
Способы записи алгоритмов. Словесные способы записи алгоритма. Блок-схемы
Вопросы занятия:
· Способы записи алгоритмов;
· Словесные способы записи алгоритма;
· Блок-схемы.
Как вы помните, чтобы задать алгоритм действий необходимо: получить задание и оценить условия задачи. Затем составить алгоритм действий и в итоге прийти к результату.
Существует несколько способов записи алгоритма, среди них выделяют:
· Словесные
· Графические
· Способы записи на алгоритмическом языке.
Давайте обратимся к
истории развития алгоритмов. Здесь весомое место принадлежит нашему
соотечественнику Андрею Андреевичу Маркову. В начале 1950-х годов в работах А.
А. Маркова получила развитие та идея, что все математические алгоритмы можно
свести к повторению простых однотипных операций, выполняемых в строгом порядке
по определённому предписанию, которое после объяснения на обычном языке или
даже демонстрации на примерах становится понятным каждому.
Марков выделил, что в общем случае алгоритмы должны содержать предписания двух видов:
Первые предписания, направлены на изменение информации (функциональные операторы)
Вторые предписания, определяют дальнейшие направление действий (логические операторы)
Эти предписания лежат в основе большинства способов записи алгоритмов.
Рассмотрим словесный способ записи алгоритмов.
Данный способ является самым простым способом записи алгоритма, так как алгоритм записывается на обычном разговорном языке в виде определённых высказываний.
Словесное описание является самым неограниченным и неофициальным. Но самым большим недостатком словесного описания является то, что все разговорные языки могут истолковаться по-разному, поэтому алгоритм может выполниться неоднозначно. Также алгоритм, записанный в словесной форме может быть очень объёмным и трудным для восприятия.
Рассмотрим пример.
Опишем словесно алгоритм построения треугольника, если известны две его стороны и угол между ними.
Итак, для того, чтобы построить треугольник по двум сторонам и углу между ними нужно:
· Провести прямую.
· На прямой, от выбранной точки А, отложить отрезок, равный первому данному отрезку.
· Построить угол, равный данному (вершиной угла будет точка А, а одной из сторон угла - прямая).
· На другой стороне угла отложить отрезок, равный второму данному отрезку.
· Соединить концы отрезков.
Такая словесная запись алгоритма называется построчной.
То есть для записи алгоритма необходимо соблюдать следующие правила:
· Каждое предписание записывается с новой строки
· Шаги алгоритма нумеруются
·
Исполнять
алгоритм начинают с первого номера предписания и продолжают по возрастанию
номеров, только если нет специальных отступлений.
Словесная запись алгоритма может содержать формулы и математические выражения.
Например:
· Обозначить первое из заданных чисел Х, второе обозначить У.
· Если 𝑋=У, то перейти к п. 8.
· Если 𝑋 > У, то перейти к п. 4, иначе перейти к п. 6.
· Заменить 𝑋 на 𝑋 − У.
· Перейти к п. 2.
· Заменить У на У − 𝑋.
· Перейти к п. 2.
· Считать 𝑋 искомым результатом.
Благодаря построчной записи алгоритма можно избежать ряда неопределённостей и восприятие алгоритма не требует специальных знаний. Но при этом построчная запись алгоритма требует от человека концентрации внимания.
Более наглядной и
доступной формой записи алгоритма является графический способ, а самый широко
применимый способ — запись с помощью блок-схем.
Блок-схема – это графический документ, глядя на который легко понять порядок работы алгоритма.
При этом предписания изображаются с помощью различных геометрических фигур, а последовательность выполнения шагов – с помощью линий, соединяющих эти фигуры.
Направления линий слева направо и сверху вниз являются стандартными и могут изображаться без стрелок.
Линии связи справа налево и сверху вниз изображаются с помощью стрелок.
Рассмотрим некоторые обозначения, используемые в блок-схемах.
Начинаем и заканчиваем выполнение алгоритма всегда с блока Начало и блока Конец, которые изображаются с помощью овала.
Из начального блока выходит одна линия связи, в конечный блок также входит одна линия связи.
Внутри блока данных,
который изображается с помощью параллелограмма содержатся исходные данные или
выведены результаты.
В блок данных входит одна линия связи и выходит одна линяя связи.
Следующий блок Процесс – это блок обработки данных. Изображается с помощью прямоугольника. Здесь записаны действия, которые необходимо выполнить при переходе на этот блок.
В блок Процесс также входит и выходит одна линяя связи.
Проверка условия изображается с помощью блока «Принятие решения», который условно обозначается ромбом, внутри его записывается условие.
В данный блок входит одна линяя связи, а выходят две линии, возле которых записываются результаты проверки условия.
Также в блок-схемах используются Комментарии, которые применяются для пояснений и это делает блок-схему понятнее.
Рассмотрим блок-схему кипячения воды.
Как видно из блок-схемы для получения результата необходимо поочерёдно выполнить три процесса:
· Налить воду в чайник
· Поставить чайник на плиту
· Включить плиту
Причём, обратите
внимание, что из каждого блока действия выходит одна линия связи.
Затем мы переходим к блоку принятия решения, из которого выходит две линии связи, предлагающие нам два варианта решения. Вода закипела либо нет. В зависимости от ответа, мы переходим к соответствующему блоку действия: выключить плиту либо ещё подождать. На этом блок-схема заканчивается, результат получен.
Таким образом, чтобы создать детальную блок-схему необходимо решить задачу в общем виде, а затем приступить к проработке блок-схемы. Причём любая блок-схема должна умещаться на стандартном листе, для большей наглядности.
Перейдём к практической части урока.
Первое задание. Нам необходимо представить в виде построчной записи алгоритм решения следующей задачи.
Система команд исполнителя Вычислитель состоит из двух команд:
· +1
· *2.
Придумать для Вычислителя
алгоритм, с помощью которого он получает из нуля число пятьдесят.
Алгоритм решения этой задачи может быть, например, таким:
0+1*2+1*2 *2*2+1*2.
Следующий пример. Необходимо представить в виде построчной записи алгоритм решения следующей задачи: «Имеются четыре дыни различной массы. Найти способ, с помощью которого пользуясь чашечными весами без гирь путём не более пяти взвешиваний расположить дыни по убыванию веса».
Итак, первое взвешивание. Положим по одной дыне на каждую чашу весов.
Дыня, которая окажется на нижней части весов будет тяжелее, отложим её в сторону.
Второе взвешивание. Положим оставшиеся дыни на каждую чашу весов. И аналогично определяем более тяжёлую дыню. Как и в первом случае, убираем дыню с нижней чаши весов в сторону.
Третье взвешивание. Сравним две самые тяжёлые дыни, послу двух взвешиваний.
Дыня, которая окажется на
нижней чаши весов, является самой тяжёлой, ставим её на первое место.
Четвёртое взвешивание. Сравниваем самые лёгкие дыни. Дыня, которая окажется на верхней части весов является самой лёгкой, ставим её на четвёртое место.
Пятое взвешивание. Сравним оставшиеся две дыни. Кладём их на чаши весов.
Дыня, которая окажется на нижней чаше весов, занимает второе место. Дыня что оказалась выше — третье.
Пришло время подвести итоги урока.
Существует несколько способов записи алгоритмов. Словесный, графический, на алгоритмическом языке
.Словесный способ – запись алгоритма с помощью привычных для человека предложений и фраз.
Графический способ – изображение алгоритма в виде блок-схем.
Блок-схемы
состоят из геометрических фигур (блоков), блоки дополнены словесными записями.
Каждый блок служит для обозначения одной команды. Блоки соединяются стрелками, указывающими
последовательность исполнения команд алгоритма.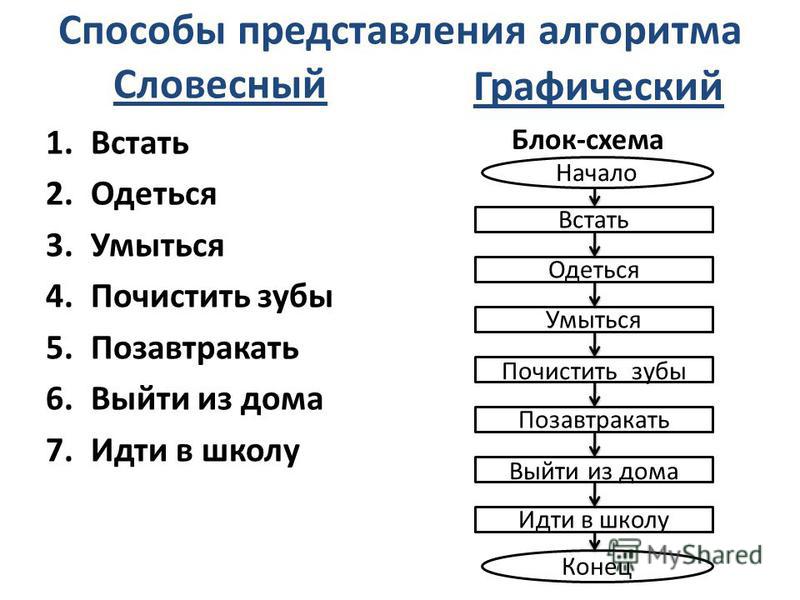
Урок по информатике «Следуя командам. Виды алгоритмов.»
Объявление новой темы. Ученики записывают тему «Типы алгоритмов»
Можно выделить три основных типа алгоритма:
1.Линейный алгоритм
2.Разветвляющийся алгоритм
3.Циклический алгоритм
Линейный алгоритм – набор команд, выполняемых последовательно друг за другом.
Пример.
Приготовление бутерброда:
Начало
Отрезать кусочек хлеба
Намазать масло
Отрезать ломтик сыра
Положить на хлеб
Конец
Разветвляющийся алгоритм – это выбор действий в зависимости от какого-нибудь условия.
В разветвляющемся алгоритме используются слова если, тоогда, иначе.
Пример.
Алгоритм выбора обуви по погоде:
Начало
Если на улице дождь, тогда нужно надеть сапоги, иначе надеть туфли.
Конец.
Циклический алгоритм – алгоритм предусматривающий многократное повторение одного и того же действия.
Пример.
Алгоритм покраски забора:
Начало
Покрасить доску
Если есть еще доска, то покрасить
Если досок нет завершить работу
Конец
Определите тип алгоритма в сказках.
Разветвляющийся, линейный, циклический.
Обоснуйте свой ответ.
Задание 1. (работа по группам, 1 группа)
Линейный алгоритм:
http://files.school-collection.edu.ru/dlrstore/48135b4e-0caf-462c-983e-629fd5ea6df6/%5BNS-INF_2-02-06-08%5D_%5BIM_104%5D.swf
Дескрипторы:
-определяет понятие алгоритм;
-составляют алгоритм «Слепи снеговика»
Задание 2. (работа по группам, 2 группа)
Разветвляющийся алгоритм: http://files.school-collection.edu.ru/dlrstore/4ff93eba-9655-45b6-8246-04b7eeebd839/%5BNS-INF_4-01-01-02%5D_%5BIM_236%5D.swf
Дескрипторы:
-определяет понятие алгоритм;
-составляют алгоритм «Погуляй с другом»
Дополнительное задание.
