для записей в таблице. В этом поле записывается лицо, выполнившее последнее изменение записи. | |||||
| ModifiedDateTime | Указывает, поддерживает ли система поле ModifiedDateTime для записей в таблице. В этом поле записывается дата последнего изменения записи. | |||||
| ModifiedTime | Указывает, поддерживает ли система поле ModifiedTime для записей в таблице. В этом поле записывается время последнего изменения записи. | |||||
| Имя | Задает имя таблицы. | |||||
| Занято | Указывает, включен ли для таблицы режим оптимистичного параллелизма. Когда этот режим включен, данные не блокируются от будущих изменений при их извлечении из базы данных. Данные блокируются только тогда, когда выполняется фактическое обновление. Данные блокируются только тогда, когда выполняется фактическое обновление. |
|||||
| PreviewPartRef | Задает информационную часть или часть формы, которые будут использоваться в расширенном предварительном просмотре. Информационная часть показывает набор полей данных из указанного запроса. Информационная часть использует метаданные для описания того, как данные отображаются. Часть формы представляет собой указатель на форму. | AX 2012 | ||||
| Первичный индекс | Задает первичный индекс.Можно выбрать только уникальный индекс. Свойство используется для оптимизации базы данных и для указания того, какой уникальный индекс использовать в качестве ключа кэширования. Если первичный индекс не указан, в качестве ключа кэширования используется уникальный индекс с наименьшим идентификатором. | |||||
| Запасной ключ | Задает поля, отображаемые в качестве идентификатора данных в некоторых элементах управления формой. |
AX 2012 | ||||
| ReportRef | Задает пункт меню вывода, который активируется при обращении к таблице.Пункт меню вывода связан с отчетом. Когда вы используете в отчете поле первичного индекса, этот отчет доступен в виде ссылки в отчете. Первичный индекс указывается с помощью свойства PrimaryIndex. | |||||
| SaveDataPerCompany | Указывает, сохранены ли данные для текущей компании. Если установить для свойства значение № , данные сохраняются без идентификатора компании (DataAreaId).
|
|||||
| SaveDataPerPartition | Показывает, есть ли в таблице системное поле с именем Partition . Это системное поле предназначено только для чтения. Если в таблице есть поле Partition , каждая запись назначается одному разделу.Каждая запись скрыта от операций доступа к данным, которые выполняются в контексте других разделов. | ТОП 2012 R2 | ||||
| SearchLinkRefName | Задает имя элемента меню, который ссылается на информацию на веб-сайте о записи таблицы, указанной в результатах поиска корпоративного портала. Если для свойства SearchLinkRefType задано значение URL, выберите пункт меню из списка свойств SearchLinkRefName , который ведет на страницу веб-части, отображающую данные таблицы.Формы и отчеты на страницах веб-частей могут отображать данные. |
|||||
| SearchLinkRefType | Задает тип элемента меню, который ссылается на информацию на веб-сайте о записи таблицы, указанной в результатах поиска корпоративного портала. | |||||
| SingularLabel | Задает метку, которая используется в модели отчета или кубе для отображения единственного имени элементов, хранящихся в таблице. | |||||
| Поддержка Наследование | Установка этого свойства на Да позволяет вам установить значение для других свойств, связанных с наследованием, таких как Extends и Abstract .