Циклический алгоритм:
http://files.school-collection.edu.ru/dlrstore/69d38a71-b7bc-4ac2-9639-4ce0c9beb6b7/%5BNS-INF_3-01-05%5D_%5BIM_166%5D.swf
Задание 3. Творческое задание.
Написать словесный алгоритм смотря на картинку
-определяет понятие алгоритм;
-понимают словесный способ записи алгоритма
-составляют алгоритм
Способы описания алгоритмов
Существуют следующие способы описания (представления) алгоритмов:
- словесное описание;
- описание алгоритма с помощью математических формул;
- графическое описание алгоритма в виде блок-схемы;
- описание алгоритма с помощью псевдокода;
-
комбинированный способ изображения алгоритма с использованием словесного, графического и др. способов
Словесное описание алгоритма представляет собой описание структуры алгоритма на естественном языке. Например, к приборам бытовой техники, как правило, прилагается инструкция по эксплуатации, т.е. словесное описание алгоритма, в соответствии с которым данный прибор должен использоваться.
Например, к приборам бытовой техники, как правило, прилагается инструкция по эксплуатации, т.е. словесное описание алгоритма, в соответствии с которым данный прибор должен использоваться.
Графическое описание алгоритма в виде блок-схемы – это описание структуры алгоритма с помощью геометрических фигур с линиями связи.
Блок схема алгоритма – это графическое представление метода решения задачи, в котором используются специальные символы для отображения операций.
Символы, из которых состоит блок-схема алгоритма, определяет ГОСТ 19.701-90. Этот ГОСТ соответствует международному стандарту оформления алгоритмов, поэтому блок-схемы алгоритмов, оформленные согласно ГОСТ 19.701-90, в разных странах понимаются однозначно.
Псевдокод – описание структуры алгоритма на естественном, но частично формализованном языке. В псевдокоде используются некоторые формальные конструкции и общепринятая математическая символика.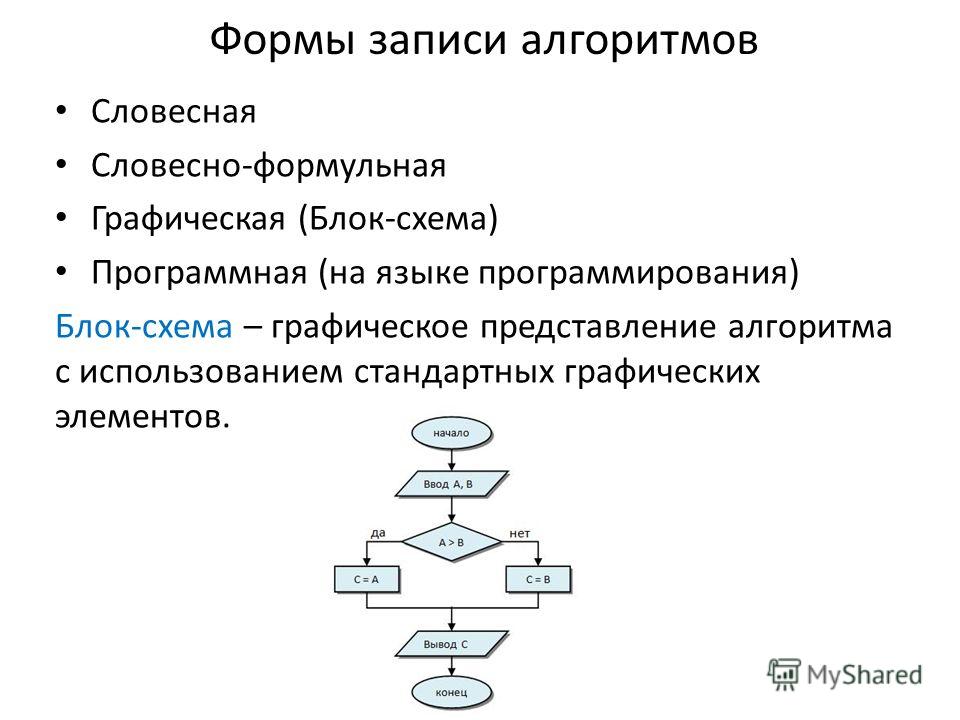 Строгих синтаксических правил для записи псевдокода не предусмотрено.
Строгих синтаксических правил для записи псевдокода не предусмотрено.
Рассмотрим простейший пример. Пусть необходимо описать алгоритм вывода на экран монитора наибольшего значения из двух чисел.
Рисунок 1 — Пример описания алгоритма в виде блок-схемы
Описание этого же алгоритма на псевдокоде:
- Начало
- Ввод чисел: Z, X
- Если Z > X то Вывод Z
- Иначе вывод Х
- Конец
Каждый из перечисленных способов изображения алгоритмов имеет и достоинства и недостатки. Например, словесный способ отличается многословностью и отсутствием наглядности, но дает возможность лучше описать отдельные операции. Графический способ более наглядный, но часто возникает необходимость описать некоторые операции в словесной форме. Поэтому при разработке сложных алгоритмов лучше использовать комбинированный способ.
Базовые алгоритмические структуры. Циклические алгоритмы
Тема урока: «Базовые алгоритмические
структуры. Циклические алгоритмы»
Циклические алгоритмы»
Цели урока:
- знакомство с циклическим алгоритмом;
- рассмотрение различий между циклом с условием и циклом с параметром;
- закрепление умений и навыков в работе в текстовом редакторе Word;
Задачи урока:
- образовательная – знакомство учащихся с базовыми алгоритмическими структурами;
- развивающие – формирование у учащихся приемов логического и алгоритмического мышления; развитие познавательного интереса к предмету; развитие умения планировать свою деятельность;
- воспитательные – воспитание необходимости связывать изучение нового материала с уже известными фактами; воспитание ответственности за выполняемую работу, аккуратности при выполнении вычислений.
Место урока в учебном плане.
Данный урок является одним из уроков по теме
«Базовые алгоритмические структуры», на котором
вводится понятие циклического алгоритма,
рассматриваются различия между циклом с
условием и циклом с параметром, закрепляется
умение работать в текстовом редакторе Word. На
предыдущих уроках было введено понятие
алгоритма, рассмотрены такие базовые
алгоритмические структуры, как линейный и
условный алгоритмы.
На
предыдущих уроках было введено понятие
алгоритма, рассмотрены такие базовые
алгоритмические структуры, как линейный и
условный алгоритмы.
Дидактические основания урока:
- метод обучения: эвристический (частично-поисковый)
- тип урока: комбинированный
- формы учебной работы учащихся: фронтальная работа, индивидуальная работа за компьютером
Средства обучения:
Учебники:
- Информатика, 10-11 класс. Начальный курс/Под ред. Н.В. Макаровой. СПб.: Питер, 2001;
Технические и программные средства:
- Персональные компьютеры
- Приложение Windows – текстовый редактор Word
- Презентация по теме урока;
- Проектор
Раздаточный материал:
- Карточки с шаблонами блок-схем алгоритмов
План урока.
1. Организационный момент – 2 мин.
2. Актуализация опорных знаний –10 мин.
3. Изучение нового материала –15 мин.
4. Применение полученных знаний –15 мин.
5. Подведение итогов урока. Домашнее задание – 3 мин.
Ход урока
В данном уроке особое внимание уделено визуальному представлению информации – в ходе урока с помощью проектора демонстрируются слайды, подготовленные в пакете презентационной графики Microsoft PowerPoint.
1. Организационный момент
Учитель приветствует учеников, отмечает в журнале отсутствующих, проверяет готовность учащихся к уроку, организует доброжелательный настрой учащихся. Учащиеся приветствуют учителя, проверяют свою готовность к уроку.
Учитель. Здравствуйте! Я рада вас видеть.
Тема нашего урока «Базовые алгоритмические
структуры. Циклические алгоритмы».
Циклические алгоритмы».
Демонстрируется слайд1 презентации – на нем записана тема урока.
2. Актуализация опорных знаний
Учитель проверяет сформированность знаний учащихся по обсуждаемым темам. С помощью беседы осуществляет подготовку учеников к восприятию новой информации.
Учащиеся внимательно слушают вопросы учителя, вспоминают материал предыдущих занятий, отвечают на вопросы.
Фронтальный опрос
Учитель. Для начала вспомним, что такое алгоритм и исполнитель алгоритма.
После ответов учащихся и приведения ими примеров исполнителей демонстрируется слайд 2 – на нем записаны определения алгоритма и исполнителя алгоритма.
Учитель. Какими свойствами обладает алгоритм?
После ответа учащихся демонстрируется слайд
3, на котором перечислены свойства
алгоритмов: однозначность, дискретность,
массовость.
Учитель. Какие способы задания алгоритмов мы знаем?
Приводятся примеры и анализируются способы задания алгоритмов.
Демонстрируется слайд 4 , на котором записаны способы задания алгоритмов: словесный, графический.
Из слайда 4 можно выйти на слайд 5 с определением словесного алгоритма и описанием построения снеговика (словесный алгоритм)
или на слайд 6 где изображена блок-схема построения снеговика (Графический алгоритм):
Учитель. Давайте вспомним, какие условные обозначения используются в схемах алгоритмов?
Демонстрируется слайд 7 с изображением условных обозначений.
Повторение определения линейного алгоритма, блок-схемы данного алгоритма.
Учитель. Что такое линейный алгоритм?
После ответа учащихся демонстрируется слайд 8 с определением и изображением блок схемы линейного алгоритма:
В качестве примера построения линейного
алгоритма рассмотри алгоритм приготовления
бутерброда.
Уитель. Давайте составим алгоритм приготовления бутерброда с маслом и сыром.
Демонстрируется слайд 9. Каждый раз после того как учащиеся называют очередную команду, на слайде демонстрируется соответствующий элемент блок-схемы:
На этом этапе происходит проверка слуховой, зрительной, моторной памяти учащихся, развитие из речи.
Повторение определения разветвляющегося алгоритма, блок-схемы данного алгоритма.
Учитель: Какие еще алгоритмические структуры нам знакомы?
Демонстрируется слайд10, на котором изображена блок-схема разветвляющегося алгоритма и его определение.
Учащиеся приводят примеры разветвляющихся алгоритмов.
Учитель: Давайте составим блок-схему разветвляющегося алгоритма действий Ивана-царевича.
Демонстрируется слайд 11 « Витязь на
распутье». Каждый раз после того как учащиеся
называют очередную команду, на слайде
демонстрируется соответствующий элемент
блок-схемы.
Каждый раз после того как учащиеся
называют очередную команду, на слайде
демонстрируется соответствующий элемент
блок-схемы.
Фронтальная работа по составлению алгоритмов
На каждую парту дается карточка, которая содержит блок-схему условного алгоритма, и незаполненный шаблон, в который нужно вписать значения, полученные в результате выполнения алгоритма.
Демонстрируется слайд с примеров выполнения заданий по карточкам.
Результаты решения по каждому из вариантов карточек проверяются с демонстрацией соответствующего слайда на экране, чтобы отследить возможные ошибки.
Данное задание способствует воспитанию у учащихся ответственности, активности при анализе работы своей и своих товарищей, развитию логического мышления.
3. Изучение нового материала
Понятие циклического алгоритма
Учитель: Давайте откроем тетради и запишем
определение новой алгоритмической структуры –
Циклического алгоритма.