 |
AX 2012 | ||||
| Системный стол | Указывает, отображается ли таблица как системная. Затем его можно отфильтровать во время экспорта и импорта. Системные таблицы всегда синхронизируются при входе в систему.Это может быть полезно для таблиц, которые вы используете сразу после входа в систему. | |||||
| Содержание таблицы | Определяет, как данные настройки / параметров могут быть повторно использованы от одного клиента к другому. Возможны следующие значения:
|
|||||
| TableGroup | Определяет, к какой группе принадлежит таблица. Группы таблиц предоставляют метод категоризации таблиц в соответствии с типом содержащихся в них данных. Группы таблиц можно использовать для определения, должна ли система запрашивать пользователей, когда они обновляют или удаляют таблицу в формах, используя таблицу в качестве источника данных.При экспорте данных вы можете использовать группы таблиц для фильтрации записей. | |||||
| TableType | Заменяет свойство Temporary в Microsoft Dynamics AX 2009. Дополнительные сведения см. В разделах «Временные таблицы» и «Свойство TableType». | AX 2012 | ||||
| Поле заголовка1 , Поле заголовка2 | Позволяет делать следующее:
|
|||||
| TypicalRowCount | Задает количество записей, которые обычно появляются в таблице.Если свойство AnalysisSelection не задано, свойство TypicalRowCount определяет способ выбора записей с помощью построителя отчетов для служб отчетов Microsoft SQL Server. Параметр свойства TypicalRowCount влияет на то, используется ли раскрывающийся список, поле со списком или отфильтрованный список для выбора записей таблицы. Дополнительные сведения см. В разделе Рекомендации для свойств таблиц. В разделе Рекомендации для свойств таблиц. |
|||||
| ValidTimeStateFieldType | Задает тип поля даты и времени, используемого системой при отслеживании данных в промежутках времени. | AX 2012 | ||||
| Видимый | Задает права доступа, когда таблица используется в качестве источника данных в форме или отчете. Если таблица используется в качестве источника данных в форме, то права доступа в форме не могут превышать права доступа, определенные для таблицы. |

 Этот параметр следует использовать, когда таблица содержит только транзакционные данные. Создается одно дочернее измерение, содержащее только значения перечисления из таблицы.
Этот параметр следует использовать, когда таблица содержит только транзакционные данные. Создается одно дочернее измерение, содержащее только значения перечисления из таблицы.  Двойной щелчок по аббревиатуре открывает диалоговое окно для перехода к другой компании.
Двойной щелчок по аббревиатуре открывает диалоговое окно для перехода к другой компании.  Например, план счетов не зависит от клиента в Германии, но используется в большинстве других мест в мире.
Например, план счетов не зависит от клиента в Германии, но используется в большинстве других мест в мире. 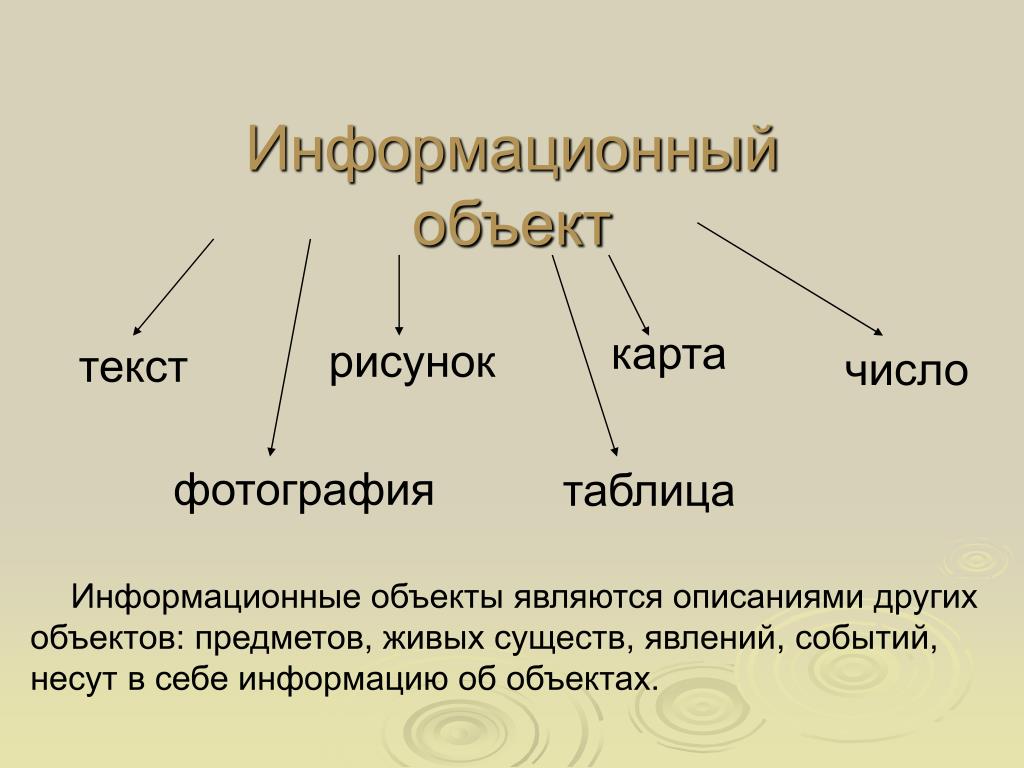
Что такое объект данных? Определение, типы и примеры — ответы аналитика
Если вы когда-либо пытались понять объекты данных из учебника или официальной документации, вы, вероятно, запутались.Объект данных — это простая концепция, но их смысл обычно теряется в плотных формулировках.
Цель этой статьи — четко определить объекты данных, объяснить их различные типы и предоставить примеры, чтобы вы ушли с чистыми основами по теме. Итак, давайте начнем с основ: что такое объект данных?
Итак, давайте начнем с основ: что такое объект данных?
Определение и описание объекта данных
Объект данных — это набор из одной или нескольких точек данных, которые создают смысл в целом. Другими словами, «объект данных» — это альтернативный способ сказать «эту группу данных следует рассматривать как отдельную».
Наиболее распространенным примером объекта данных является таблица данных , но другие включают массивы, указатели, записи, файлы, наборы и скалярные типы.
Значения в объекте данных могут иметь свои собственные уникальные идентификаторы, типы данных и атрибуты. Таким образом, объекты данных различаются в зависимости от структуры базы данных и разных языков программирования.
Проще всего думать о как о термине «объект данных», поскольку он отражает простую потребность в разделении информации в базе данных, которая в противном случае выглядит большой и сбивает с толку .
Помимо разделения, аналитики данных используют уникальные идентификаторы, типы данных и атрибуты, чтобы сделать данные еще более понятными. Эти объекты данных почти всегда представлены в моделях данных, которые показывают отношения между объектами данных.
В виде списка объекты данных состоят из:
- Значения. Сами данные.
- Уникальные идентификаторы . Одна точка данных, которая идентифицирует других, связанных с ней.
- Атрибуты . Дополнительные данные в рамках одного Уникального идентификатора.
- Типы данных . Классификации данных, такие как текстовые, числовые и логические.
ПРИМЕЧАНИЕ: тонкость и главный источник путаницы вокруг объектов данных касается «типов данных». В некоторых языках программирования «объект данных» означает отдельное значение одного «типа данных» или другого зависящего от языка определения.Аналитики зависят от контекста, чтобы различать объекты данных в виде таблиц и других типов.
Пример объектов данных в базах данных
Представьте, что вы управляете компанией электронной коммерции, которая продает часы розничным торговцам. Ваша компания называется Batch Watch , и ее основными подразделениями являются поставщиков , продуктов и клиентов . Со временем вы создали сложную базу данных с большим объемом данных.
Как необработанная база данных, ваши данные выглядят как огромная таблица.Практически невозможно концептуализировать или извлечь понимание из данных в этом формате. Вместо этого вы нанимаете внешнего консультанта для построения модели данных, которая поможет вам понять. Что в вашей модели данных? Вы догадались: объекты данных.
Эти объекты данных являются подмножествами вашей огромной базы данных. Например, в то время как огромная база данных содержит данных поставщика, продукта и клиента , объект данных может содержать только данные поставщика . Другой содержит данные о продукте.И еще одно — данные о клиентах.