Демонстрируется слайд:
После того как определение записано, на слайде появляется блок схема данного алгоритма.
Учитель: Теперь зарисуйте блок-схему данного алгоритмы в тетрадях.
Понятие цикла с условием
Учитель: Решим задачу «Маша и оладьи».
Демонстрируется слайд с текстом задачи:
Один из учащихся определяет порядок действий по приготовлению оладий. После того как названа очередная команда, на слайде демонстрируется соответствующий элемент блок-схемы:
Ребята обсуждают возможное название данной алгоритмической структуры и постепенно приходят к понятию цикла с условием.
На данном этапе происходит проверка понимания
учащимися сущности новых понятий при применении
их к ранее изученному материалу – так как
учащиеся знакомы с условными алгоритмами, то
должны вывести понятие цикла с условием.
Понятие цикла с параметром
Учитель: Изменим задачу. Пусть Маша готовит яичницу из четырёх яиц.
Сначала учитель предлагает одному из учащихся устно проговорить вариант данной задачи. Здесь следует иметь в виду, что возможна ошибка в составлении алгоритма, когда Маша продолжает действия, пока не закончатся яйца в холодильнике.
Затем демонстрируется слайд с верным решением задачи.
При исправлении ошибки, учащиеся должны определить понятие цикла с параметром как повторение действий определенное количество раз.
На данном этапе урока учащиеся побуждаются к обобщению ранее изученного материала, умению делать логический выводы.
4. Применение полученных знаний
Теперь мы перейдем к практической работе на компьютере.
Демонстрируется слайд, на котором
изображена тучка темно синего цвета, белый
полумесяц и четыре желтые снежинки-звездочки.
Анализируются объекты и действия над ними, разбирается блок-схема построения данного алгоритма.
Учитель: Ребята! На рабочем столе найдите файл, который называется Практическое задание. Вы должны:
- составить блок схему алгоритма выполнения рисунка используя предложенный конструктор.
- определите, какой тип алгоритма у вас получился.
- результат работы нужно распечатать и сдать преподавателю для проверки.
После того как работы распечатаны, демонстрируется слайд с верно составленным алгоритмом. Ученикам предлагается саммит выставит себе оценки в зависимости от правильности выполнения задания.
Подведение итогов урока. Домашнее задание
Учитель задает вопросы, подводящие учеников к
формулировке выводов о цели урока и выполнении
ими задач урока. Ученики отвечают на вопросы. Они
должны самостоятельно прийти к выводу о
соответствии целей и результатов урока.
Учитель: Итак, мы познакомились с новой алгоритмической структурой – циклическим алгоритмом, выяснили, что цикл может быть с условием и с параметром, поработали в программе Word.
Домашнее задание. Демонстрируется слайд с домашним заданием: придумать циклический алгоритм по мотивам русских народных сказок и составить его блок-схему.
Учитель: Мы с вами хорошо поработали, выполнили все задания. Особенно хотелось бы отметить …(называет фамилии). Урок окончен.
Эффективность тарифного метода: проверка простого аддитивного алгоритма анализа вербальных вскрытий | Показатели здоровья населения
Тарифы
В таблице 1 показаны выбранные тарифы, которые демонстрируют патологическую достоверность, а также то, как определенные признаки / симптомы позволяют точно предсказать определенные причины по сравнению с другими причинами. Например, при прогнозировании диабета с кожной инфекцией признак «язвы с выделением гноя» имеет частоту положительного ответа, которая на 25 межквартильных диапазонов выше средней частоты этого признака по всем причинам. Это приведет к тому, что любая смерть, сообщающая об этом признаке, будет иметь высокий рейтинг в рейтинге предсказания причины. Слово «рак», записанное в медицинской карте, имеет относительно высокий тариф как для рака пищевода, так и для рака шейки матки, что свидетельствует о его прогностической ценности, несмотря на то, что оно менее специфично, чем другие элементы. Интересно отметить, что примерно в 50% случаев смерти от гипертонического расстройства у матерей наблюдались судороги, а в 50% случаев смерти от диабета с кожной инфекцией сообщалось о выделении гноя из язвы, однако тарифы на эти две комбинации «признак-причина» существенно различаются.Это отражает то, как расчет тарифов может уловить силу и уникальность признака / симптома при прогнозировании причины. Эти два примера имеют равную силу с точки зрения степени подтверждения признака / причины симптома, но признак «язва с выделением гноя» более уникален для диабета с кожной инфекцией, чем судороги для гипертонических расстройств.
Это приведет к тому, что любая смерть, сообщающая об этом признаке, будет иметь высокий рейтинг в рейтинге предсказания причины. Слово «рак», записанное в медицинской карте, имеет относительно высокий тариф как для рака пищевода, так и для рака шейки матки, что свидетельствует о его прогностической ценности, несмотря на то, что оно менее специфично, чем другие элементы. Интересно отметить, что примерно в 50% случаев смерти от гипертонического расстройства у матерей наблюдались судороги, а в 50% случаев смерти от диабета с кожной инфекцией сообщалось о выделении гноя из язвы, однако тарифы на эти две комбинации «признак-причина» существенно различаются.Это отражает то, как расчет тарифов может уловить силу и уникальность признака / симптома при прогнозировании причины. Эти два примера имеют равную силу с точки зрения степени подтверждения признака / причины симптома, но признак «язва с выделением гноя» более уникален для диабета с кожной инфекцией, чем судороги для гипертонических расстройств.
Дополнительные файлы 1, 2 и 3 показывают тарифы (полученные из полного набора данных) для 40 наиболее популярных товаров на основе абсолютного значения тарифа для каждой причины для модулей для взрослых, детей и новорожденных, соответственно.
Подтверждение назначения причин тарифа
Индивидуальное определение смерти
В таблице 2 сравнивается общая медианная скорректированная по вероятности согласованность по 500 разделам данных поездных тестов для тарифов и PCVA для взрослых, детей и новорожденных. Среди взрослых тариф превосходит PCVA, когда не учитывается медицинский опыт, и незначительно отличается от PCVA, когда включается информация о медицинском опыте. PCVA превосходит Тариф по согласованности со скорректированной случайностью для детского модуля как с информацией о медицинском опыте, так и без нее.Тариф достигает 21,6% (без HCE) и 23,9% (с HCE) согласованности с поправкой на случайность в анализе модуля для новорожденных. Результаты для новорожденных между Tariff и PCVA нельзя напрямую сравнивать, потому что PCVA не может предсказать причины смерти для всех 11 причин новорожденных и, следовательно, объединяет пять причин преждевременных родов в одну причину преждевременных родов. На Рисунке 2 представлена подробная информация о том, насколько хорошо Тариф определяет истинную причину как вторую, третью, четвертую — шестую причину в списке. Для всех возрастных групп частичное совпадение с поправкой на случайность неуклонно увеличивается по мере того, как дополнительные причины учитываются в списке.Важно отметить, что частичное совпадение с поправкой на случайность включает поправочный коэффициент для совпадения, обусловленного случайностью. Тариф достигает 66% частичного совпадения с поправкой на случайность, если для взрослых назначены три причины, 62% для детей и 52% для новорожденных.
Результаты для новорожденных между Tariff и PCVA нельзя напрямую сравнивать, потому что PCVA не может предсказать причины смерти для всех 11 причин новорожденных и, следовательно, объединяет пять причин преждевременных родов в одну причину преждевременных родов. На Рисунке 2 представлена подробная информация о том, насколько хорошо Тариф определяет истинную причину как вторую, третью, четвертую — шестую причину в списке. Для всех возрастных групп частичное совпадение с поправкой на случайность неуклонно увеличивается по мере того, как дополнительные причины учитываются в списке.Важно отметить, что частичное совпадение с поправкой на случайность включает поправочный коэффициент для совпадения, обусловленного случайностью. Тариф достигает 66% частичного совпадения с поправкой на случайность, если для взрослых назначены три причины, 62% для детей и 52% для новорожденных.
Частичное согласованное совпадение прогнозов взрослого, ребенка и новорожденного для определения множественных причин смерти для каждой смерти . Можно сделать несколько назначений, посмотрев на самые популярные причины на основе тарифных баллов по каждой причине. Для данной смерти, например, СПИД, туберкулез и пневмония могут быть тремя наиболее вероятными причинами смерти, таким образом повышая вероятность того, что одна из этих причин верна. Расчет согласования с частичной случайной коррекцией включает поправочный член для компенсации изначально более высокой вероятности выполнения правильного назначения, когда назначено несколько причин.
Можно сделать несколько назначений, посмотрев на самые популярные причины на основе тарифных баллов по каждой причине. Для данной смерти, например, СПИД, туберкулез и пневмония могут быть тремя наиболее вероятными причинами смерти, таким образом повышая вероятность того, что одна из этих причин верна. Расчет согласования с частичной случайной коррекцией включает поправочный член для компенсации изначально более высокой вероятности выполнения правильного назначения, когда назначено несколько причин.
Дополнительный файл 4 содержит согласования для Тарифа, скорректированные случайным образом.Для взрослых, если исключить семейные воспоминания об опыте оказания медицинской помощи, Тариф дает средние скорректированные по вероятности совпадения более 50% для ряда травм, включая укус ядовитым животным, рак груди, рак шейки матки, утопление, рак пищевода, пожары, убийство, материнство. , другие травмы и дорожное движение. Добавление опыта в области здравоохранения повышает согласованность с поправкой на случайность более чем на 50% для СПИДа, астмы и инсульта. Дополнительный файл 4 также показывает, что у детей, которые не помнят семейного опыта оказания медицинской помощи, медиана согласованности с поправкой на шанс превышает 50% для падений, малярии и кори.С HCE список расширяется и включает СПИД, укус ядовитого животного, утопление, пожары, дорожное движение и насильственную смерть. У новорожденных лучший показатель по тарифу для преждевременных родов и сепсиса / асфиксии при рождении, преждевременных родов с респираторным дистресс-синдромом, врожденных пороков развития и мертворождений. На рисунках 3, 4 и 5 показаны визуальные сравнения каждой конкретной причины согласованности со скорректированной вероятностью с HCE и без HCE для взрослых, детей и новорожденных, соответственно. Эти цифры также подчеркивают важность добавления информации о HCE и демонстрируют, насколько трудно установить индивидуальную причину для определенных причин, когда информация о HCE недоступна.Например, важные причины СПИДа, малярии и туберкулеза у взрослых имеют низкую согласованность, когда информация о HCE не разглашается, хотя производительность значительно улучшается при добавлении информации о HCE.