Другой содержит данные о продукте.И еще одно — данные о клиентах.
Как вы могли догадаться, эти объекты данных могут по-прежнему содержать немыслимое количество данных. Вот почему объекты данных на самом деле имеют 2 «представления» или структуры: базовая таблица данных и представление блочного типа. Давайте вкратце рассмотрим их:
- Базовые таблицы данных . Это таблицы данных, состоящие из столбцов и строк. Вот очень простой пример таблицы данных поставщика с уникальным идентификатором и 3 атрибутами:
Хотя наш пример здесь упрощен, объект данных может быть довольно громоздким для понимания.Кто может легко помещать слои или строки и столбцы в контекст? По моему опыту, не много. Вот почему существует второе представление: представление объекта данных в виде прямоугольника.
- Коробчатый вид. В представлении блочного стиля отображаются только заголовки столбцов в таблице данных, чтобы суммировать объект .
 Вот прямоугольное представление таблицы данных выше, в котором метаданные используются в качестве сводки:
Вот прямоугольное представление таблицы данных выше, в котором метаданные используются в качестве сводки:
Ссылка <
Типы объектов данных в базах данных
До этого момента мы говорили исключительно о таблицах данных, но это не единственный тип объектов данных. Вот список дополнительных объектов данных, с которыми аналитики сталкиваются при работе с базами данных:
- Массивы
- Указатели
- Записи
- Файлы
- Наборы
- Скалярные типы
Массивы
Массивы — это объекты данных, которые имеют только одно измерение . Вы можете думать о них как об одном столбце в таблице данных. Аналитики используют массивы, когда их данные недостаточно подробны, чтобы их можно было составить в виде таблицы.
Вы можете думать о них как об одном столбце в таблице данных. Аналитики используют массивы, когда их данные недостаточно подробны, чтобы их можно было составить в виде таблицы.
Записи
Записи — это объекты данных, которые содержат по одной записи данных для каждого измерения в таблице данных . Вы можете рассматривать записи данных как одну строку в таблице данных. Аналитики используют записи каждый раз, когда они вводят наблюдение, которые обычно имеют значения для каждого измерения в таблице.
Указатели
Указатель объекта данных — это специальное значение данных, которое указывает расположение в памяти другой точки данных или группы точек данных. В большинстве случаев указатель включается в столбец таблицы как отдельное измерение.
Файлы
Файлы объектов данных используют код, чтобы гарантировать, что другие объекты данных используют правильную структуру . Хотя они не являются исполняемыми, как другие объекты данных, файлы объектов данных бесценны. Они обеспечивают целостность данных, обеспечивая ввод данных в одном формате. Простой способ концептуализировать файлы состоит в том, что, в отличие от других объектов данных, вы не можете просматривать их в простом программном обеспечении для баз данных, таком как Excel.
Хотя они не являются исполняемыми, как другие объекты данных, файлы объектов данных бесценны. Они обеспечивают целостность данных, обеспечивая ввод данных в одном формате. Простой способ концептуализировать файлы состоит в том, что, в отличие от других объектов данных, вы не можете просматривать их в простом программном обеспечении для баз данных, таком как Excel.
Наборы
Наборы объектов данных объединяют несколько объектов данных и, в большинстве случаев, таблицы . Таким образом, наборы данных занимают уровень иерархии между таблицами данных и базами данных. Обычно аналитики используют сокращенный термин «набор данных» для обозначения наборов объектов данных. Кроме того, этот термин стал термином по умолчанию для всех объектов данных.
Скаляр
Объект скалярных данных указывает на одно значение, а не на агрегацию, такую как таблицы данных, массивы и записи. При этом термин «скалярные данные» принимает разные значения в зависимости от системы управления базами данных или языка программирования.
ПРИМЕЧАНИЕ. В дополнение к этим типам объектов данных существует еще один уровень «типа объекта данных» для языков программирования. Типы объектов данных программирования более сложные и тонкие и часто зависят от «типов данных». Давайте теперь посмотрим на них.
Визуальное представление типов объектов данных и их взаимосвязей
Вот диаграмма, которая поможет вам понять различные типы объектов данных:
Схема типов объектов данных и их взаимосвязейОбъекты данных в языках программирования: нюансы зависимых от языка определений
Существенная путаница в отношении объектов данных заключается в использовании терминов «объект данных» и «тип данных» как синонимы.В формальной документации по языкам программирования вы часто встретите объекты данных, определенные либо как как тип данных, либо на как тип данных.
Если вы не знакомы, типы данных — это категории данных, основанные на их основных характеристиках. Типы данных включают «текст», «целое число», «данные», «время» и «логическое значение». (Дополнительные сведения о типах данных см. В этой статье.)
Типы данных включают «текст», «целое число», «данные», «время» и «логическое значение». (Дополнительные сведения о типах данных см. В этой статье.)
Например, в C ++ объект данных — это область памяти в программе , которая имеет только один тип данных .
Кроме того, некоторые языки программирования имеют уникальные определения для собственных внутренних объектов данных , как мы увидим ниже.
Не все языки программирования содержат нюансы по объектам данных. Языки программирования, которые с по ориентированы на объекты данных, называются объектно-ориентированными программами (ООП) . Они противостоят и программам, ориентированным на функции и логику . Для большей ясности давайте посмотрим на ООП:
- Ява. Использует традиционный метод класса, который предоставляет управляемые кодом шаблоны, управляющие типом данных и функцией каждого типа объекта данных.

- JavaScript. Объекты данных могут быть переменными (скалярными значениями) или более сложными функциями. Примечание: функции не существуют как объекты данных в базах данных, они существуют только в самом языке.
- Python. Объекты данных содержат идентификатор, тип и значение. В отличие от объектов базы данных, «значение» в языках Python может быть сложной функцией или действием.
- С ++ . Объекты данных C ++ имеют только один тип данных.
- Visual Basic. Visual Basic — это язык Microsoft Excel. Его объекты данных очень похожи на объекты в базах данных. Объекты данных — это представления (в программном коде) физической базы данных, таблиц данных и полей.
- . НЕТТО. Как и Java, использует традиционный метод класса, который предоставляет управляемые кодом шаблоны, управляющие типом данных и функцией каждого типа объекта данных.
- Рубин. Объекты данных Ruby состоят в основном из массивов и специального отношения «идентификатор к значению», называемого «хеш».

- Скала. Подобно Java и .NET, использует традиционный метод класса, который предоставляет управляемые кодом шаблоны, управляющие типом данных и функцией каждого типа объекта данных.
- PHP. Использует зависящее от языка расширение для доступа к объектам базы данных, подобным тем, которые определены выше в этой статье.
Заключение
Объект данных, в большинстве случаев, представляет собой таблицу данных или какую-либо ее производную.Это то, что мы имеем в виду в контексте таблиц данных. Однако у языков программирования часто есть свои собственные уникальные определения.
Поскольку языки программирования и базы данных часто работают в унисон, расхождения в определениях могут сбивать с толку. Чтобы понять разницу, аналитики полагаются на контекст.
В конце концов, объекты данных — это не что иное, как набор данных. Когда вы аналитик данных, вам постоянно нужно разделять их на части. Это обеспечивает структуру и упрощает работу с данными.
А как можно так сделать? Используя объекты данных.
Проектирование базы данных — Введение
Это четвертое издание этой онлайн-книги Альваро Монж, пожалуйста, свяжитесь с ним с любыми вопросами и особенно, чтобы сообщить о любых ошибках или предлагать изменения.
Предыдущие издания были выполнены Томом Джуэттом. Теперь, когда Том ушел с преподавания, он по-прежнему активно занимается веб-дизайном и консультированием по вопросам доступности.