Дополнительный файл 4 также показывает, что у детей, которые не помнят семейного опыта оказания медицинской помощи, медиана согласованности с поправкой на шанс превышает 50% для падений, малярии и кори.С HCE список расширяется и включает СПИД, укус ядовитого животного, утопление, пожары, дорожное движение и насильственную смерть. У новорожденных лучший показатель по тарифу для преждевременных родов и сепсиса / асфиксии при рождении, преждевременных родов с респираторным дистресс-синдромом, врожденных пороков развития и мертворождений. На рисунках 3, 4 и 5 показаны визуальные сравнения каждой конкретной причины согласованности со скорректированной вероятностью с HCE и без HCE для взрослых, детей и новорожденных, соответственно. Эти цифры также подчеркивают важность добавления информации о HCE и демонстрируют, насколько трудно установить индивидуальную причину для определенных причин, когда информация о HCE недоступна.Например, важные причины СПИДа, малярии и туберкулеза у взрослых имеют низкую согласованность, когда информация о HCE не разглашается, хотя производительность значительно улучшается при добавлении информации о HCE. Точно так же согласованность с поправкой на случайность улучшается примерно в четыре раза для СПИДа в дочернем модуле при добавлении HCE. На рисунке 6 показано сравнение для взрослых с HCE соответствия, достигнутого тарифами и PCVA, примененными к одним и тем же наборам тестовых данных. Эти результаты показывают, что PCVA варьируется в большей степени, чем тариф с поправкой на случайность, несмотря на то, что их медиана по 500 разделениям примерно одинакова.
Точно так же согласованность с поправкой на случайность улучшается примерно в четыре раза для СПИДа в дочернем модуле при добавлении HCE. На рисунке 6 показано сравнение для взрослых с HCE соответствия, достигнутого тарифами и PCVA, примененными к одним и тем же наборам тестовых данных. Эти результаты показывают, что PCVA варьируется в большей степени, чем тариф с поправкой на случайность, несмотря на то, что их медиана по 500 разделениям примерно одинакова.
Среднее значение совпадения, скорректированное на случайность (%), по 500 разделенным тестам, по взрослым причинам с HCE и без него.
Рисунок 4Среднее соответствие (%), скорректированное на случайность, в 500 разделениях теста, по детской причине с HCE и без него.
Рисунок 5
Среднее значение совпадения с поправкой на случайность (%) в 500 разделениях теста, по причине новорожденных с HCE и без него.
Разброс сравнения согласованности с поправкой на случайность для 500 разделов оценок модуля PCVA и тарифа для взрослых .Эти результаты включали использование информации HCE.
Оценка CSMF
Чтобы оценить способность Tariff точно определять CSMF, мы предсказали причины смерти для 500 различных наборов тестовых данных с различным составом причин. Таблица 3 показывает, что Tariff дает более точные оценки CSMF, чем PCVA для взрослых и детей, как с информацией об опыте оказания медицинской помощи, так и без нее. Поскольку PCVA не может назначать причины для полного списка из 11 причин новорожденных, невозможно напрямую сравнить точность PCVA и тарифа.
Таблица 3 Медианная точность CSMF для тарифов и PCVA с 95% UI, по возрастным группам с и без информации HCE Дополнительный файл 5 показывает наклон, точку пересечения и среднеквадратичную ошибку (RMSE) регрессии оцененного CSMF как функцию истинного CSMF для всех причин в 500 тестовых разделах. Мы выбрали четыре причины для взрослых на основе Дополнительного файла 5, чтобы проиллюстрировать диапазон случаев, когда Тариф дает хорошие или относительно плохие оценки CSMF как функции истинного CSMF.На рисунке 7 показано сравнение оценочного CSMF для утопления с истинным CSMF для утопления у взрослых по 500 тестовым наборам данных. В целом, по широкому спектру истинных CSMF, Tariff хорошо оценивает CSMF по этой причине. Это качество дополнительно подтверждается результатами регрессии. Утопление имеет точку пересечения 1,5%, что означает, что даже если в наборе данных VA нет истинных смертей от утопления, Тариф будет иметь тенденцию прогнозировать CSMF примерно на 1,5%. Однако наклон 0,817 и RMSE 0.006 также указывают на то, что оценки имеют тенденцию довольно точно отслеживать истинные CSMF, и что оцененные CSMF не будут широко варьироваться для данной истинной CSMF. Для рака груди, показанного на Рисунке 8, Tariff может точно определить доли смертности в тестовых группах с небольшим или умеренным числом истинных смертей от рака груди; однако в тестовых группах с высокими долями смертности от рака груди тариф имеет тенденцию занижать эту долю.
Мы выбрали четыре причины для взрослых на основе Дополнительного файла 5, чтобы проиллюстрировать диапазон случаев, когда Тариф дает хорошие или относительно плохие оценки CSMF как функции истинного CSMF.На рисунке 7 показано сравнение оценочного CSMF для утопления с истинным CSMF для утопления у взрослых по 500 тестовым наборам данных. В целом, по широкому спектру истинных CSMF, Tariff хорошо оценивает CSMF по этой причине. Это качество дополнительно подтверждается результатами регрессии. Утопление имеет точку пересечения 1,5%, что означает, что даже если в наборе данных VA нет истинных смертей от утопления, Тариф будет иметь тенденцию прогнозировать CSMF примерно на 1,5%. Однако наклон 0,817 и RMSE 0.006 также указывают на то, что оценки имеют тенденцию довольно точно отслеживать истинные CSMF, и что оцененные CSMF не будут широко варьироваться для данной истинной CSMF. Для рака груди, показанного на Рисунке 8, Tariff может точно определить доли смертности в тестовых группах с небольшим или умеренным числом истинных смертей от рака груди; однако в тестовых группах с высокими долями смертности от рака груди тариф имеет тенденцию занижать эту долю. Результаты регрессии для рака груди показывают, что оценки немного менее шумны, чем для случаев утопления, и что метод начнет систематически недооценивать CSMF сверх истинного CSMF, равного примерно 2.5%. На рисунке 9 показана такая же взаимосвязь для материнского, с немного более высоким порогом, когда метод начинает недооценивать CSMF. В этом случае, однако, хотя в целом сохраняется хорошая взаимосвязь между истинным и предполагаемым CSMF, при низких значениях истинного CSMF тариф имеет тенденцию к завышению доли причины, в то время как при очень высоких CSMF он имеет небольшую тенденцию к занижению. На другом конце спектра Tariff плохо справляется с оценкой доли населения в смертях от рака желудка, показанной на Рисунке 10, и имеет тенденцию недооценивать долю истинной причины, превышающую 2%.RMSE позволяют измерить уровень шума или точность прогнозов каждой причины. В прогнозах для взрослых, включая использование информации о HCE, RMSE варьировалось от 0,005 для материнских причин до 0,019 для других неинфекционных заболеваний.
Результаты регрессии для рака груди показывают, что оценки немного менее шумны, чем для случаев утопления, и что метод начнет систематически недооценивать CSMF сверх истинного CSMF, равного примерно 2.5%. На рисунке 9 показана такая же взаимосвязь для материнского, с немного более высоким порогом, когда метод начинает недооценивать CSMF. В этом случае, однако, хотя в целом сохраняется хорошая взаимосвязь между истинным и предполагаемым CSMF, при низких значениях истинного CSMF тариф имеет тенденцию к завышению доли причины, в то время как при очень высоких CSMF он имеет небольшую тенденцию к занижению. На другом конце спектра Tariff плохо справляется с оценкой доли населения в смертях от рака желудка, показанной на Рисунке 10, и имеет тенденцию недооценивать долю истинной причины, превышающую 2%.RMSE позволяют измерить уровень шума или точность прогнозов каждой причины. В прогнозах для взрослых, включая использование информации о HCE, RMSE варьировалось от 0,005 для материнских причин до 0,019 для других неинфекционных заболеваний.
Истинная и расчетная доли смертности при утоплении, модуль для взрослых с информацией HCE .
Рисунок 8Доли истинной и расчетной смертности от рака груди, модуль для взрослых с информацией HCE .
Рисунок 9Истинная и расчетная доли смертности от материнских причин, модуль для взрослых с информацией HCE .
Рисунок 10Доли истинной и расчетной смертности от рака желудка, модуль для взрослых с информацией HCE .
Мы выполнили аналогичный анализ результатов для детей и новорожденных (результаты полной регрессии также показаны в дополнительном файле 5). На Рисунке 11 показано, как Тарифы имеют тенденцию к завышению прогнозов CSMF по кори в группах населения с меньшей долей кори.Однако по мере того как истинная доля кори увеличивается, Тариф не переоценивает систематически или недооценивает доли смертности в той степени, в какой это наблюдается по другим причинам. Кроме того, оценки CSMF по кори у детей намного шумнее, чем другие примеры для взрослых. Об этом качестве также свидетельствует более высокое значение RMSE 0,019. Для детского сепсиса, напротив, тариф имеет тенденцию недооценивать CSMF, поскольку доля истинной причины увеличивается. Истинные и предполагаемые CSMF при сепсисе показаны на рисунке 12. RMSE для детей выше, чем для взрослых, в диапазоне от 0.013 для дорожно-транспортных происшествий до 0,033 для малярии.
Кроме того, оценки CSMF по кори у детей намного шумнее, чем другие примеры для взрослых. Об этом качестве также свидетельствует более высокое значение RMSE 0,019. Для детского сепсиса, напротив, тариф имеет тенденцию недооценивать CSMF, поскольку доля истинной причины увеличивается. Истинные и предполагаемые CSMF при сепсисе показаны на рисунке 12. RMSE для детей выше, чем для взрослых, в диапазоне от 0.013 для дорожно-транспортных происшествий до 0,033 для малярии.
Истинная и расчетная доли смертности от кори, детский модуль с информацией HCE .
Рисунок 12Доля истинной смертности в сравнении с расчетной долей смертности при сепсисе, детский модуль с информацией HCE .
Оценка CSMF новорожденных имеет тенденцию отличаться от фракции истинной причины чаще, чем для случаев смерти детей или взрослых. Врожденная аномалия, показанная на рисунке 13, иллюстрирует причину, по которой Tariff может приблизительно определить правильный CSMF независимо от истинного размера CSMF. Однако другие неонатальные причины, такие как преждевременные роды с респираторным дистресс-синдромом, подлежат гораздо более шумным оценкам, как показано на рисунке 14. Эти результаты далее отражаются в соответствующих коэффициентах и перехватах, представленных в дополнительном файле 5, которые позволяют оценить взаимосвязь. между истинным и предполагаемым CSMF. Что касается взрослых и детей, RMSE из этих регрессий показывает, какие причины можно оценить с большей точностью, даже если оценка систематически является высокой или низкой.В результатах новорожденных, включая использование информации о HCE, RMSE варьировался от минимума 0,023 для мертворожденных до 0,051 для преждевременных родов и асфиксии при родах, а также для преждевременных родов, сепсиса и асфиксии при рождении.
Однако другие неонатальные причины, такие как преждевременные роды с респираторным дистресс-синдромом, подлежат гораздо более шумным оценкам, как показано на рисунке 14. Эти результаты далее отражаются в соответствующих коэффициентах и перехватах, представленных в дополнительном файле 5, которые позволяют оценить взаимосвязь. между истинным и предполагаемым CSMF. Что касается взрослых и детей, RMSE из этих регрессий показывает, какие причины можно оценить с большей точностью, даже если оценка систематически является высокой или низкой.В результатах новорожденных, включая использование информации о HCE, RMSE варьировался от минимума 0,023 для мертворожденных до 0,051 для преждевременных родов и асфиксии при родах, а также для преждевременных родов, сепсиса и асфиксии при рождении.
Доли истинной и расчетной смертности от врожденных пороков развития, модуль для новорожденных с информацией HCE .
Рисунок 14
Доля истинной и расчетной смертности от преждевременных родов с респираторным дистресс-синдромом, модуль для новорожденных с информацией HCE .
GRE Scoring Grid: Что, если Сценарии
За последние годы я видел много споров относительно алгоритма оценки GRE и методологии оценки GRE. Заблуждений предостаточно!
Студенты не могут понять, как ETS оценивает тест GRE, и поэтому будущим участникам теста GRE очень сложно разработать стратегию прохождения теста.
Как это возможно, что один ученик может получить 155 за вербальную часть, просто правильно ответив на 3–4 вопроса по второй вербальной части? Чтобы ответить на этот вопрос, я недавно углубился в то, как работает алгоритм оценки GRE.
Все мы знаем, что GRE — это адаптивный тест, и уровень сложности тестов зависит от ваших результатов. Если вы преуспеете в первом разделе, вы получите более сложный второй раздел, и наоборот. Точно так же, чем сложнее раздел, тем больший вес он имеет в вашей общей оценке.
Вы можете узнать больше о весах разделов GRE и механизме адаптируемости в этом посте.
Используя отчеты о фактических результатах тестов 200+ учащихся GRE, я попытался оценить, как вы можете заработать желаемый результат. Таблицы в этом посте основаны на 237 фактических отчетах о результатах GRE, и я использовал эти данные для приблизительной оценки различных сценариев оценки GRE на вашем фактическом экзамене GRE с некоторым диапазоном ошибок +/- 3 .
Таблицы в этом посте основаны на 237 фактических отчетах о результатах GRE, и я использовал эти данные для приблизительной оценки различных сценариев оценки GRE на вашем фактическом экзамене GRE с некоторым диапазоном ошибок +/- 3 .
Я поделился некоторыми образцами отчетов об оценках, которые я использовал для своего анализа здесь.
В этой таблице вы увидите, что общее количество правильных вопросов никоим образом не дает вам представления о вашей реальной оценке. Например, правильно ответив на 20 вопросов из 40 в двух вербальных разделах, вы можете получить оценку от 147 до 155.Все зависит от раздела, в котором вы правильно ответили на большинство вопросов. В результате вы должны правильно ответить на большинство вопросов по разделу 1. Например, если вы наберете 20/20 по разделу 1 и 0/20 по разделу 2, вы получите вербальную оценку 155. Однако, если вы получите 0/20 в разделе 1 и 20/20 в разделе 2, вы получите скудные 147. Следовательно, раздел 1 жизненно важен.
| # Исправить в Разделе 2 (Q) | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |||
| # Исправить в Раздел 1 (Q) | |||||||||||||
| 0 | 130 | 130 | 131 | 131 | 132 | 132 | 133 | 133 | 134 | 134 | 135 | ||
| 1 | 130 | 130 | 131 | 131 | 133 | 133 | 133 | 133 | 134 | 134 | 135 | ||
| 2 | 130 | 130 | 131 | 131 | 133 | 133 | 134 | 134 | 135 | 135 | 135 | ||
| 3 | 131 | 131 | 132 | 132 | 133 | 134 | 134 | 134 | 135 | 136 | 137 | ||
| 4 | 131 | 131 | 132 | 132 | 133 | 134 | 135 | 135 | 136 | 136 | 137 | ||
| 5 | 131 | 131 | 132 | 133 | 134 | 134 | 135 | 135 | 136 | 137 | 138 | ||
| 6 | 132 | 132 | 133 | 134 | 135 | 135 | 136 | 136 | 137 | 138 | 139 | ||
| 7 | 133 | 133 | 134 | 135 | 136 | 136 | 137 | 137 | 138 | 139 | 140 | ||
| 8 | 134 | 134 | 135 | 136 | 136 | 137 | 138 | 138 | 139 | 140 | 141 | ||
| 9 | 135 | 135 | 136 | 137 | 137 | 138 | 139 | 139 | 140 | 141 | 142 | ||
| 10 | 138 | 139 | 140 | 141 | 141 | 142 | 143 | 144 | 145 | 145 | 146 | ||
| 11 | 139 | 140 | 141 | 142 | 142 | 143 | 144 | 145 | 146 | 146 | 147 | 147 | |
| 12 | 140 | 141 | 142 | 143 | 143 | 144 | 145 | 146 | 147 | 148 | 149 | ||
| 13 | 141 | 142 | 143 | 144 | 144 | 145 | 146 | 147 | 148 | 149 | 150 | ||
| 14 | 142 | 143 | 144 | 145 | 146 | 147 | 148 | 149 | 150 | 151 | 152 | ||
| 15 | 146 | 147 | 148 | 149 | 150 | 150 | 151 | 152 | 152 | 153 | 154 | 154 | |
| 16 | 147 | 148 | 149 | 150 | 151 | 151 | 152 | 153 | 153 | 154 | 155 | ||
| 17 | 148 | 149 | 150 | 151 | 152 | 152 | 153 | 154 | 154 | 155 | 156 | 156 90 | |
| 18 | 149 | 150 | 151 | 152 | 153 | 153 | 154 | 155 | 155 | 156 | 157 | 157 | |
| 19 | 150 | 151 | 152 | 153 | 154 | 154 | 155 | 156 | 156 | 157 | 158 | 158 | |
| 20 | 151 | 152 | 153 | 154 | 155 | 155 | 156 | 157 | 157 | 158 | 159 | 159 | |
Важные замечания для таблицы количественной оценки: Если вы хотите получить действительно высокий балл, убедитесь, что вы правильно ответили как минимум на 15 вопросов в разделе 1 количественного анализа. Поскольку это уровень, на котором алгоритм будет адаптироваться. От 10 до 14 вопросов по разделу 1, уровень следующего раздела останется прежним. Тем не менее, если в разделе 1 ниже 10 вопросов, тест будет адаптирован к более низкому уровню.
Поскольку это уровень, на котором алгоритм будет адаптироваться. От 10 до 14 вопросов по разделу 1, уровень следующего раздела останется прежним. Тем не менее, если в разделе 1 ниже 10 вопросов, тест будет адаптирован к более низкому уровню.
| # Исправить в разделе 2 (Q) | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | ||||
| # Исправить в Раздел 1 (Q) | |||||||||||||
| 0 | 136 | 137 | 138 | 139 | 139 | 140 | 141 | 141 | 142 | 143 | |||
| 1 | 136 | 137 | 139 | 139 | 139 | 140 | 141 | 141 | 142 | 143 | |||
| 2 | 137 | 138 | 139 | 140 | 140 | 141 | 142 | 142 | 143 | 144 | |||
| 3 | 138 | 138 | 140 | 140 | 140 | 141 | 142 | 142 | 143 | 145 | |||
| 4 | 138 | 139 | 140 | 140 | 141 | 142 | 142 | 143 | 144 | 146 | |||
| 5 | 139 | 140 | 141 | 141 | 141 | 142 | 143 | 144 | 145 | 146 | |||
| 6 | 139 | 140 | 141 | 142 | 142 | 143 | 144 | 144 | 146 | 147 | |||
| 7 | 140 | 141 | 142 | 143 | 143 | 144 | 145 | 145 | 146 | 147 | |||
| 8 | 141 | 142 | 143 | 144 | 144 | 145 | 146 | 146 | 147 | 148 | |||
| 9 | 142 | 143 | 144 | 145 | 145 | 146 | 147 | 147 | 148 | 149 | |||
| 10 | 147 | 148 | 149 | 150 | 151 | 151 | 152 | 153 | 154 | 155 | |||
| 11 | 148 | 149 | 150 | 151 | 152 | 152 | 153 | 154 | 155 | 156 | |||
| 12 | 150 | 151 | 152 | 152 | 153 | 153 | 154 | 155 | 156 | 157 | |||
| 13 | 151 | 152 | 153 | 153 | 154 | 154 | 155 | 156 | 157 | 158 | |||
| 14 | 153 | 154 | 154 | 155 | 155 | 156 | 156 | 157 | 158 | 159 | |||
| 15 | 154 | 155 | 156 | 157 | 158 | 159 | 160 | 161 | 162 | 163 | |||
| 16 | 155 | 156 | 157 | 158 | 159 | 160 | 161 | 162 | 163 | 164 | |||
| 17 | 156 | 157 | 158 | 159 | 160 | 161 | 163 | 164 | 165 | 166 | |||
| 18 | 157 | 158 | 159 | 160 | 161 | 163 | 164 | 166 | 167 | 168 | |||
| 19 | 158 | 159 | 160 | 161 | 162 | 164 | 165 | 167 | 168 | 169 | |||
| 20 | 159 | 160 | 161 | 162 | 163 | 164 | 166 | 169 | 170 | 170 | |||
Обратите внимание, что в количественной таблице, насколько сильно ваша оценка будет варьироваться в пределах 14–15 и 9–10 правильных вопросов в разделе 1. Это границы, в которых адаптируется количественный раздел. Вы можете значительно улучшить или уменьшить свои оценки, выставляя оценки по каждому разделу.
Это границы, в которых адаптируется количественный раздел. Вы можете значительно улучшить или уменьшить свои оценки, выставляя оценки по каждому разделу.
| # Исправить в разделе 2 (V) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | ||
| # Исправить в Раздел 1 (V) | ||||||||||||
| 0 | 130 | 130 | 130 | 131 | 132 | 133 | 134 | 135 | 136 | 137 | 138 | |
| 1 | 130 | 131 | 132 | 133 | 134 | 135 | 136 | 137 | 138 | 139 | 140 | |
| 2 | 131 | 132 | 133 | 134 | 135 | 136 | 137 | 138 | 139 | 140 | 141 | |
| 3 | 132 | 133 | 134 | 135 | 136 | 137 | 138 | 139 | 140 | 141 | 142 | |
| 4 | 133 | 134 | 135 | 136 | 137 | 138 | 139 | 140 | 141 | 142 | 143 | |
| 5 | 134 | 135 | 136 | 137 | 138 | 139 | 140 | 141 | 142 | 143 | 144 | |
| 6 | 134 | 135 | 136 | 137 | 138 | 139 | 140 | 141 | 142 | 143 | 144 | |
| 7 | 135 | 136 | 137 | 138 | 139 | 140 | 141 | 142 | 143 | 144 | 144 | |
| 8 | 140 | 141 | 142 | 143 | 144 | 145 | 146 | 147 | 148 | 149 | 150 | 150 |
| 9 | 141 | 142 | 143 | 144 | 145 | 146 | 147 | 148 | 149 | 150 | 151 | 151 |
| 10 | 142 | 143 | 144 | 145 | 146 | 147 | 148 | 149 | 150 | 151 | 152 | |
| 11 | 143 | 144 | 145 | 146 | 147 | 148 | 149 | 151 | 152 | 153 | 154 | |
| 12 | 144 | 145 | 146 | 147 | 148 | 149 | 150 | 151 | 152 | 153 | 154 | 154 |
| 13 | 150 | 151 | 151 | 152 | 152 | 153 | 154 | 154 | 155 | 156 | 157 | 157 |
| 14 | 151 | 152 | 152 | 153 | 153 | 154 | 155 | 155 | 156 | 157 | 158 | 158 90 |
| 15 | 151 | 152 | 153 | 154 | 154 | 155 | 156 | 156 | 157 | 158 | 159 | |
| 16 | 153 | 154 | 154 | 155 | 155 | 156 | 157 | 157 | 158 | 159 | 160 | |
| 17 | 154 | 154 | 155 | 155 | 156 | 156 | 157 | 158 | 159 | 160 | 161 | 161 |
| 18 | 154 | 155 | 155 | 156 | 157 | 157 | 158 | 158 | 159 | 160 | 161 | 161 |
| 19 | 155 | 156 | 156 | 157 | 157 | 158 | 159 | 160 | 161 | 162 | 163 | |
| 20 | 155 | 156 | 157 | 157 | 158 | 159 | 159 | 160 | 161 | 162 | 163 | |
Важные замечания для устной оценки Frid: Если вы хотите получить действительно высокий балл, убедитесь, что вы правильно ответили как минимум на 13 вопросов в разделе 1 устной речи. Поскольку это уровень, на котором алгоритм будет адаптироваться. От 8 до 12 вопросов по разделу 1 уровень следующего раздела останется прежним. Тем не менее, если в разделе 1 ниже 8 вопросов, тест будет адаптирован к более низкому уровню.