Редакции
Это четвертое издание dbDesign является значительным обновлением содержания книги. а также его дизайну (готовится к печати).Большая часть контента была обновлена и работа над этим продолжается. Более подробная информация об изменениях будет продолжать публиковаться ниже на протяжении всего процесса.
- Обновите все веб-страницы, чтобы использовать элементы HTML, соответствующие их содержанию. За
например, использовать списки, в которых есть информация, использование HTML5
элементы секционирования (статья, раздел и т.
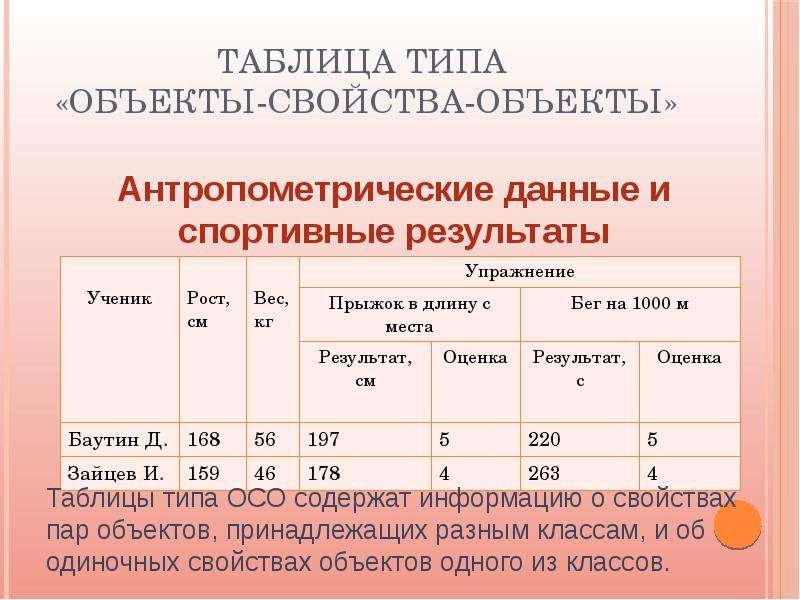 д.), используйте элемент figure в качестве контейнера
изображений и т. д. Удалите использование устаревших элементов / атрибутов HTML.
д.), используйте элемент figure в качестве контейнера
изображений и т. д. Удалите использование устаревших элементов / атрибутов HTML. - Обновляет определения стилей CSS по мере необходимости с учетом изменений в HTML.
- Использование символов UTF-8 вместо символов HTML.
- интегрирует Highlight.js, библиотека подсветки синтаксиса, встроенная в JavaScript и используется на этом веб-сайте для выделения примеров операторов SQL.
- Исправьте ошибки в представленном синтаксисе SQL и предоставьте альтернативный синтаксис SQL.
- Расширить пояснения некоторых понятий, которые группа студентов считает трудными
основанный на многолетнем опыте их преподавания.Например, студенты
часто путают использование классов ассоциации и «многие-ко-многим» с историей
шаблон дизайна. Объяснение этого было изменено, и дополнительная информация
предоставлены в попытке прояснить эти (и другие концепции).

- Организовал тематические страницы, добавив больше заголовков для структурирования содержания.
Предыдущие издания
По историческим причинам в приведенном ниже списке представлены изменения к предыдущим редакциям.
- Третье издание dbDesign — это общее обновление, отвечающее требованиям законодательства. требования к доступности «Раздела 508» США и внесение кода в соответствие последним стандартам Консорциума World Wide Web. В процессе, Я попытался сделать примеры SQL как можно более общими, хотя вы все равно придется обращаться к документации для вашей собственной системы баз данных. Графика больше не требует подключаемого модуля SVG; только большие изображения и текст просмотры каждого рисунка предоставляются всем читателям; в меню теперь организовано по тематическим областям; и версия для печати (без навигации слева) выполняется автоматически таблицей стилей.