Поскольку это уровень, на котором алгоритм будет адаптироваться. От 8 до 12 вопросов по разделу 1 уровень следующего раздела останется прежним. Тем не менее, если в разделе 1 ниже 8 вопросов, тест будет адаптирован к более низкому уровню.
| # Исправить в разделе 2 (V) | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | ||||
| # Исправить в Раздел 1 (V) | |||||||||||||
| 0 | 138 | 139 | 140 | 141 | 142 | 143 | 144 | 145 | 146 | 147 | |||
| 1 | 141 | 142 | 143 | 144 | 145 | 146 | 146 | 147 | 148 | 148 | |||
| 2 | 142 | 143 | 144 | 145 | 146 | 147 | 148 | 149 | 149 | 149 | |||
| 3 | 143 | 144 | 145 | 146 | 147 | 148 | 149 | 150 | 150 | 150 | |||
| 4 | 144 | 145 | 146 | 147 | 148 | 149 | 150 | 151 | 151 | 151 | |||
| 5 | 145 | 146 | 147 | 148 | 149 | 150 | 151 | 152 | 152 | 152 | |||
| 6 | 145 | 146 | 147 | 148 | 149 | 150 | 151 | 152 | 153 | 153 | |||
| 7 | 145 | 146 | 147 | 148 | 149 | 150 | 151 | 152 | 153 | 153 | |||
| 8 | 151 | 152 | 153 | 154 | 155 | 156 | 157 | 158 | 159 | 159 | |||
| 9 | 152 | 153 | 154 | 155 | 156 | 157 | 158 | 159 | 160 | 161 | |||
| 10 | 153 | 154 | 155 | 156 | 157 | 158 | 159 | 160 | 161 | 162 | |||
| 11 | 155 | 156 | 156 | 157 | 157 | 158 | 159 | 160 | 161 | 162 | |||
| 12 | 155 | 156 | 156 | 157 | 158 | 159 | 160 | 161 | 162 | 162 | |||
| 13 | 157 | 158 | 159 | 160 | 160 | 161 | 162 | 163 | 164 | 164 | |||
| 14 | 158 | 159 | 160 | 161 | 162 | 163 | 164 | 164 | 165 | 165 | |||
| 15 | 159 | 160 | 161 | 162 | 163 | 164 | 165 | 166 | 167 | 167 | |||
| 16 | 160 | 161 | 162 | 163 | 164 | 165 | 166 | 167 | 168 | 168 | |||
| 17 | 162 | 162 | 163 | 163 | 164 | 165 | 166 | 167 | 168 | 169148 | |||
| 18 | 162 | 162 | 163 | 163 | 164 | 165 | 166 | 167 | 168 | 169148 | |||
| 19 | 164 | 165 | 166 | 167 | 168 | 169 | 169 | 170 | 170 | 170 | |||
| 20 | 164 | 165 | 166 | 167 | 168 | 169 | 169 | 170 | 170 | 170 | |||
В устной таблице отметьте, насколько сильно будет варьироваться ваш балл по 12–13 и 7–8 правильным вопросам в разделе 1. Это границы, в которых тест адаптируется. Вы можете значительно улучшить или уменьшить свои оценки, выставляя оценки по каждому разделу.
Это границы, в которых тест адаптируется. Вы можете значительно улучшить или уменьшить свои оценки, выставляя оценки по каждому разделу.
Надеюсь, теперь, зная, как работает матрица оценок GRE, вы сможете оценить, сколько вам нужно потратить на каждую секцию, чтобы достичь цели. Конечно, в таблице будет небольшая ошибка, поскольку она рассчитана на основе выборочных данных более 200 студентов GRE. Тем не менее, он довольно точен и развеет путаницу, связанную с механизмом оценки GRE.
Исследование событий с использованием алгоритма прогнозирования
18 Генри
Журнал новых технологий в бухгалтерском учете, 2006 г.
Амир, Э. и Б. Лев. 1996. Значимость нефинансовой информации: индустрия беспроводной связи. Журнал экономики бухгалтерского учета 22: 3–30.
Болл Р. и П. Браун. 1968. Эмпирическая оценка бухгалтерских чисел доходов. Журнал
Бухгалтерские исследования 6 (2): 159–178.
——— и С.Котари. 1991. Гарантия безопасности вокруг объявлений о прибылях и убытках. Бухгалтерский учет Re-
Бухгалтерский учет Re-
вид 66 (4): 718–738.
Бартов, Э., С. Радхакришна, И. Крински. 2000. Изощренность инвестора и модели доходности акций
после объявления прибыли. Обзор бухгалтерского учета 75 (1): 43–63.
Бернар В. Л. и Дж. К. Томас. 1989. Дрейф объявления после объявления прибыли: отложенная реакция цены
или премия за риск? Журнал бухгалтерских исследований 27 (Приложение): 1–36.
Ботосан, К. А. 1997. Уровень раскрытия информации и стоимость собственного капитала. Обзор бухгалтерского учета 72 (3):
323–349.
Брейман, Л., Дж. Фридман, Р. А. Олшен и К. Дж. Стоун. 1984. Деревья классификации и регрессии.
Бока-Ратон, Флорида: Чепмен и Холл / CRC.
———. 2001. Статистическое моделирование: две культуры. Статистическая наука 16 (3): 199–215.
Burgstahler, D., and I. Dichev. 1997. Управление прибылью, чтобы избежать снижения прибыли и убытков.
Бухгалтерский и экономический журнал 24: 99–126.
Чан, Л. К., Н. Джегадиш. И Дж. Лаконишок. 1996. Импульсные стратегии. Финансовый журнал
51 (5): 1681–1713.
Клатуорти М. и М. Дж. Джонс. 2003. Финансовая отчетность о хороших и плохих новостях: Доказательства
из бухгалтерских повествований. Бухгалтерский учет и бизнес-исследования 33 (3): 171–185.
ДеБондт, У. Ф. М. и Р. Талер. 1985. Рынок акций остро реагирует? Финансовый журнал
40 (3): 793–805.
Фама, Э., и К. Френч. 1997. Отраслевые затраты на собственный капитал. Журнал финансовой экономики 43: 153–
193.
Фостер Г., К. Олсен и Т. Шевлин. 1984. Выпуски доходов, аномалии и поведение возвращений ценных бумаг
. Обзор бухгалтерского учета 59 (4): 574–603.
Фрэнсис, Дж., К. Шиппер и Л. Винсент. 2002. Расширенные раскрытия и повышенная полезность объявлений о прибылях и убытках
. Обзор бухгалтерского учета 77 (3): 515–546.
Фрейзер, К., Р. Инграм и М. Теннисон. 1984. Методология анализа повествовательного учета —
раскрытия информации. Журнал бухгалтерских исследований 22 (1): 318–331.
Журнал бухгалтерских исследований 22 (1): 318–331.
Фридман Д. А. 1983. Заметка о проверке уравнений регрессии. Американский статистик 37 (2):
152–155.
Hand, D., H. Mannila, and P. Smyth. 2001. Принципы интеллектуального анализа данных. Кембридж, Массачусетс: MIT Press.
Харт Р. П. 2000. Diction 5.0, Программа анализа текста, Руководство пользователя. Таузенд-Оукс, Калифорния: Сколари,
Sage Publications.
Хасти Т., Р. Тибширани и Дж. Фридман. 2001. Элементы статистического обучения: интеллектуальный анализ данных,
Вывод и прогнозирование. Нью-Йорк, штат Нью-Йорк: Springer-Verlag.
Хайн С. 1995. Информационное содержание потерь. Журнал бухгалтерского учета и экономики 20: 125–
153.
Генри, Э. 2005. Влияет ли на инвесторов способ написания пресс-релизов о доходах? Рабочий документ
, Университет Рутгерса.
Хоскин Р. Э., Дж. С. Хьюз и У.Э. Рикс. 1986. Свидетельства о возрастающем информационном содержании
дополнительных раскрытий компанией информации, сделанных одновременно с прибылью. Журнал бухгалтерских исследований
Журнал бухгалтерских исследований
24 (Приложение): 1–32.
Hotchkiss, E. S., and D. Strickland. 2003. Имеет ли значение состав акционеров? Свидетельства реакции рынка
на сообщения о корпоративных доходах. The Journal of Finance 58 (4): 1469–
1498.
Хуссейни, К., Т. Шлейхер и М. Уокер. 2003 г.Проведение крупномасштабных исследований по раскрытию информации при отсутствии рейтингов
AIMR-FAF: случай, когда цены опережают прибыль. Бухгалтерский учет и
Business Research 33 (4): 275–294.
Джегадиш Н. и С. Титман. 1993. Возврат к покупке победителей и продаже проигравших: последствия для эффективности фондового рынка
.
Финансовый журнал 48 (1): 65–91.
Проверка экспертных алгоритмов иерархической вербальной аутопсии в большом наборе данных с известными причинами смерти — Университет Джона Хопкинса
TY — JOUR
T1 — Проверка иерархических экспертных алгоритмов вербальной аутопсии в большом наборе данных с известными причинами смерти
AU — Калтер, Генри
AU — Перин, Джейми
AU — Блэк, Роберт Э.
N1 — Информация о финансировании: Мы хотели бы поблагодарить Элизабет Рэган за ее помощь в очистке базы данных PHMRC. Финансирование было предоставлено Фондом Билла и Мелинды Гейтс в виде гранта Фонду США для ЮНИСЕФ для Справочной группы по эпидемиологии здоровья детей. Спонсор не принимал участия в разработке исследования, сборе и анализе данных, интерпретации данных, решении опубликовать или подготовке рукописи.
PY — 2016
Y1 — 2016
N2 — Общие сведения Оценка врача исторически была наиболее распространенным методом анализа данных вербальной аутопсии (VA).Недавно Всемирная организация здравоохранения одобрила два автоматизированных метода, Tariff 2.0 и InterVA-4, которые обещают большую объективность и меньшую стоимость. Недостатком метода тарифов является то, что он требует набора обучающих данных из предыдущего валидационного исследования, в то время как InterVA полагается на клинически определенные условные вероятности. Мы взяли на себя обязательство проверить иерархический экспертный алгоритм анализа данных VA, автоматизированный, интуитивно понятный, детерминированный метод, не требующий набора обучающих данных. Методы с использованием исходных данных больниц, проведенных Консорциумом по исследованию показателей здоровья населения, мы сравнили основные причины 1629 неонатальных и 1456 детских смертей в возрасте 1-59 месяцев, полученные с помощью алгоритмов экспертов VA, упорядоченных по иерархии, с исходными стандартными причинами.Экспертные алгоритмы оставались неизменными, в то время как пять предшествующих и одна новая «компромиссная» неонатальная иерархия и три бывших дочерних иерархии были протестированы. Для каждого сравнения эталонные стандартные данные подвергались повторной выборке 1000 раз в диапазоне фракций причинно-специфической смертности (CSMF) для одного из трех приближенных сценариев сообществ в глобальном сценарии причин смерти ВОЗ 2013 г. плюс один сценарий пропорций причин случайной смертности. Мы использовали точность CSMF для оценки общей валидности на уровне популяции и абсолютную разницу между VA и эталонными CSMF для изучения конкретных причин.Согласование с поправкой на случайность (CCC) и каппа Коэна использовались для оценки назначения причин на индивидуальном уровне.
Методы с использованием исходных данных больниц, проведенных Консорциумом по исследованию показателей здоровья населения, мы сравнили основные причины 1629 неонатальных и 1456 детских смертей в возрасте 1-59 месяцев, полученные с помощью алгоритмов экспертов VA, упорядоченных по иерархии, с исходными стандартными причинами.Экспертные алгоритмы оставались неизменными, в то время как пять предшествующих и одна новая «компромиссная» неонатальная иерархия и три бывших дочерних иерархии были протестированы. Для каждого сравнения эталонные стандартные данные подвергались повторной выборке 1000 раз в диапазоне фракций причинно-специфической смертности (CSMF) для одного из трех приближенных сценариев сообществ в глобальном сценарии причин смерти ВОЗ 2013 г. плюс один сценарий пропорций причин случайной смертности. Мы использовали точность CSMF для оценки общей валидности на уровне популяции и абсолютную разницу между VA и эталонными CSMF для изучения конкретных причин.Согласование с поправкой на случайность (CCC) и каппа Коэна использовались для оценки назначения причин на индивидуальном уровне. Результаты. Общая точность CSMF для иерархии наиболее эффективных экспертных алгоритмов составила 0,80 (диапазон 0,57–0,96) для неонатальных смертей и 0,76 (0,50–0,97) для детских смертей. Эффективность по конкретным причинам смерти варьировалась, с довольно стабильной оценкой CSMF в диапазоне контрольных значений для нескольких причин. Эффективность индивидуальной диагностики также была менее благоприятной, чем для общей CSMF (неонатальный: лучший CCC = 0.23, диапазон 0,16-0,33; наилучшая каппа = 0,29, 0,23-0,35; ребенок: лучший CCC = 0,40, 0,19-0,45; наилучшая каппа = 0,29, 0,07-0,35). Выводы Экспертные алгоритмы в иерархии предлагают доступный автоматизированный метод определения причин смерти VA. Общая точность на уровне популяции аналогична точности более сложных методов машинного обучения, но без необходимости в наборе обучающих данных из предыдущего валидационного исследования.
Результаты. Общая точность CSMF для иерархии наиболее эффективных экспертных алгоритмов составила 0,80 (диапазон 0,57–0,96) для неонатальных смертей и 0,76 (0,50–0,97) для детских смертей. Эффективность по конкретным причинам смерти варьировалась, с довольно стабильной оценкой CSMF в диапазоне контрольных значений для нескольких причин. Эффективность индивидуальной диагностики также была менее благоприятной, чем для общей CSMF (неонатальный: лучший CCC = 0.23, диапазон 0,16-0,33; наилучшая каппа = 0,29, 0,23-0,35; ребенок: лучший CCC = 0,40, 0,19-0,45; наилучшая каппа = 0,29, 0,07-0,35). Выводы Экспертные алгоритмы в иерархии предлагают доступный автоматизированный метод определения причин смерти VA. Общая точность на уровне популяции аналогична точности более сложных методов машинного обучения, но без необходимости в наборе обучающих данных из предыдущего валидационного исследования.
AB — Предпосылки Оценка врача исторически была наиболее распространенным методом анализа данных вербальной аутопсии (VA). Недавно Всемирная организация здравоохранения одобрила два автоматизированных метода, Tariff 2.0 и InterVA-4, которые обещают большую объективность и меньшую стоимость. Недостатком метода тарифов является то, что он требует набора обучающих данных из предыдущего валидационного исследования, в то время как InterVA полагается на клинически определенные условные вероятности. Мы взяли на себя обязательство проверить иерархический экспертный алгоритм анализа данных VA, автоматизированный, интуитивно понятный, детерминированный метод, не требующий набора обучающих данных. Методы с использованием исходных данных больниц, проведенных Консорциумом по исследованию показателей здоровья населения, мы сравнили основные причины 1629 неонатальных и 1456 детских смертей в возрасте 1-59 месяцев, полученные с помощью алгоритмов экспертов VA, упорядоченных по иерархии, с исходными стандартными причинами.Экспертные алгоритмы оставались неизменными, в то время как пять предшествующих и одна новая «компромиссная» неонатальная иерархия и три бывших дочерних иерархии были протестированы.
Недавно Всемирная организация здравоохранения одобрила два автоматизированных метода, Tariff 2.0 и InterVA-4, которые обещают большую объективность и меньшую стоимость. Недостатком метода тарифов является то, что он требует набора обучающих данных из предыдущего валидационного исследования, в то время как InterVA полагается на клинически определенные условные вероятности. Мы взяли на себя обязательство проверить иерархический экспертный алгоритм анализа данных VA, автоматизированный, интуитивно понятный, детерминированный метод, не требующий набора обучающих данных. Методы с использованием исходных данных больниц, проведенных Консорциумом по исследованию показателей здоровья населения, мы сравнили основные причины 1629 неонатальных и 1456 детских смертей в возрасте 1-59 месяцев, полученные с помощью алгоритмов экспертов VA, упорядоченных по иерархии, с исходными стандартными причинами.Экспертные алгоритмы оставались неизменными, в то время как пять предшествующих и одна новая «компромиссная» неонатальная иерархия и три бывших дочерних иерархии были протестированы. Для каждого сравнения эталонные стандартные данные подвергались повторной выборке 1000 раз в диапазоне фракций причинно-специфической смертности (CSMF) для одного из трех приближенных сценариев сообществ в глобальном сценарии причин смерти ВОЗ 2013 г. плюс один сценарий пропорций причин случайной смертности. Мы использовали точность CSMF для оценки общей валидности на уровне популяции и абсолютную разницу между VA и эталонными CSMF для изучения конкретных причин.Согласование с поправкой на случайность (CCC) и каппа Коэна использовались для оценки назначения причин на индивидуальном уровне. Результаты. Общая точность CSMF для иерархии наиболее эффективных экспертных алгоритмов составила 0,80 (диапазон 0,57–0,96) для неонатальных смертей и 0,76 (0,50–0,97) для детских смертей. Эффективность по конкретным причинам смерти варьировалась, с довольно стабильной оценкой CSMF в диапазоне контрольных значений для нескольких причин. Эффективность индивидуальной диагностики также была менее благоприятной, чем для общей CSMF (неонатальный: лучший CCC = 0.
Для каждого сравнения эталонные стандартные данные подвергались повторной выборке 1000 раз в диапазоне фракций причинно-специфической смертности (CSMF) для одного из трех приближенных сценариев сообществ в глобальном сценарии причин смерти ВОЗ 2013 г. плюс один сценарий пропорций причин случайной смертности. Мы использовали точность CSMF для оценки общей валидности на уровне популяции и абсолютную разницу между VA и эталонными CSMF для изучения конкретных причин.Согласование с поправкой на случайность (CCC) и каппа Коэна использовались для оценки назначения причин на индивидуальном уровне. Результаты. Общая точность CSMF для иерархии наиболее эффективных экспертных алгоритмов составила 0,80 (диапазон 0,57–0,96) для неонатальных смертей и 0,76 (0,50–0,97) для детских смертей. Эффективность по конкретным причинам смерти варьировалась, с довольно стабильной оценкой CSMF в диапазоне контрольных значений для нескольких причин. Эффективность индивидуальной диагностики также была менее благоприятной, чем для общей CSMF (неонатальный: лучший CCC = 0. 23, диапазон 0,16-0,33; наилучшая каппа = 0,29, 0,23-0,35; ребенок: лучший CCC = 0,40, 0,19-0,45; наилучшая каппа = 0,29, 0,07-0,35). Выводы Экспертные алгоритмы в иерархии предлагают доступный автоматизированный метод определения причин смерти VA. Общая точность на уровне популяции аналогична точности более сложных методов машинного обучения, но без необходимости в наборе обучающих данных из предыдущего валидационного исследования.
23, диапазон 0,16-0,33; наилучшая каппа = 0,29, 0,23-0,35; ребенок: лучший CCC = 0,40, 0,19-0,45; наилучшая каппа = 0,29, 0,07-0,35). Выводы Экспертные алгоритмы в иерархии предлагают доступный автоматизированный метод определения причин смерти VA. Общая точность на уровне популяции аналогична точности более сложных методов машинного обучения, но без необходимости в наборе обучающих данных из предыдущего валидационного исследования.
UR — http://www.scopus.com/inward/record.url?scp=8499
50&partnerID=8YFLogxKUR — http: // www.scopus.com/inward/citedby.url?scp=8499
50&partnerID=8YFLogxKU2 — 10.7189 / jogh.06.010601
DO — 10.7189 / jogh.06.010601
M3 — Артикул
USD
VL — 6
JO — Журнал глобального здравоохранения
JF — Журнал глобального здравоохранения
SN — 2047-2978
IS — 1
M1 — 010601
ER —
Безопасность | Стеклянная дверь
Подождите, пока мы убедимся, что вы настоящий человек.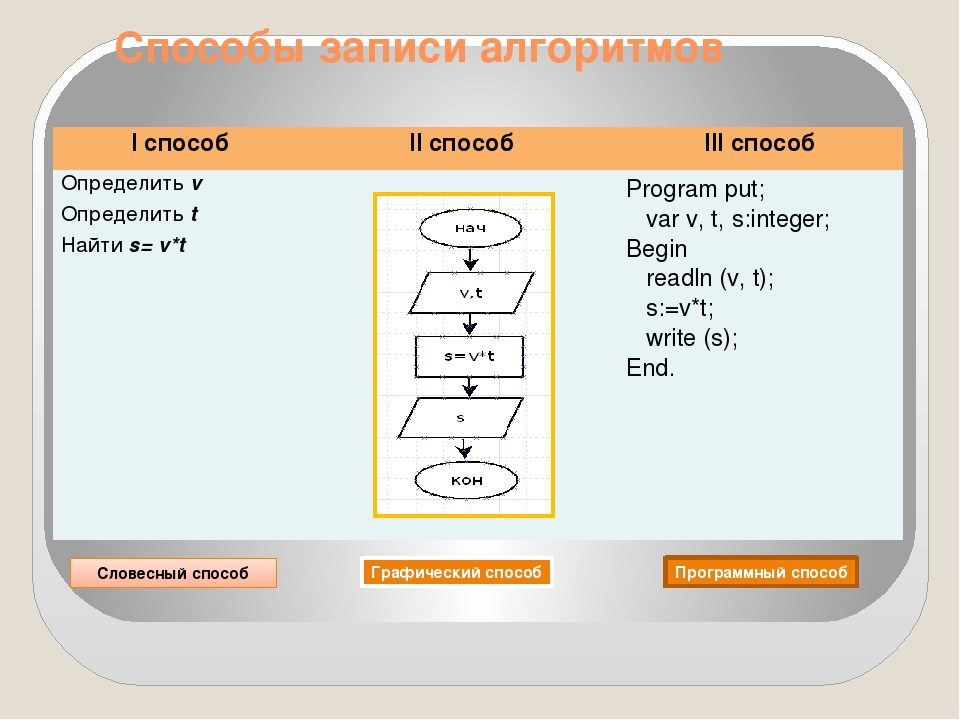 Ваш контент появится в ближайшее время.