- Второе издание во многом было мотивировано очень полезными
комментарии профессора Альваро Монжа, а также
Собственные наблюдения Тома Джуэтта в двух
семестров использования его предшественника в классе.
 Основные изменения включали четкое разделение
UML от его реализации в реляционной модели, введение
терминологии реляционной алгебры как помощь в понимании SQL, и
повышенное внимание к пониманию дизайна на естественном языке.
Основные изменения включали четкое разделение
UML от его реализации в реляционной модели, введение
терминологии реляционной алгебры как помощь в понимании SQL, и
повышенное внимание к пониманию дизайна на естественном языке. - Первоначальный сайт возник на основе предыдущей книги. проект, Практическое проектирование реляционной базы данных (PRDD), Уэйн Дик и Том Джуэтт. Переезд в Интернете включал сжатые обсуждения, интегрированный взгляд на концепции и навыки работы с базами данных, и использование единого языка моделирования в процессе проектирования. Я благодарен за положительный отклик, который получил сайт, оба от моих собственных учеников и от онлайн-читателей со всего мира.
Благодарности
- В 2002 году Том Джуэтт воплотил в жизнь книжный проект PRDD в Интернете. Инструкторы CSULB
вводного класса базы данных (CECS 323) использовали эту онлайн-книгу все эти годы
и добились отличных результатов.
 Трудолюбие, целеустремленность и профессионализм Тома
сделали эту онлайн-книгу успешной. В 2014 году он передал этот проект Альваро Монжу,
который надеется продолжить великую работу, которую они с Уэйном Диком начали много лет назад и которая
Том принес в Сеть с большим успехом.
Трудолюбие, целеустремленность и профессионализм Тома
сделали эту онлайн-книгу успешной. В 2014 году он передал этот проект Альваро Монжу,
который надеется продолжить великую работу, которую они с Уэйном Диком начали много лет назад и которая
Том принес в Сеть с большим успехом. - В каждом выпуске этого сайта огромная благодарность выражается Проф. Уэйн Дик, ведущий автор более ранней книги PRDD и всемирно известный эксперт по доступности. За эти годы он внес огромный вклад в в базах данных, попавших в этот онлайн-ресурс.
Альваро Монж
Кафедра компьютерной инженерии и компьютерных наук
Калифорнийский государственный университет, Лонг-Бич
Альваро Монге
электронная почта: [email protected]
[К началу страницы]
Проектирование баз данных с помощью UML и SQL, 4-е издание Альваро Монж под лицензией Creative Commons Международная лицензия Attribution-NonCommercial-NoDerivatives 4. 0.
На основе работы в
http://www.tomjewett.com/dbdesign/.
0.
На основе работы в
http://www.tomjewett.com/dbdesign/.
Основы работы с объектами JavaScript — Изучите веб-разработку
В этой статье мы рассмотрим фундаментальный синтаксис объекта JavaScript и вернемся к некоторым функциям JavaScript, которые мы уже видели ранее в курсе, повторяя тот факт, что многие из функций вы Я уже имел дело с объектами.
| Предварительные требования: | Базовая компьютерная грамотность, базовое понимание HTML и CSS, знакомство с основами JavaScript (см. Первые шаги и Строительные блоки). |
|---|---|
| Цель: | Чтобы понять основную теорию объектно-ориентированного программирования, как это относится к JavaScript («большинство вещей — объекты»), и как начать работа с объектами JavaScript. |
Объект — это набор связанных данных и / или функций (которые обычно состоят из нескольких переменных и функций — которые называются свойствами и методами, когда они находятся внутри объектов). Давайте рассмотрим пример, чтобы понять, как они выглядят. .
Давайте рассмотрим пример, чтобы понять, как они выглядят. .
Для начала сделайте локальную копию нашего файла oojs.html. Он содержит очень мало — элемент