Если вы продолжаете видеть это сообщение, напишите нам
чтобы сообщить нам, что у вас проблемы.
Ваш контент появится в ближайшее время.
Если вы продолжаете видеть это сообщение, напишите нам
чтобы сообщить нам, что у вас проблемы.
Подвеска Veuillez Patient que nous vérifions que vous êtes une personne réelle. Votre contenu s’affichera bientôt. Si vous continuez à voir ce message, contactez-nous à l’adresse pour nous faire part du problème.
Bitte warten Sie, während wir überprüfen, dass Sie wirklich ein Mensch sind. Ihr Вдохните вирд в Kürze angezeigt.Венн Си weiterhin diese Meldung erhalten, informieren Sie uns darüber bitte по электронной почте и .
Даже geduld a.u.b. Terwijl, мы проверяем, что вы склонны. Uw content wordt binnenkort weergegeven. Als u dit bericht blijft zien, stuur dan een e-mail naar om ons te информирует о новых проблемах.
Espera mientras verificamos que eres una persona real. Tu contenido se mostrará en breve. Si Continúas recibiendo este mensaje, infórmanos del проблема enviando un correo electrónico a .
Espera mientras verificamos que eres una persona real. Tu contenido aparecerá en
бреве. Si Continúas viendo este mensaje, envía un correo electrónico a
para informarnos que tienes issues.
Tu contenido aparecerá en
бреве. Si Continúas viendo este mensaje, envía un correo electrónico a
para informarnos que tienes issues.
Aguarde enquanto confirmamos que Você é Uma Pessoa de Verdade. Сеу конеудо será exibido em breve. Caso continuerecebendo esta mensagem, envie um e-mail para para nos informar sobre o проблема.
Attendi mentre verifichiamo Che sei una persona reale.Il tuo contenuto verrà visualizzato a breve. Secontini a visualizzare questo messaggio, invia un’email all’indirizzo per informarci del проблема.
Пожалуйста, включите куки и перезагрузите страницу.
Это автоматический процесс. Ваш браузер в ближайшее время перенаправит вас на запрошенный контент.
Подождите до 5 секунд…
Перенаправление…
Заводское обозначение: CF-102 / 6c099e137f2a4975.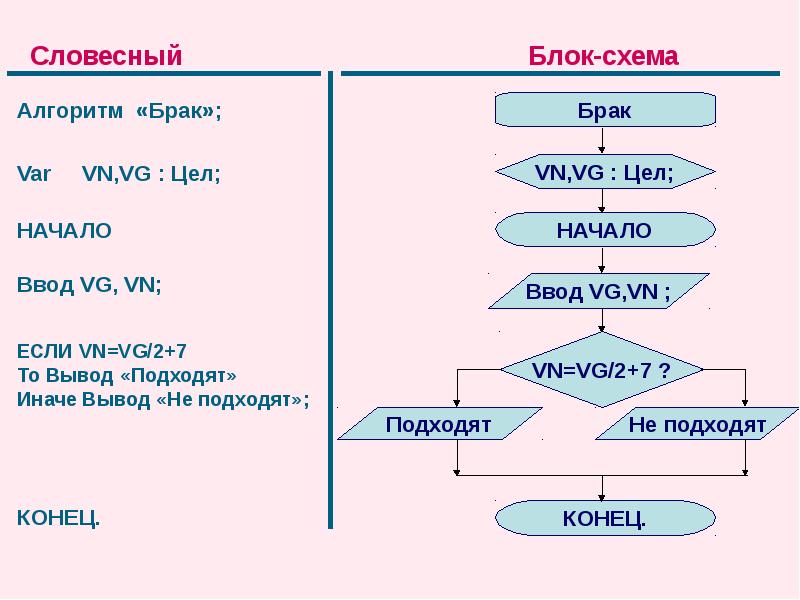
— валидационное исследование в Танзании и Зимбабве на JSTOR
Абстрактный Общие сведения Вербальное вскрытие в настоящее время является единственным способом получения информации о причинах смерти в большинстве групп населения с широко распространенной эпидемией ВИЧ / СПИДа.Методы. С использованием алгоритма, управляемого данными, был обучен набор критериев для классификации смертности от СПИДа. Использовались данные двух лонгитюдных исследований сообществ в Танзании и Зимбабве, в обоих из которых была собрана информация о ВИЧ-статусе населения за длительный период времени, а также поддерживалась система демографического наблюдения, которая собирает информацию о причинах смерти посредством вербальной аутопсии. Затем алгоритм был протестирован в разное время (две фазы исследования Зимбабве) и в разных местах (Танзания и Зимбабве).Результаты Обученный алгоритм, включающий девять признаков и симптомов, последовательно выполнялся на основе чувствительности и специфичности данных вербальной аутопсии для случаев смерти среди подростков в возрасте 15-44 лет из Зимбабве, фаза I (чувствительность 79%; специфичность 79%), фаза II (чувствительность 83%; специфичность 75%) и Танзании (чувствительность 75%; специфичность 74%). Чувствительность заметно снизилась при классификации смертей в возрасте 45-59 лет. Выводы. С помощью словесного вскрытия можно последовательно измерить смертность от СПИДа с помощью набора из девяти критериев.Эпиднадзор должен быть сосредоточен на случаях смерти в возрастной группе от 15 до 44 лет, в отношении которой метод дает надежные результаты. Добавление нескольких вопросов, связанных с оппортунистическими инфекциями, позволит другим широко используемым инструментам вербальной аутопсии применить этот проверенный метод в областях, по которым тестирование на ВИЧ и больничные записи недоступны или неполны.
Чувствительность заметно снизилась при классификации смертей в возрасте 45-59 лет. Выводы. С помощью словесного вскрытия можно последовательно измерить смертность от СПИДа с помощью набора из девяти критериев.Эпиднадзор должен быть сосредоточен на случаях смерти в возрастной группе от 15 до 44 лет, в отношении которой метод дает надежные результаты. Добавление нескольких вопросов, связанных с оппортунистическими инфекциями, позволит другим широко используемым инструментам вербальной аутопсии применить этот проверенный метод в областях, по которым тестирование на ВИЧ и больничные записи недоступны или неполны.
Журнал эпидемиологии и общественного здравоохранения — это действительно международный журнал, охватывающий все аспекты эпидемиологии и общественного здравоохранения.Он публикует оригинальные исследования, мнения и материалы, касающиеся изучения и улучшения сообществ во всем мире.
Информация об издателе Vision — Быть ведущим и пользующимся наибольшим доверием поставщиком информации и услуг в мире, которые существенно повлияют на клиническую практику и улучшат результаты для пациентов. Миссия — вести дебаты по вопросам здравоохранения и предоставлять инновационные, полезные знания, основанные на фактических данных, передовой опыт и обучение врачам, другим медицинским работникам, исследователям и пациентам, когда и где они в этом нуждаются.Мы издаем ряд журналов по основным специальностям и растущему числу онлайн-продуктов для врачей и пациентов. Непрерывное развитие продуктов гарантирует, что наши продукты и услуги имеют постоянное значение для медицинской профессии.
BMJ Publishing Group Ltd (BMJPG) является инновационным издательским подразделением Британской медицинской ассоциации (BMA) и одним из мировых лидеров в области медицинских публикаций. Группа BMJ дополняет деятельность BMA.
Миссия — вести дебаты по вопросам здравоохранения и предоставлять инновационные, полезные знания, основанные на фактических данных, передовой опыт и обучение врачам, другим медицинским работникам, исследователям и пациентам, когда и где они в этом нуждаются.Мы издаем ряд журналов по основным специальностям и растущему числу онлайн-продуктов для врачей и пациентов. Непрерывное развитие продуктов гарантирует, что наши продукты и услуги имеют постоянное значение для медицинской профессии.
BMJ Publishing Group Ltd (BMJPG) является инновационным издательским подразделением Британской медицинской ассоциации (BMA) и одним из мировых лидеров в области медицинских публикаций. Группа BMJ дополняет деятельность BMA.
ED регулирует алгоритм выбора для проверки, нормы выбора для нормализации
Карен Маккарти, сотрудник NASFAA по вопросам политики и федеральных отношений
В выходные, 16-17 декабря, Министерство образования (ED) внесло коррективы в свой алгоритм выбора для проверки на 2018-19 гг. , Что должно привести к нормализации показателей выбора для проверки для 2018-19 FAFSA, обработанных после этого времени, согласно устное руководство предоставлено NASFAA.
, Что должно привести к нормализации показателей выбора для проверки для 2018-19 FAFSA, обработанных после этого времени, согласно устное руководство предоставлено NASFAA.
После того, как многие школы сообщили о резких скачках в показателях проверочного отбора в 2018-19 годах по сравнению с тем же периодом в 2017-18 годах, ED исследовал и определил, что необходимы корректировки, чтобы вернуть показатели отбора к типичному диапазону, который колеблется около 30 процентов. в зависимости от страны, но может варьироваться в зависимости от учреждения.
Помимо административных проблем и проблем с рабочей нагрузкой для учебных заведений, школы и защитники доступа в колледжи сообщают, что проверка может удержать многих учащихся от завершения процесса подачи заявления.
ED вряд ли будет повторно обрабатывать любые ранее обработанные FAFSA, поэтому приложения, которые уже были выбраны для проверки ранее, останутся выбранными и должны быть проверены, если не применяется одно из допустимых исключений в соответствии с 668. 54 (b).
54 (b).
Хотя показатели отбора во многих учреждениях снизятся настолько, что общий процент отбора на 2018-19 год в конечном итоге будет таким же, как и в последние годы, есть некоторые учреждения, которые сообщили, что даже не через три месяца после начала года обработки они уже получили больше отобранных заявок на 2018-19 гг., чем за весь 2016-17 год.Чтобы решить эту проблему, NASFAA попросило ED ввести ограничение проверки, аналогичное тому, что существовало в предыдущие годы, в соответствии с которым учреждение не будет обязано выполнять дополнительные проверки после достижения определенного порога. НАФАА не получило информации о том, введет ли ED такое ограничение.
Дата публикации: 04.01.2018
.

